
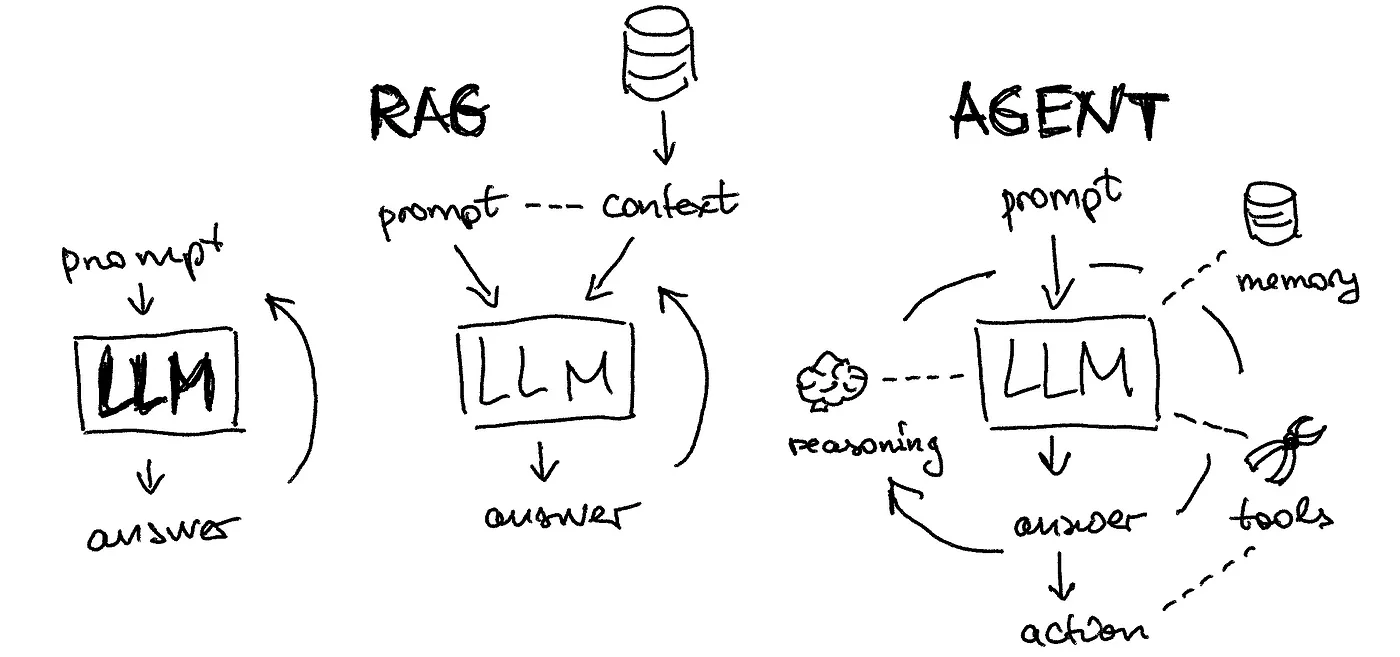
RAG - LLM + Prompt Engineering
RAG 生成流程
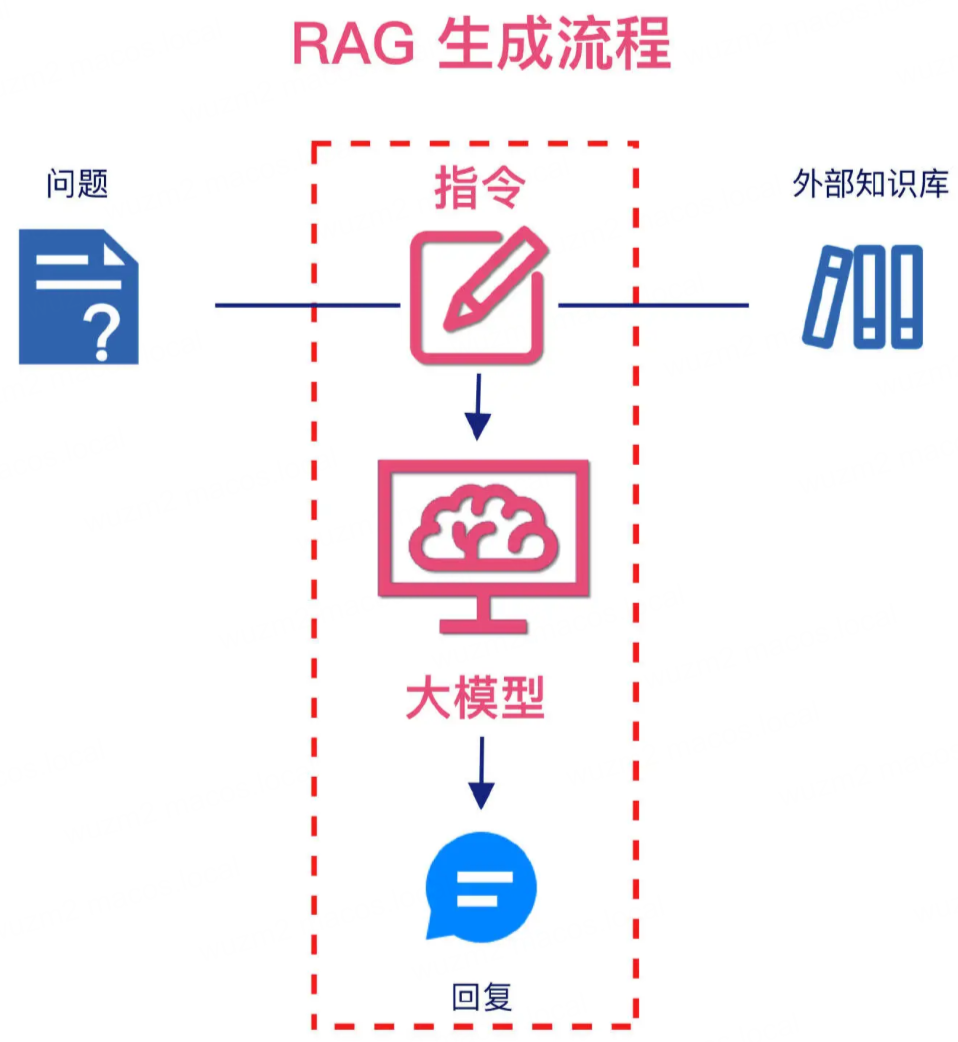
- 经过 RAG 索引流程(外部知识的解析和向量化)和 RAG 检索流程(语义相似性的匹配及混合检索),进入到 RAG 生成流程
- 在 RAG 生成流程中,需要组合指令,即携带查询问题及检索到的相关信息输入的 LLM,由 LLM 理解并生成最终的回复
- RAG 的本质是通过 LLM 提供外部知识来增强其理解和回答领域问题的能力
- LLM 在 RAG 系统中起到了大脑的作用
- 在面对复杂且多样化的 RAG 任务时,LLM 的性能直接决定了系统的整体效果
- 提示词工程是生成流程中的另一个关键环节
- 通过有效的指令的设计和组合,可以帮助 LLM 更好地理解输入内容,从而生成更加精确和相关的回答
- 精心设计的问题提示词,往往能提升生成效果
LLM
发展

RAG 目前更关注通用大模型
原理
- Google 于 2017 年发布论文 Attention Is All You Need,引入了 Transformer 模型
- Transformer 模型是深度学习领域的一个突破性架构,LLM 的成功得益于对 Transformer 模型的应用
- 与传统的 RNN(循环神经网络) 相比,Transformer 模型不依赖于序列顺序
- 通过自注意力(Self-Attention)机制来捕捉序列中各元素之间的关系
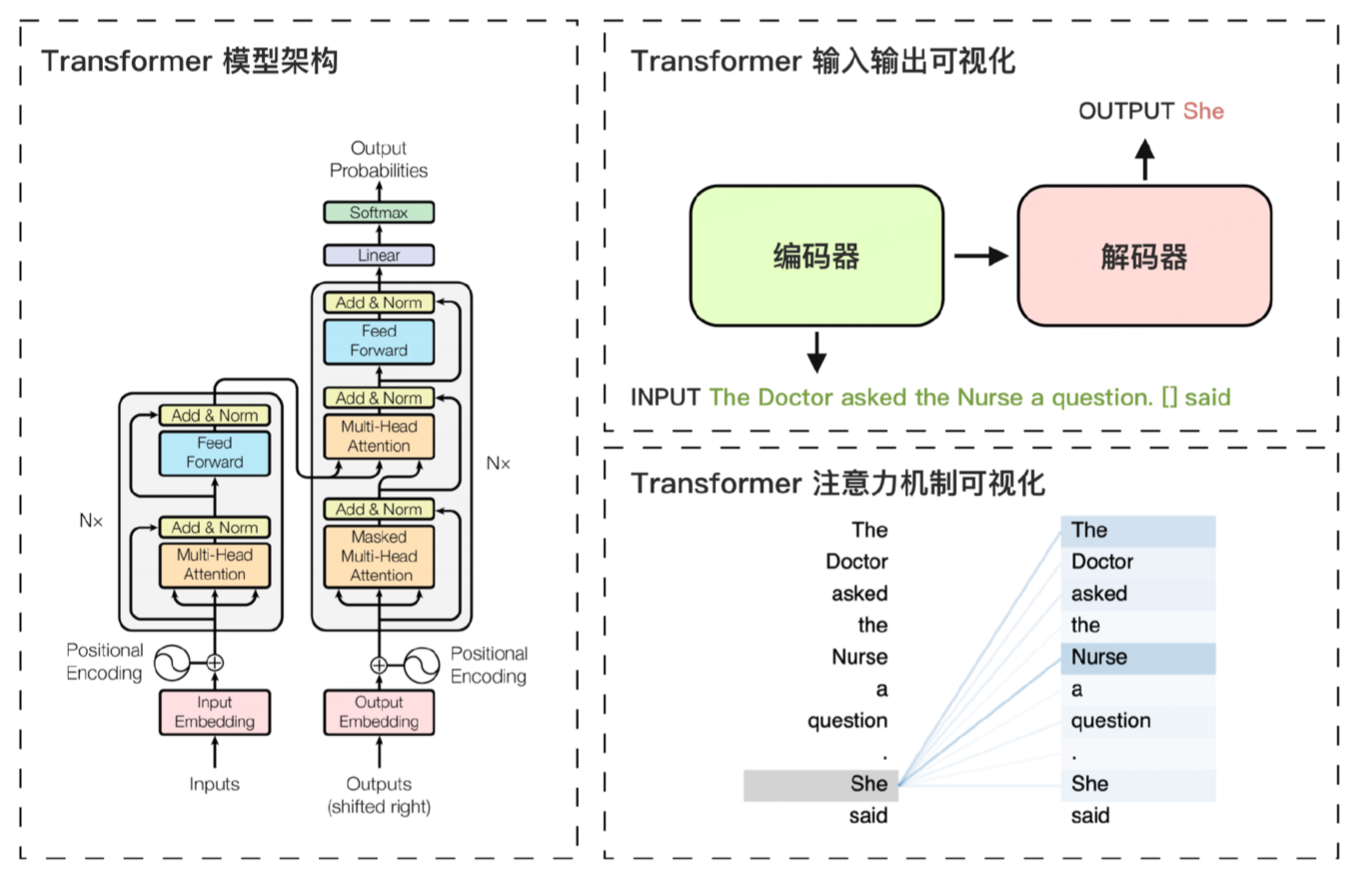
- Transformer 由多个堆叠的编码层(Encoder)和解码层(Decoder)组成
- 每一层包括自注意力层、前馈层和归一化层
- 这些层协同工作,逐步捕捉输入数据信息特征,从而预测输出,实现强大的语言理解和生成能力
- Transformer 模型的核心创新 - 位置编码 + 自注意力机制
- 位置编码
- 帮助模型理解输入数据的顺序信息
- 自注意力机制
- 允许模型根据输入的全局上下文,为每个 Token 分配不同的注意力权重
- 从而更准确地理解词与词之间的关联性
- 位置编码
- Transformer 特别适用于语言模型
- 语言模型需要精确捕捉上下文中的细微差别,生成符合语义逻辑的文本
编码器负责理解输入信息的顺序和语义,而解码器则输出概率最高的 Token
- LLM 的突破始于 OpenAI 于 2022 年底发布的 ChatGPT
- 核心优势
- 庞大的参数规模 + 基于 PB 级别数据的训练所带来的卓越语言理解和生成能力 + 显著的涌现能力
- LLM 不仅在传统的 NLP 处理任务中展现了卓越表现,还具备解决复杂问题和进行逻辑推理等高级认知能力
- 基于 Transformer 模型预测下一个 Token 的原理
- LLM 在分析海量的语料库后,能够在逻辑上精准补全不完整的句子,甚至生成新的句子
- 赋予了 LLM 生成连贯且上下文相关的文本的能力,适用于文本生成、翻译、问答系统等多个领域
选型
测评
SuperCLUE:中文通用大模型综合性测评基准
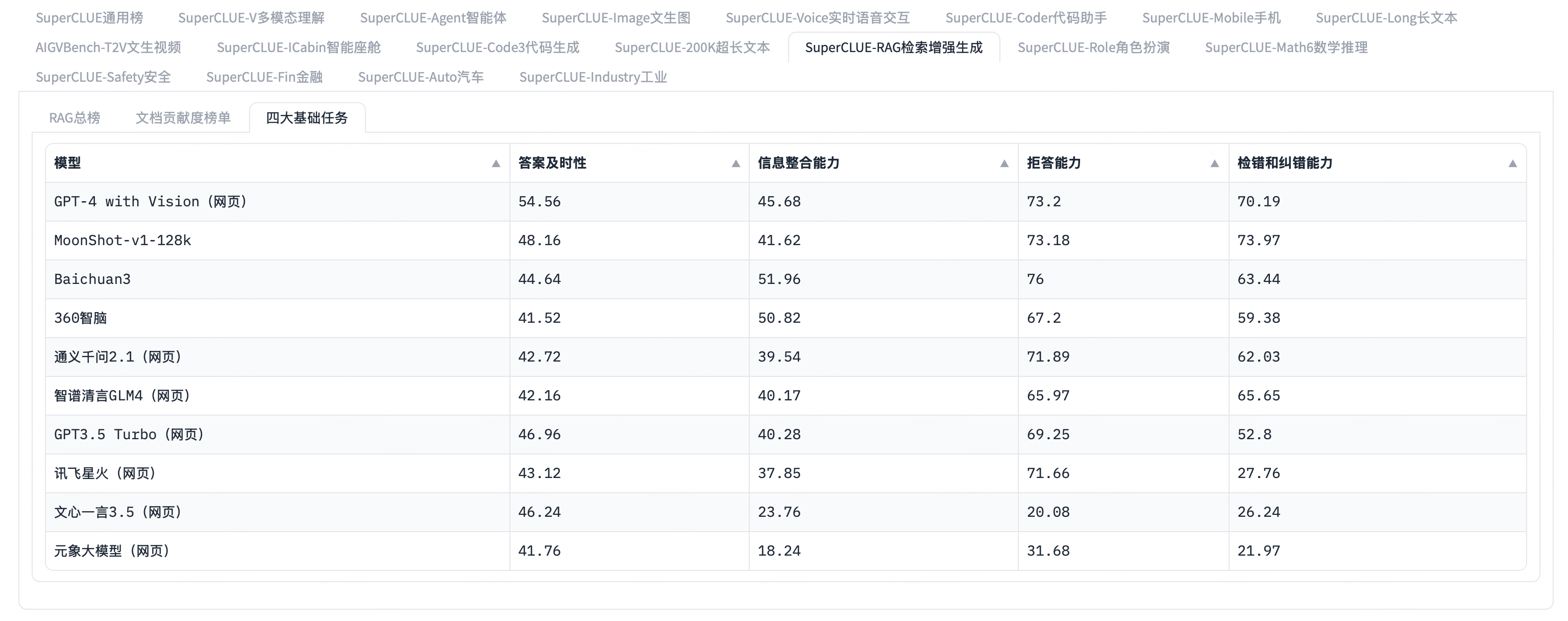
- 在 RAG 场景中,LLM 的检索能力表现是核心
- SuperCLUE 针对 RAG 应用场景进行了独立测试,具体评估了检索和生成过程中的表现
维度
开源 vs 闭源
- 开源模型适用于数据敏感性高或者有严格合规要求的场景,通过自托管实现对数据的完全掌控,确保隐私与安全
- 闭源模型适用于数据敏感度较低的应用场景,其维护和服务相对完善,降低运维复杂度
模型参数规模
- 大参数模型在复杂任务中的推理和生成能力较强,但并非所有应用场景都需要高精度模型
- 小参数模型(7B)在满足简单逻辑任务时,具备更优的响应速度、成本控制和资源利用效率
国内部署 vs 国外部署
- 稳定性、网络延迟、充值付费等
- 数据合规
推荐
闭源
- 通义千问、文心一言、腾讯混元、字节豆包、Kimi Chat
- 参数量较高,在 RAG 场景的实际表现差异较少,主要取决于成本
开源
| 系列 | 特点 |
|---|---|
| Qwen | 在长上下文处理上表现出色,非常适合需要深度语义理解的 RAG 任务 |
| Baichuan | 在数学和编码任务中表现卓越,在安全性方面经过深入评估 |
| ChatGLM | 适用于长文本检索和生成 |
Prompt Engineering
概念
- Prompt Engineering 是为生成式 AI 模型设计输入以获得最佳输出的实践
- 输入即 Prompt,而编写 Prompt 的过程即 Prompt Engineering
- 核心理念 - 通过提供更优质的输入,让生成式 AI 模型(如 LLM)生成更符合需求的结果
- Prompt Engineering 通过开发和优化 Prompt 来有效利用 LLM 的潜力
- Prompt 工程师的任务不仅仅是设计提示
- 而是通深入理解模型的功能和局限性,创造能够与模型输入产生最佳互动的 Prompt
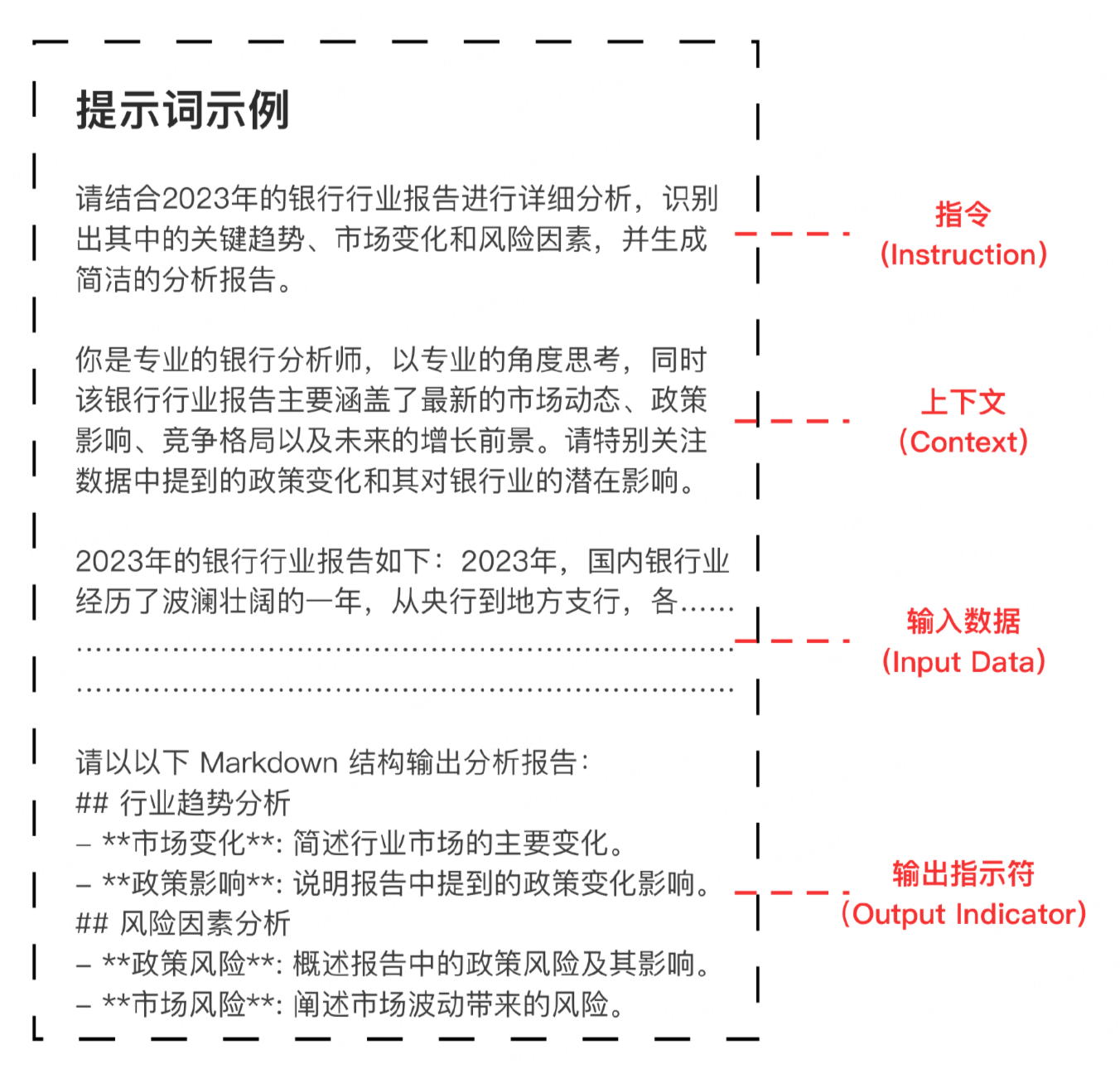
元素
Prompt 组成元素
| 元素 | 描述 |
|---|---|
| Instruction | 指示模型要执行的特定任务或者操作 |
| Context | 为模型提供额外信息或背景,帮助引导模型生成更准确的响应 |
| Input Data | 希望模型回答的问题或者感兴趣的输入内容 |
| Output Indicator | 指示模型的输出类型或格式 |
技巧
RAG 中的 Prompt Engineering 技巧 - 高效低成本地提升输出质量
具体指令
- 向 LLM 提供具体清晰的指令,能够提高输出的准确性
- 模糊的指令往往导致模型生成不理想的结果
1 | 请根据上传的银行业报告,简洁总结当前的市场趋势,重点分析政策变化对行业的影响,输出为以下Markdown格式: |
示例学习
- 通过给模型提供多个参考示例,模型可以进行模式识别,进而模仿、思考并生成类似的答案
- 无需对模型进行进一步训练,有效提升模型的输出质量
1 | 以下是两个关于银行业的分析示例,请按照这种格式对新的报告进行分析: |
默认回复
- 当模型无法从文档中获取足够信息时,通过设定默认回复策略,避免模型产生幻觉(虚假答案)
- 确保模型仅基于文档中的事实进行回答
1 | 如果文档中没有足够的事实回答问题,请返回{无法从文档中获得相关内容},而不是进行推测。 |
角色设定
- 为模型设定特定的角色身份,可以帮助模型更好地理解任务要求和角色责任,输出更加一致的内容
1 | 你的角色: 知识库专家 |
解释理由
- 在编写 Prompt 时,向模型解释为什么某些任务需要特定的处理方式
- 可以帮助模型更好地理解任务背景,从而提高输出的质量和相关性
1 | 请生成一份简明扼要的银行业报告摘要,不要逐字重复段落内容。原因:读者可以访问完整文档,如果需要可以详细阅读全文。 |
基础说明
- 为模型提供文档的背景信息和文本来源可以奠定任务基础,让模型更好地进行任务推理和回答
1 | 以下是关于银行业政策变化的相关规则,它们将用于回答有关政策对银行业影响的问题。 |
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2024-08-12
RAG - Vector Stores
Embedding Vector Store概述 在 AI 时代,文字、图像、语音、视频等多模态数据的复杂性显著增加 多模态数据具有非结构化和多维特征 向量表示能够有效表示语义和捕捉潜在的语义关系 促使向量数据库成为存储、检索和分析高维向量的关键工具 Qdrant / Milvus 优势 SQL vs NoSQL 传统数据库通常分为关系型(SQL)数据库和非关系型(NoSQL)数据库 存储复杂、非结构化或半结构化信息的需求,主要依赖于 NoSQL 的能力 Store Desc Note Key-Value 用于简单的数据存储,通过 Key 来快速访问数据 精准定位信息 Document 用于存储文档结构的数据,如 JSON 格式 复杂的结构化信息 Graph 用于表示和存储复杂的关系数据,常用于社交网络、推荐等场景 复杂的关系数据 Vector 用于存储和检索基于向量表示的数据,用于 AI 模型的高维度和复杂的嵌入向量 语义最相关的数据 向量数据库的核心在于能够基于向量之间的相似性,能够快速、精确地定位和检索数据 向量数据库不仅为嵌入向量提供了...
2024-08-04
RAG - LangChain
Practice LangChain RAG https://github.com/langchain-ai/rag-from-scratch RAG 如何随着长期 LLM 而改变 Is RAG Really Dead? https://www.youtube.com/watch?v=SsHUNfhF32s 自适应 RAG 根据复杂程度动态地将查询路由到不同的 RAG 方法 - Command-R @ LangGraph Adaptive RAG https://www.youtube.com/watch?v=04ighIjMcAI Code https://github.com/langchain-ai/langgraph/blob/main/examples/rag/langgraph_adaptive_rag_cohere.ipynb Paper https://arxiv.org/abs/2403.14403 Adaptive RAG 在循环单元测试中自我纠正检索错误,以确定文档相关性并返回到网络搜索 在 LangGraph 中实现 Mistral 7B + Ol...
2024-08-13
RAG - Hybrid retrieval + Rerank
向量检索 当前主流的 RAG 检索方式主要采用向量检索,通过语义相似度来匹配 Chunk 向量检索并非万能,在某些场景下无法替代传统关键词检索的优势 当需要精准搜索的时候,向量检索的准确性就往往不如关键词检索 当用户输入的问题非常简短,语义匹配的效果可能不尽理想 关键词检索的适用场景 精确匹配 少量字符的匹配 - 不适合用向量检索 低频词汇的匹配 混合检索 结合关键词检索和语义匹配的优势 在 RAG 检索场景中,首要目标是确保最相关的结果能够出现在候选列表中 向量检索和关键词检索各具优势,混合检索通过结合多种检索技术,弥补各自不足,提供一种更加全面的搜索方案 重排序技术在检索系统中扮演着至关重要的角色 即使检索算法已经能够捕捉到所有相关的结果,重排序过程依然不可或缺 确保最符合用户意图和查询语义的结果优先展示,提升用户的搜索体验和结果的准确性 在多个数据集和多个检索任务中,混合检索和重排序的组合均取得了最佳表现 融合检索 / 多路召回 https://python.langchain.com/v0.2/api_reference/community/r...
2024-08-05
RAG - Document Parsing
文档解析 文档解析的本质 - 将格式各异、版本多样、元素多种的文档数据,转化为阅读顺序正确的字符串信息 Quality in, Quality out 是 LLM 的典型特征 高质量的文档解析能够从各种复杂格式的非结构化数据中提取出高精度信息 对 RAG 系统的最终效果起到决定性作用 RAG 系统的应用场景主要集中在专业领域和企业场景 除了数据库,更多的数据以 PDF、Word 等多种格式存储 PDF 文件有统一的排版和多样化的结构形式,是最为常见的文档数据格式和交换格式 Quality in, Quality out LangChainDocument Loaders LangChain 提供了一套功能强大的文档加载器(Document Loaders) LangChain 定义了 BaseLoader 类和 Document 类 BaseLoader - 定义如何从不同数据源加载文档 Document - 统一描述不同文档类型的元数据 开发者可以基于 BaseLoader 为特定数据源创建自定义加载器,将其内容加载为 Document 对象 Document Loader 模...
2024-08-01
RAG - AI 2.0
AI 技术 做 AI 产品的工程研发需充分掌握 AI 技术 AI 产品从 MVP 到 PMF 的演进过程中会面临非常多的挑战 MVP - Minimum Viable Product - 最小可用产品 PMF - Product-Market Fit - 产品市场契合 要实现 AI 产品的 PMF 首先需要充分了解 AI 技术,明确技术边界,找到合适 AI 技术的应用场景 其次,需要深刻理解业务,用户需求决定产品方向,AI 技术是为业务服务的工具 在验证阶段,优先使用最佳 AI 模型以确保产品满足市场需求,确认后再逐步降低模型成本 坚持业务优先、价值至上的原则,避免纯 AI 科研化,脱离实际场景做 AI 技术选型 RAG LLM 局限 - 幻觉 + 知识实效性 + 领域知识不足 + 数据安全问题 由 OpenAI ChatGPT 引领的 AI 2.0 LLM 时代,见证了 LLM 在知识、逻辑、推理能力上的突破 Scaling Law、压缩产生智能、边际成本为零为理想中的 AGI 尽管 LLM 功能强大,但仍存在幻觉、知识实效性、领域知识不足以及数据安全问题的局限性 - RAG 文档问...
2024-09-09
RAG - Qdrant
Features Getting StartedIntroduction Vector databases are a relatively new way for interacting with abstract data representations derived from opaque machine learning models such as deep learning architectures. These representations are often called vectors or embeddings and they are a compressed version of the data used to train a machine learning model to accomplish a task like sentiment analysis, speech recognition, object detection, and many others. What is Qdrant? Qdrant “is a vector similarity s...




