
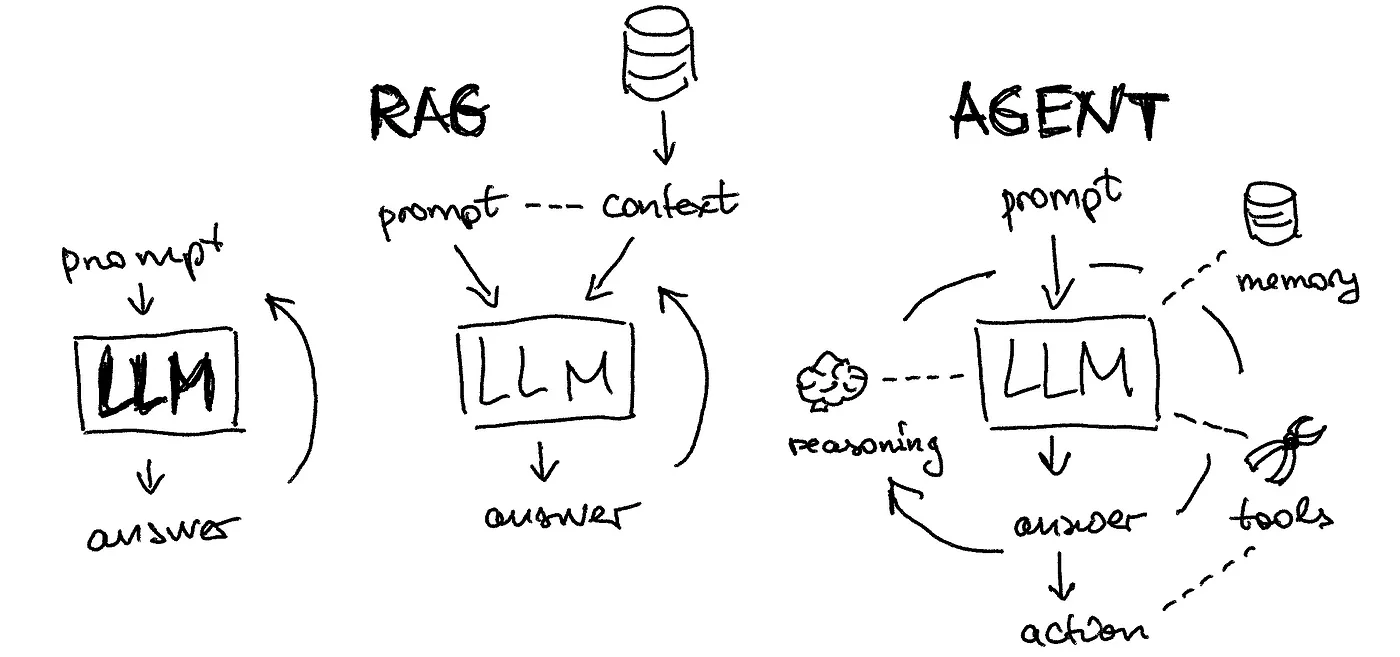
RAG - Chatbot
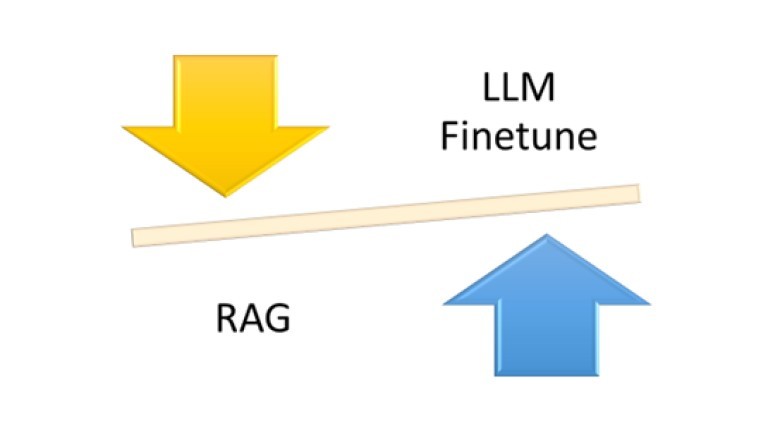
Fine-tuning vs RAG
核心诉求 - 实时更新知识库,不需要模型去深度探讨问题,使用已有知识经验去解答问题
| Fine-tuning | RAG | |
|---|---|---|
| 知识整合 | 直接把数据融入到模型参数 | 存储在外部知识库 |
| 知识更新 | 每次更新内容都需要重新训练模型,更新成本高 | 只需要在外部知识库插入记录,更新成本低 |
| 响应速度 | 很快,直接给出回答 | 现在外部知识库进行检索,然后再生成 |
| 实时更新 | 很难做到实时更新 | 外部知识库可以实时更新 |
| 人为干预 | 只能通过 Prompt 干预 | 可以通过外部知识库的语料和 Prompt 控制 |
| 领域定制 | 可以针对特定领域进行深度定制 | 依赖通用模型能力 |
适合使用 Fine-tuning 的场景
- 特定场景下的高一致性和定制化
- 数据量充足且稳定
- 训练 - 拥有高质量的对话原始数据
- 微调 - 基于现有对话数据做对话助手
- 强个性化需求
- 文言文的理解和输出 - 需要使用大量文言文语料微调后,才能满足需求
- 高速响应
- Fine-tuning 能够直接输出有效内容,而 RAG 需要先检索再生成
LLM
- LLM 针对输入是有长度限制的,计量单位为 Token(英文单词、英文短语、汉字)
- GPT-3.5 的最大 Token 数为 4K,包含了输入和输出的总和
架构
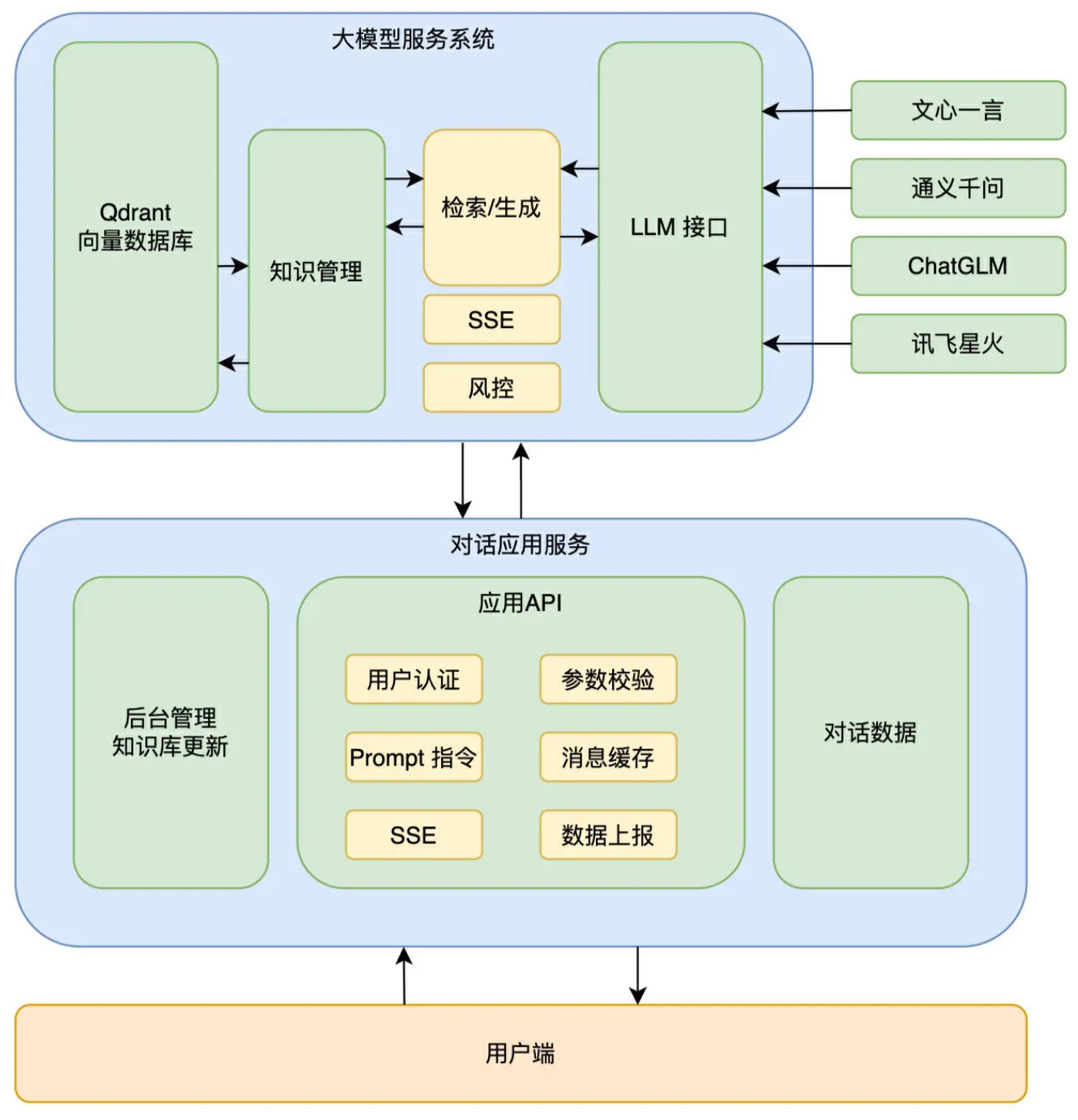
实现
Context
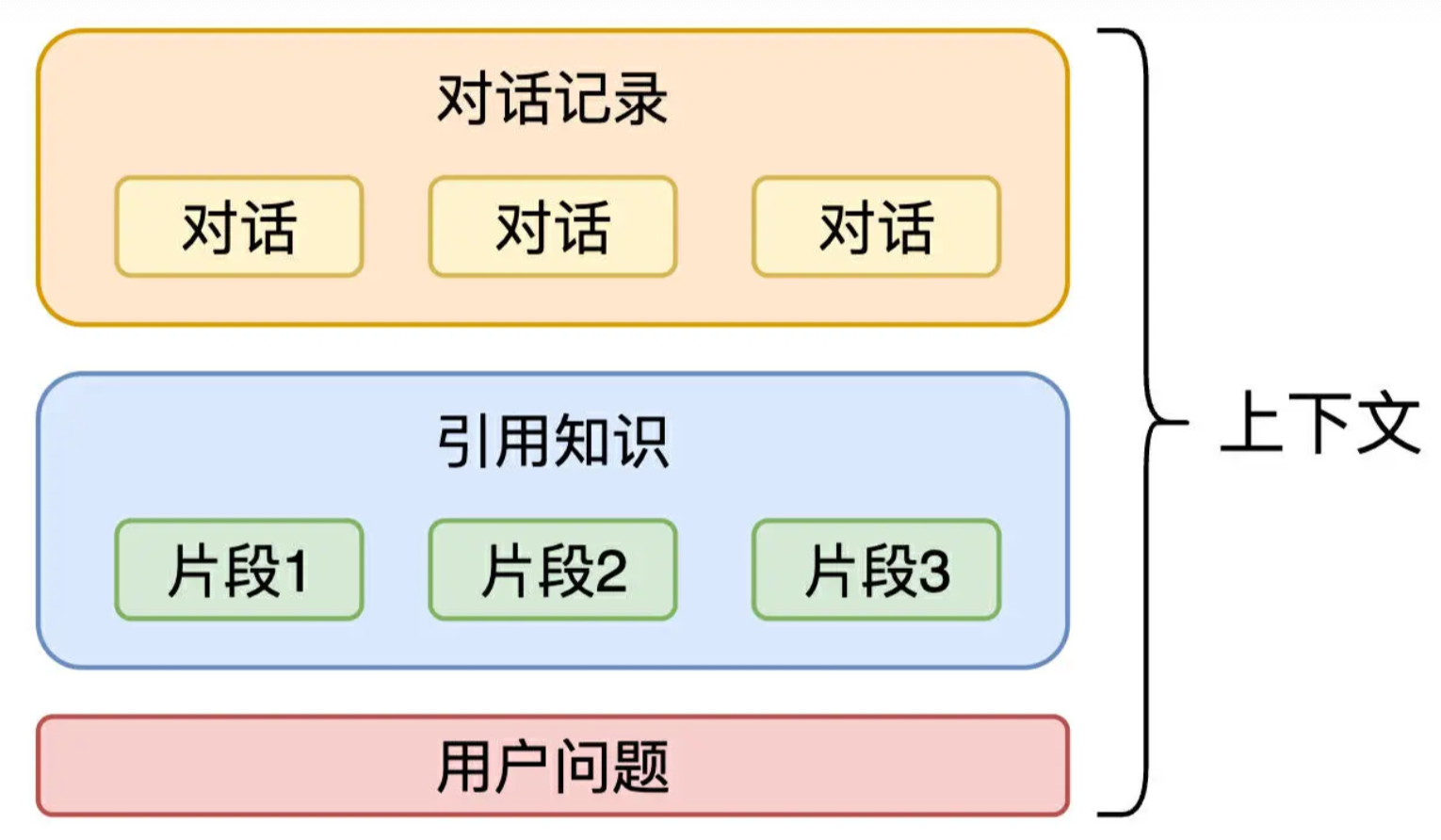
Framework
LlamaIndex
SSE vs WebSocket
HTTP Server-Sent Events - 流式对话
| SSE | WebSocket | |
|---|---|---|
| 通信方向 | 单向通信 | 双向通信 |
| 协议 | 基于 HTTP 协议 兼容性好,各种网关防火墙都支持 |
基于 WebSocket 协议 需要整条链路的网关都支持 WebSocket |
| 自动重连 | 自带重连机制 | 需要手动实现 |
| 性能 | 轻量,服务器资源占用低 | 每个应用都会占用一个 WebSocket 连接 |
| 浏览器支持 | 除 IE 外 | 基本都支持 |
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2024-08-13
RAG - Hybrid retrieval + Rerank
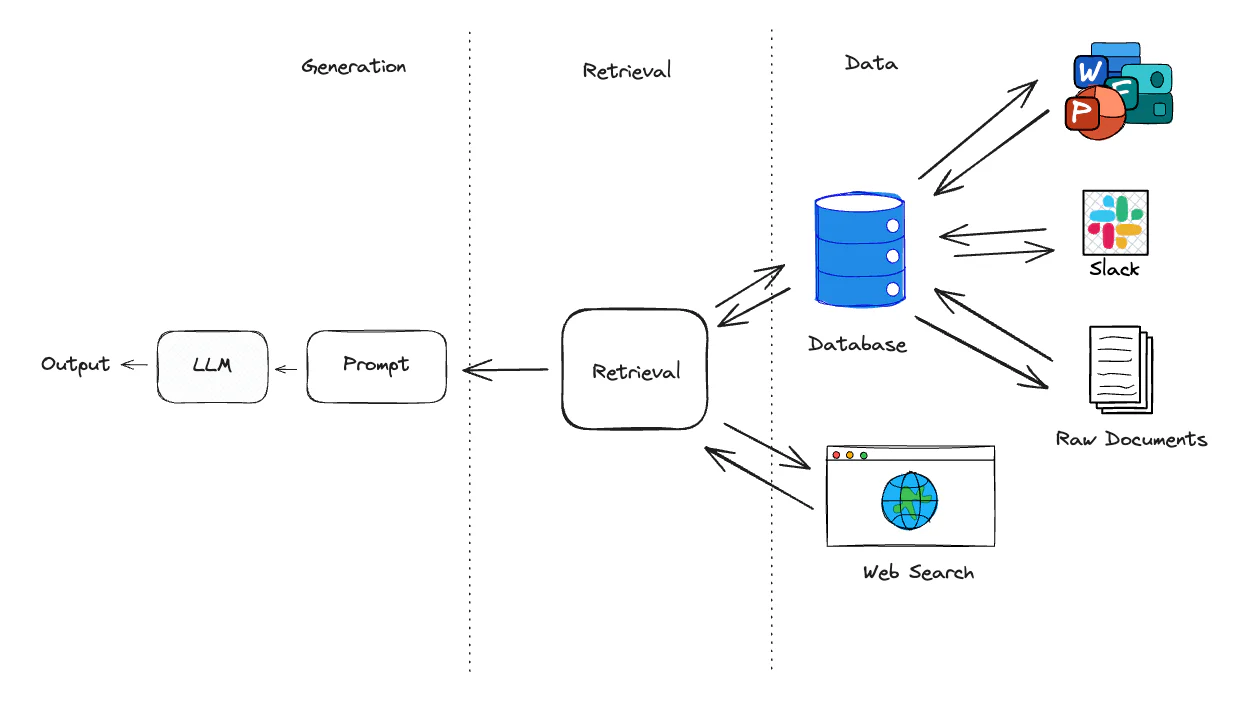
向量检索 当前主流的 RAG 检索方式主要采用向量检索,通过语义相似度来匹配 Chunk 向量检索并非万能,在某些场景下无法替代传统关键词检索的优势 当需要精准搜索的时候,向量检索的准确性就往往不如关键词检索 当用户输入的问题非常简短,语义匹配的效果可能不尽理想 关键词检索的适用场景 精确匹配 少量字符的匹配 - 不适合用向量检索 低频词汇的匹配 混合检索 结合关键词检索和语义匹配的优势 在 RAG 检索场景中,首要目标是确保最相关的结果能够出现在候选列表中 向量检索和关键词检索各具优势,混合检索通过结合多种检索技术,弥补各自不足,提供一种更加全面的搜索方案 重排序技术在检索系统中扮演着至关重要的角色 即使检索算法已经能够捕捉到所有相关的结果,重排序过程依然不可或缺 确保最符合用户意图和查询语义的结果优先展示,提升用户的搜索体验和结果的准确性 在多个数据集和多个检索任务中,混合检索和重排序的组合均取得了最佳表现 融合检索 / 多路召回 https://python.langchain.com/v0.2/api_reference/community/r...
2024-08-04
RAG - LangChain
Practice LangChain RAG https://github.com/langchain-ai/rag-from-scratch RAG 如何随着长期 LLM 而改变 Is RAG Really Dead? https://www.youtube.com/watch?v=SsHUNfhF32s 自适应 RAG 根据复杂程度动态地将查询路由到不同的 RAG 方法 - Command-R @ LangGraph Adaptive RAG https://www.youtube.com/watch?v=04ighIjMcAI Code https://github.com/langchain-ai/langgraph/blob/main/examples/rag/langgraph_adaptive_rag_cohere.ipynb Paper https://arxiv.org/abs/2403.14403 Adaptive RAG 在循环单元测试中自我纠正检索错误,以确定文档相关性并返回到网络搜索 在 LangGraph 中实现 Mistral 7B + Ol...
2024-08-03
RAG - In Action
技术选型LangChain LangChain 是专门为开发基于 LLM 应用而设计的全面框架 LangChain 的核心目标是简化开发者的构建流程,使其能够高效地创建 LLM 驱动的应用 索引文档解析 pypdf 专门用于处理 PDF 文档 pypdf 支持 PDF 文档的创建、读取、编辑和转换,能够有效地提取和处理文本、图像及页面内容 文档分块 RecursiveCharacterTextSplitter 是 LangChain 默认的文本分割器 RecursiveCharacterTextSplitter 通过层次化的分隔符(从双换行符到单字符)拆分文本 旨在保持文本的结构和连贯性,优先考虑自然边界(如段落和句子) 索引 + 检索向量化模型 bge-small-zh-v1.5 是由北京智源人工智能研究院(BAAI)开发的开源向量模型 bge-small-zh-v1.5 的模型体积较小,但仍能提供高精度和高效的中文向量检索 bge-small-zh-v1.5 的向量维度为 512,最大输入长度同样为 512 向量库 Faiss - Facebook AI Similarity Sea...
2024-08-05
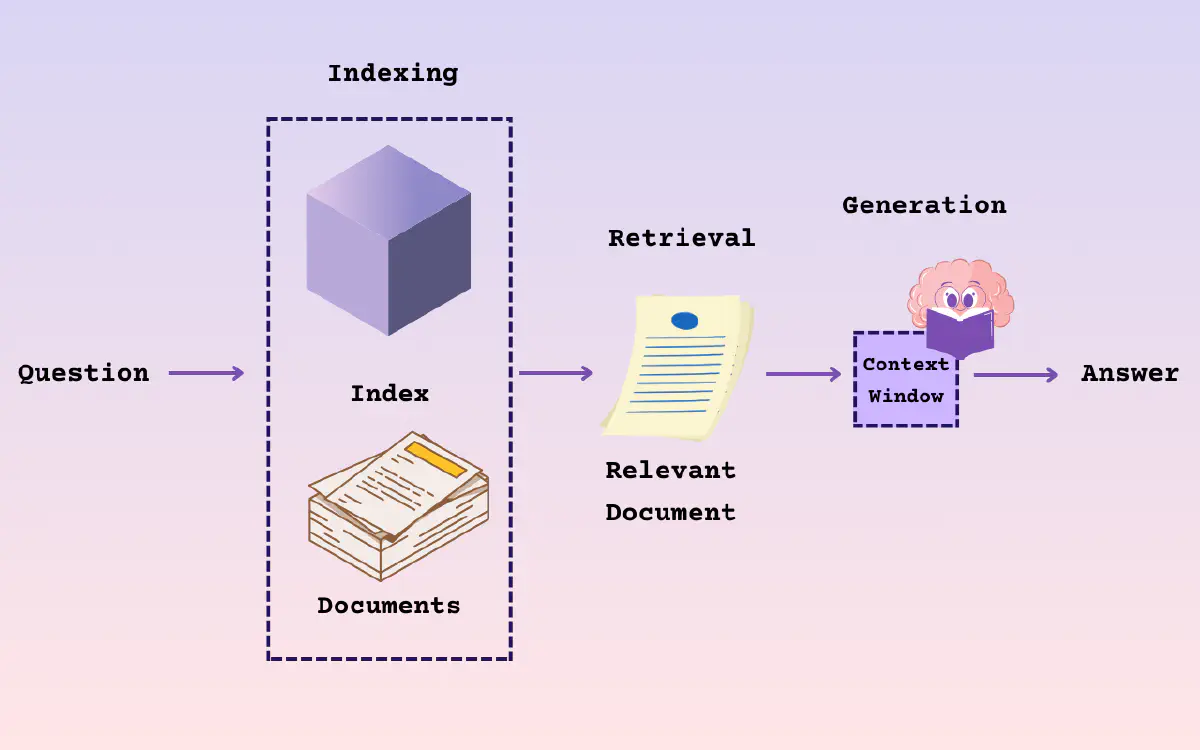
RAG - Document Parsing
文档解析 文档解析的本质 - 将格式各异、版本多样、元素多种的文档数据,转化为阅读顺序正确的字符串信息 Quality in, Quality out 是 LLM 的典型特征 高质量的文档解析能够从各种复杂格式的非结构化数据中提取出高精度信息 对 RAG 系统的最终效果起到决定性作用 RAG 系统的应用场景主要集中在专业领域和企业场景 除了数据库,更多的数据以 PDF、Word 等多种格式存储 PDF 文件有统一的排版和多样化的结构形式,是最为常见的文档数据格式和交换格式 Quality in, Quality out LangChainDocument Loaders LangChain 提供了一套功能强大的文档加载器(Document Loaders) LangChain 定义了 BaseLoader 类和 Document 类 BaseLoader - 定义如何从不同数据源加载文档 Document - 统一描述不同文档类型的元数据 开发者可以基于 BaseLoader 为特定数据源创建自定义加载器,将其内容加载为 Document 对象 Document Loader 模...
2024-06-30
LLM RAG - ChatGLM3-6B + LangChain + Faiss
RAG 使用知识库,用来增强 LLM 信息检索的能力 知识准确 先把知识进行向量化,存储到向量数据库中 使用的时候通过向量检索从向量数据库中将知识检索出来,确保知识的准确性 更新频率快 当发现知识库里面的知识不全时,可以随时补充 不需要像微调一样,重新跑微调任务、验证结果、重新部署等 应用场景 ChatOps 知识库模式适用于相对固定的场景做推理 如企业内部使用的员工小助手,不需要太多的逻辑推理 使用知识库模式检索精度高,且可以随时更新 LLM 基础能力 + Agent 进行堆叠,可以产生智能化的效果 LangChain-Chatchat组成模块 模块 作用 支持列表 大语言模型 智能体核心引擎 ChatGLM / Qwen / Baichuan / LLaMa Embedding 模型 文本向量化 m3e-* / bge-* 分词器 按照规则将句子分成短句或者单词 LangChain Text Splitter 向量数据库 向量化数据存储 Faiss / Milvus Agent Tools 调用第三方...
2024-08-12
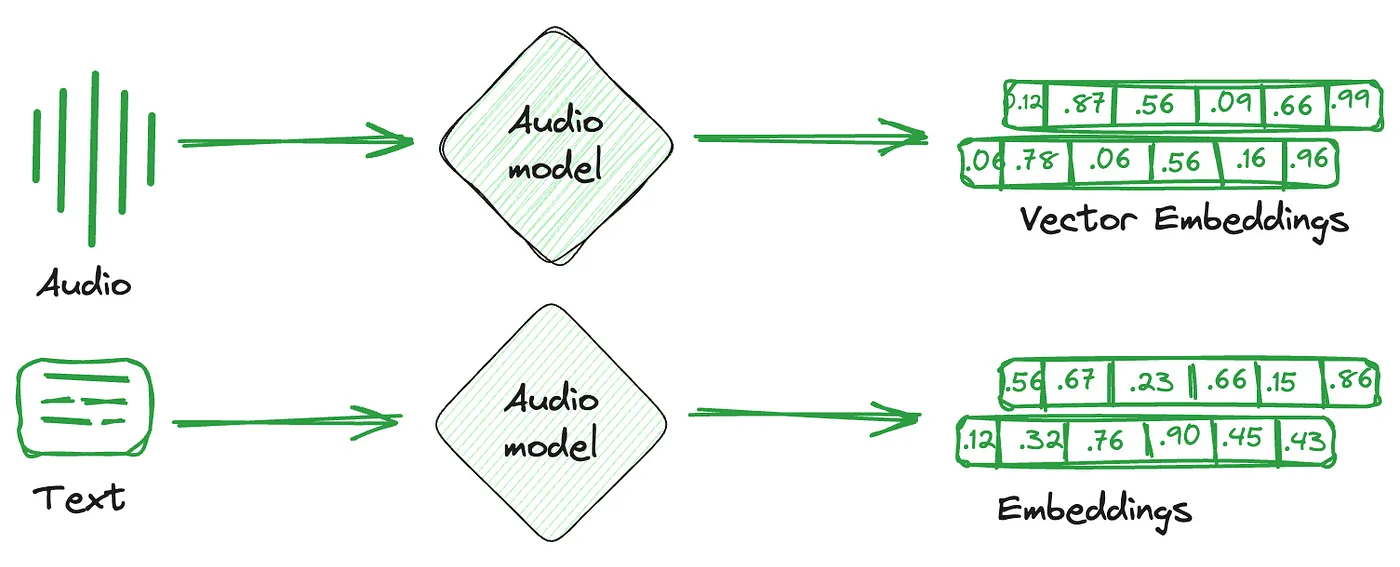
RAG - Vector Stores
Embedding Vector Store概述 在 AI 时代,文字、图像、语音、视频等多模态数据的复杂性显著增加 多模态数据具有非结构化和多维特征 向量表示能够有效表示语义和捕捉潜在的语义关系 促使向量数据库成为存储、检索和分析高维向量的关键工具 Qdrant / Milvus 优势 SQL vs NoSQL 传统数据库通常分为关系型(SQL)数据库和非关系型(NoSQL)数据库 存储复杂、非结构化或半结构化信息的需求,主要依赖于 NoSQL 的能力 Store Desc Note Key-Value 用于简单的数据存储,通过 Key 来快速访问数据 精准定位信息 Document 用于存储文档结构的数据,如 JSON 格式 复杂的结构化信息 Graph 用于表示和存储复杂的关系数据,常用于社交网络、推荐等场景 复杂的关系数据 Vector 用于存储和检索基于向量表示的数据,用于 AI 模型的高维度和复杂的嵌入向量 语义最相关的数据 向量数据库的核心在于能够基于向量之间的相似性,能够快速、精确地定位和检索数据 向量数据库不仅为嵌入向量提供了...




