
RAG - Hybrid retrieval + Rerank
向量检索
- 当前主流的 RAG 检索方式主要采用向量检索,通过语义相似度来匹配 Chunk
- 向量检索并非万能,在某些场景下无法替代传统关键词检索的优势
- 当需要精准搜索的时候,向量检索的准确性就往往不如关键词检索
- 当用户输入的问题非常简短,语义匹配的效果可能不尽理想
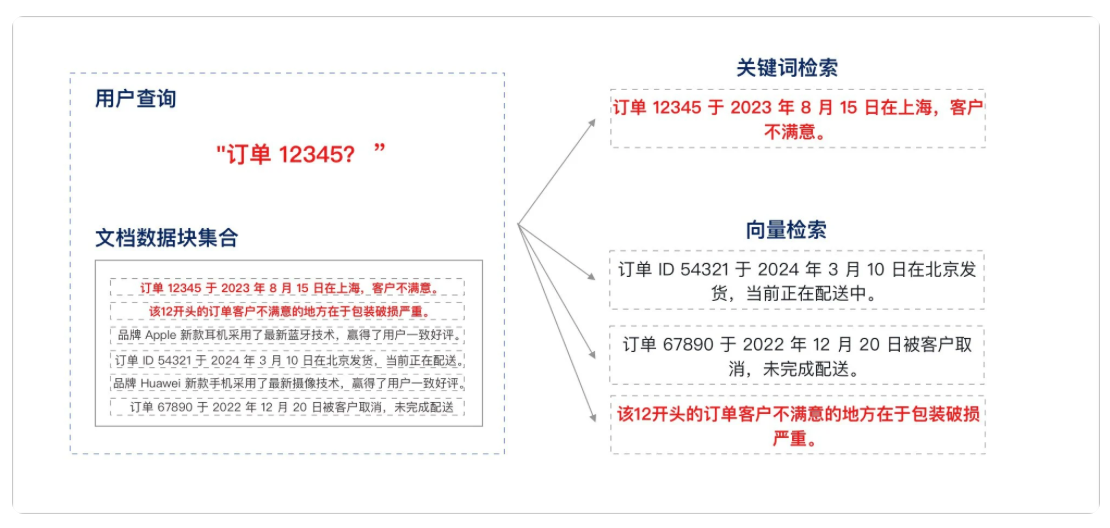
- 关键词检索的适用场景
- 精确匹配
- 少量字符的匹配 - 不适合用向量检索
- 低频词汇的匹配
混合检索
结合关键词检索和语义匹配的优势
- 在 RAG 检索场景中,首要目标是确保最相关的结果能够出现在候选列表中
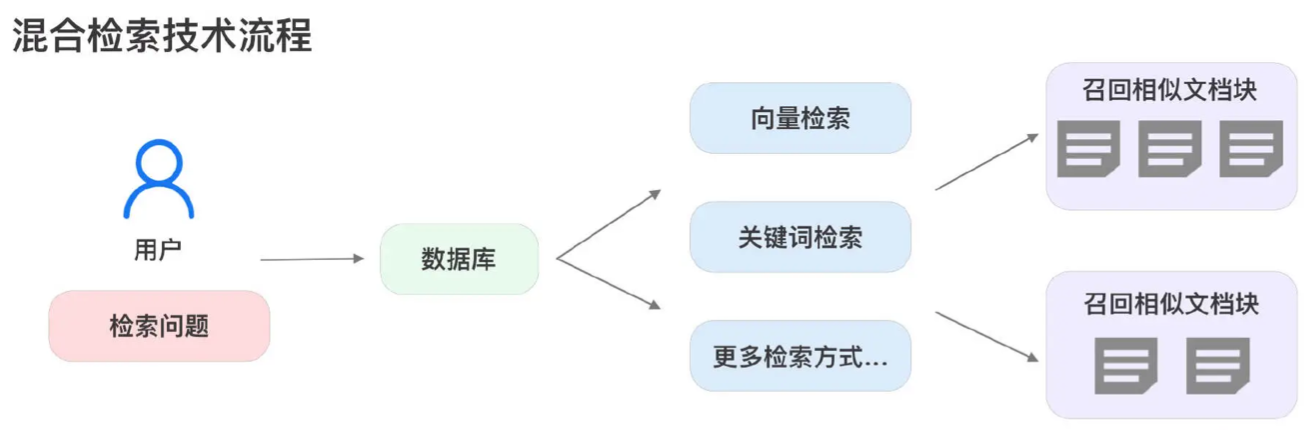
- 向量检索和关键词检索各具优势,混合检索通过结合多种检索技术,弥补各自不足,提供一种更加全面的搜索方案
- 重排序技术在检索系统中扮演着至关重要的角色
- 即使检索算法已经能够捕捉到所有相关的结果,重排序过程依然不可或缺
- 确保最符合用户意图和查询语义的结果优先展示,提升用户的搜索体验和结果的准确性
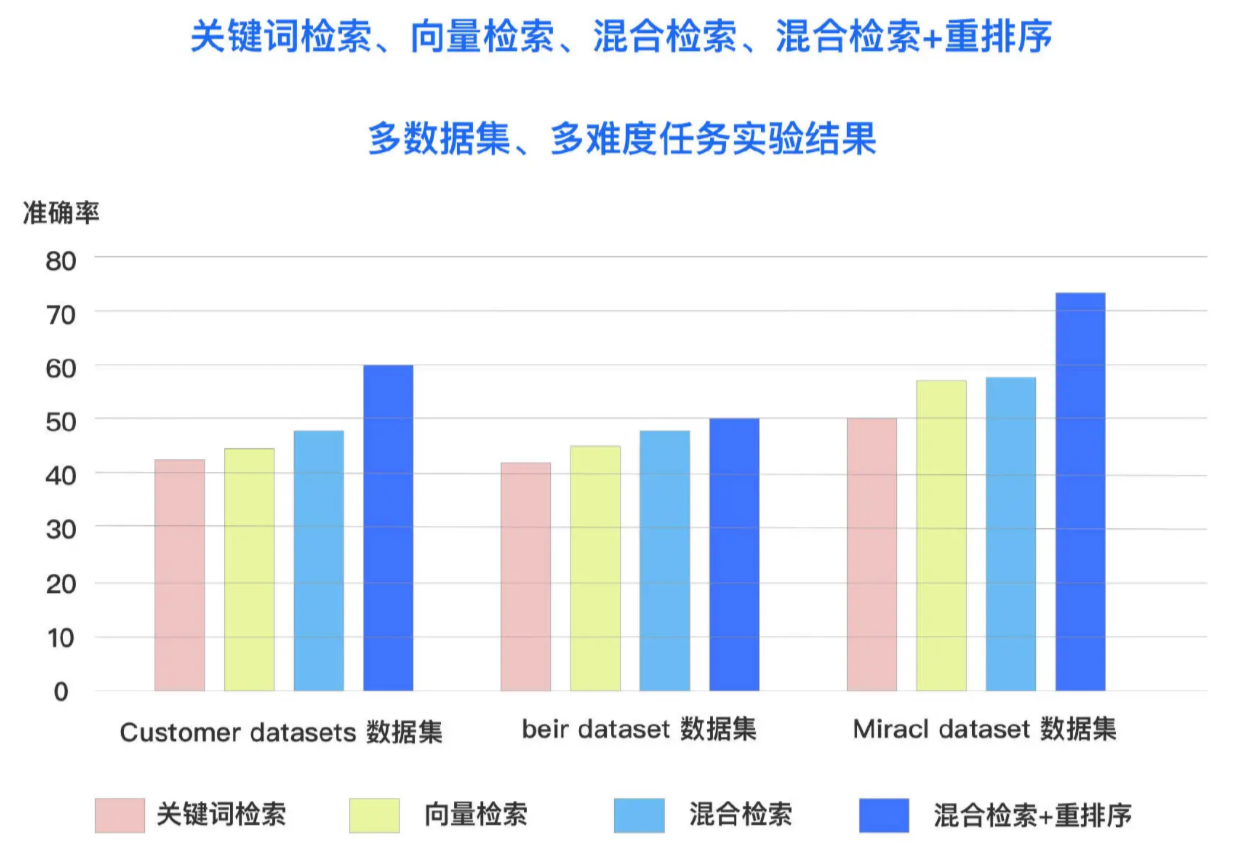
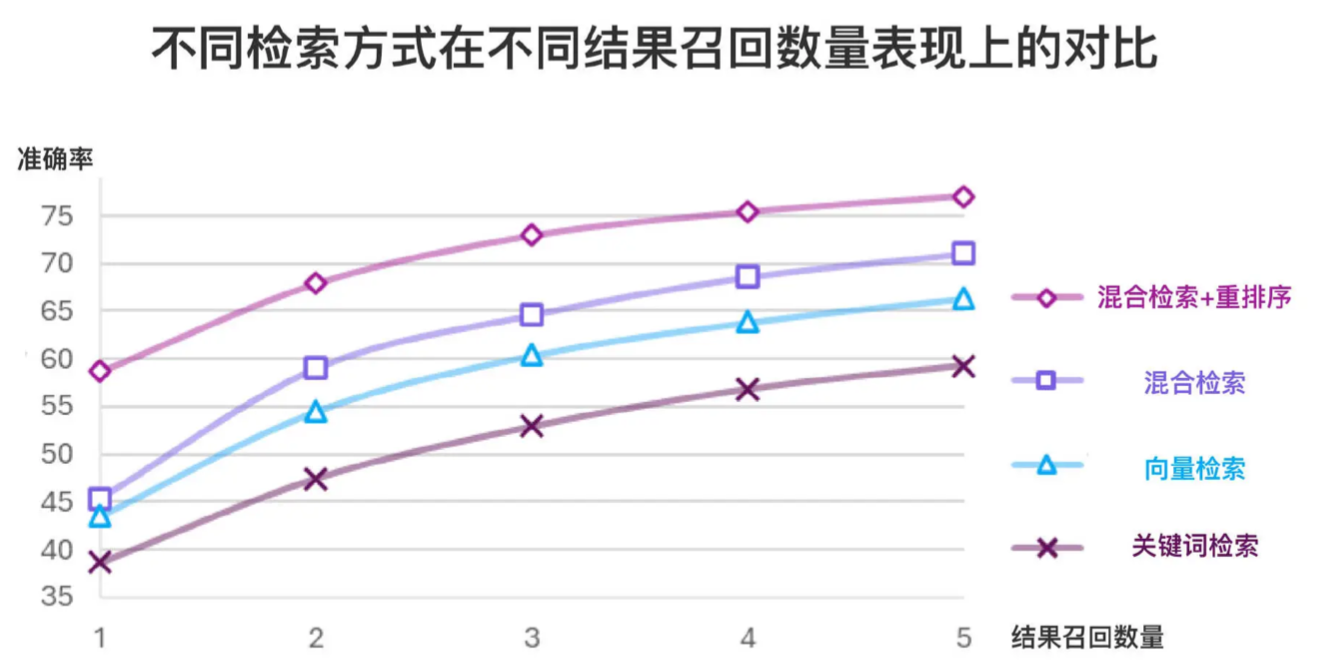
在多个数据集和多个检索任务中,混合检索和重排序的组合均取得了最佳表现
融合检索 / 多路召回
https://python.langchain.com/v0.2/api_reference/community/retrievers.html
| 检索方法 | 方法说明 |
|---|---|
| 向量检索 | 通过将文档转换为向量表示,利用向量之间的语义相似度检索,能够找到与查询语义最相近的内容 |
| 关键词检索 | 依赖于精确匹配文本中的关键词。适用于需要精确查找特定术语、短语或标识符的场景。 |
| 多重提问检索 - 问题扩写 | 通过生成多个与原始查询相关的问题,扩展检索范围,适用于查询不明确问题的情况 |
| 上下文压缩检索 | 先检索出大量相关文档,然后对其内容进行压缩,保留核心信息,以便 LLM 处理和理解 |
| 父文档检索 | 不仅检索文档片段,而是检索整个文档,适用于需要查看完整文档内容的场景,确保信息全面性 |
| 多向量检索 | 为每个文档创建多个向量表示,捕捉文档的不同特征,能够在检索中识别出文档多维度信息 |
| 自查询检索 - Self RAG | 理解并重构复杂查询,从而提高检索的精度,使检索结果更贴合用户意图 |
- 选择何种检索技术,取决于需要解决什么问题、系统的性能要求、数据的复杂性以及用户的搜索习惯等
- 针对具体需求选择合适的检索技术,能够最大化地提升 RAG 系统的效率和准确性
BM25
- BM25 是一种强大的关键词搜索算法
- 通过分析词频(TF)和逆向文档频率(IDF)来评估文档与查询的相关性
- BM25 检查查询词在文档中的出现频率,以及该词在所有文档中出现的稀有程度
- 如果一个词在特定文档中频繁出现,但在其他文档中较少出现 - 该文档高度相关
- BM25 还通过调整文档长度的影响,防止因文档长度不同而导致的词频偏差
- BM25 结合了词频和文档长度平衡的机制,使得 BM25 在关键词检索中能够提供精准的检索结果
重排序
概述
- 在 RAG 检索流程中,重排序技术通过对初始检索结果进行重新排序
- 改善检索结果的相关性,为 LLM 提供更优质的上下文,从而提升 RAG 系统的整体效果
- 尽管向量检索技术能够为每个 Chunk 生成初步的相关性分数,但引入重排序模型仍然至关重要
- 向量检索主要依赖于全局语义相似性
- 通过将查询和文档映射到高维语义空间进行匹配
- 往往忽略了查询与文档具体内容之间的细粒度交互
- 重排序模型大多基于双塔或交叉编码架构的模型
- 在此基础上进一步计算更加精确的相关性分数
- 能够捕捉词与 Chunk 之间更细致的相关性,从而在细节层面上提高检索精度
- 向量检索提供了有效的初步筛选,重排序模型则通过更深入的分析和排序
- 确保最终结果在语义和内容层面上更紧密地契合查询意图,实现检索质量的提升
- RAG 流程有两个概念:粗排 + 精排
- 粗排 - 检索效率高,但召回的内容不一定强相关
- 精排 - 效率较低,适合在粗排的基础上进一步优化,代表技术为重排序
优势
- 优化检索结果
- 在 RAG 系统中,初始的检索结果通常来自于向量检索或基于关键词的检索方法
- 初始的检索结果可能包含大量的冗余信息或与查询完全不相关的文档
- 通过重排序技术,可以对初步检索到的文档进行进一步的筛选和排序,将最相关、最重要的文档至于前列
- 增强上下文相关性
- RAG 系统依赖于检索到的文档作为 LLM 的上下文 - 直接影响生成结果
- 重排序技术通过重新评估文档与查询的相关性,确保 LLM 优先使用那些与查询最相关的文档
- 应对复杂查询
- 对于复杂查询,初始检索可能会返回一些与表面上相关但实际上不太匹配的文档
- 重排序技术可以根据查询的复杂性和具体需求,对这些结果进行更细致的分析和排序
RRF
Reciprocal Rank Fusion - 递归折减融合
- RRF 是一种把来自不同检索方法的排名结果结合起来的技巧
- 基本思想:如果一个文档在不同的检索结果中都排名比较靠前,那么它在综合排名中应该得到更高的位置
- 相比于复杂的重排序技术,RRF 的操作更加简单,不需要对每种检索结果进行复杂的调整或计算
- 通过直接考虑文档在不同方法中的排名,快速生成一个合理的综合排名
- 非常适合那些需要快速融合多个检索结果的场景,短时间内得到一个有参考价值的排序
模型
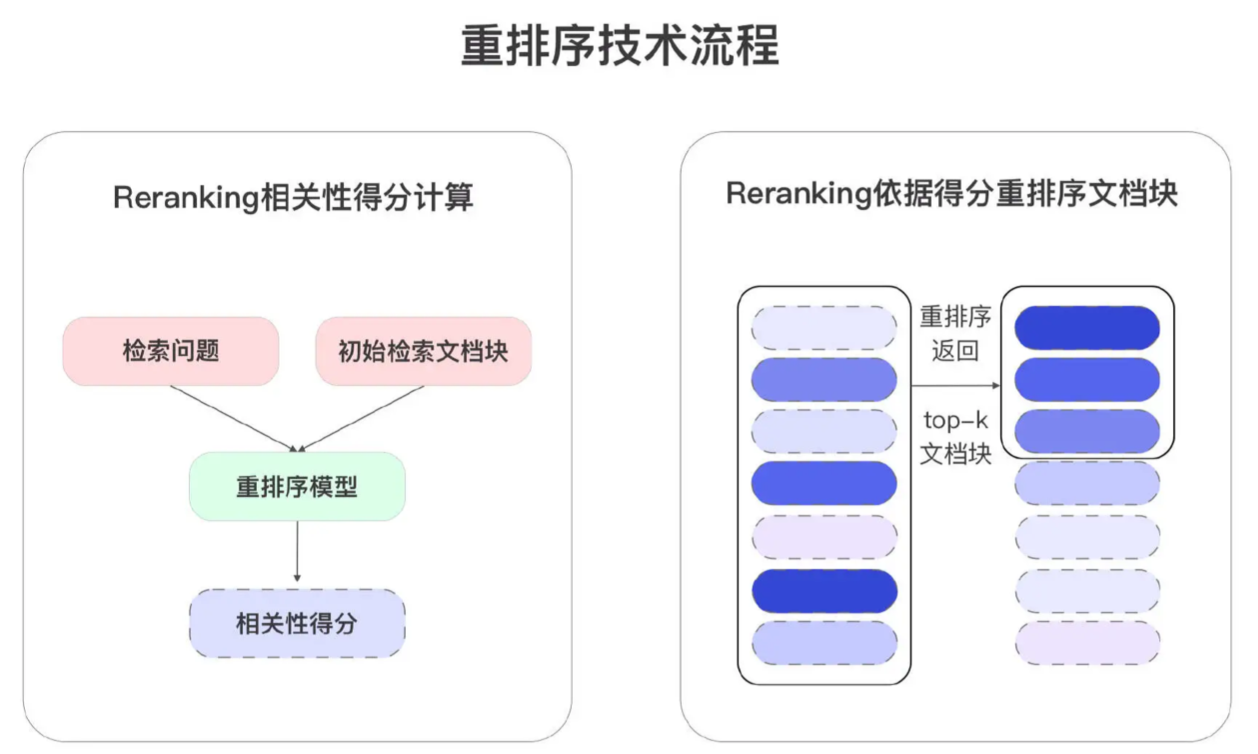
- Query 与每个 Chunk 计算对应的相关性分数,并根据这些分数对文档进行重新排序
- 市面上可用的重排序模型并不多
- 商用 - Cohere
- 开源 - BGE、Sentence、Mixedbread、T5-Reranker、BCE
- 甚至可以使用 Prompt 让 LLM 进行重排
- 在生产环境中使用重排序模型会面临资源和效率问题
- 计算资源消耗高 + 推理速度慢 + 模型参数量大
- 重排序模型在对候选项进行精细排序时,因其较大参数量而导致的高计算需求和复杂耗时的推理过程
- 从而对 RAG 系统的响应时间和整体效率产生负面影响
- 在实际应用中,要根据实际资源需求,在精度和效率之间进行平衡
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2024-08-03
RAG - In Action
技术选型LangChain LangChain 是专门为开发基于 LLM 应用而设计的全面框架 LangChain 的核心目标是简化开发者的构建流程,使其能够高效地创建 LLM 驱动的应用 索引文档解析 pypdf 专门用于处理 PDF 文档 pypdf 支持 PDF 文档的创建、读取、编辑和转换,能够有效地提取和处理文本、图像及页面内容 文档分块 RecursiveCharacterTextSplitter 是 LangChain 默认的文本分割器 RecursiveCharacterTextSplitter 通过层次化的分隔符(从双换行符到单字符)拆分文本 旨在保持文本的结构和连贯性,优先考虑自然边界(如段落和句子) 索引 + 检索向量化模型 bge-small-zh-v1.5 是由北京智源人工智能研究院(BAAI)开发的开源向量模型 bge-small-zh-v1.5 的模型体积较小,但仍能提供高精度和高效的中文向量检索 bge-small-zh-v1.5 的向量维度为 512,最大输入长度同样为 512 向量库 Faiss - Facebook AI Similarity Sea...
2024-08-07
RAG - Data Processing
数据存储 LLM 变成生产力,有两个制约因素 - 交互过程中的长文本 + 内容的实时更新 在传统的应用开发中,数据存储在数据库中,保留了应用的全部记忆 在 AI 时代,向量数据库充当了这一角色 在 RAG 系统中,数据被转换为高维向量形式,使得语言模型能够进行高效的语义相似度计算和检索 在向量数据库中,查找变成了计算每条记录的向量近似度,然后按照分值倒序返回结果 RAG 就如何存储向量的方法论,根据不同的实现策略,衍生出了不同的 RAG 技术 利用图结构表示和检索知识的 GraphRAG 结合知识图谱增强生成能力的 KG-RAG - Knowledge Graph Augmented Generation AI 应用的数据建模强调的是数据的语义表示和关联,以支持更灵活的查询和推理 高质量的数据处理,不仅影响检索的准确性,还直接决定了 LLM 生成内容的质量和可靠性 Embedding 将所有内容转成文本 + 额外数据(用来关联数据) 选择一个 Embedding 模型,把文本转成向量,并存储到向量数据库中 厂商 LLM Embedding 国产 百度 文心一言 Embeddi...
2024-06-30
LLM RAG - ChatGLM3-6B + LangChain + Faiss
RAG 使用知识库,用来增强 LLM 信息检索的能力 知识准确 先把知识进行向量化,存储到向量数据库中 使用的时候通过向量检索从向量数据库中将知识检索出来,确保知识的准确性 更新频率快 当发现知识库里面的知识不全时,可以随时补充 不需要像微调一样,重新跑微调任务、验证结果、重新部署等 应用场景 ChatOps 知识库模式适用于相对固定的场景做推理 如企业内部使用的员工小助手,不需要太多的逻辑推理 使用知识库模式检索精度高,且可以随时更新 LLM 基础能力 + Agent 进行堆叠,可以产生智能化的效果 LangChain-Chatchat组成模块 模块 作用 支持列表 大语言模型 智能体核心引擎 ChatGLM / Qwen / Baichuan / LLaMa Embedding 模型 文本向量化 m3e-* / bge-* 分词器 按照规则将句子分成短句或者单词 LangChain Text Splitter 向量数据库 向量化数据存储 Faiss / Milvus Agent Tools 调用第三方...
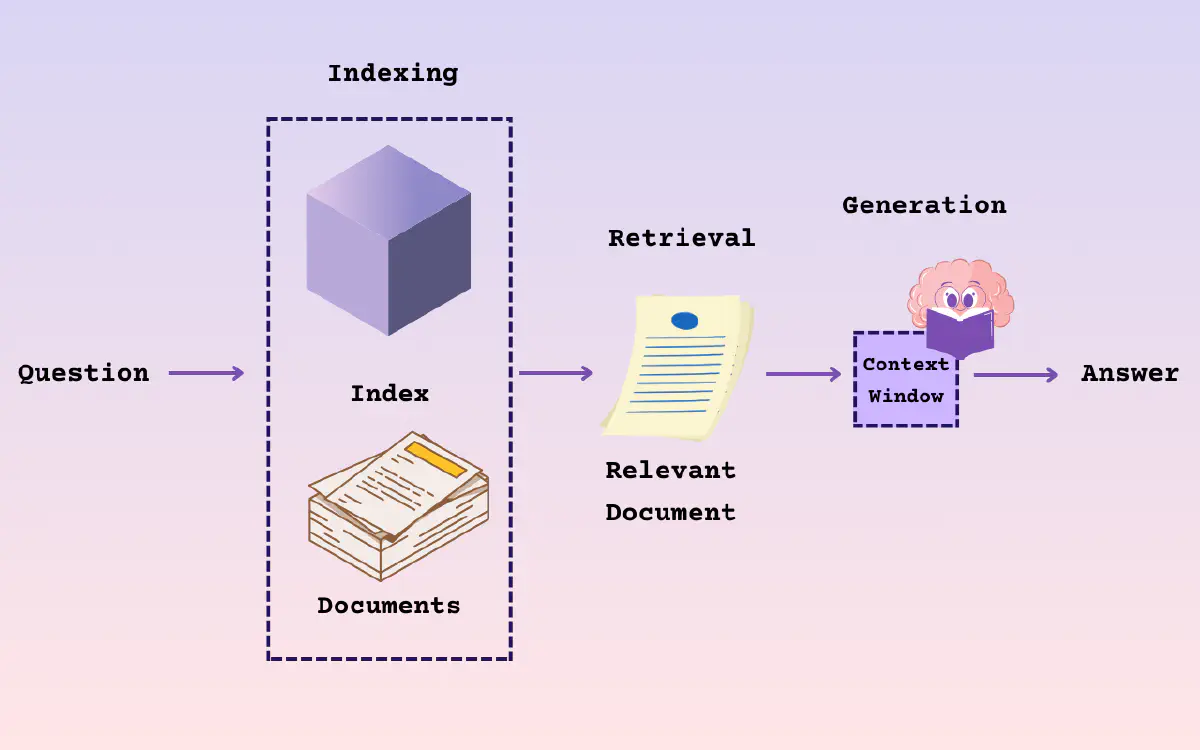
2024-08-05
RAG - Document Parsing
文档解析 文档解析的本质 - 将格式各异、版本多样、元素多种的文档数据,转化为阅读顺序正确的字符串信息 Quality in, Quality out 是 LLM 的典型特征 高质量的文档解析能够从各种复杂格式的非结构化数据中提取出高精度信息 对 RAG 系统的最终效果起到决定性作用 RAG 系统的应用场景主要集中在专业领域和企业场景 除了数据库,更多的数据以 PDF、Word 等多种格式存储 PDF 文件有统一的排版和多样化的结构形式,是最为常见的文档数据格式和交换格式 Quality in, Quality out LangChainDocument Loaders LangChain 提供了一套功能强大的文档加载器(Document Loaders) LangChain 定义了 BaseLoader 类和 Document 类 BaseLoader - 定义如何从不同数据源加载文档 Document - 统一描述不同文档类型的元数据 开发者可以基于 BaseLoader 为特定数据源创建自定义加载器,将其内容加载为 Document 对象 Document Loader 模...

2024-08-09
RAG - Chunking + Embedding
概述 Chunking Documents 经过解析后,通过 Chunking 将信息内容划分为适当大小的 Chunks - 能够高效处理和精准检索 Chunk 的本质在于依据一定的逻辑和语义原则,将长文本拆解为更小的单元 Chunking 有多种策略,各有侧重,选择适合特定场景的 Chunking 策略,有助于提升 RAG 召回率 Embedding Embedding Model 负责将文本数据映射到高维向量空间,将输入的文档片段转换为对应的嵌入向量 嵌入向量捕捉了文本的语义信息,并存储到向量库中,以便于后续检索 Query 同样通过 Embedding Model 的处理生成 Query 的嵌入向量,在向量库中通过向量检索匹配最相似的文档片段 根据不同的场景,评估并选择最优的 Embedding Model,以确保 RAG 的检索性能符合要求 Chunking影响 Documents 包含丰富的上下文信息和复杂的语义结构 通过 Chunking,模型可以更有效地提取关键信息,并减少不相关内容的干扰 Chunking 的目标 确保每个片段在保留核心语义的同时,具备相对独立的语...

2024-08-08
RAG - Frameworks
Overview Retrieval-Augmented Generation (RAG) is an AI framework that enhances the capabilities of large language models (LLMs) by incorporating external knowledge sources. It helps overcome limitations such as knowledge cutoff dates and reduces the risk of hallucinations in LLM outputs. RAG works by retrieving relevant information from a knowledge base and using it to augment the LLM’s input, allowing the model to generate more accurate, up-to-date, and contextually relevant responses. Haystack Hays...




