Python - Dict + Set
基础
- 字典是由 kv 对组成的元素的集合,在 Python 3.7+,字典被确定为有序
- 相比于列表和元组,字典的性能更优,对于查找、添加和删除操作,时间复杂度为 O(1)
- 集合是一系列唯一无序的元素组合
- 字典和集合,无论是 Key 还是 Value,都可以是混合类型
字典初始化
1 | d1 = {'name': 'jason', 'age': 20, 'gender': 'male'} |
集合初始化
1 | s1 = {1, 2, 3} |
混合类型
1 | s = {1, 'hello', 5.0} |
字典通过 Key 访问,如果不存在,则抛出异常
1 | d = {'name': 'jason', 'age': 20} |
可以通过 get(key, default) 函数来访问,如果不存在,则返回默认值
1 | d = {'name': 'jason', 'age': 20} |
集合不支持索引操作,集合本质上是一个哈希表,与列表不一样
1 | s = {1, 2, 3} |
判断一个元素是否在一个集合或者字典中 - value in dict / set
1 | s = {1, 2, 3} |
字典和集合同样支持增加、删除、更新等操作
set.pop() 删除集合中的最后一个元素,但集合本身是无序的,随机删除
1 | d = {'name': 'jason', 'age': 20} |
1 | s = {1, 2, 3} |
根据字典的 Key 或者 Value,进行升序或者降序
返回一个列表,列表中的每个元素是由原字典的 Key 和 Value 组成的元组
1 | d = {'b': 1, 'a': 2, 'c': 10} |
对于集合,直接调用 sorted(set),返回一个排序后的列表
1 | s = {3, 4, 2, 1} |
性能
- 字典和集合是进行过性能高度优化的数据结构,特别适用于查找、添加和删除操作
- 字典的内部组成是哈希表,查找的时间复杂度为 O(1)
- 集合是高度优化的哈希表,查找的时间复杂度也是 O(1)
原理
字典和集合的内部结构都是哈希表
- 对于字典来说,哈希表存储了 Hash、Key 和 Value 3个元素
- 对于集合来说,哈希表中没有 Key 和 Value,只有单一元素,在 Java 中,为 Hash、Key、null
哈希表
老版本 Python 的哈希表 - 随着哈希表的扩张,会变得越来越稀疏 - 浪费存储空间
1 | --+-------------------------------+ |
为了提升存储空间的利用率,将索引与(Hash、Key 和 Value)单独分开 - 类似于 Java HashMap
1 | Indices |
插入
- 每次向字典或者集合插入一个元素时,Python 会首先计算 key 的哈希值,即 hash(key)
- 再与 mask = PyDicMinSize-1 进行与操作,计算该元素应该插入哈希表的位置 index = hash(key) & mask
- 如果哈希表该位置是空的,则该元素会被插入其中
- 如果哈希表此位置已被占用,Python 会比较两个元素的 Hash 和 Key 是否相等
- 如果都相等,表明该元素已经存在,如果值不同,则更新值
- 如果有一个不相等,表明发生哈希冲突,Python 会继续寻找哈希表中的空余位置,直到找到为止
- 简单实现为线性寻找,即从该位置开始,挨个往后寻找空位
查找
- 与插入类似,Python 根据 index = hash(key) & mask 找到预期位置
- 比较预期位置中的 Hash 和 Key 是否命中
- 如果命中,则直接返回
- 如果不命中,则继续查找,直到找到空位或者抛出异常为止
删除
- Python 会暂时对命中位置的元素,赋予一个特殊值,等到重新调整哈希表的大小时,再将其删除
Rehashing
- 哈希冲突的发生,往往会降低字典和集合操作的速度
- 为了保证高效性,字典和集合内的哈希表,往往会保证其至少留有 1/3 的剩余空间
- 当剩余空间小于 1/3 时,Python 会重新获取到更大的内存空间,扩充哈希表
- 哈希表内的所有元素都会被重新排放
- 虽然哈希冲突和 Rehashing,都会导致速度减缓,但发生次数极少
- 所以插入、查找和删除的平均时间复杂度依然为 O(1)
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2024-09-02
Python - Coroutine
基础 协程是实现并发编程的一种方式 多线程/多进程模型,是解决并发问题的经典模式 C10K - 线程/进程上下文切换占用大量资源 Nginx Event loop 启动一个统一的调度器,让调度器来决定一个时刻去运行哪个任务 节省了多线程中启动线程、管理线程、同步锁等各种开销 相比于 Apache,用更低的资源支持更多的并发连接 Callback hell - JavaScript 继承了 Event loop 的优越性,同时还提供 async / await 语法糖,解决了执行性和可读性共存的难题 协程开始崭露头角,尝试使用 Node.js 实现后端 Python 3.7 提供基于 asyncio 的 async / await 方法 同步 简单实现 12345678910111213141516import timedef crawl_page(url): print('crawling {}'.format(url)) sleep_time = int(url.split('_&...
2024-09-07
Python - With
场景 资源是有限的,使用过后需要释放,否则会造成资源泄露 File123for x in range(10_000_000): f = open('test.txt', 'w') # OSError: [Errno 24] Too many open files f.write('hello') context manager 帮助自动分配并释放资源 - with 语句 123for x in range(10_000_000): with open('test.txt', 'w') as f: # This will open and close the file 10_000_000 times f.write('hello') try - finally 12345f = open('test.txt', 'w')try: f.write('hello')fin...
2024-08-23
Python - Exception
错误 vs 异常 语法错误,无法被识别与执行 123name = 'x'if name is not None # SyntaxError: invalid syntax print(name) 异常 - 语法正确,可以被执行,但在执行过程中遇到错误,抛出异常,并终止程序 123# 10 / 0 # ZeroDivisionError: division by zero# order * 2 # NameError: name 'order' is not defined# 1 + [1, 2] # TypeError: unsupported operand type(s) for +: 'int' and 'list' 处理异常 try-exceptexcept block 只接受与它相匹配的异常类型并执行 123456try: s = input('please enter two numbers separated by comma: ') num1 = ...

2024-08-24
Python - Function
基础 函数为实现了某一功能的代码片段,可以重复利用函数可以返回调用结果(return or yield),也可以不返回 123def name(param1, param2, ..., paramN): statements return/yield value # optional 与编译型语言不同,def 是可执行语句,即函数直到被调用前,都是不存在的 当调用函数时,def 语句才会创建一个新的函数对象,并赋予其名字 在主程序调用函数时,必须保证这个函数已经定义过,否则会报错 12345my_func('hello world') # NameError: name 'my_func' is not defineddef my_func(message): print('Got a message: {}'.format(message)) 在函数内部调用其它函数,则没有定义顺序的限制def 是可执行语句 - 函数在调用之前都不存在,只需保证调用时,所需的函数都已经声明定义即可 ...
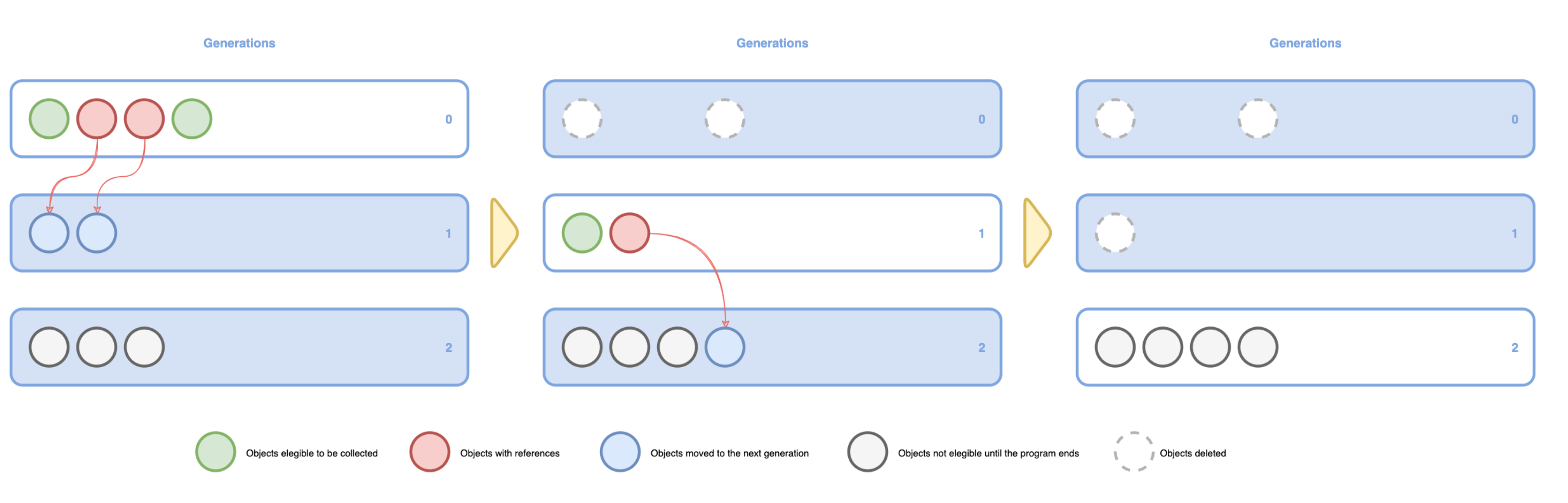
2024-09-06
Python - GC
计数引用 Python 中一切皆对象,变量的本质是对像的指针 当一个对象的引用计数(指针数)为 0 时,说明该对象不可达,成为垃圾,需要被回收 调用函数 func(),创建列表 a 后,内存占用迅速增加,在函数调用结束后,内存恢复正常 函数内部声明的列表 a 是局部变量,在函数返回后,局部变量的引用会被注销 列表 a 所指向的对象的引用数为 0,Python 会执行 GC,回收内存 全局变量 - global 将生成的列表返回,在主程序中接收 内部实现1234567891011121314import sysa = []print(sys.getrefcount(a)) # 2 = a + getrefcountdef func(a): print(sys.getrefcount(a)) # 4 = a + getrefcount + func call stack + func argsfunc(a)print(sys.getrefcount(a)) # 2 = a + getrefcount sys.getrefcount 本身也会引入一次计数 在函数调用...

2024-08-21
Python - IO
基础1234567891011name = input('your name:')gender = input('you are a boy? (y/n)')welcome_str = 'Welcome to the matrix {prefix} {name}.'welcome_dic = { 'prefix': 'Mr.' if gender == 'y' else 'Mrs.', 'name': name}print('authorizing...')print(welcome_str.format(**welcome_dic)) input() 函数暂停程序运行,等待键盘输入,直到回车被按下 函数的参数为提示语,输入的类型永远都是字符串(string) print() 函数则接受字符串、数字、字典、列表和自定义类 input() 的...