
Beam - PCollection
数据抽象
Spark RDD
- 不同的技术系统有不同的数据结构, 如在 C++ 中有 vector、unordered_map
- 几乎所有的 Beam 数据都能表达为 PCollection
- PCollection - Parallel Collection - 可并行计算的数据集,与 Spark RDD 非常类似
- 在一个分布式计算系统中,需要为用户隐藏实现细节,包括数据是怎样表达和存储的
- 数据可能来自于内存的数据,也可能来自于外部文件,或者来自于 MySQL 数据库
- 如果没有一个统一的数据抽象的话,开发者需要不停地修改代码,无法专注于业务逻辑
Coder
将数据类型进行序列化和反序列化,便于在网络上传输
- 需要为 PCollection 的元素编写 Coder
- Coder 的作用与 Beam 的本质紧密相关
- 计算流程最终会运行在一个分布式系统
- 所有的数据都可能在网络上的计算机之间相互传递
- Coder 就是告诉 Beam 如何将数据类型进行序列化和反序列化,以便于在网络上传输
- Coder 需要注册进全局的 CoderRegistry
- 为自定义的数据类型建立与 Coder 的对应关系,无需每次都手动指定
无序
- PCollection 的无序特性与分布式本质有关
- 一旦一个 PCollection 被分配到不同的机器上执行
- 为了保证最大的吞吐量,不同机器都是独立运行的
- 因此执行顺序无从得知
无固定大小
- Beam 要统一批处理和流处理,所以要统一表达有界数据和无界数据,因此 PCollection 并没有限制容量
- 一个 PCollection 可以是有界的,也可以是无界的
- 一个无界的 PCollection 表达了一个无限大小的数据集
- 一个 PCollection 是否有界,往往取决于它是如何产生的
- 从批处理的数据源(一个文件、一个数据库)中读取,就会产生有界的 PCollection
- 从流式或者持续更新的数据库中读取,如 pub/sub 或者 Kafka,会产生一个无界的 PCollection
- PCollection 的有界和无界特性会影响到 Beam 的数据处理方式
- 一个批处理作业往往处理有界的 PCollection,而无界的 PCollection 需要流式作业来连续处理
- Beam 也是用 Window 来分割持续更新的无界数据,一个流数据可以被持续地拆分成不同的小块
不可变性
- PCollection 不提供任何修改它所承载数据的方式
- 修改一个 PCollection 的唯一方式去 Transform
- Beam 的 PCollection 都是延迟执行的 - deferred execution
1 | PCollection<T1> p1 = ...; |
- p2 这个 PCollection 仅仅会记录下自己是由 doSomeWork 这个操作计算而来的,和计算自己所需要的数据 p1
- 运算操作的最终结果,仅仅只是生成一个 DAG,即执行计划 - execution plan
- DAG 是框架能够自动优化执行计划的核心
- PCollection 下的数据不可变性是因为改变本身毫无意义
- 由于 Beam 的分布式本质,想要去修改一个 PCollection 的底层表达数据,需要在多个机器上查找
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2024-09-24
Beam - Paradigm
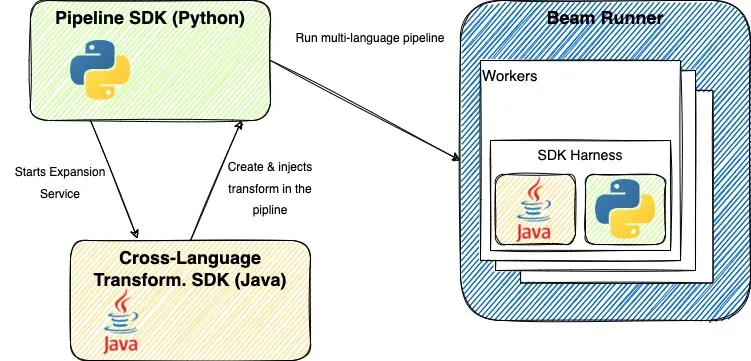
Why Apache Beam 本身并不是一个数据处理平台,本身也无法对数据进行处理 Apache Beam 所提供的是一个统一的编程模型思想 通过 Apache Beam 统一的 API 来编写处理逻辑,该处理逻辑会被转化为底层运行引擎相应的 API 去运行 SDK 会变,但背后的设计原理却不会改变 生态 Layer Desc Runner 现有的各种大数据处理平台,如 Apache Spark、Apache Flink 可移植的统一模型层 各个 Runner 将会依据中间抽象出来的模型思想Runner 将提供一套符合该模型的 APIs 出来,以供上层转换 SDK 提供不同语言版本的 API 来编写数据处理逻辑这些数据处理逻辑会被转换成 Runner 中相应的 API 来运行 基本概念 数据可以分成有界数据和无界数据 其中有界数据是无界数据的特例,可以将所有的数据抽象看作无界数据 每个数据都有两个时域,即事件时间和处理时间 处理无界数据时,数据会有延迟、丢失的情况 因此,无法保证是否接收完了所有发生在某一时刻之前的数据 - 事件时间 流处理必须在数据的完整性和数据...
2024-09-26
Beam - Transform
DAG Transform 是 Beam 中数据处理的最基本单元 Beam 把数据转换抽象成有向图 反直觉 - PCollection 是有向图中的边,而 Transform 是有向图中的节点 区分节点和边的关键是看一个 Transform 是不是有一个多余的输入和输出 每个 Transform 都可能有大于一个的输入 PCollection,也可能输出大于一个的输出 PCollection Apply Beam 中的 PCollection 有一个抽象的成员函数 Apply,使用任何一个 Transform 时,都需要调用 Apply 123final_collection = input_collection.apply(Transform1).apply(Transform2).apply(Transform3) Transform概述 ParDo - Parallel Do - 表达的是很通用的并行处理数据操作 GroupByKey - 把一个 Key/Value 的数据集按照 Key 归并 可以用 ParDo 实现 GroupByKey 简单实现 - 放...
2024-10-04
Beam - Streaming
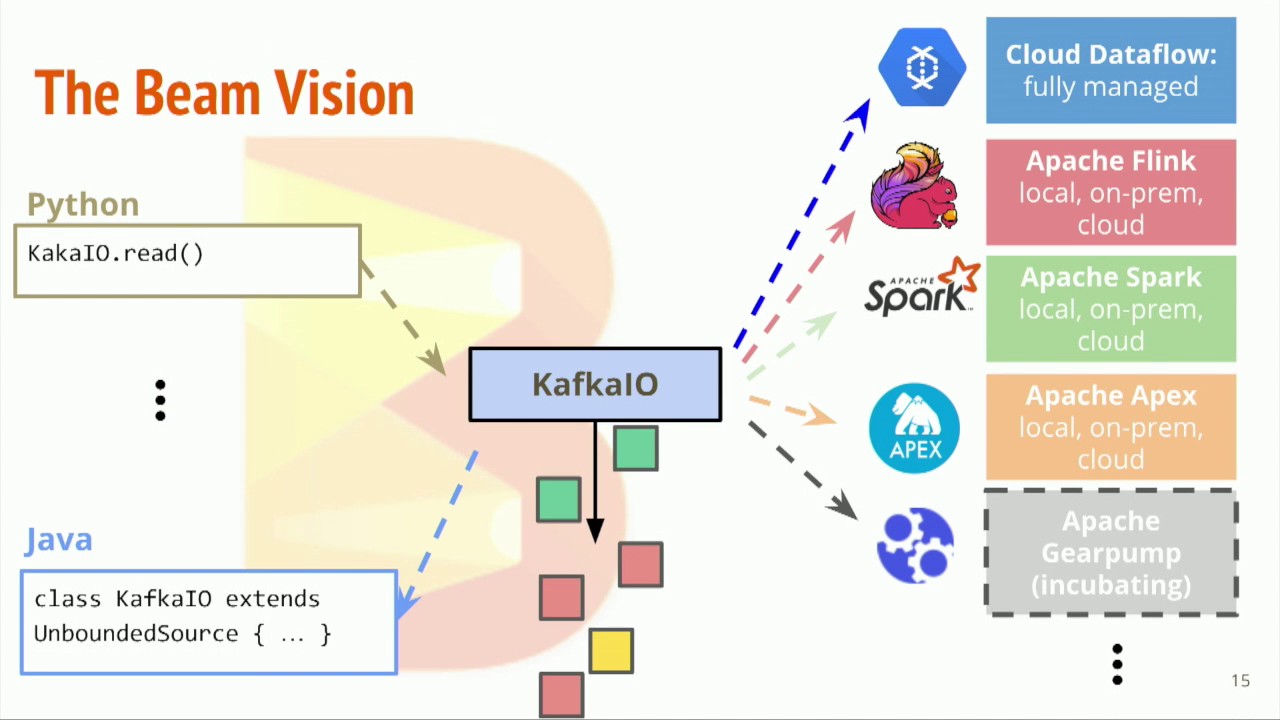
有界数据 vs 无界数据 在 Beam 中,可以用同一个 Pipeline 处理有界数据和无界数据 无论是有界数据还是无界数据,在 Beam 中,都可以用窗口把数据按时间分割成一些有限大小的集合 对于无界数据,必须使用窗口对数据进行分割,然后对每个窗口内的数据集进行处理 读取无界数据 withLogAppendTime - 使用 Kafka 的 log append time 作为 PCollection 的时间戳 12345678Pipeline pipeline = Pipeline.create();pipeline.apply( KafkaIO.<String, String>read() .withBootstrapServers("broker_1:9092,broker_2:9092") .withTopic("shakespeare") // use withTopics(List<String>) to read from multiple topics. .wi...

2024-09-23
Beam - Context
MapReduce架构思想 提供一套简洁的 API 来表达工程师数据处理的逻辑 在这套 API 底层嵌套一套扩展性很强的容错系统 计算模型 Map 计算模型从输入源中读取数据集合 这些数据经过用户所写的逻辑后生成一个临时的键值对数据集 MapReduce 计算模型会将拥有相同键的数据集集中起来发送到下一阶段,即 Shuffle 阶段 Reduce 接收从 Shuffle 阶段发送过来的数据集 在经过用户所写的逻辑后生成零个或多个结果 划时代意义 Map 和 Reduce 这两种抽象,其实可以适用于非常多的应用场景 MapReduce 的容错系统,可以让数据处理逻辑在分布式环境下有很好的扩展性(Scalability) 不足 使用 MapReduce 来解决一个工程问题,往往会涉及非常多的步骤 每次使用 MapReduce 时,都需要在分布式环境中启动机器来完成 Map 和 Reduce 步骤 并且需要启动 Master 机器来协调两个步骤的中间结果,存在不少的硬件资源开销 FlumeJava 将所有的数据都抽象成名为 PCollection 的数据结构 无论是从内存中读取的数据,...
2024-10-05
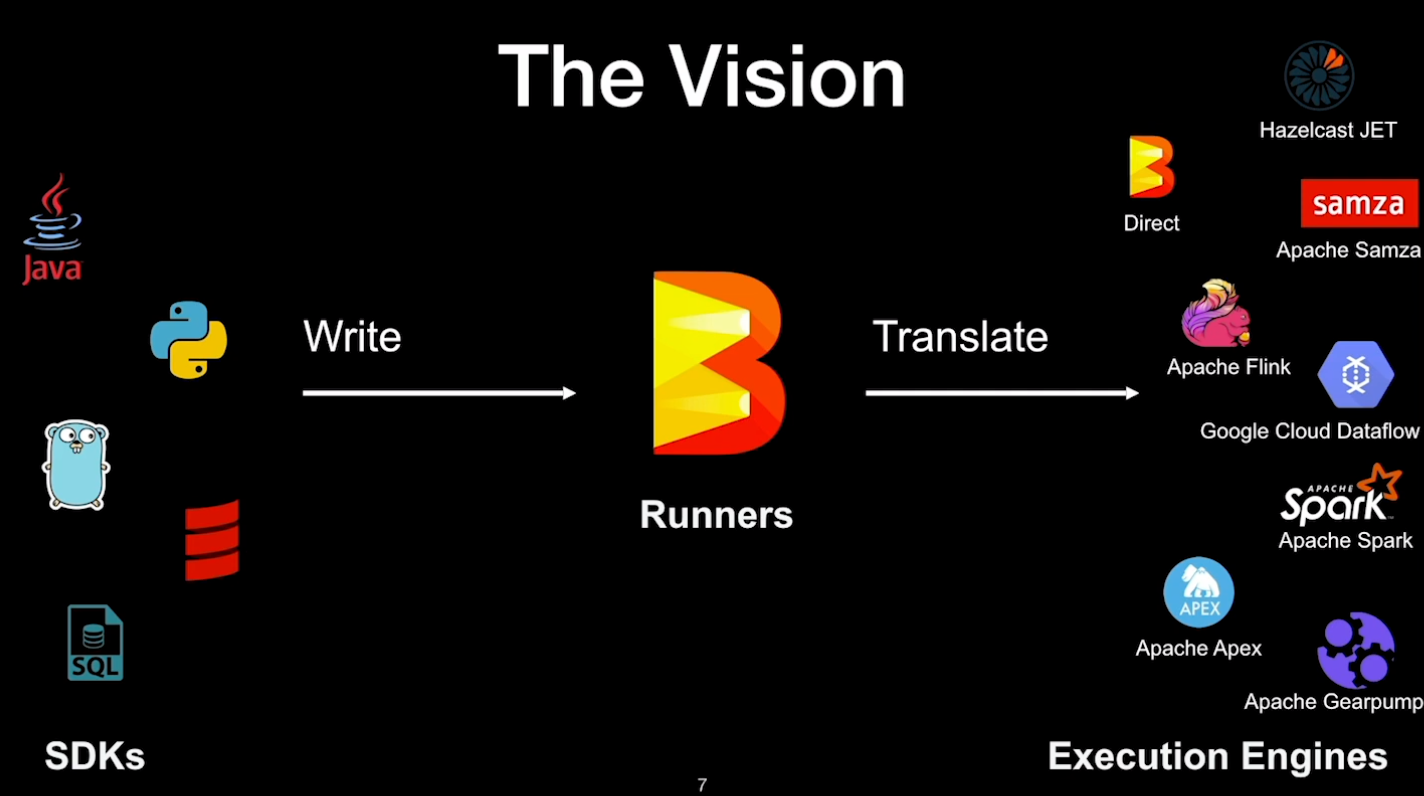
Beam - Future
技术迭代 2006,Apache Hadoop 发布,基于 MapReduce 计算模型 2009,Spark 计算框架在 加州伯克利大学诞生,于 2010 年开源,于 2014 年成为 Apache 的顶级项目 Spark 的数据处理效率远在 Hadoop 之上 2014,Flink 面世,流批一体,于 2018 年被阿里收购 Apache Beam Apache Beam 根据 Dataflow Model API 实现的,能完全胜任批流一体的任务 Apache Beam 有中间的抽象转换层,工程师无需学习新 Runner 的 API 的语法,减少学习新技术的时间成本 Runner 可以专心优化效率和迭代功能,而不必担心迁移 Beam Runner 迭代非常快 - 如 Flink
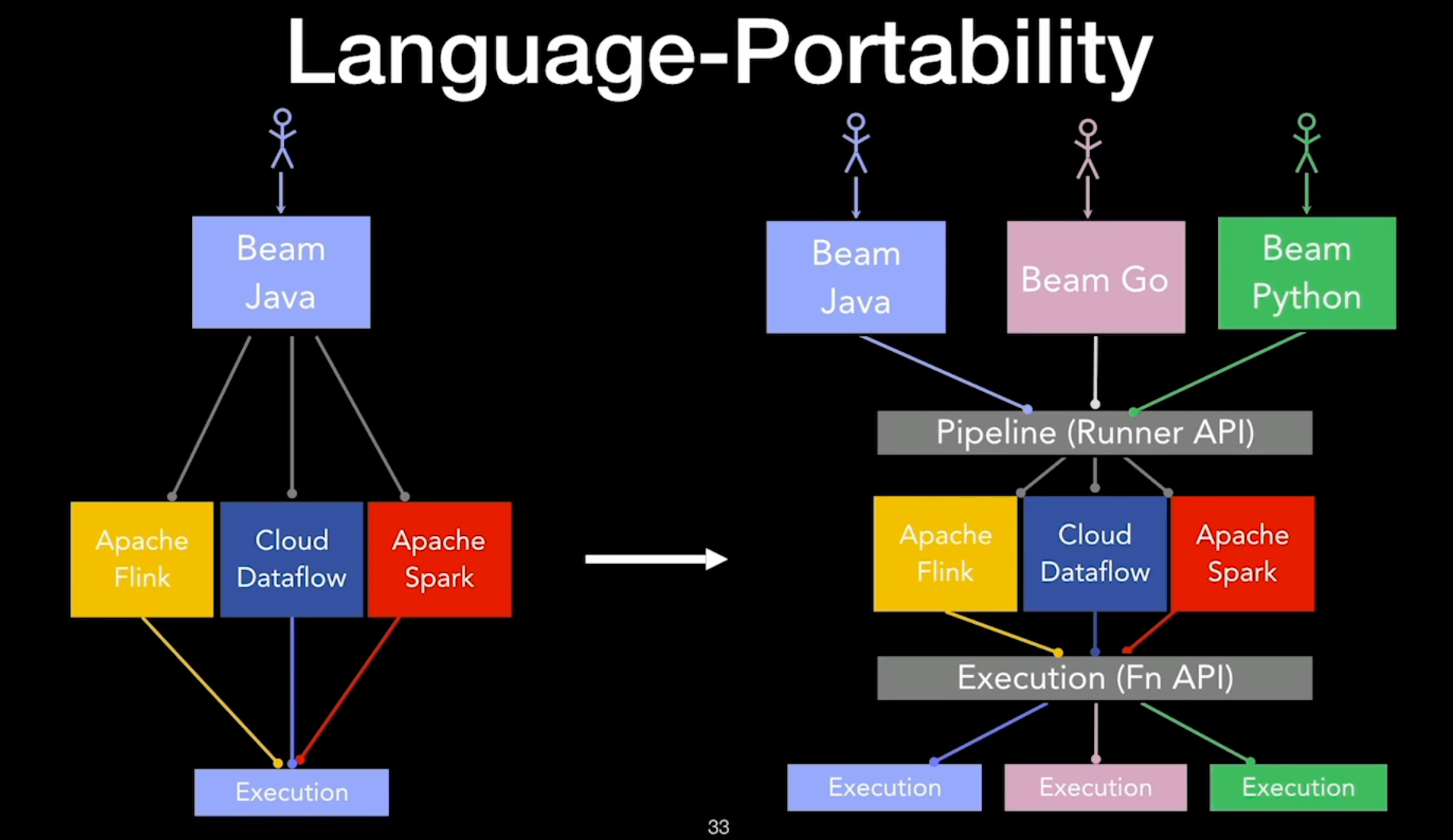
2024-10-01
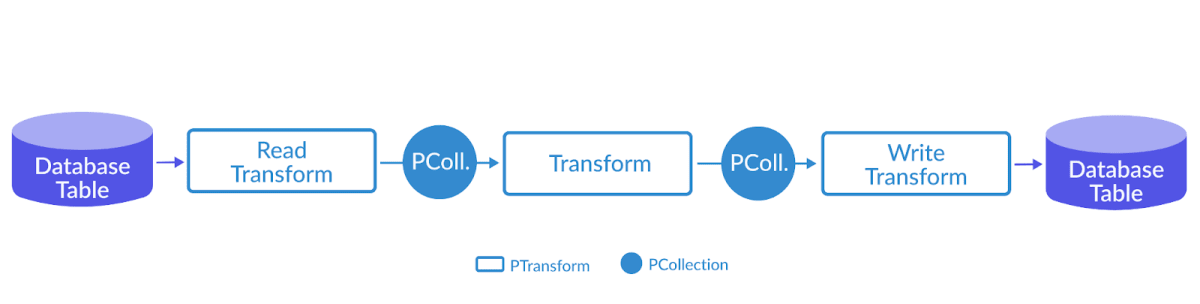
Beam - Execution Engine
Pipeline 读取输入数据到 PCollection 对读进来的 PCollection 进行 Transform,得到另一个 PCollection 输出结果 PCollection 1234567891011121314// Start by defining the options for the pipeline.PipelineOptions options = PipelineOptionsFactory.create();// Then create the pipeline.Pipeline pipeline = Pipeline.create(options);PCollection<String> lines = pipeline.apply( "ReadLines", TextIO.read().from("gs://some/inputData.txt"));PCollection<String> filteredLines = lines.apply(new FilterLines());filtere...




