
Python - Dict + Set
基础
- 字典是由 kv 对组成的元素的集合,在 Python 3.7+,字典被确定为有序
- 相比于列表和元组,字典的性能更优,对于查找、添加和删除操作,时间复杂度为 O(1)
- 集合是一系列唯一无序的元素组合
- 字典和集合,无论是 Key 还是 Value,都可以是混合类型
字典初始化
1 | d1 = {'name': 'jason', 'age': 20, 'gender': 'male'} |
集合初始化
1 | s1 = {1, 2, 3} |
混合类型
1 | s = {1, 'hello', 5.0} |
字典通过 Key 访问,如果不存在,则抛出异常
1 | d = {'name': 'jason', 'age': 20} |
可以通过 get(key, default) 函数来访问,如果不存在,则返回默认值
1 | d = {'name': 'jason', 'age': 20} |
集合不支持索引操作,集合本质上是一个哈希表,与列表不一样
1 | s = {1, 2, 3} |
判断一个元素是否在一个集合或者字典中 - value in dict / set
1 | s = {1, 2, 3} |
字典和集合同样支持增加、删除、更新等操作
set.pop() 删除集合中的最后一个元素,但集合本身是无序的,随机删除
1 | d = {'name': 'jason', 'age': 20} |
1 | s = {1, 2, 3} |
根据字典的 Key 或者 Value,进行升序或者降序
返回一个列表,列表中的每个元素是由原字典的 Key 和 Value 组成的元组
1 | d = {'b': 1, 'a': 2, 'c': 10} |
对于集合,直接调用 sorted(set),返回一个排序后的列表
1 | s = {3, 4, 2, 1} |
性能
- 字典和集合是进行过性能高度优化的数据结构,特别适用于查找、添加和删除操作
- 字典的内部组成是哈希表,查找的时间复杂度为 O(1)
- 集合是高度优化的哈希表,查找的时间复杂度也是 O(1)
原理
字典和集合的内部结构都是哈希表
- 对于字典来说,哈希表存储了 Hash、Key 和 Value 3个元素
- 对于集合来说,哈希表中没有 Key 和 Value,只有单一元素,在 Java 中,为 Hash、Key、null
哈希表
老版本 Python 的哈希表 - 随着哈希表的扩张,会变得越来越稀疏 - 浪费存储空间
1 | --+-------------------------------+ |
为了提升存储空间的利用率,将索引与(Hash、Key 和 Value)单独分开 - 类似于 Java HashMap
1 | Indices |
插入
- 每次向字典或者集合插入一个元素时,Python 会首先计算 key 的哈希值,即 hash(key)
- 再与 mask = PyDicMinSize-1 进行与操作,计算该元素应该插入哈希表的位置 index = hash(key) & mask
- 如果哈希表该位置是空的,则该元素会被插入其中
- 如果哈希表此位置已被占用,Python 会比较两个元素的 Hash 和 Key 是否相等
- 如果都相等,表明该元素已经存在,如果值不同,则更新值
- 如果有一个不相等,表明发生哈希冲突,Python 会继续寻找哈希表中的空余位置,直到找到为止
- 简单实现为线性寻找,即从该位置开始,挨个往后寻找空位
查找
- 与插入类似,Python 根据 index = hash(key) & mask 找到预期位置
- 比较预期位置中的 Hash 和 Key 是否命中
- 如果命中,则直接返回
- 如果不命中,则继续查找,直到找到空位或者抛出异常为止
删除
- Python 会暂时对命中位置的元素,赋予一个特殊值,等到重新调整哈希表的大小时,再将其删除
Rehashing
- 哈希冲突的发生,往往会降低字典和集合操作的速度
- 为了保证高效性,字典和集合内的哈希表,往往会保证其至少留有 1/3 的剩余空间
- 当剩余空间小于 1/3 时,Python 会重新获取到更大的内存空间,扩充哈希表
- 哈希表内的所有元素都会被重新排放
- 虽然哈希冲突和 Rehashing,都会导致速度减缓,但发生次数极少
- 所以插入、查找和删除的平均时间复杂度依然为 O(1)
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2024-08-31
Python - Metaclass
超越变形 YAMLObject 的一个超越变形能力,即的任意子类支持序列化和反序列化 123456789101112131415161718192021222324252627282930import yamlclass Monster(yaml.YAMLObject): yaml_tag = u'!Monster' def __init__(self, name, hp, ac, attacks): self.name = name self.hp = hp self.ac = ac self.attacks = attacks def __repr__(self): return "%s(name=%r, hp=%r, ac=%r, attacks=%r)" % ( self.__class__.__name__, self.name, self.hp, self.ac, self.attacks)yaml.load("...
2024-07-01
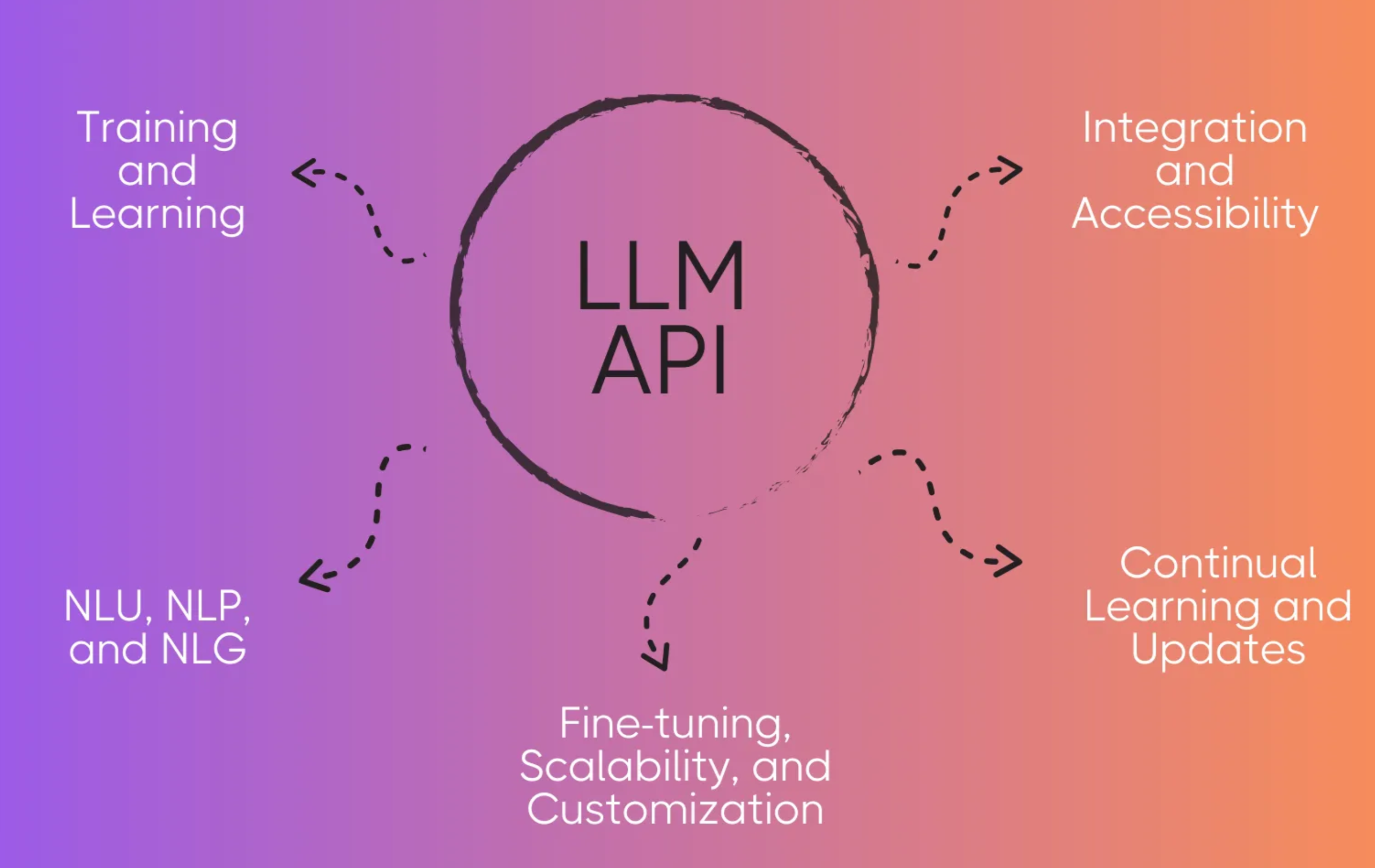
LLM - API
背景 LLM 是没有 Web API 的,需要进行一次封装 将 LLM 的核心接口封装成 Web API 来为用户提供服务 - 必经之路 接口封装FastAPI接口封装 Uvicorn + FastAPI Uvicorn 类似于 Tomcat,但比 Tomcat 轻量很多,作为 Web 服务器 允许异步处理 HTTP 请求,非常适合处理并发请求 基于 uvloop 和 httptools,具备非常高的性能 FastAPI 类似于 SpringBoot,同样比 SpringBoot 轻量很多,作为 API 框架 结合 Uvicorn 和 FastAPI 可以构建一个高性能的、易于扩展的异步 Web 应用程序 Uvicorn 作为服务器运行 FastAPI 应用,可以提供优异的并发处理能力 安装依赖12$ pip install fastapi$ pip install uvicorn 代码分层1234567891011121314import uvicornfrom fastapi import FastAPI# 创建API应用app = FastAPI()@app.get(&quo...
2024-08-20
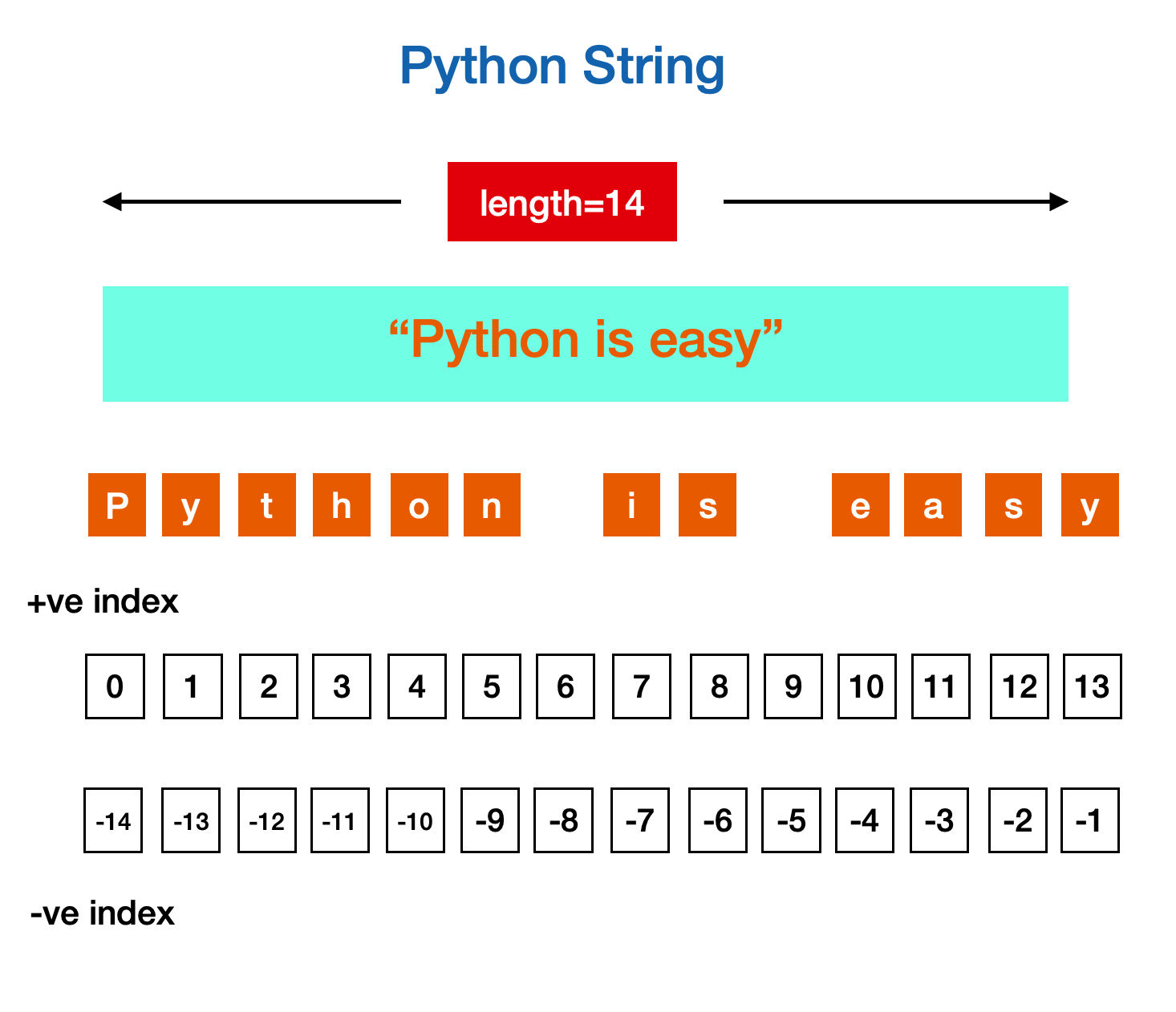
Python - String
基础 字符串是由独立字符组成的一个序列,通常包含在 '...'、"..."、"""...""" 中 123name = 'jason'city = "guangzhou"desc = """I'm a software engineer""" 1234s1 = 'rust's2 = "rust"s3 = """rust"""print(s1 == s2 == s3) # True 便于在字符串中,内嵌带引号的字符串 12s = "I'm a string"print(s) # I'm a string """...""" 常用于多行字符串,如函数注释 Python 支持转义字...

2024-08-26
Python - OOP
命令式 Python 的命令式语言是图灵完备的 - 即理论上可以做到其它任何语言能够做到的所有事情 仅依靠汇编语言的 MOV 指令,就能实现图灵完备编程 传统的命令式语言有着无数重复性代码,虽然函数的诞生减缓了许多重复性 但只有函数是不够的,需要把更加抽象的概念引入计算机才能缓解 – OOP 基本概念12345678910111213141516171819202122232425class Document(): def __init__(self, title, author, context): print('init function called') self.title = title self.author = author self.__context = context # __context is private def get_context_length(self): return len(self.__context) def intercept_cont...
2024-08-28
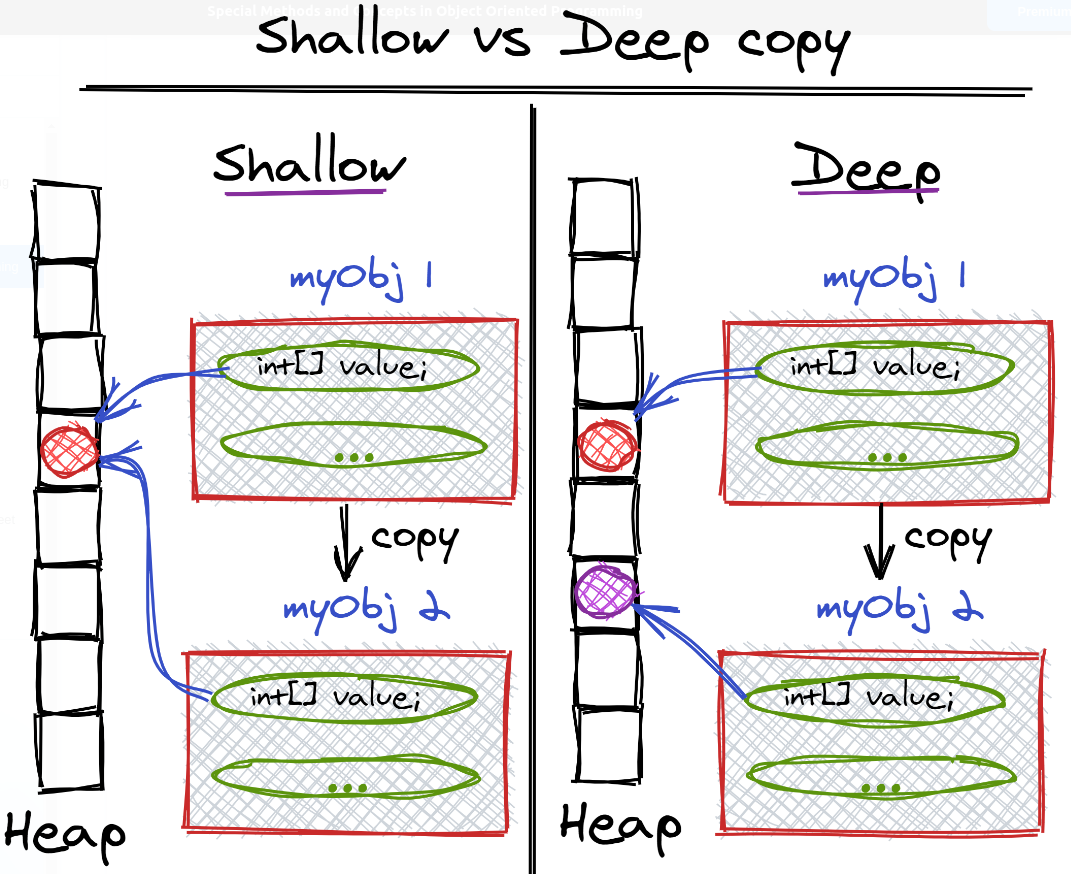
Python - Compare + Copy
== vs is == 比较对象之间的值是否相等,类似于 Java 中的 equals is 比较的是对象的身份标识是否相等,即是否为同一个对象,是否指向同一个内存地址,类似于 Java 中的 == is None or is not None 在 Python 中,每个对象的身份标识,都能通过 id(object) 函数获得,is 比较的是对象之间的 ID 是否相等 类似于 Java 对象的 HashCode 在实际工作中,**== 更常用,一般关心的是两个变量的值,而非内部存储地址** 12345678a = 10 # allocate memory for 10b = 10 # point to the same memory location as aprint(a == b) # Trueprint(id(a)) # 4376158344print(id(b)) # 4376158344print(a is b) # True a is b 为 True,仅适用于 -5 ~ 256 范...
2024-08-25
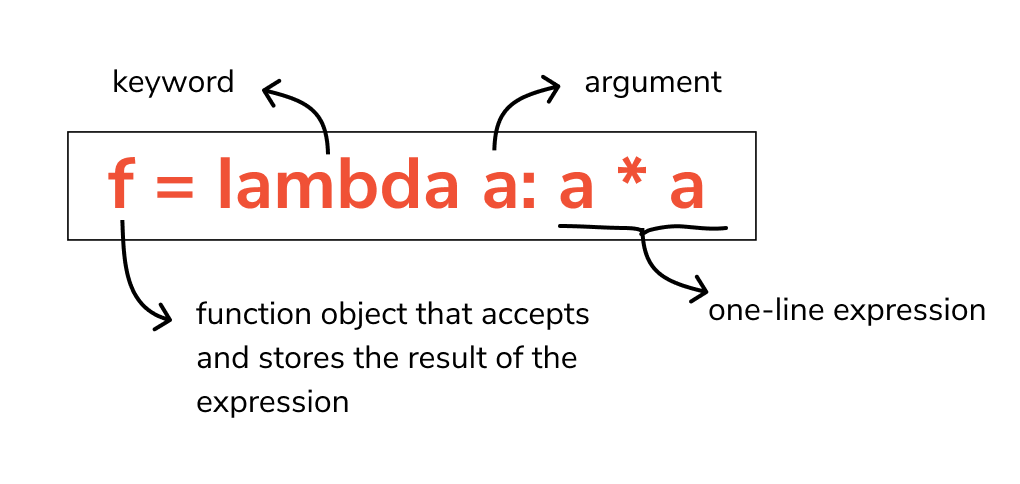
Python - Lambda
基础 匿名函数的关键字为 lambda 1lambda argument1, argument2,... argumentN : expression 1234square = lambda x: x ** 2print(type(square)) # <class 'function'>print(square(5)) # 25 lambda 是一个表达式(expression),而非一个语句(statement) 表达式 - 用一系列公式去表达 语句 - 完成某些功能 lambda 可以用在列表内部,而常规函数 def 不能 lambda 可以用作函数参数,而常规函数 def 不能 常规函数 def 必须通过其函数名被调用,因此必须首先被定义 lambda 是一个表达式,返回的函数对象不需要名字,即匿名函数 lambda 的主体只有一行的简单表达式,并不能扩展成多行的代码块 lambda 专注于简单任务,而常规函数 def 负责更复杂的多行逻辑 12y = [(lambda x: x * x)(x) for x in range(10)]...




