
RAG - Evolution
演进
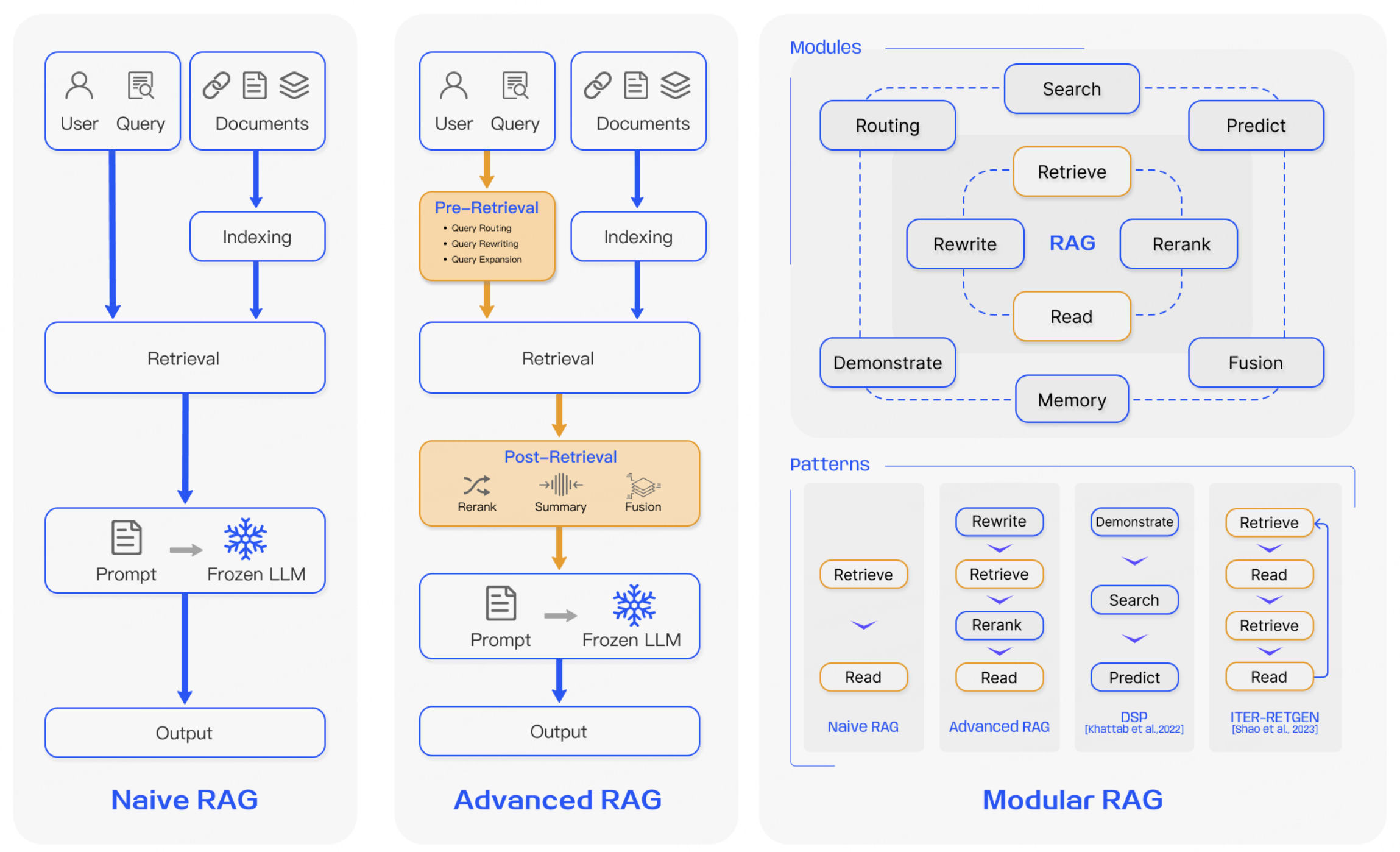
- Naive RAG -> Advanced RAG -> Modular RAG
- 三个范式之间具有继承与发展的关系
- Advanced RAG 是 Modular RAG 的一种特例形式
- Naive RAG 是 Advanced RAG 的基础特例
- RAG 技术不断演进,以适应更复杂的任务和场景需求
Naive RAG
- Naive RAG 是最基础的形式,依赖核心的索引和检索策略来增强生成模型的输出
- Naive RAG 适用于一些基础任务和产品 MVP 阶段
Advanced RAG
通过增加检索前、检索中以及检索后的优化策略,提高检索的准确性和生成的关联性 - 适用于复杂任务
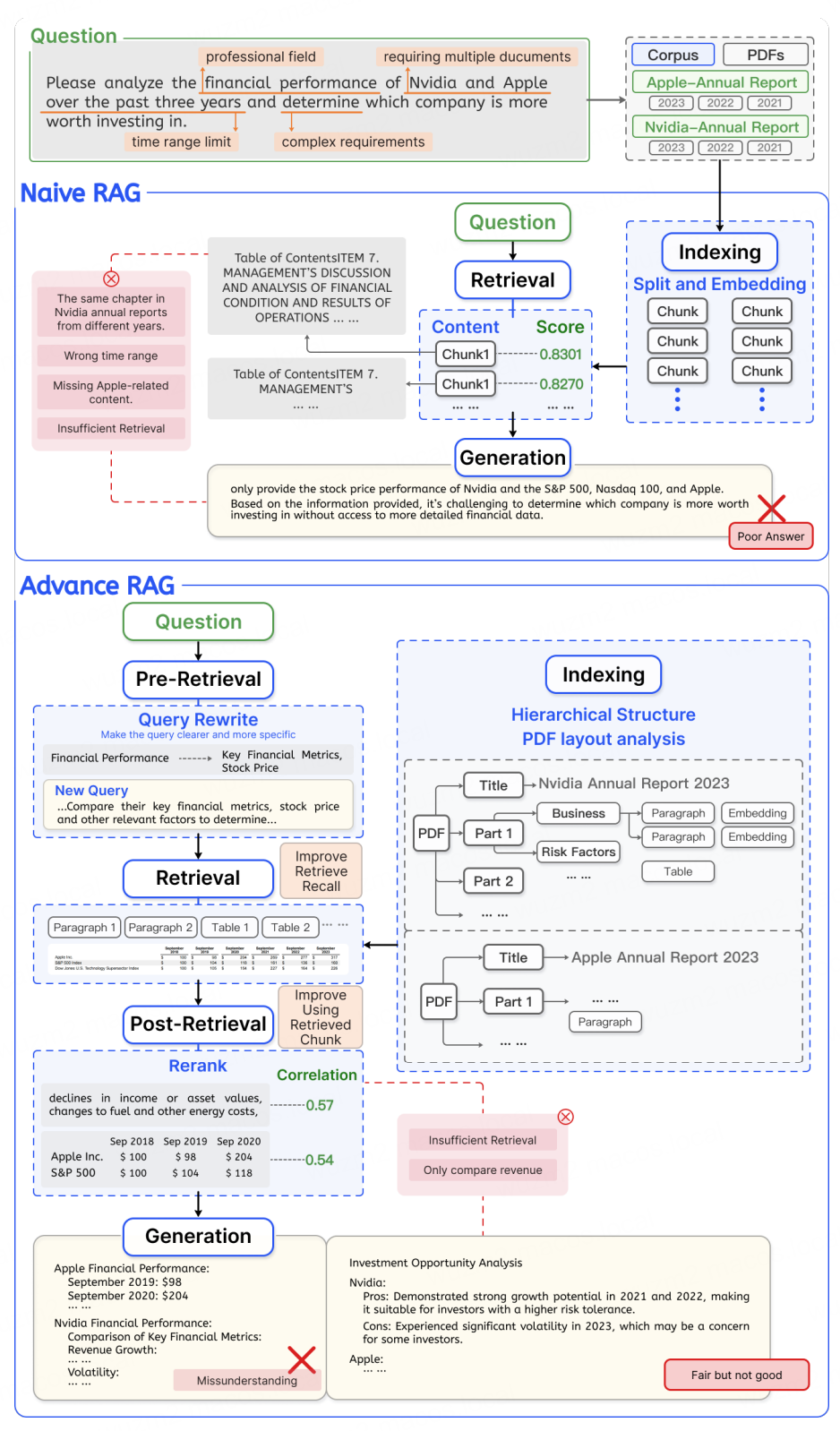
- Advanced RAG 通过优化检索前、检索中、检索后的各个环节
- 在索引质量、检索效果以及生成内容的上下文相关性方面都取得显著提升
检索前
通过索引、分块、查询优化和内容向量化等技术手段,提高检索内容的精确性和生成内容的相关性
滑动窗口
overlap
- 经典的 Chunking 技术,通过在相邻的 Chunk 之间创建重叠区域,确保关键信息不会因简单的 Chunking 而丢失
- 在 Indexing 过程中,通过在 Chunk 之间保留重复部分
- 保证了检索时上下文信息的连贯性,进而提高了检索的精度
元数据
- 为每个 Chunk 添加元数据,能够使系统在检索时快速过滤掉无关内容
分层索引
- 在 Indexing 过程中,可以采用句子级、段落级甚至文档级的多层次嵌入方法
- 系统可以根据查询的具体要求,灵活地在不同层次上进行检索
- 复杂的长句查询 - 段落级别的嵌入能够提供更加全面的语义匹配
- 简短查询 - 句子级的嵌入能够提供更加精确的结果
句子窗口
- 将文档中的每个句子独立嵌入,从而提高检索的精确度
- 在检索过程中,系统找到与 Query 最相关的句子后,会扩展句子前后的上下文窗口
- 保证生成模型能够获取足够的背景信息进行推理
- 既能精准定位关键信息,又能确保生成的上下文连贯
查询重写
- 针对用户输入的原始查询进行重新表诉,使其更加清晰易懂,并且与检索任务匹配
- 针对用户的模糊提问,系统可以通过重写,使查询更加具体化,从而检索到更加精准的内容
查询扩展
- 通过增加同义词、相关词汇或者概念,扩展用户的原始查询,增加了检索结果的广度
- 当用户输入简短或不完整的查询时,系统能够通过扩展词汇找到更多潜在的内容,从而提升检索效果
内容向量化
长短不一
- 在 RAG 系统中,Document 或 Query 的长度对向量化过程有着显著影响
- 对于短句子或者短语,其生成的向量更加聚焦于具体细节,能够实现更加精确的句子级别匹配
- 段落或文档级别的向量化涵盖了更广泛的上下文信息,能够捕捉到内容的整体语义
检索中
核心环节
动态嵌入
- 通过动态嵌入模型根据上下文实时调整单词的嵌入表示,能够捕捉单词在不同上下文中的不同含义
- 动态嵌入可以根据具体语境生成合适的向量,从而提高检索的精确性
- 现代的高质量 Embedding 模型本质上都是动态的,本质上是通过上下文信息进行训练并生成动态的嵌入表示
- 传统的 Embedding 模型(Word2Vec、GloVe)都是基于预先构建的词汇表生成的
- 每个单词的嵌入表示都是固定不变的,无法根据上下文变化进行动态调整
领域特定嵌入微调
jina-embeddings-v2-base-code
- 在实际应用中,不同领域的数据语境差异较大
- 通用的嵌入模型无法覆盖某些特定领域的专业术语或特定语义
- 通过对通用嵌入模型进行微调,可以增强其在特定领域的表现
假设文档嵌入
HyDE - Hypothetical Document Embeddings - 通过假设文档,系统可以捕捉到更准确的相关文档
- HyDE 通过生成假设文档并将其向量化,以提升查询与检索结果之间的语义匹配度
- 用户输入 Query 时,LLM 首先基于 Query 生成一个假设性答案
- 该答案不一定是真实存在的文档内容,但能反映查询的核心语义
- 根据假设性文档进行检索,系统可能最终找到类似的真实文档
混合检索
- 结合向量搜索和关键词搜索等多种检索方法,能够同时利用语义匹配与关键词匹配的优势
小到大检索
小块有助于提高精度,而大块则提供丰富的背景信息,使得生成的内容更加全面 – 分层检索
- 首先通过较小内容块(单句或短段落)进行嵌入和检索,确保模型能找到与查询最匹配的小范围上下文
- 检索到相关内容后,在生成阶段使用对应的较大内容块(完整段落或全文)为模型提供更广泛的上下文支持
递归块合并
- 逐级扩展检索内容,确保生成阶段能够捕捉到更全面的上下文信息
- 在细粒度的子块检索后,自动将相关的父块合并,以便为生成模型提供完整的上下文
检索后
重排序
- 初始检索可以找到多个与查询相关的内容块,但这些内容的相关性存在差异,需要进一步排序以优化生成结果
- 通过重排序模型根据上下文的重要性、相关性评分等因素对已检索的内容重新打分,确保最相关的信息被优先处理
提示压缩
- 删除冗余信息、合并相关内容、突出关键信息等方式来压缩提示,为生成模型提供更简洁、更相关的输入
上下文重构
- 通过对检索到的内容进行加工或重组,以便更好地符合查询的需求
- 将多个检索到的上下文片段整合成一个更具连贯性的文本块,减少重复或者冲突的内容,为 LLM 提供统一、清晰的输入
内容过滤
- 根据预设规则,过滤掉与查询无直接关联的内容,语义相似度较低的片段,冗长且无关的背景信息,避免影响生成结果
多级推理
- 系统通过多个推理步骤,逐步整合信息,以回答复杂查询,常用于需要跨多个上下文或多步推理的问题
知识注入
- 在检索后通过外部知识库或者预定义的领域知识,增强生成的上下文内容
- 适用于对准确性要求较高的场景,系统需要补充额外的专业知识
Modular RAG
打破传统的链式结构,允许不同模块之间的灵活组合以及流程的适应性编排 - 更高的灵活性和可扩展性
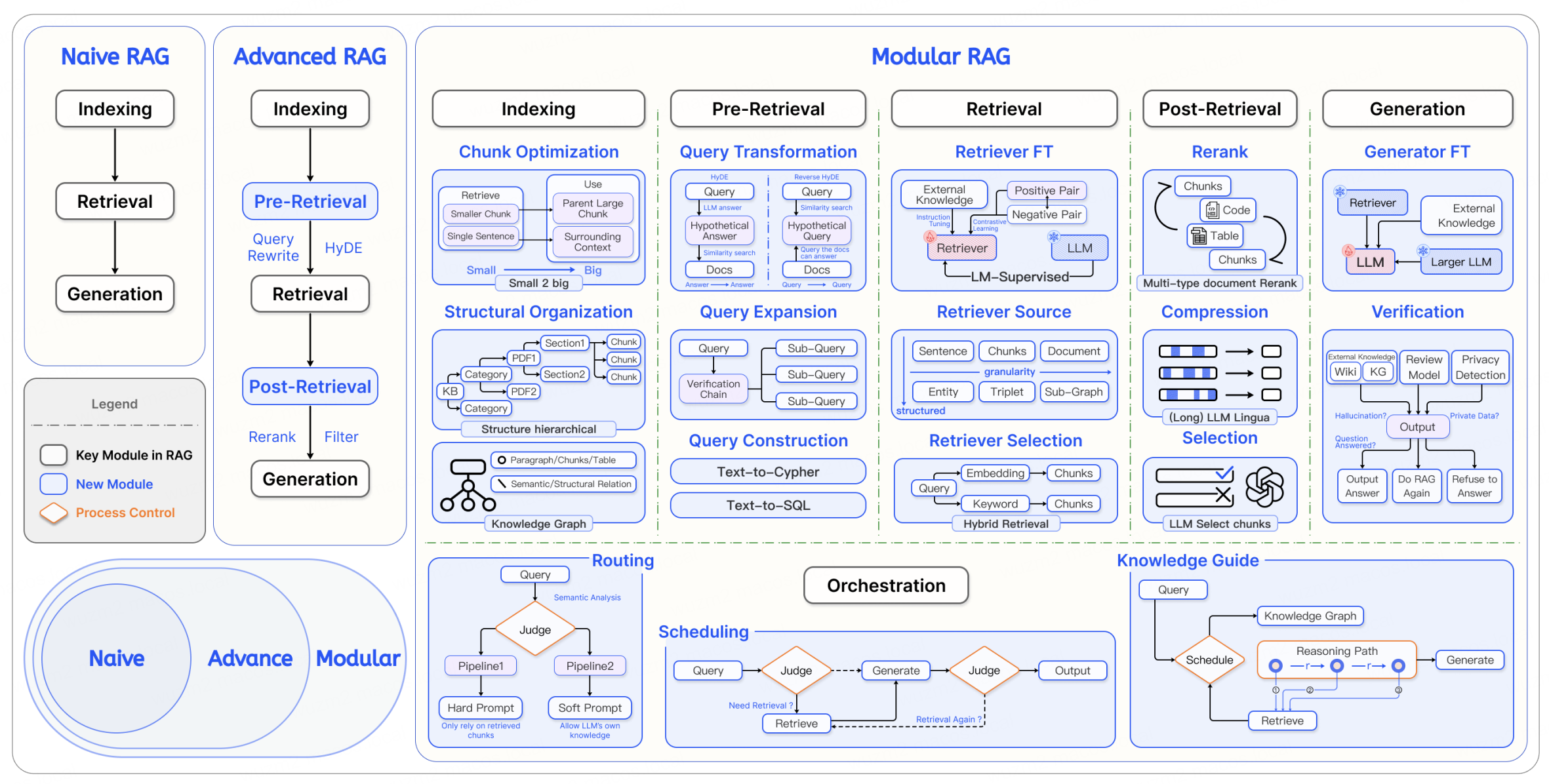
- Modular RAG 沿袭了 Naive RAG 和 Advanced RAG 的核心原则,但超越了两者,提供了更强的适应性和灵活性
- 通过多种优化策略和独有的编排功能,提高 RAG 系统的场景适应性
- Modular RAG 将 RAG 的过程细分为多个可优化的模块,支持高度定制化和优化
- Modular RAG 通过将 Advanced RAG 的优化策略自由组合
- 根据不同的应用场景定制化处理检索和生成任务,显著提升效率和效果
- 在 Modular RAG 中,Orchestration 是区别于 Advanced RAG 最显著部分
- 通过自由的流程控制和决策来优化检索和生成的全流程
- 核心思想 - 通过智能路由和调度,动态地决定查询处理的路径和步骤,从而在复杂场景下提升 RAG 系统的性能
Routing
路由是编排流程中的关键步骤 - 根据 Query 的特点和上下文,选择最合适的流程
Query Analysis
- 对 Query 进行语义分析,判断其类型和难度
- 直接问答式的查询 - 不需要复杂的检索过程
- 涉及多步推理的复杂问题 - 需要走更长的检索路径
Pipeline Selection
- 根据 Query Analysis 的结果,动态选择合适的 Pipeline
- 简单查询 - 禁用 LLM 的知识来回答,效率高
- 需要领域知识以及复杂推理的查询 - 集合外部文档及知识进行深度检索生成
Scheduling
管理 Query 的执行顺序,并动态调整检索和生成步骤
Query Scheduling
- 当系统接收到 Query 时,判断是否需要进行检索
- 根据 Query 重要性、上下文信息、已有生成结果的质量等多维度因素进行评估
Judgment of Retrieval Needs
- 通过特定的判断节点来确定是否需要额外检索
- 在某些情况下,可能会多次判断是否有必要执行新一轮的检索
Knowledge Guide
结合知识图谱和推理路径来增强查询处理过程
Knowledge Graph
- 在处理复杂查询时,系统可以调用知识图谱来辅助检索
- 提升了检索结果的准确性,还可以通过知识图谱中的上下文关系,推导出更为精确的答案
- 当查询涉及多个实体的关系,知识图谱能够提供更深层次的推理支持
Reasoning Path
- 通过推理路径,系统可以设计出一条符合查询需求的推理链条
- 系统根据该推理链条,进行逐步的推理和检索
- 适用于处理具有强逻辑性的问题 - 跨多个文档的关系推理或时间序列推理
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2024-08-12
RAG - Vector Stores
Embedding Vector Store概述 在 AI 时代,文字、图像、语音、视频等多模态数据的复杂性显著增加 多模态数据具有非结构化和多维特征 向量表示能够有效表示语义和捕捉潜在的语义关系 促使向量数据库成为存储、检索和分析高维向量的关键工具 Qdrant / Milvus 优势 SQL vs NoSQL 传统数据库通常分为关系型(SQL)数据库和非关系型(NoSQL)数据库 存储复杂、非结构化或半结构化信息的需求,主要依赖于 NoSQL 的能力 Store Desc Note Key-Value 用于简单的数据存储,通过 Key 来快速访问数据 精准定位信息 Document 用于存储文档结构的数据,如 JSON 格式 复杂的结构化信息 Graph 用于表示和存储复杂的关系数据,常用于社交网络、推荐等场景 复杂的关系数据 Vector 用于存储和检索基于向量表示的数据,用于 AI 模型的高维度和复杂的嵌入向量 语义最相关的数据 向量数据库的核心在于能够基于向量之间的相似性,能够快速、精确地定位和检索数据 向量数据库不仅为嵌入向量提供了...
2024-06-29
LLM PEFT - ChatGLM3-6B + LoRA
通用 LLM 千亿大模型(130B、ChatGPT)和小规模的大模型(6B、LLaMA2)都是通用 LLM 通用 LLM 都是通过常识进行预训练的 在实际使用过程中,需要 LLM 具备某一特定领域知识的能力 - 对 LLM 的能力进行增强 增强方式 Method Desc 微调 让预先训练好的 LLM 适应特定任务或数据集的方案,成本相对低LLM 学会训练者提供的微调数据,并具备一定的理解能力 知识库 使用向量数据库或者其它数据库存储数据,为 LLM 提供信息来源外挂 API 与知识库类似,为 LLM 提供信息来源外挂 互不冲突,可以同时使用几种方案来优化 LLM,提升内容输出能力 LoRA / QLoRA / 知识库 / API LLM Performance = 推理效果 落地过程 Method Pipeline 微调 准备数据 -> 微调 -> 验证 -> 提供服务 知识库 准备数据 -> 构建向量库 -> 构建智能体 -> 提供服务 API 准备数据 -&g...
2024-08-17
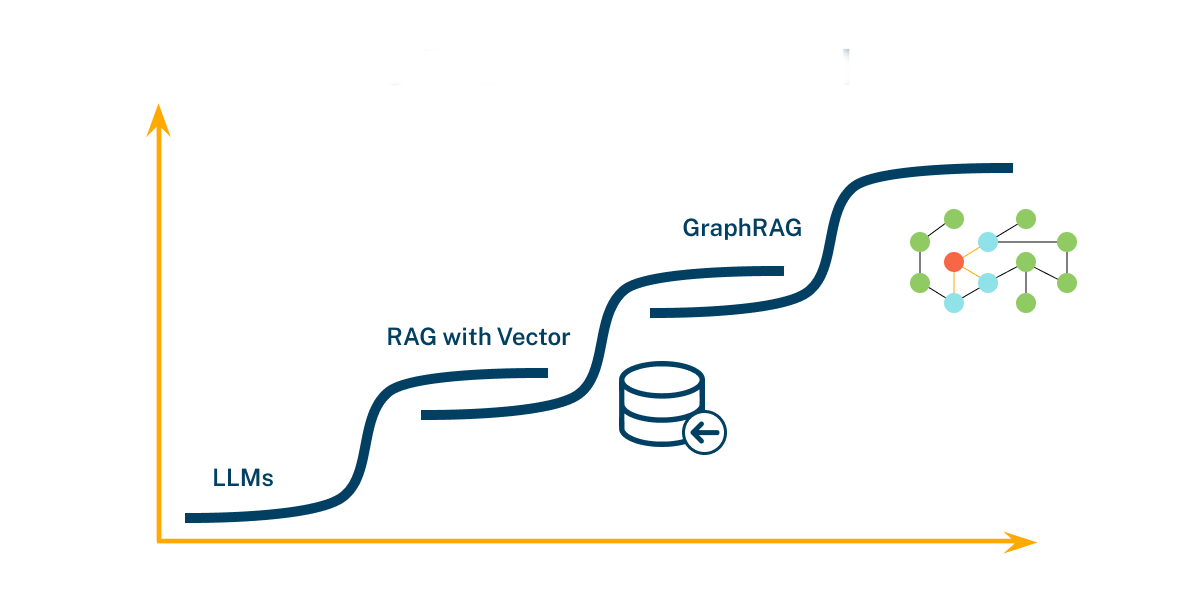
RAG - GraphRAG
向量检索 信息片段之间的连接能力有限 RAG 在跨越多个信息片段以获取综合见解时表现不足 当要回答一个复杂问题时,必须要通过共享属性在不同信息之间建立联系 RAG 无法有效捕捉这些关系 限制了 RAG 在处理需要多跳推理或整合多源数据的复杂查询时的能力 归纳总结能力不足 在处理大型数据集或长文档时,RAG 难以有效地归纳和总结复杂的语义概念 RAG 在需要全面理解和总结复杂语义信息的场景中表现不佳 GraphRAG 利用 LLM 生成的知识图谱来改进 RAG 的检索部分 GraphRAG 利用结构化的实体和关系信息,使得检索过程更加精准和全面 GraphRAG 在处理多跳问题和复杂文档分析时表现出色 GraphRAG 在处理复杂信息处理任务时,显著提升问答性能,提供比 RAG 更为准确和全面的答案 GraphRAG 通过知识图谱有效地连接不同的信息片段 不仅能够提供准确答案,还能展示答案之间的内在联系,提供更丰富和有价值的结果 GraphRAG 先利用知识图谱,关联查询的实体和关系从与知识图谱实体直接相关的文档中检索片段,提供一个更全面、指标化、高信息密度的总结 主...
2024-08-11
RAG - KG-RAG
Knowledge Graph 知识图谱也称为语义网络,表示现实世界实体的网络,并说明它们之间的关系 信息通常存储在图形数据库中,并以图形结构直观呈现 知识图谱由三部分组成 - 节点 + 边 + 标签 Why 降噪 + 提召 + 提准 传统 RAG 中的 Chunking 方式会召回一些噪音的 Chunk 引入 KG,可以通过实体层级特征来增强相关性 传统 RAG 中的 Chunk 之间是彼此孤立的,缺乏关联,在跨文档回答任务上表现不太好 引入 KG,增强 Chunk 之间的关联,并提升召回的相关性 假设已有 KG 数据存在,可以将 KG 作为一路召回信息源,补充上下文信息 Chunk 之间形成的 KG,可以提供 Graph 视角的 Embedding,来补充召回特征 构建一个高质量、灵活更新、计算简单的大规模图谱的代价很高 - RAG 会很慢 https://hub.baai.ac.cn/view/30017 https://hub.baai.ac.cn/view/33147 https://hub.baai.ac.cn/view/33390 https://hub.baa...
2024-08-15
RAG - Optimization + Evaluation
RAG 检索优化数据清洗和预处理 在 RAG 索引流程中,文档解析之后,文档切块之前,进行数据清洗和预处理 减少脏数据和噪音,提升文本的整体质量和信息密度 手段:清除冗余信息、统一格式、处理异常字符等 处理冗余的模板内容 消除文档中的额外空白和格式不一致 去除文档脚注、页眉页脚、版权信息 查询扩写 在 RAG 系统的检索步骤中,用户的查询会转换为向量后进行检索 单个向量查询只能覆盖向量空间中一个有限区域 如果查询中的嵌入向量未能包含所有关键信息,则可能检索到不相关的 Chunk 单点查询的局限性 - 限制系统在庞大文档库中的搜索范围,导致错失与查询语义相关的内容 查询扩写 通过 LLM 从原始查询语句生成多个语义相关的查询,可以覆盖向量空间中的不同区域 提高检索的全面性和准确性 扩写后的查询在被嵌入后,能够击中不同的语义区域 确保系统能够从更广泛的文档中检索到与用户需求相关的有用信息 通过查询扩写,原始问题被分解为多个子查询 每个子查询独立检索相关文档并生成相应的结果 系统将所有子查询的检索结果进行合并和重新排序 能够有效扩展用户的查询意图,确保在复杂信息库中进行更全面的文...

2024-08-09
RAG - Chunking + Embedding
概述 Chunking Documents 经过解析后,通过 Chunking 将信息内容划分为适当大小的 Chunks - 能够高效处理和精准检索 Chunk 的本质在于依据一定的逻辑和语义原则,将长文本拆解为更小的单元 Chunking 有多种策略,各有侧重,选择适合特定场景的 Chunking 策略,有助于提升 RAG 召回率 Embedding Embedding Model 负责将文本数据映射到高维向量空间,将输入的文档片段转换为对应的嵌入向量 嵌入向量捕捉了文本的语义信息,并存储到向量库中,以便于后续检索 Query 同样通过 Embedding Model 的处理生成 Query 的嵌入向量,在向量库中通过向量检索匹配最相似的文档片段 根据不同的场景,评估并选择最优的 Embedding Model,以确保 RAG 的检索性能符合要求 Chunking影响 Documents 包含丰富的上下文信息和复杂的语义结构 通过 Chunking,模型可以更有效地提取关键信息,并减少不相关内容的干扰 Chunking 的目标 确保每个片段在保留核心语义的同时,具备相对独立的语...




