
RAG - Vector Stores
Embedding
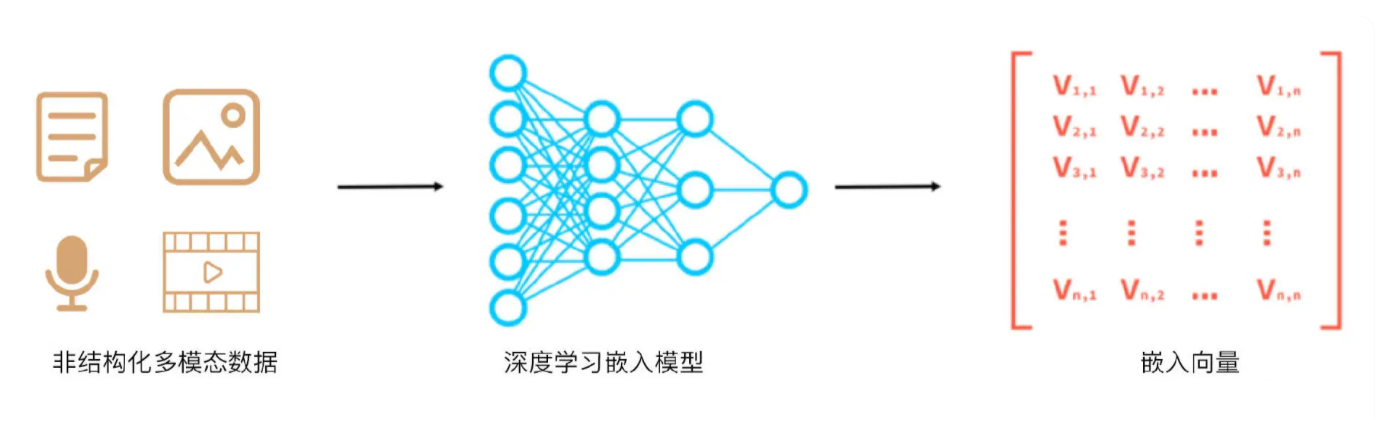
Vector Store
概述
- 在 AI 时代,文字、图像、语音、视频等多模态数据的复杂性显著增加
- 多模态数据具有非结构化和多维特征
- 向量表示能够有效表示语义和捕捉潜在的语义关系
- 促使向量数据库成为存储、检索和分析高维向量的关键工具
Qdrant / Milvus

优势
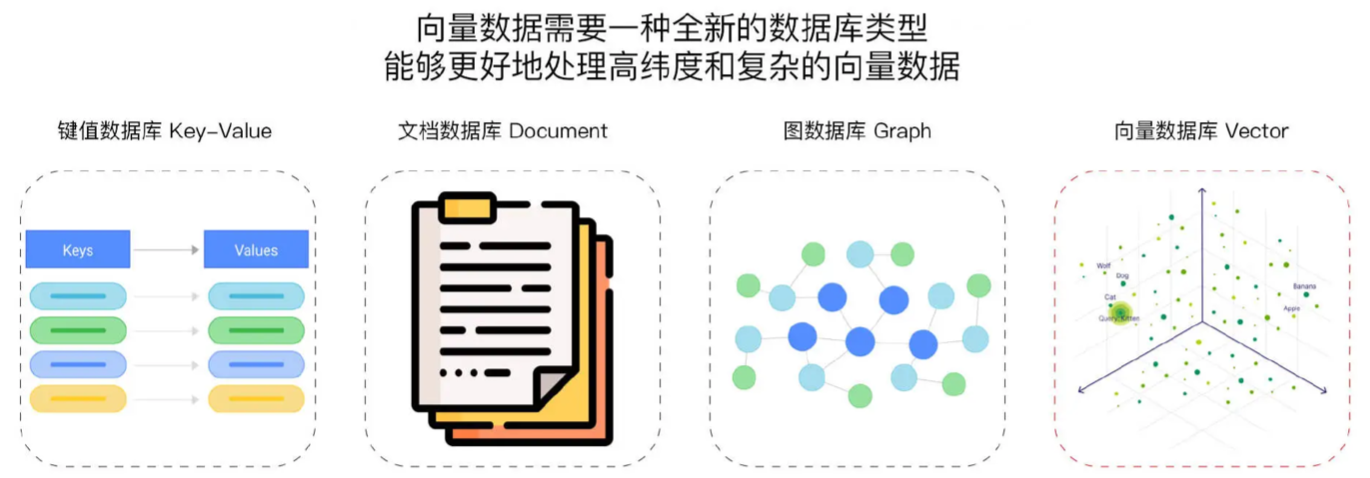
SQL vs NoSQL
- 传统数据库通常分为关系型(SQL)数据库和非关系型(NoSQL)数据库
- 存储复杂、非结构化或半结构化信息的需求,主要依赖于 NoSQL 的能力
| Store | Desc | Note |
|---|---|---|
| Key-Value | 用于简单的数据存储,通过 Key 来快速访问数据 | 精准定位信息 |
| Document | 用于存储文档结构的数据,如 JSON 格式 | 复杂的结构化信息 |
| Graph | 用于表示和存储复杂的关系数据,常用于社交网络、推荐等场景 | 复杂的关系数据 |
| Vector | 用于存储和检索基于向量表示的数据,用于 AI 模型的高维度和复杂的嵌入向量 | 语义最相关的数据 |
- 向量数据库的核心在于能够基于向量之间的相似性,能够快速、精确地定位和检索数据
- 向量数据库不仅为嵌入向量提供了优化的存储和查询性能
- 同时也继承了传统数据库的诸多优势 - 性能、可扩展性、灵活性 - 充分利用大规模数据
- 传统的基于标量的数据库
- 无法应对数据复杂性和规模化处理的挑战,难以有效提取洞察并实现实时分析
主要优势
- 数据管理
- 向量数据库提供易于使用的数据存储功能 - 插入 + 删除 + 更新
- Faiss 是独立的向量索引工具,需要额外的工作才能与存储解决方案集成
- 元数据存储和筛选
- 向量数据库能够存储与每个向量条目关联的元数据
- 基于元数据,可以进行更细粒度的查询,从而提升查询的精确度和灵活性
- 可扩展性
- 向量数据库支持分布式和并行处理
- 并通过无服务器架构优化大规模场景下成本
- 实时更新
- 向量数据库支持实时数据更新
- 允许动态修改数据以确保检索结果的时效性和准确性
- 备份与恢复
- 向量数据库具备完善的备份机制,确保数据的安全性和持久性
- 生态系统集成
- 向量数据库能够与数据处理生态系统中的其它组件轻松集成 - Spark
- 还能无缝集成 AI 相关工具 - LangChain / LlamaIndex / Cohere
- 数据安全与访问控制
- 向量数据库提供内置的数据安全功能和访问控制机制,以保护敏感信息
- 通过命名空间实现多租户管理,允许对索引进行完全分区
应用场景
- 向量数据库广泛应用于 LLM RAG 系统、推荐系统等多种 AI 产品中
- 向量数据库是一类专门为生产场景下的嵌入向量管理而构建的数据库
- 与传统基于标量的数据库以及独立的向量索引工具相比
- 向量数据库在性能、可扩展性、安全性和生态系统集成等方面展现了显著的优势
原理
- 向量数据库是一种专门用于存储和检索多维向量的数据库类型
- 与传统的基于行列结构的数据库不同,向量数据库主要处理高维空间中的数据点
- 传统数据库通常处理字符串、数字等标量,并通过精确匹配来查询数据
- 向量数据库的操作逻辑是基于相似性搜索
- 在查询时,应用特定的相似性度量(余弦相似度、欧几里得距离等)来查找与查询向量最相似的向量
- 向量数据库的核心在于其高效的索引和搜索机制
- 为了优化查询性能,采用哈希(LSH)、量化(PQ)和基于图形(HNSW)的多种算法
- 构建层次化可导航小世界(HNSW)、产品量化(PQ)和位置敏感哈希(LSH)等索引结构,提升查询性能
- 搜索过程并非追求绝对精确
- 通过近似最近邻算法(ANN)在速度和准确性之间进行权衡
- ANN 算法允许一定程度的误差 - 显著提升搜索速度 + 找到与查询相似度较高的向量
向量数据库的索引结构相当于一种预处理步骤
| Index structure | Desc |
|---|---|
| HNSW | 通过在多层结构中将相似向量连接在一起,快速缩小搜索范围 |
| PQ | 通过压缩高维向量,减少内存占用并加速检索 |
| LSH | 通过哈希函数将相似向量聚集在一起,便于快速定位 |
流程
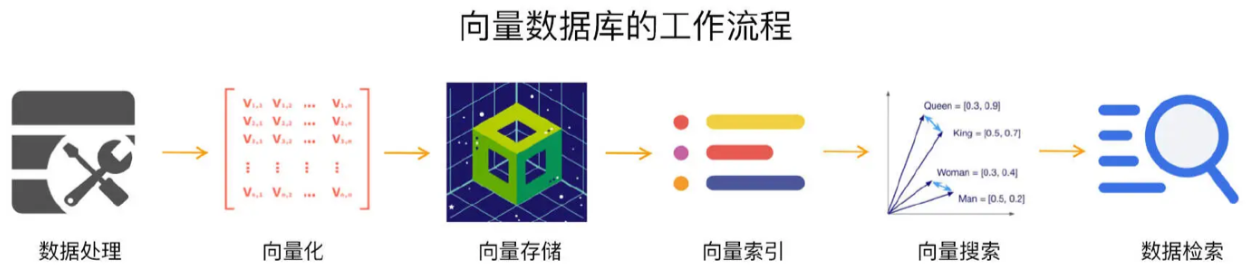
- 数据处理 + 向量化
- 原始数据首先被处理并转化为嵌入向量
- 通过嵌入模型实现,利用深度学习算法提取数据的语义特征,生成适合后续处理的高维向量表示
- 向量存储
- 将转化后的嵌入向量存储到向量数据库中
- 数据高效检索 + 以优化的方式管理和维护存储资源(适应不同规模和复杂度的应用需求)
- 向量索引
- 存储的嵌入向量经过索引处理,便于在后续查询中快速定位相关数据
- 索引过程通过构建特定结构,使得数据库能够在大规模数据集上实现高效的查询响应
- 向量搜索
- 在收到查询向量后,向量数据库通过已建立的索引结构执行相似性搜索 - 与查询向量最接近的数据点
- 平衡搜索速度和准确性 - 在大数据环境下提供快速且相关的查询结果
- 相似度度量
- 余弦相似度 - 用于文件处理和信息检索 - 关注向量之间的角度,捕捉语义相似性
- 欧几里得距离 - 测量向量之间的实际距离 - 适用于密集特征集的聚类和分类
- 曼哈顿距离 - 计算笛卡尔坐标中绝对差值之和,适用于稀疏数据的处理
- 点积
- 数据检索
- 向量数据库从匹配的向量中检索出对应的原始数据,并按需处理
- 确保最终结果能够准确反映用户的查询意图,并提供有意义的输出
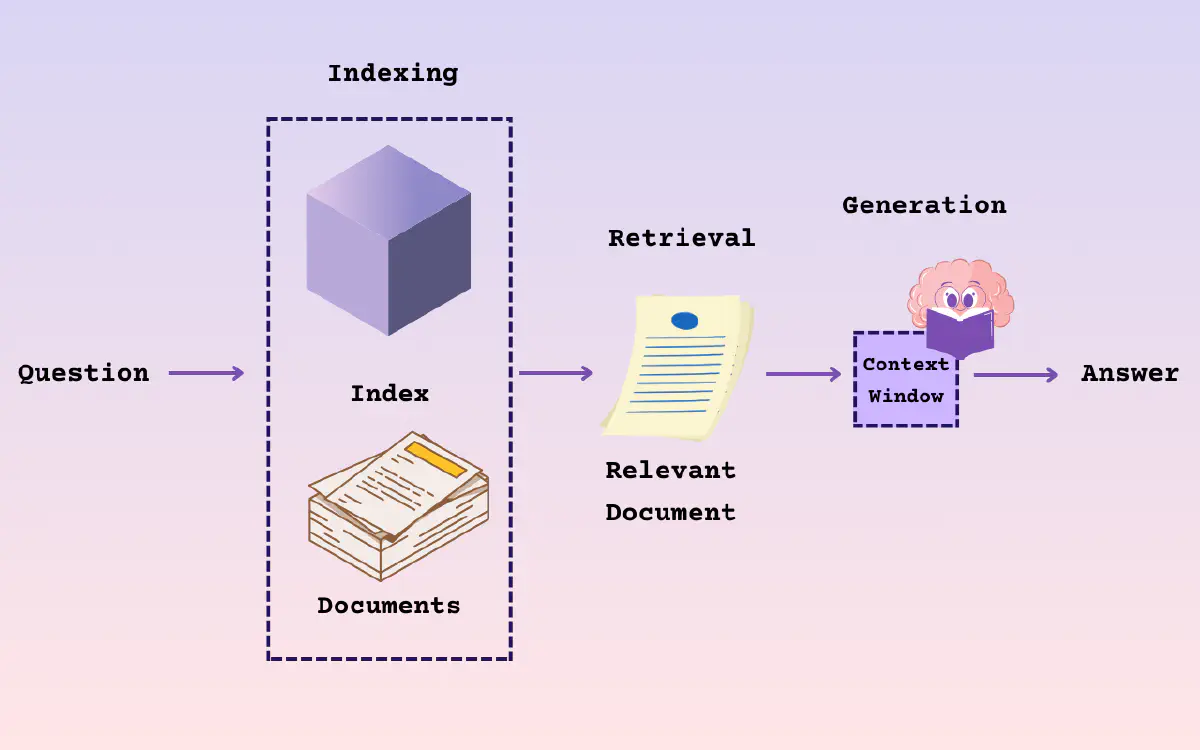
RAG
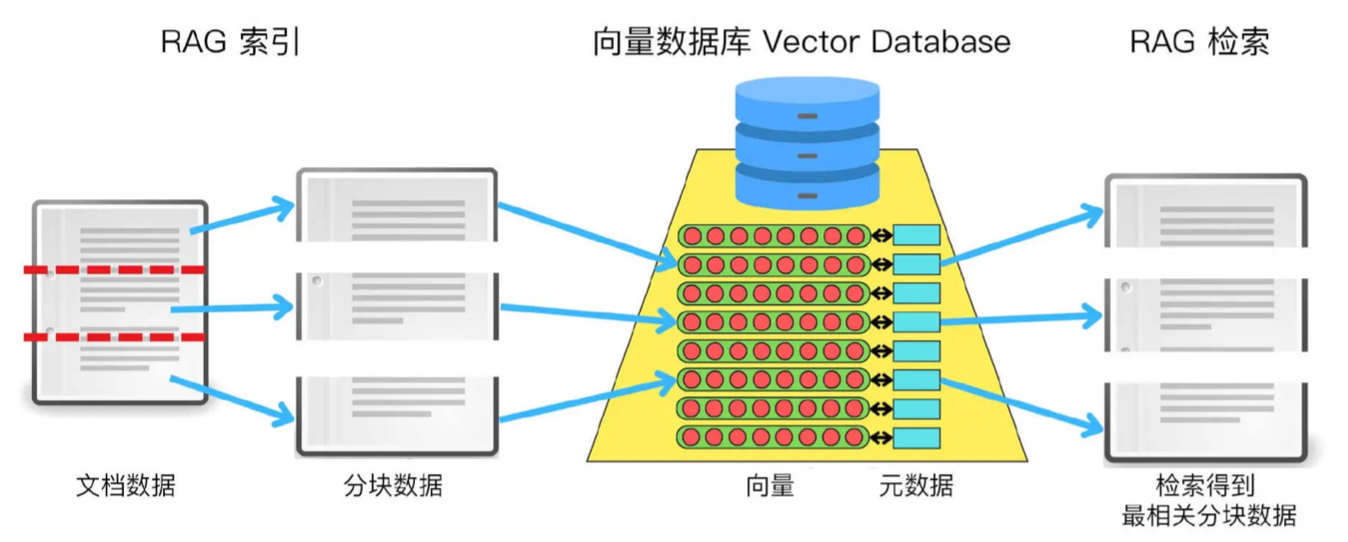
- 在 RAG 系统中,向量数据库的主要功能在于索引过程中,建立高效的向量索引结构
- 在查询阶段,系统将输入的提示转化为向量表示形式
- 从向量数据库中检索出与之最相关的向量及其对应的分块数据
- 通过索引和检索,检索到的向量为 LLM 提供了必要的上下文信息
- LLM 能够依据当前的语义上下文生成更加精确和相关的响应
选型
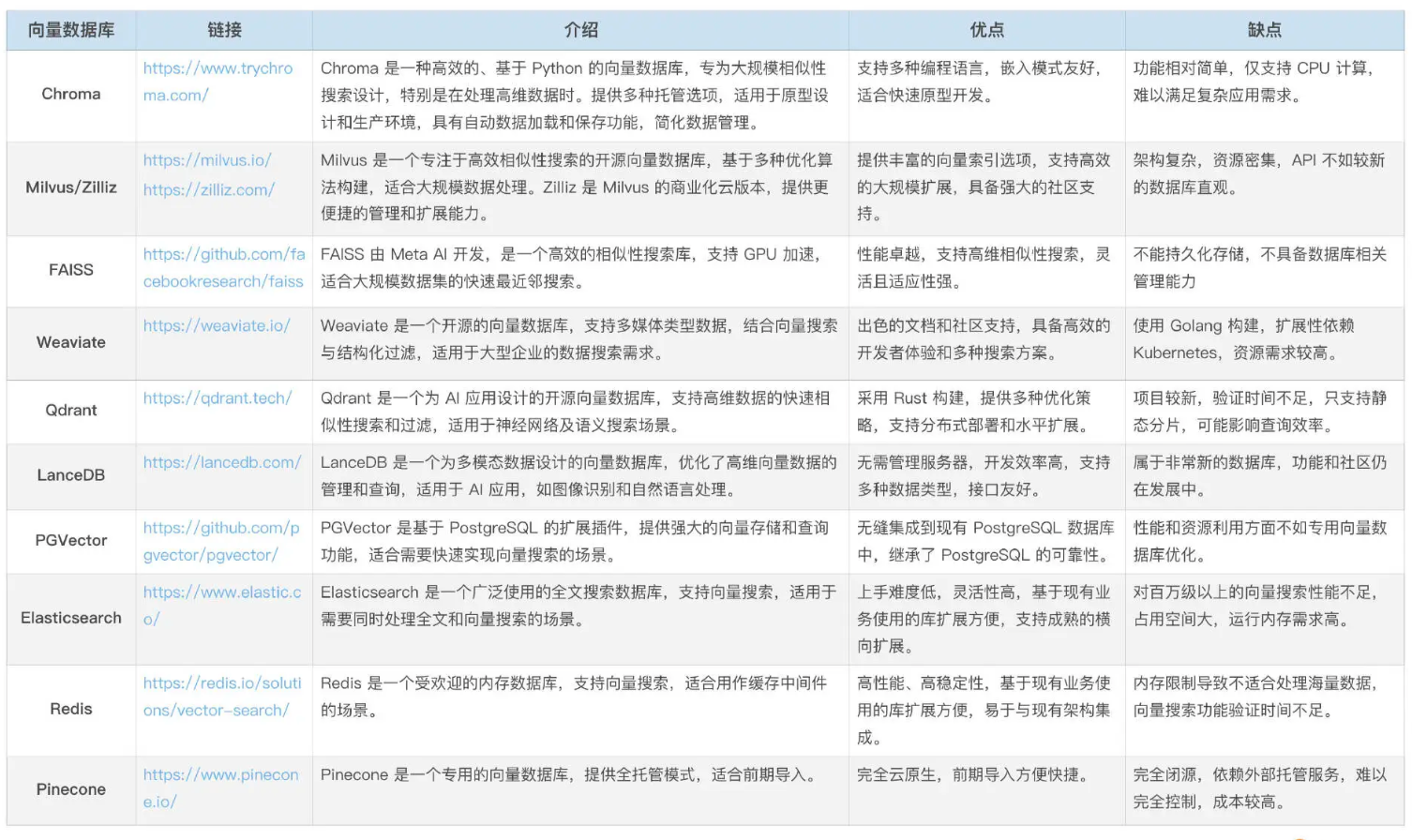
| 场景 | 选型 |
|---|---|
| 快速开发 + 轻量化部署 | Chroma / Qdrant |
| 高性能 + 可扩展性 | Milvus / Zilliz |
| 极致性能 + 无需持久化 + 无需数据管理 | FAISS |
| 多模态数据 | Weaviate / LanceDB |
| 集成现有数据库 | PGVector / Elasticsearch / Redis |
| 全托管 | Pinecone |
Chroma
- Chroma 是一种简单且易于持久化的向量数据库,以轻量级、开箱即用的特性著称
- Chroma 支持内存中操作和磁盘持久化,能够高效地管理和查询向量数据,非常适合快速集成和开发
Client + Collection
1 | # 创建ChromaDB本地存储实例和collection |
Indexing
1 | def indexing_process(folder_path, embedding_model, collection): |
Retrieval
1 | def retrieval_process(query, collection, embedding_model=None, top_k=6): |
Persistence
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2024-09-09
RAG - Qdrant
Features Getting StartedIntroduction Vector databases are a relatively new way for interacting with abstract data representations derived from opaque machine learning models such as deep learning architectures. These representations are often called vectors or embeddings and they are a compressed version of the data used to train a machine learning model to accomplish a task like sentiment analysis, speech recognition, object detection, and many others. What is Qdrant? Qdrant “is a vector similarity s...

2024-08-10
RAG - Chatbot
Fine-tuning vs RAG 核心诉求 - 实时更新知识库,不需要模型去深度探讨问题,使用已有知识经验去解答问题 Fine-tuning RAG 知识整合 直接把数据融入到模型参数 存储在外部知识库 知识更新 每次更新内容都需要重新训练模型,更新成本高 只需要在外部知识库插入记录,更新成本低 响应速度 很快,直接给出回答 现在外部知识库进行检索,然后再生成 实时更新 很难做到实时更新 外部知识库可以实时更新 人为干预 只能通过 Prompt 干预 可以通过外部知识库的语料和 Prompt 控制 领域定制 可以针对特定领域进行深度定制 依赖通用模型能力 适合使用 Fine-tuning 的场景 特定场景下的高一致性和定制化 数据量充足且稳定 训练 - 拥有高质量的对话原始数据 微调 - 基于现有对话数据做对话助手 强个性化需求 文言文的理解和输出 - 需要使用大量文言文语料微调后,才能满足需求 高速响应 Fine-tuning 能够直接输出有效内容,而 RAG 需要先检索再生成 LLM LLM 针对输入是有长度限制的,计量单位为 To...
2024-08-05
RAG - Document Parsing
文档解析 文档解析的本质 - 将格式各异、版本多样、元素多种的文档数据,转化为阅读顺序正确的字符串信息 Quality in, Quality out 是 LLM 的典型特征 高质量的文档解析能够从各种复杂格式的非结构化数据中提取出高精度信息 对 RAG 系统的最终效果起到决定性作用 RAG 系统的应用场景主要集中在专业领域和企业场景 除了数据库,更多的数据以 PDF、Word 等多种格式存储 PDF 文件有统一的排版和多样化的结构形式,是最为常见的文档数据格式和交换格式 Quality in, Quality out LangChainDocument Loaders LangChain 提供了一套功能强大的文档加载器(Document Loaders) LangChain 定义了 BaseLoader 类和 Document 类 BaseLoader - 定义如何从不同数据源加载文档 Document - 统一描述不同文档类型的元数据 开发者可以基于 BaseLoader 为特定数据源创建自定义加载器,将其内容加载为 Document 对象 Document Loader 模...
2024-08-06
RAG - Methodology
场景识别 分析业务流程,找出业务中依赖大量知识和信息处理的环节 复杂决策环节 在需要多维度信息综合分析与判断的业务流程中,RAG 可以为决策者提供实时的信息支持 使用 LLM 从各种来源的信息提炼出关键点,加权求和 - 压缩和整理非格式化信息 重复性内容生成 企业中有大量重复且标准化的内容生成任务 可以用程序去归纳流程,用 LLM 和 RAG 去填充每个环节 用户交互场景 增加自然语言交互 识别问题,找出流程痛点,并识别 LLM 和 RAG 能发挥的作用 信息碎片化 + 难以系统化输出 使用 LLM 和 RAG 能够通过自动化整合固定信息源,定期获取信息 统一整理(或生成)到统一的知识库,将分散的知识转化为结构化输出 人工处理效率低下 通过 LLM 自动化任务,可以更专注于更有创造力的工作 小步快跑 + 快速迭代 - LLM 技术变化极快 MVP Minimum viable product 数据驱动的迭代优化 持续收集用户行为数据和反馈,通过 A/B 测试等方法,不断优化系统表现

2024-08-09
RAG - Chunking + Embedding
概述 Chunking Documents 经过解析后,通过 Chunking 将信息内容划分为适当大小的 Chunks - 能够高效处理和精准检索 Chunk 的本质在于依据一定的逻辑和语义原则,将长文本拆解为更小的单元 Chunking 有多种策略,各有侧重,选择适合特定场景的 Chunking 策略,有助于提升 RAG 召回率 Embedding Embedding Model 负责将文本数据映射到高维向量空间,将输入的文档片段转换为对应的嵌入向量 嵌入向量捕捉了文本的语义信息,并存储到向量库中,以便于后续检索 Query 同样通过 Embedding Model 的处理生成 Query 的嵌入向量,在向量库中通过向量检索匹配最相似的文档片段 根据不同的场景,评估并选择最优的 Embedding Model,以确保 RAG 的检索性能符合要求 Chunking影响 Documents 包含丰富的上下文信息和复杂的语义结构 通过 Chunking,模型可以更有效地提取关键信息,并减少不相关内容的干扰 Chunking 的目标 确保每个片段在保留核心语义的同时,具备相对独立的语...
2024-08-15
RAG - Optimization + Evaluation
RAG 检索优化数据清洗和预处理 在 RAG 索引流程中,文档解析之后,文档切块之前,进行数据清洗和预处理 减少脏数据和噪音,提升文本的整体质量和信息密度 手段:清除冗余信息、统一格式、处理异常字符等 处理冗余的模板内容 消除文档中的额外空白和格式不一致 去除文档脚注、页眉页脚、版权信息 查询扩写 在 RAG 系统的检索步骤中,用户的查询会转换为向量后进行检索 单个向量查询只能覆盖向量空间中一个有限区域 如果查询中的嵌入向量未能包含所有关键信息,则可能检索到不相关的 Chunk 单点查询的局限性 - 限制系统在庞大文档库中的搜索范围,导致错失与查询语义相关的内容 查询扩写 通过 LLM 从原始查询语句生成多个语义相关的查询,可以覆盖向量空间中的不同区域 提高检索的全面性和准确性 扩写后的查询在被嵌入后,能够击中不同的语义区域 确保系统能够从更广泛的文档中检索到与用户需求相关的有用信息 通过查询扩写,原始问题被分解为多个子查询 每个子查询独立检索相关文档并生成相应的结果 系统将所有子查询的检索结果进行合并和重新排序 能够有效扩展用户的查询意图,确保在复杂信息库中进行更全面的文...




