
Spark - RDD
分布式内存
- 传统的 MapReduce 框架运行缓慢,主要原因是 DAG 的中间计算结果需要写入硬盘来防止运行结果丢失
- 每次调用中间计算结果都需要进行一次硬盘的读取
- 反复对硬盘进行读写操作以及潜在的数据复制和序列化操作会大大地提高了计算延迟
- 新的分布式存储方案 - 保持之前系统的稳定性、错误恢复和可扩展性,并尽可能地减少硬盘 IO 操作
- RDD 是基于分布式内存的数据抽象,不仅支持基于工作集的应用,同时具有数据流模型的特点
定义
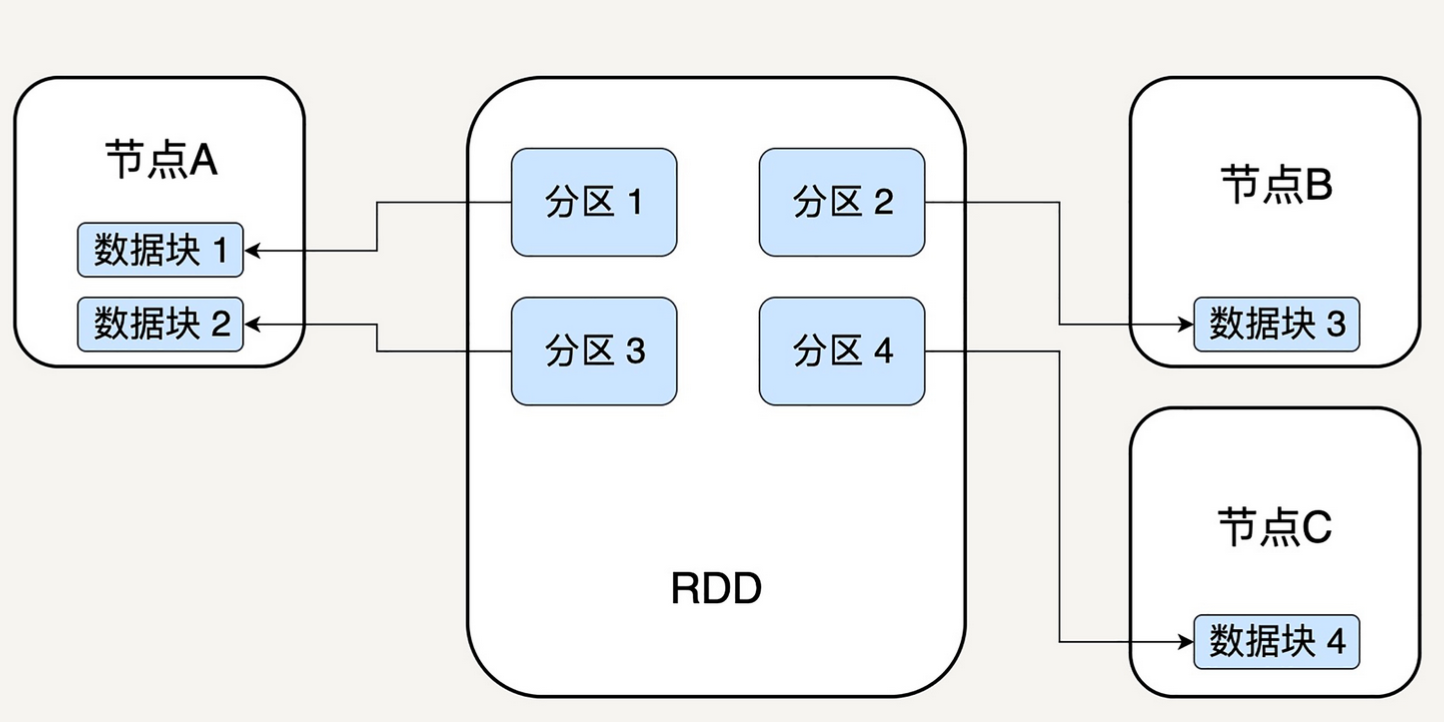
分区
- 分区代表同一个 RDD 包含的数据被存储在系统的不同节点上,这是可以被并行处理的前提
- 在逻辑上,可以认为 RDD 是一个大数组,数组中的每个元素代表一个分区(Partition)
- 在物理存储中,每个分区指向一个存放在内存或者硬盘中的数据块(Block)
- Block 是独立的,可以被存放在分布式系统中的不同节点
- RDD 只是抽象意义的数据集合,分区内部并不会存储具体的数据
- RDD 中的每个分区都有它在该 RDD 中的 Index
- 通过 RDD_ID 和 Partition_Index 可以唯一确定对应 Block 的编号
- 从而通过底层存储层的接口中提取到数据进行处理
- 在集群中,各个节点的 Block 会尽可能地存放在内存中,只有在内存不足时,才会写入硬盘
- 可以最大化地减少硬盘读写的开销
- RDD 内部存储的数据是只读的,但可以修改并行计算单元的划分结构,即分区数量
不可变
- 不可变性代表每个 RDD 都是只读的,RDD 所包含的分区信息是不可以被改变的
- 已有的 RDD 不可以被改变
- 只能对现有的 RDD 进行转换(Transformation)操作,得到新的 RDD 作为中间计算的结果
- RDD 与函数式编程的 Collection 很相似
1 | lines = sc.textFile("data.txt") |
- 读入文本文件 data.txt,创建第一个 RDD lines,每一个元素就是一行文本
- 调用 map 函数去映射产生第二个 RDD lineLengths,每一个元素代表每一行简单文本的字数
- 调用 reduce 函数得到第三个 RDD totalLength,只有一个元素,代表整个文本的总字数
优势
- 对于代表中间结果的 RDD,需要记录它是通过哪个 RDD 进行了哪些转换操作得到的,即依赖关系
- 而无需立即去具体存储计算出的数据本身
- 有助于提升 Spark 的计算效率,并且使得错误恢复更容易
- 在一个有 N 步的计算模型中,如果记载第 N 步输出 RDD 的节点发生了故障,导致数据丢失
- 可以从第 N-1 步的 RDD 出发,再次计算,无需重复整个 N 步计算过程
- 这种容错机制,也是 RDD 为什么是 Resilient 的原因
并行计算
- 由于单个 RDD 的分区特性,使得它天然支持并行操作
- 不同节点上的数据可以被分别处理,然后产生一个新的 RDD
结构
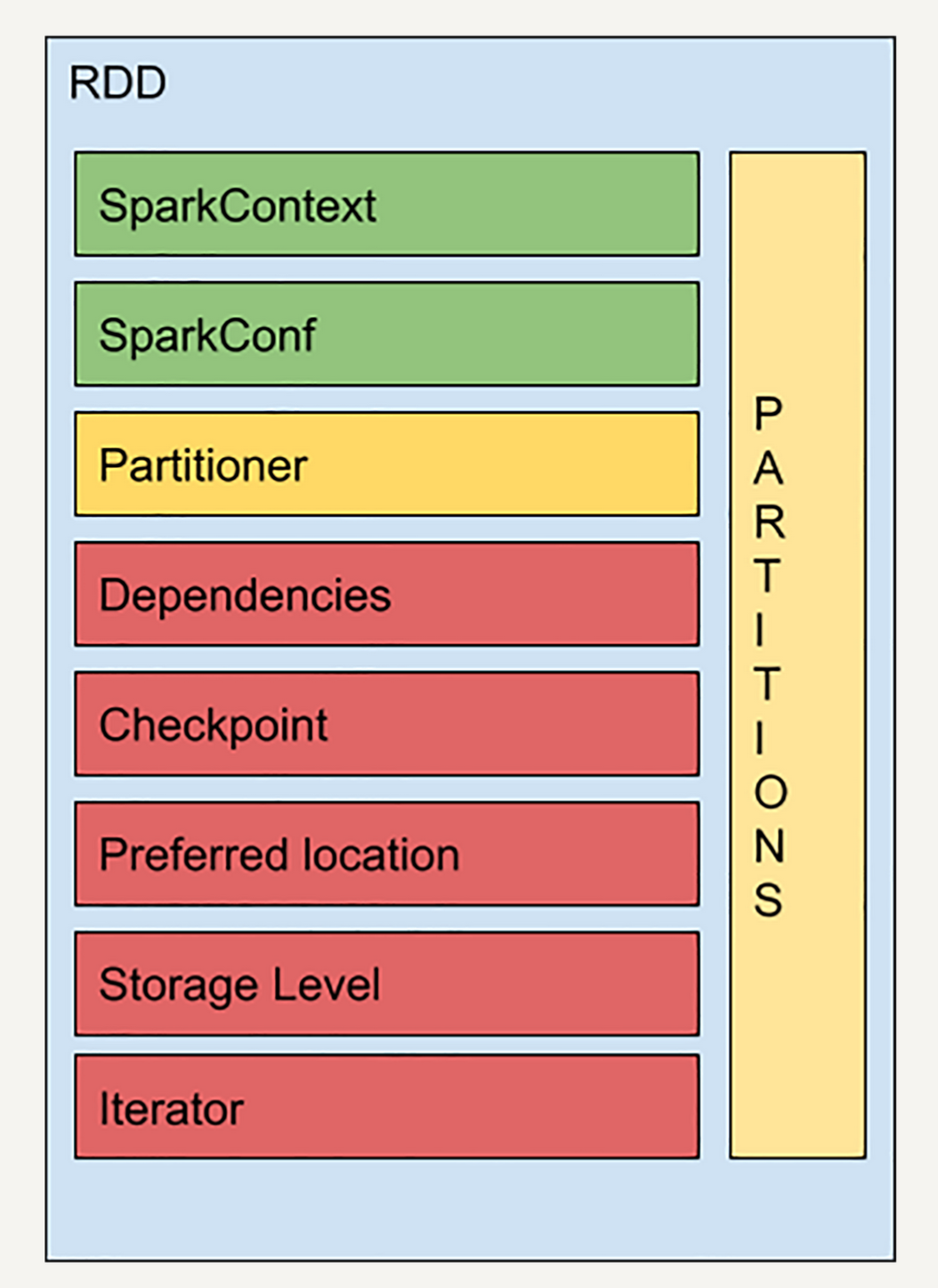
- SparkContext 是所有 Spark 功能的入口
- 代表了与 Spark 节点的连接,可以用来创建 RDD 对象,在节点中广播变量等
- 一个线程只有一个 SparkContext
- SparkConf 是一些参数配置信息
- Partitions 代表 RDD 中数据的逻辑结构
- 每个 Partition 会映射到某个节点上内存或者硬盘的一个 Block
- Partitioner 决定了 RDD 的分区方式,主流的分区方式有两种:Hash partitioner 和 Range partitioner
- Hash - 对数据的 Key 进行散列分区
- Range - 按照 Key 的排序进行均匀分区
依赖关系
- Dependencies 是 RDD 中最重要的组件之一
- Spark 不需要将每个中间计算结果进行数据复制以防止数据丢失
- 每一步产生的 RDD 里都会存储它的依赖关系
- 依赖关系 - 当前的 RDD 是通过哪个 RDD 经过哪个转换操作得到的
- 窄依赖 vs 宽依赖
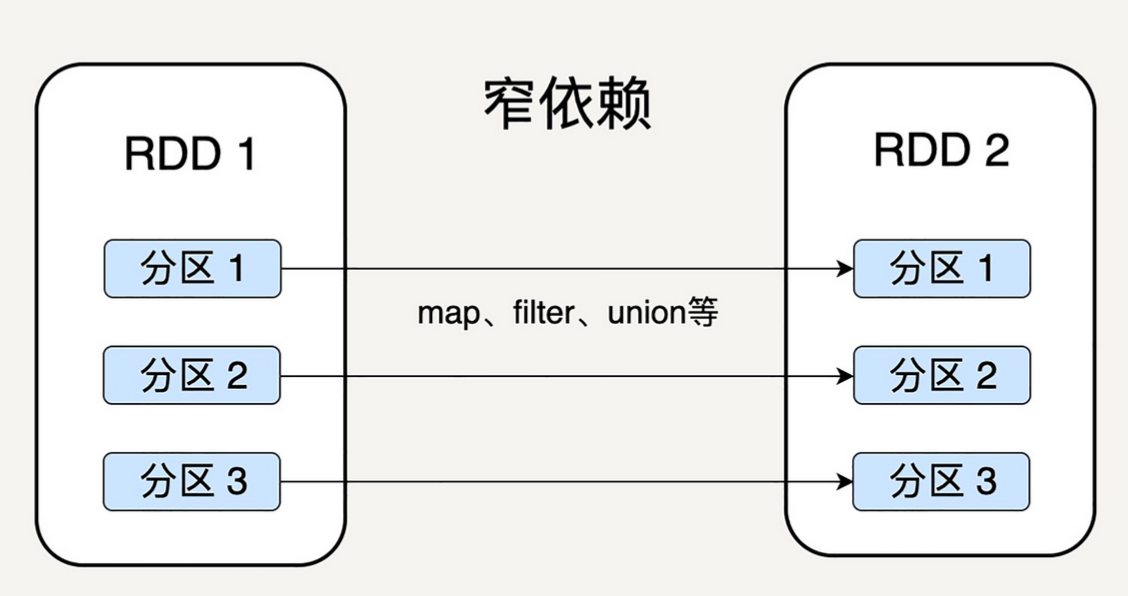
- 窄依赖 - 允许子 RDD 的每个分区可以被并行处理产生
- map - 一个父 RDD 分区里的数据不会分散到不同的子 RDD 分区
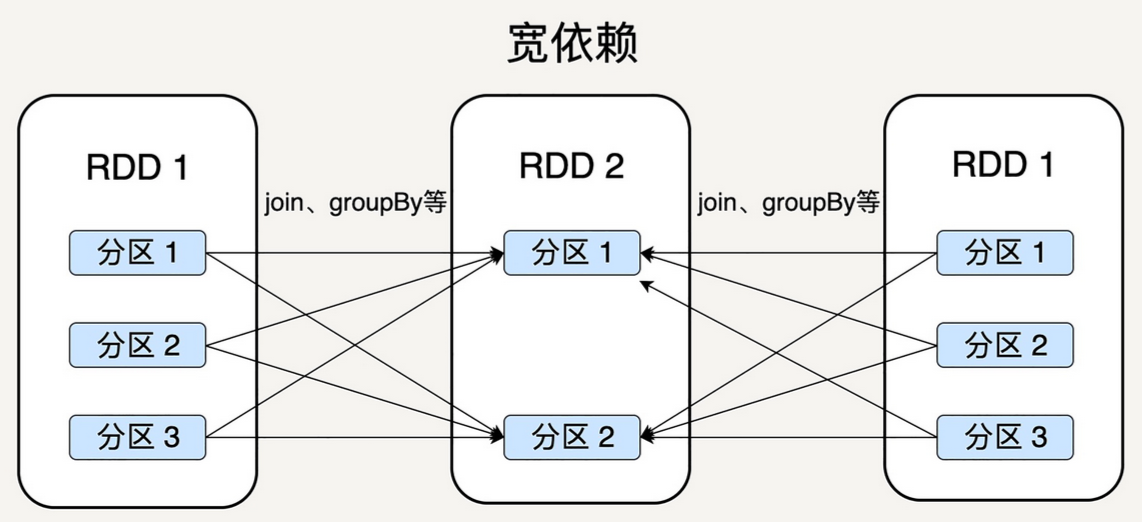
- 宽依赖 - 必须等父 RDD 的所有分区都被计算好之后才能开始处理
- groupBy - 一个父 RDD 分区里可能有多种 Key 的数据,因此可能被子 RDD 不同的分区所依赖
- 窄依赖 - 允许子 RDD 的每个分区可以被并行处理产生
- 同一节点 + 链式执行
- 窄依赖可以支持同一个节点上链式执行多条命令,map -> filter
- 宽依赖需要父 RDD 的所有分区都是可用的,可能还需要调用类似 MapReduce 之类的操作进行跨节点传递
- 失败恢复
- 窄依赖的失败恢复更有效,因为只需要重新计算丢失的父分区即可
- 宽依赖,则牵涉 RDD 各级的多个父分区
窄依赖
Narrow Dependency - 父 RDD 的分区可以一一对应到子 RDD 的分区
宽依赖
Wide Dependency - 父 RDD 的每个分区可以被多个子 RDD 的分区使用
检查点
Checkpoint
- 基于 RDD 的依赖关系,如果任意一个 RDD 在相应的节点丢失
- 只需从上一步的 RDD 出发再次计算,便可恢复该 RDD
- 如果一个 RDD 的依赖链比较长,而且中间有多个 RDD 出现故障,进行恢复会非常耗费时间和计算资源
- 引入检查点,可以优化这些情况下的数据恢复
- 很多数据库系统都有检查点机制
- 在连续的 transaction 列表中记录某几个 transaction 后数据的内容,从而加快错误恢复
- 在计算过程中,对于一些计算过程比较耗时的 RDD
- 将它缓存至硬盘或者 HDFS,标记该 RDD 被检查点处理过,并且清空它的所有依赖关系
- 同时,新建一个依赖于 CheckpointRDD 的依赖关系
- CheckpointRDD 可以从硬盘中读取 RDD 和生成新的分区信息
- 当某个子 RDD 需要错误恢复时,回溯到该 RDD,发现它被检查点记录过
- 直接去硬盘读取该 RDD,而无需再向前回溯计算
存储级别
Storage Level - 枚举类型,用来记录 RDD 持久化时的存储级别
| Storage Level | Desc |
|---|---|
| MEMORY_ONLY - 默认值 | 只缓存在内存中,如果内存不足则不缓存多出来的部分 |
| MEMORY_AND_DISK | 缓存在内存中,如果空间不够则缓存在硬盘中 |
| DISK_ONLY | 只缓存在硬盘中 |
| MEMORY_ONLY_2 / MEMORY_AND_DISK_2 | 同上,每个分区在集群中的两个节点上建立副本 |
相对于 Hadoop,随时可以将计算好的 RDD 缓存在内存中,以便于下次计算时使用
迭代 + 计算
Iterator + Compute - 表示 RDD 怎样通过父 RDD 计算得到的
- 迭代函数会首先判断缓存中是否有想要计算的 RDD,如果有则直接读取
- 如果没有,则检查想要计算的 RDD 是否被检查点处理过,如果有则直接读取
- 如果没有,就调用计算函数向上递归,查找父 RDD 进行计算
缓存 -> 检查点
操作
转换 - Transformation
- MapReduce 只支持 Map 和 Reduce 操作,而 Spark 支持大量的基本操作
- 转换 - 将一个 RDD 转换为另一个 RDD
Map
- 将一个 RDD 中的所有数据通过一个函数,映射成一个新的 RDD
- 任何原 RDD 中的元素在新 RDD 中都有且只有一个元素与之对应
1 | rdd = sc.parallelize(["b", "a", "c"]) |
Filter
选择原 RDD 里所有数据中满足特定条件的数据,返回一个新的 RDD
1 | rdd = sc.parallelize([1, 2, 3, 4, 5]) |
MapPartitions
- MapPartitions 是 Map 的变种
- Map 的输入函数应用于 RDD 中的每个元素
- MapPartitions 的输入函数应用于 RDD 中的每个分区,将每个分区中的内容作为整体来处理
1 | rdd = sc.parallelize([1, 2, 3, 4], 2) // 创建一个有两个分区的 RDD |
GroupByKey
- 与 SQL 中的 groupBy 类似,将对象的集合按照某个 Key 来归类
- 返回的 RDD 中的每个 Key 对应一个序列
1 | rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 2)]) |
动作 - Action
动作 - 通过计算返回一个结果
Collect
- Collect 与函数式编程中的 Collect 类似,以数组的形式,返回 RDD 的所有元素
- Collect 操作只有在输出数组较小时使用
- 因为所有的数据都会载入到程序的内存中,如果输出数组很大,则会占用大量 JVM 内存,导致内存溢出
1 | rdd = sc.parallelize(["b", "a", "c"]) |
Reduce
与 MapReduce 中的 Reduce 类似,将 RDD 中的元素根据一个输入函数聚合起来
1 | from operator import add |
Count
返回 RDD 中元素的个数
1 | sc.parallelize([2, 3, 4]).count() // 3 |
CountByKey
仅适用于 Key-Value Pair 类型的 RDD,返回具有每个 Key 的计数的 Key-Count 字典
1 | rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)]) |
惰性求值
- 所有的转换操作都很懒,只是生成新的 RDD,并且记录依赖关系
- Spark 并不会立刻计算出新 RDD 中各个分区的数值
- 直到遇到一个动作时,数据才会被计算,并输出结果给 Driver
- 惰性求值的设计可以让 Spark 的运算更加高效和快速
执行流程
- Spark 在每次转换操作时,使用了新产生的 RDD 来记录计算逻辑
- 把作用在 RDD 上的所有计算逻辑串联起来,形成一个链条
- 当 RDD 进行动作操作时
- Spark 会从计算链的最后一个 RDD 开始,依次从上一个 RDD 获取数据并执行计算逻辑,最后输出结果
持久化 - 缓存
类似于 Guava LoadingCache
- 每当对 RDD 调用一个新的动作操作时,整个 RDD 都会从头开始运算
- 如果某个 RDD 会被反复重用的话,每次都重头计算非常低效 – 进行持久化操作
- Spark 的 persist() 和 cache() 方法支持将 RDD 的数据缓存值内存或硬盘中
- 下次对同一 RDD 进行动作操作时,可以直接读取 RDD 的结果,大幅提高 Spark 的计算效率
- 缓存 RDD 时,其所有的依赖关系也会被一并保存
- 持久化的 RDD 有自动的容错机制
- 如果 RDD 的任一分区丢失了,通过使用原先创建它的转换操作,会被自动重算
- 持久化可以选择不同的存储级别,而 cache() 方法的默认值为 MEMORY_ONLY
1 | rdd = sc.parallelize([1, 2, 3, 4, 5]) |
持久化 vs Checkpoint
- Checkpoint 是在 Action 后执行的,相当于事务完成后备份结果
- 既然结果有了,之前的计算过程,即 RDD 的依赖链,也不需要了,不必保存
- 持久化(persist or cache)只是保存当前 RDD,并不要求在 Action 后调用
- 相当于事务的计算过程,还没有结果
- 既然没有结果,当需要恢复、重新计算时就需要重放计算过程,自然就不能放弃之前的依赖链,需要保存
- 需要恢复时,从最初或者最近的 Checkpoint 开始重新计算
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2024-09-21
Spark - Structured Streaming
背景 Spark Streaming 将无边界的流数据抽象成 DStream 按特定的时间间隔,把数据流分割成一个个 RDD 进行批处理 DStream API 与 RDD API 高度相似,拥有 RDD 的各种性质 DataSet/DataFrame DataSet/DataFrame 是高级 API,提供类似于 SQL 的查询接口,方便熟悉关系型数据库的开发人员使用 Spark SQL 执行引擎会自动优化 DataSet/DataFrame 程序 用 RDD API 开发的程序本质上需要开发人员手工构造 RDD 的 DAG 执行图,依赖于手工优化 如果拥有 DataSet/DataFrame API 的流处理模块 无需去用相对底层的 DStream API 去处理无边界数据,大大提升开发效率 在 2016 年,Spark 2.0 中推出结构化流处理的模块 - Structured Streaming Structured Streaming 基于 Spark SQL 引擎实现 在开发视角,流数据和静态数据没有区别,可以像批处理静态数据那样处理流...
2024-09-17
Spark - Overview
MapReduce概述 MapReduce 通过简单的 Map 和 Reduce 的抽象提供了一个编程模型 可以在一个由上百台机器组成的集群上并发处理大量的数据集,而把计算细节隐藏起来 各种各样的复杂数据处理都可以分解为 Map 和 Reduce 的基本元素 复杂的数据处理可以分解成由多个 Job(包含一个 Mapper 和一个 Reducer)组成的 DAG 然后,将每个 Mapper 和 Reducer 放到 Hadoop 集群上执行,得到最终结果 不足 高昂的维护成本 时间性能不达标 MapReduce 模型的抽象层次低 大量的底层逻辑需要开发者手工完成 - 用汇编语言开发游戏 只提供 Map 和 Reduce 操作 很多现实的数据处理场景并不适合用这个模型来描述 实现复杂的操作需要技巧,让整个工程变得庞大且难以维护 维护一个多任务协调的状态机成本很高,且扩展性很差 在 Hadoop 中,每个 Job 的计算结果都会存储在 HDFS 文件存储系统中 每一步计算都要进行硬盘的读取和写入,大大增加了系统的延迟 MapReduce 对于迭代算法的处理性能很差,而且非常耗资源 因...

2024-09-19
Spark - SQL
历史Hive 一开始,Hadoop/MapReduce 在企业生产中大量使用,在 HDFS 上积累了大量数据 MapReduce 对于开发者而言使用难度较大,大部分开发人员最熟悉的还是传统的关系型数据库 为了方便大多数开发人员使用 Hadoop,诞生了 Hive Hive 提供类似 SQL 的编程接口,HQL 经过语法解析、逻辑计划、物理计划转化成 MapReduce 程序执行 使得开发人员很容易对 HDFS 上存储的数据进行查询和分析 Shark 在 Spark 刚问世时,Spark 团队开发了 Shark 来支持用 SQL 来查询 Spark 的数据 Shark 的本质是 Hive,Shark 修改了 Hive 的内存管理模块,大幅优化了运行速度 Shark 依赖于 Hive,严重影响了 Spark 的发展,Spark 要定义一个统一的技术栈和完整的生态 依赖于 Hive 还会制约 Spark 各个组件的相互集成,Spark 无法利用 Spark 的特性进行深度优化 2014 年 7 月 1 日,Spark 团队将 Shark 交给 Hive 进行管理,即 Hive on Spa...

2024-09-20
Spark - Streaming
流处理 Spark SQL 中的 DataFrame API 和 DataSet API 都是基于批处理模式对静态数据进行处理 在 2013,Spark 的流处理组件 Spark Streaming 发布,现在的 Spark Streaming 已经非常成熟,应用非常广泛 原理 Spark Streaming 的原理与微积分的思想很类似 微分是无限细分,而积分是对无限细分的每一段进行求和 本质 - 将一个连续的问题转换成了无限个离散的问题 流处理的数据是一系列连续不断变化,且无边界的,永远无法预测下一秒的数据 Spark Streaming 用时间片拆分了无限的数据流 然后对每个数据片用类似于批处理的方法进行处理,输出的数据也是分块的 Spark Streaming 提供一个对于流数据的抽象 DStream DStream 可以由 Kafka、Flume 或者 HDFS 的流数据生成,也可以由别的 DStream 经过各种转换操作得到 底层 DStream 由多个序列化的 RDD 构成,按时间片(如一秒)切分成的每个数据单位都是一个 RDD Spark 核心引擎将对 DStream ...

2024-09-22
Big Data - Spark + Flink
Spark 实时性 无论是 Spark Streaming 还是 Structured Streaming,Spark 流处理的实时性还不够 无法应对实时性要求很高的流处理场景 Spark 的流处理是基于微批处理的思想 把流处理看做批处理的一种特殊形式,没接收到一个时间间隔的数据才会去处理 虽然在 Spark 2.3 中提出连续处理模型,但只支持有限的功能,并不能在大项目中使用 要在流处理的实时性提升,就不能继续用微批处理的模式,而是有数据数据就立即处理,不做等待 Apache Flink 采用了基于操作符(Operator)的连续流模型,可以做到微秒级别的延迟 Flink模型 Flink 中最核心的数据结构是 Stream,代表一个运行在多个分区上的并行流 在 Stream 上可以进行各种转换(Transformation)操作 与 Spark RDD 不同的是,Stream 代表一个数据流而不是静态数据的集合 Stream 所包含的数据随着时间增长而变化的 而且 Stream 上的转换操作都是逐条进行的 - 每当有新数据进入,整个流程都会被执行并更新结果 Flink 比 Spark...
2024-09-24
Beam - Paradigm
Why Apache Beam 本身并不是一个数据处理平台,本身也无法对数据进行处理 Apache Beam 所提供的是一个统一的编程模型思想 通过 Apache Beam 统一的 API 来编写处理逻辑,该处理逻辑会被转化为底层运行引擎相应的 API 去运行 SDK 会变,但背后的设计原理却不会改变 生态 Layer Desc Runner 现有的各种大数据处理平台,如 Apache Spark、Apache Flink 可移植的统一模型层 各个 Runner 将会依据中间抽象出来的模型思想Runner 将提供一套符合该模型的 APIs 出来,以供上层转换 SDK 提供不同语言版本的 API 来编写数据处理逻辑这些数据处理逻辑会被转换成 Runner 中相应的 API 来运行 基本概念 数据可以分成有界数据和无界数据 其中有界数据是无界数据的特例,可以将所有的数据抽象看作无界数据 每个数据都有两个时域,即事件时间和处理时间 处理无界数据时,数据会有延迟、丢失的情况 因此,无法保证是否接收完了所有发生在某一时刻之前的数据 - 事件时间 流处理必须在数据的完整性和数据...




