
RAG - Frameworks
Overview
- Retrieval-Augmented Generation (RAG) is an AI framework that enhances the capabilities of large language models (LLMs) by incorporating external knowledge sources.
- It helps overcome limitations such as knowledge cutoff dates and reduces the risk of hallucinations in LLM outputs.
- RAG works by retrieving relevant information from a knowledge base and using it to augment the LLM’s input, allowing the model to generate more accurate, up-to-date, and contextually relevant responses.

Haystack
- Haystack is an end-to-end LLM framework that allows you to build applications powered by LLMs, Transformer models, vector search and more.
- Whether you want to perform RAG, document search, question answering or answer generation, Haystack can orchestrate state-of-the-art embedding models and LLMs into pipelines to build end-to-end NLP applications and solve your use case.
- Haystack supports multiple installation methods including Docker images. You can simply get Haystack via pip.

RAGFlow
- RAGFlow offers a streamlined RAG workflow for businesses of any scale, combining LLM (Large Language Models) to provide truthful question-answering capabilities, backed by well-founded citations from various complex formatted data.
- It features “Quality in, quality out“, template-based chunking, grounded citations with reduced hallucinations, compatibility with heterogeneous data sources, and automated and effortless RAG workflow.

Prerequisites
| Component | Desc |
|---|---|
| CPU | >= 4 cores |
| RAM | >= 16 GB |
| Disk | >= 50 GB |
| Docker | >= 24.0.0 |
| Docker Compose | >= v2.26.1 |
STORM
- STORM is a LLM system that writes Wikipedia-like articles from scratch based on Internet search.
- It breaks down generating long articles with citations into two steps
- Pre-writing stage and Writing stage
- and identifies the core of automating the research process as automatically coming up with good questions to ask.
- To improve the depth and breadth of the questions, STORM adopts two strategies
- Perspective-Guided Question Asking and Simulated Conversation.
- Based on the separation of the two stages, STORM is implemented in a highly modular way using dspy.
- DSPy: Programming—not prompting—Foundation Models

FlashRAG
- FlashRAG is a Python toolkit for the reproduction and development of RAG research including 32 pre-processed benchmark RAG datasets and 14 state-of-the-art RAG algorithms.
- With FlashRAG and provided resources, you can reproduce existing SOTA works in the RAG domain or implement your custom RAG processes and components.
- FlashRAG features Extensive and Customizable Framework, Comprehensive Benchmark Datasets, Pre-implemented Advanced RAG Algorithms, Efficient Preprocessing Stage, and Optimized Execution. It’s still under development and more good functions are to be uncovered.
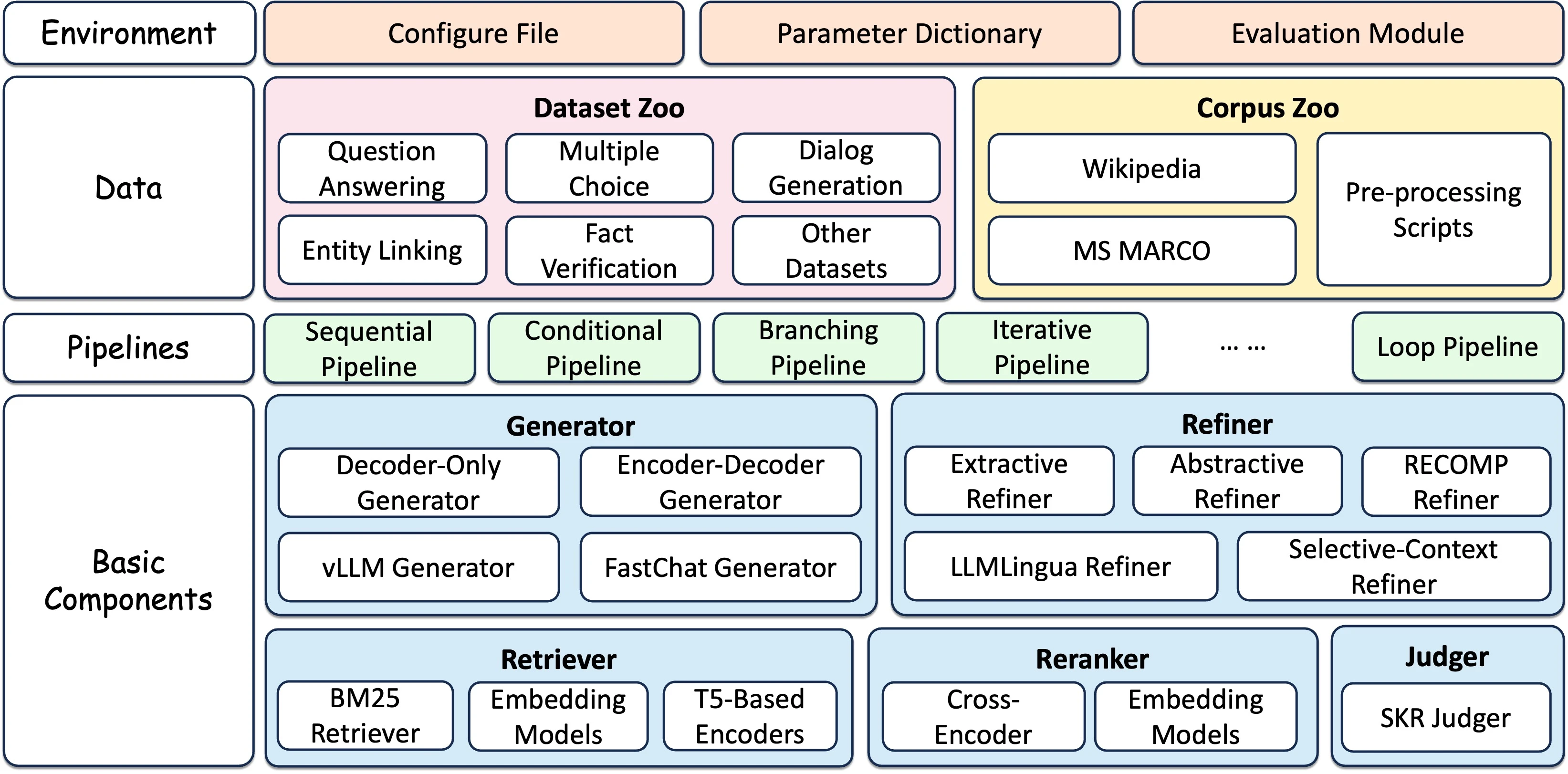
Canopy
- Canopy is an open-source RAG framework and context engine built on top of the Pinecone vector database enabling you to quickly and easily experiment with and build applications using RAG.
- Just start chatting with your documents or text data with a few simple commands.
- Canopy takes on the heavy lifting for building RAG applications
- from chunking and embedding your text data to chat history management, query optimization, context retrieval (including prompt engineering), and augmented generation.
- It provides a configurable built-in server so you can effortlessly deploy a RAG-powered chat application to your existing chat UI or interface. Or you can build your own, custom RAG application using the Canopy library.
- It lets you evaluate your RAG workflow with a CLI based chat tool as well.
- With a simple command in the Canopy CLI you can interactively chat with your text data and compare RAG vs. non-RAG workflows side-by-side.
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2024-08-04
RAG - LangChain
Practice LangChain RAG https://github.com/langchain-ai/rag-from-scratch RAG 如何随着长期 LLM 而改变 Is RAG Really Dead? https://www.youtube.com/watch?v=SsHUNfhF32s 自适应 RAG 根据复杂程度动态地将查询路由到不同的 RAG 方法 - Command-R @ LangGraph Adaptive RAG https://www.youtube.com/watch?v=04ighIjMcAI Code https://github.com/langchain-ai/langgraph/blob/main/examples/rag/langgraph_adaptive_rag_cohere.ipynb Paper https://arxiv.org/abs/2403.14403 Adaptive RAG 在循环单元测试中自我纠正检索错误,以确定文档相关性并返回到网络搜索 在 LangGraph 中实现 Mistral 7B + Ol...

2024-08-09
RAG - Chunking + Embedding
概述 Chunking Documents 经过解析后,通过 Chunking 将信息内容划分为适当大小的 Chunks - 能够高效处理和精准检索 Chunk 的本质在于依据一定的逻辑和语义原则,将长文本拆解为更小的单元 Chunking 有多种策略,各有侧重,选择适合特定场景的 Chunking 策略,有助于提升 RAG 召回率 Embedding Embedding Model 负责将文本数据映射到高维向量空间,将输入的文档片段转换为对应的嵌入向量 嵌入向量捕捉了文本的语义信息,并存储到向量库中,以便于后续检索 Query 同样通过 Embedding Model 的处理生成 Query 的嵌入向量,在向量库中通过向量检索匹配最相似的文档片段 根据不同的场景,评估并选择最优的 Embedding Model,以确保 RAG 的检索性能符合要求 Chunking影响 Documents 包含丰富的上下文信息和复杂的语义结构 通过 Chunking,模型可以更有效地提取关键信息,并减少不相关内容的干扰 Chunking 的目标 确保每个片段在保留核心语义的同时,具备相对独立的语...
2024-08-03
RAG - In Action
技术选型LangChain LangChain 是专门为开发基于 LLM 应用而设计的全面框架 LangChain 的核心目标是简化开发者的构建流程,使其能够高效地创建 LLM 驱动的应用 索引文档解析 pypdf 专门用于处理 PDF 文档 pypdf 支持 PDF 文档的创建、读取、编辑和转换,能够有效地提取和处理文本、图像及页面内容 文档分块 RecursiveCharacterTextSplitter 是 LangChain 默认的文本分割器 RecursiveCharacterTextSplitter 通过层次化的分隔符(从双换行符到单字符)拆分文本 旨在保持文本的结构和连贯性,优先考虑自然边界(如段落和句子) 索引 + 检索向量化模型 bge-small-zh-v1.5 是由北京智源人工智能研究院(BAAI)开发的开源向量模型 bge-small-zh-v1.5 的模型体积较小,但仍能提供高精度和高效的中文向量检索 bge-small-zh-v1.5 的向量维度为 512,最大输入长度同样为 512 向量库 Faiss - Facebook AI Similarity Sea...

2024-08-10
RAG - Chatbot
Fine-tuning vs RAG 核心诉求 - 实时更新知识库,不需要模型去深度探讨问题,使用已有知识经验去解答问题 Fine-tuning RAG 知识整合 直接把数据融入到模型参数 存储在外部知识库 知识更新 每次更新内容都需要重新训练模型,更新成本高 只需要在外部知识库插入记录,更新成本低 响应速度 很快,直接给出回答 现在外部知识库进行检索,然后再生成 实时更新 很难做到实时更新 外部知识库可以实时更新 人为干预 只能通过 Prompt 干预 可以通过外部知识库的语料和 Prompt 控制 领域定制 可以针对特定领域进行深度定制 依赖通用模型能力 适合使用 Fine-tuning 的场景 特定场景下的高一致性和定制化 数据量充足且稳定 训练 - 拥有高质量的对话原始数据 微调 - 基于现有对话数据做对话助手 强个性化需求 文言文的理解和输出 - 需要使用大量文言文语料微调后,才能满足需求 高速响应 Fine-tuning 能够直接输出有效内容,而 RAG 需要先检索再生成 LLM LLM 针对输入是有长度限制的,计量单位为 To...

2024-06-28
LLM Deploy - ChatGLM3-6B
LLM 选择核心玩家 厂家很多,但没多少真正在研究技术 - 成本 - 不少厂商是基于 LLaMA 套壳 ChatGLM-6B ChatGLM-6B 和 LLaMA2 是比较热门的开源项目,国产 LLM 是首选 企业布局 LLM 选择 MaaS 服务,调用大厂 LLM API,但会面临数据安全问题 选择开源 LLM,自己微调、部署、为上层应用提供服务 企业一般会选择私有化部署 + 公有云 MaaS 的混合架构 在国产厂商中,从技术角度来看,智谱 AI 是国内 LLM 研发水平最高的厂商 6B 的参数规模为 62 亿,单张 3090 显卡就可以进行微调和推理 企业预算充足(百万以上,GPU 费用 + 商业授权) 可以尝试 GLM-130B,千亿参数规模,推理能力更强 GLM-130B 轻量化后,可以在 3090 × 4 上进行推理 训练 GLM-130B 大概需要 96 台 A100(320G),历时两个多月 计算资源 适合 CPU 计算的 LLM 不多 有些 LLM 可以在 CPU 上进行推理,但需要使用低精度轻量化的 LLM 但在低精度下,LLM 会失真,效果较差 要真正体验并应...
2024-08-16
RAG - Evolution
演进 Naive RAG -> Advanced RAG -> Modular RAG 三个范式之间具有继承与发展的关系 Advanced RAG 是 Modular RAG 的一种特例形式 Naive RAG 是 Advanced RAG 的基础特例 RAG 技术不断演进,以适应更复杂的任务和场景需求 Naive RAG Naive RAG 是最基础的形式,依赖核心的索引和检索策略来增强生成模型的输出 Naive RAG 适用于一些基础任务和产品 MVP 阶段 Advanced RAG 通过增加检索前、检索中以及检索后的优化策略,提高检索的准确性和生成的关联性 - 适用于复杂任务 Advanced RAG 通过优化检索前、检索中、检索后的各个环节 在索引质量、检索效果以及生成内容的上下文相关性方面都取得显著提升 检索前 通过索引、分块、查询优化和内容向量化等技术手段,提高检索内容的精确性和生成内容的相关性 滑动窗口 overlap 经典的 Chunking 技术,通过在相邻的 Chunk 之间创建重叠区域,确保关键信息不会因简单的 Chunking 而丢失 在 ...




