
Beam - Pipeline
创建
- 在 Beam 中,所有的数据处理逻辑都会被抽象成 Pipeline 来运行
- Pipeline 是对数据处理逻辑的一个封装
- 包括一整套流程 - 读取数据集、将数据集转换成想要的结果、输出结果数据集
创建 Pipeline
1 | PipelineOptions options = PipelineOptionsFactory.create(); |
应用
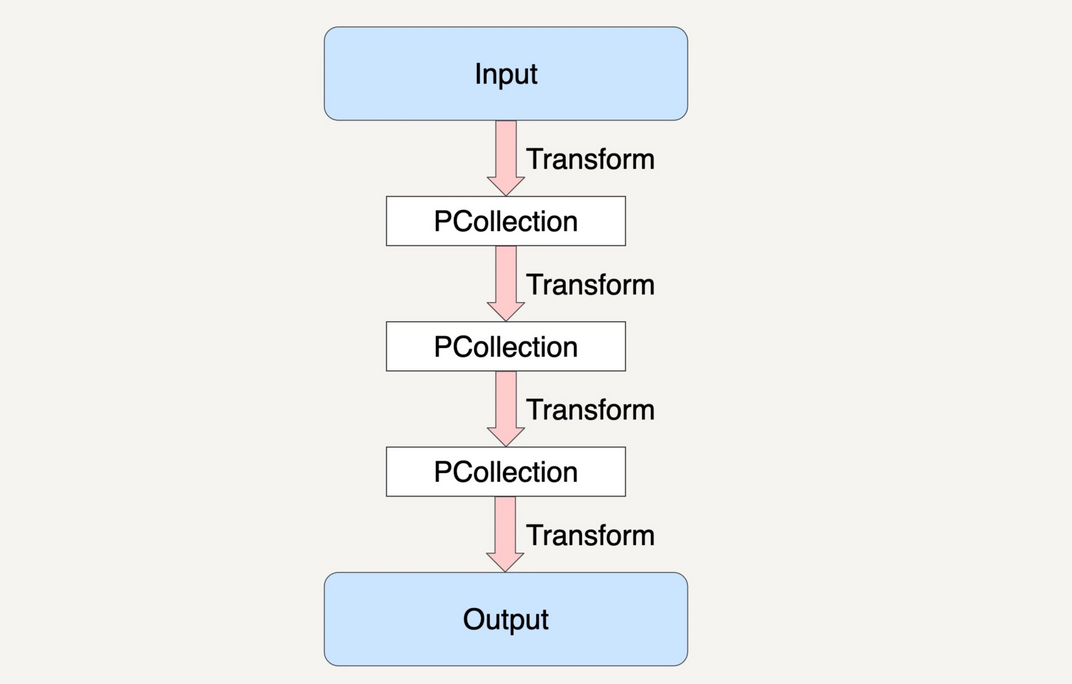
- PCollection 具有不可变性
- 一个 PCollection 一旦生成,就不能在增加或者删除里面的元素了
- 在 Beam 中,每次 PCollection 经过一个 Transform 之后,Pipeline 都会创建一个新的 PCollection
- 新创建的 PCollection 又成为下一个 Transform 的输入
- 原先的 PCollection 不会有任何改变
- 对同一个 PCollection 可以应用多种不同的 Transform
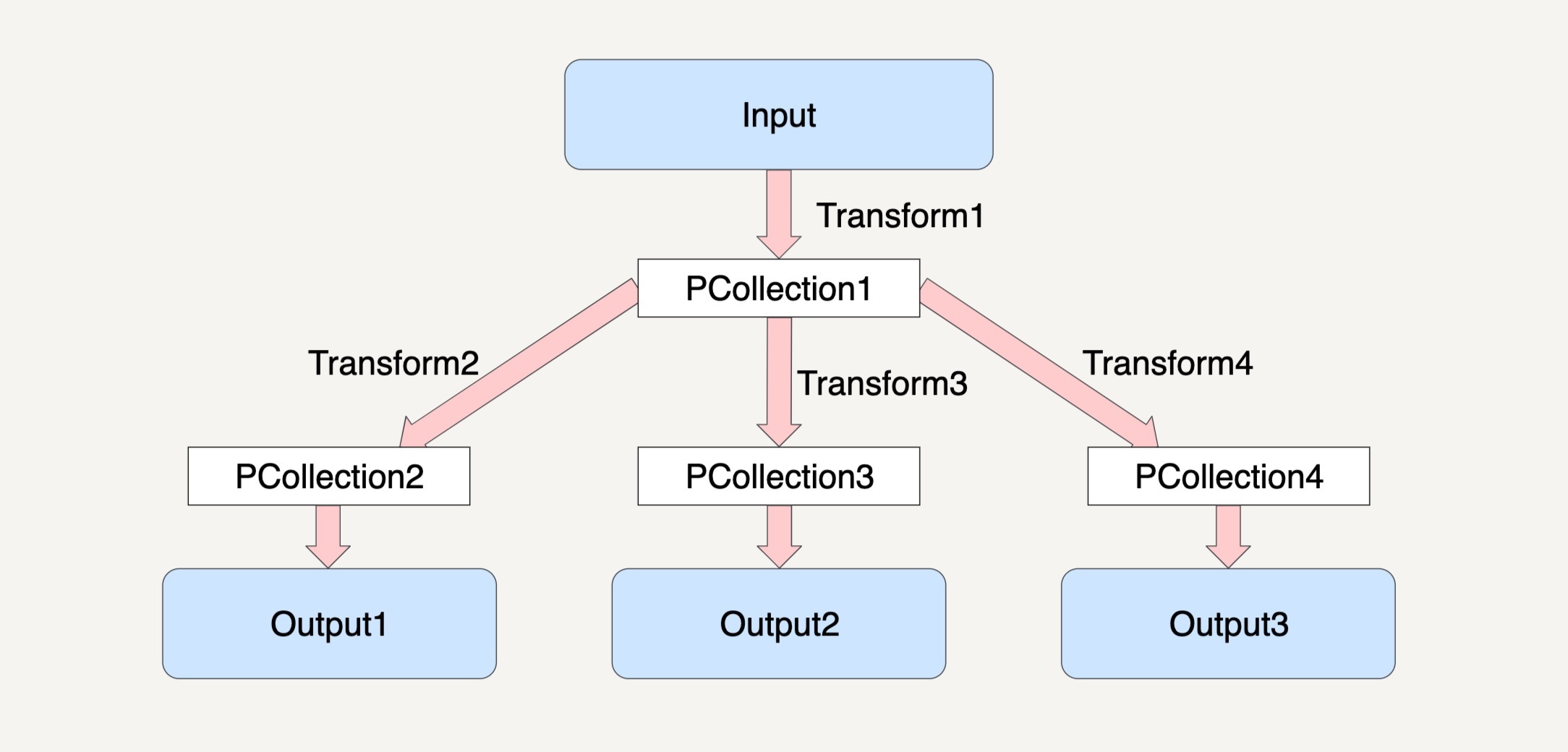
处理模型
- Pipeline 的底层思想依然是 MapReduce
- 在分布式环境下,整个 Pipeline 会启动 N 个 Workers 来同时处理 PCollection
- 在具体处理某个特定 Transform 时
- Pipeline 会将这个 Transform 的输入数据集 PCollection 中的元素分割成不同的 Bundle
- 并将这些 Bundle 分发到不同的 Worker 来处理
- Pipeline 具体会分配多少个 Worker,以及将一个 PCollection 分割成多少个 Bundle 都是随机的
- Pipeline 会尽可能地让整个处理流程达到完美并行 - Embarrassingly Parallel
- 在多步骤的 Transforms 中,一个 Bundle 通过一个 Transform 产生出来的结果作为下一个 Transform 的输入
- 每一个 Bundle 在一个 Worker 上经过 Transform 逻辑后,也会产生一个新的不可变的 Bundle
- 具有关联性的 Bundle,必须在同一个 Worker 上处理
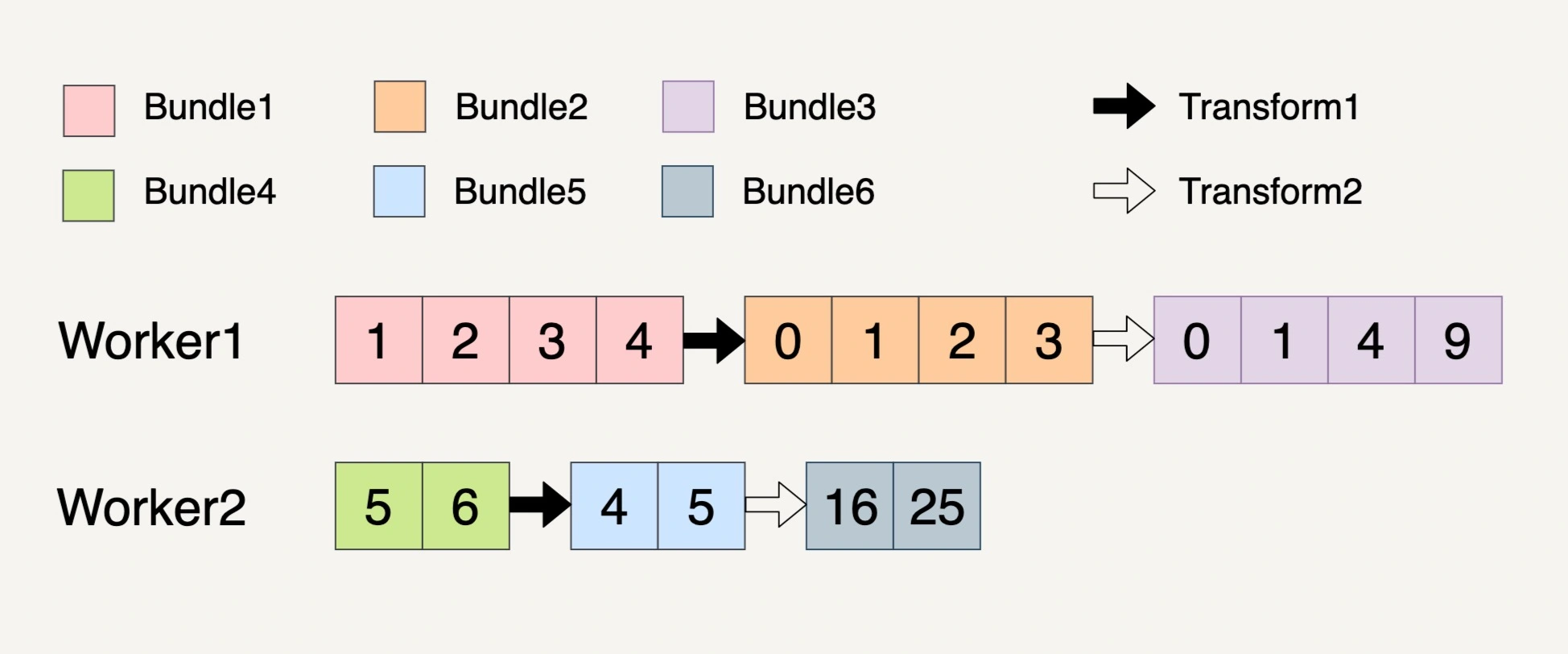
第一个 Transform 将元素的数值减 1;第二个 Transform 对元素的数值求平方
总共产生 6 个不可变的 Bundle,Bundle1~Bundle3 的整个过程都必须放在 Worker1 上完成,因为具有关联性
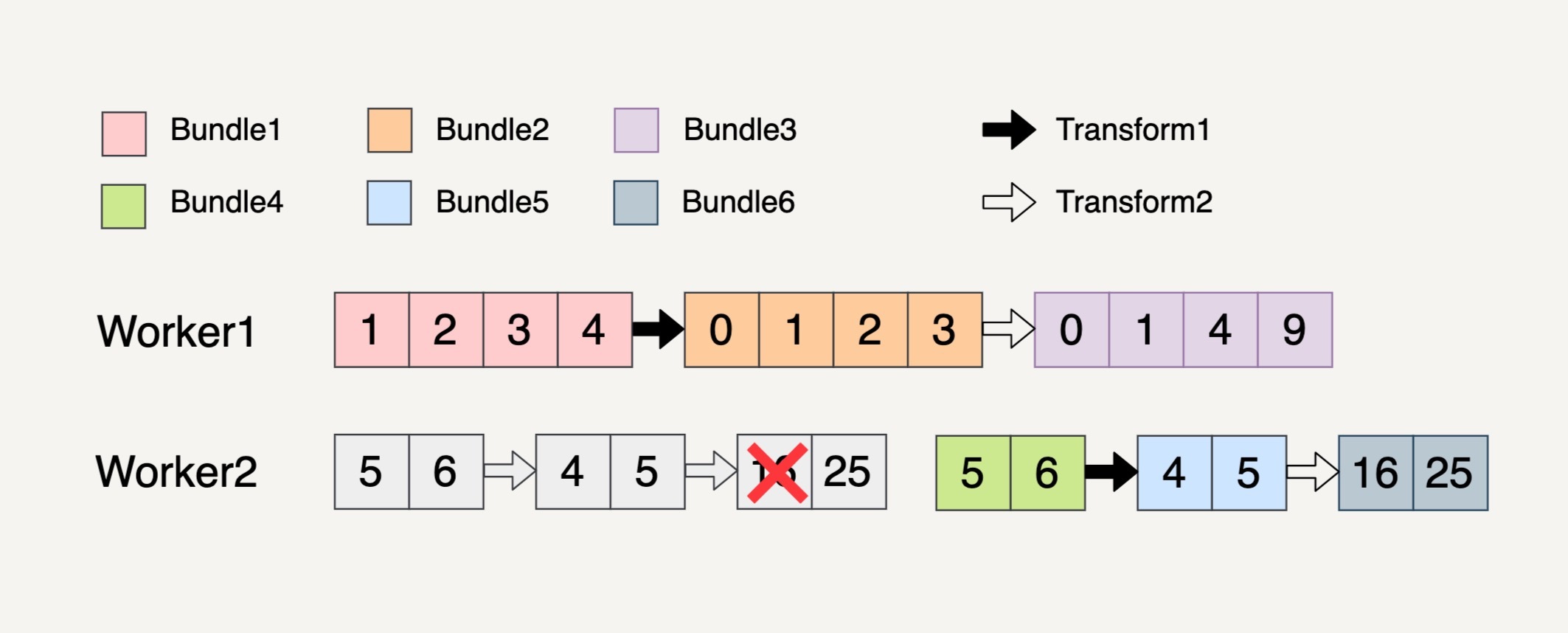
错误处理
单个 Transform 上的错误处理
- 如果某一个 Bundle 里面的元素因为任意原因导致处理失败,则整个 Bundle 里面的元素都必须重新处理
- 重新处理的 Bundle 不一定要在原来的 Worker 上执行,可能会转移到其它 Worker
多步骤 Transform 上的错误处理
- 如果处理的一个 Bundle 元素发生了错误
- 则这个元素所在的整个 Bundle 以及与这个 Bundle 有关联的所有 Bundle 都必须重新处理
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2024-10-03
Beam - Window
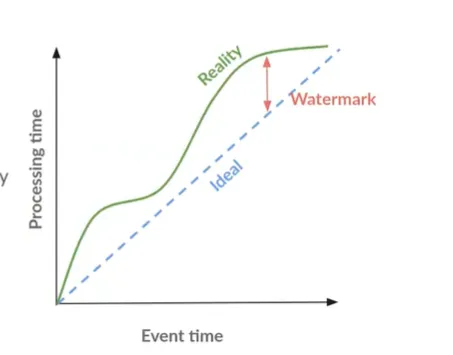
Window 在 Beam 中,Window 将 PCollection 里的每个元素根据时间戳划分成不同的有限数据集合 要将一些聚合操作应用在 PCollection 上时,或者对不同的 PCollection 进行 Join 操作 Beam 将这些操作应用在这些被 Window 划分好的不同的数据集上 无论是有界数据还是无界数据,Beam 都会按同样的规则进行处理 在用 IO Connector 读取有界数据集的过程中,Read Transform 会默认为每个元素分配一个相同的时间戳 一般情况下,该时间戳为运行 Pipeline 的时间,即处理时间 - Processing Time Beam 会为该 Pipeline 默认分配一个全局窗口 - Global Window - 从无限小到无限大的时间窗口 Global Window 可以显式将一个全局窗口赋予一个有界数据集 12PCollection<String> input = p.apply(TextIO.read().from(filepath));PCollection<String> batchI...
2024-09-24
Beam - Paradigm
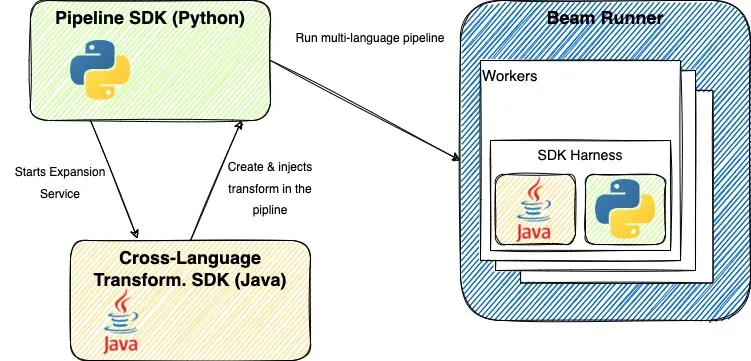
Why Apache Beam 本身并不是一个数据处理平台,本身也无法对数据进行处理 Apache Beam 所提供的是一个统一的编程模型思想 通过 Apache Beam 统一的 API 来编写处理逻辑,该处理逻辑会被转化为底层运行引擎相应的 API 去运行 SDK 会变,但背后的设计原理却不会改变 生态 Layer Desc Runner 现有的各种大数据处理平台,如 Apache Spark、Apache Flink 可移植的统一模型层 各个 Runner 将会依据中间抽象出来的模型思想Runner 将提供一套符合该模型的 APIs 出来,以供上层转换 SDK 提供不同语言版本的 API 来编写数据处理逻辑这些数据处理逻辑会被转换成 Runner 中相应的 API 来运行 基本概念 数据可以分成有界数据和无界数据 其中有界数据是无界数据的特例,可以将所有的数据抽象看作无界数据 每个数据都有两个时域,即事件时间和处理时间 处理无界数据时,数据会有延迟、丢失的情况 因此,无法保证是否接收完了所有发生在某一时刻之前的数据 - 事件时间 流处理必须在数据的完整性和数据...
2024-09-26
Beam - Transform
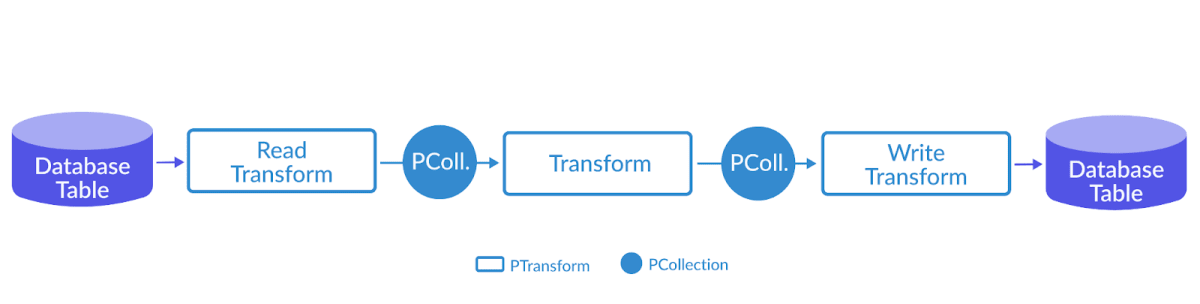
DAG Transform 是 Beam 中数据处理的最基本单元 Beam 把数据转换抽象成有向图 反直觉 - PCollection 是有向图中的边,而 Transform 是有向图中的节点 区分节点和边的关键是看一个 Transform 是不是有一个多余的输入和输出 每个 Transform 都可能有大于一个的输入 PCollection,也可能输出大于一个的输出 PCollection Apply Beam 中的 PCollection 有一个抽象的成员函数 Apply,使用任何一个 Transform 时,都需要调用 Apply 123final_collection = input_collection.apply(Transform1).apply(Transform2).apply(Transform3) Transform概述 ParDo - Parallel Do - 表达的是很通用的并行处理数据操作 GroupByKey - 把一个 Key/Value 的数据集按照 Key 归并 可以用 ParDo 实现 GroupByKey 简单实现 - 放...
2024-10-05
Beam - Future
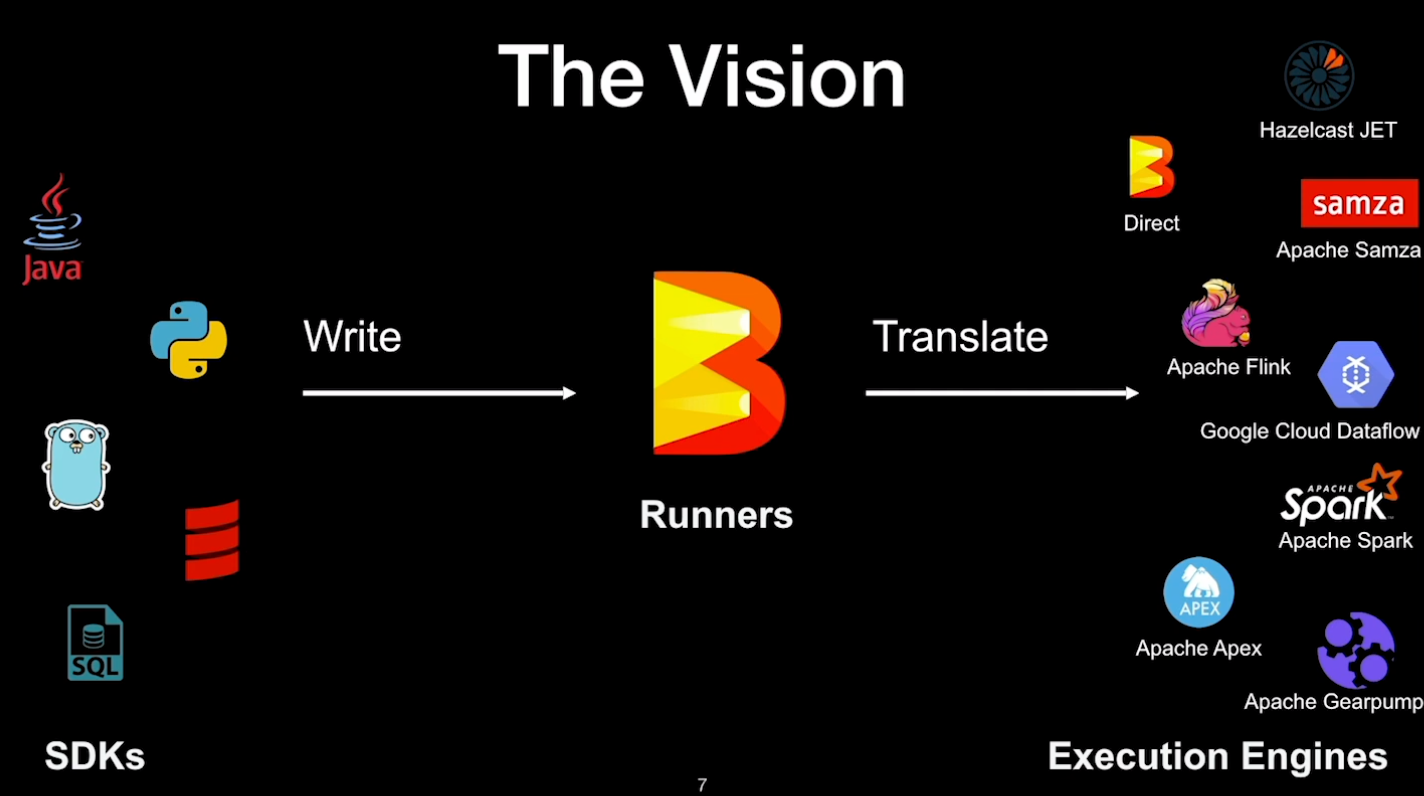
技术迭代 2006,Apache Hadoop 发布,基于 MapReduce 计算模型 2009,Spark 计算框架在 加州伯克利大学诞生,于 2010 年开源,于 2014 年成为 Apache 的顶级项目 Spark 的数据处理效率远在 Hadoop 之上 2014,Flink 面世,流批一体,于 2018 年被阿里收购 Apache Beam Apache Beam 根据 Dataflow Model API 实现的,能完全胜任批流一体的任务 Apache Beam 有中间的抽象转换层,工程师无需学习新 Runner 的 API 的语法,减少学习新技术的时间成本 Runner 可以专心优化效率和迭代功能,而不必担心迁移 Beam Runner 迭代非常快 - 如 Flink
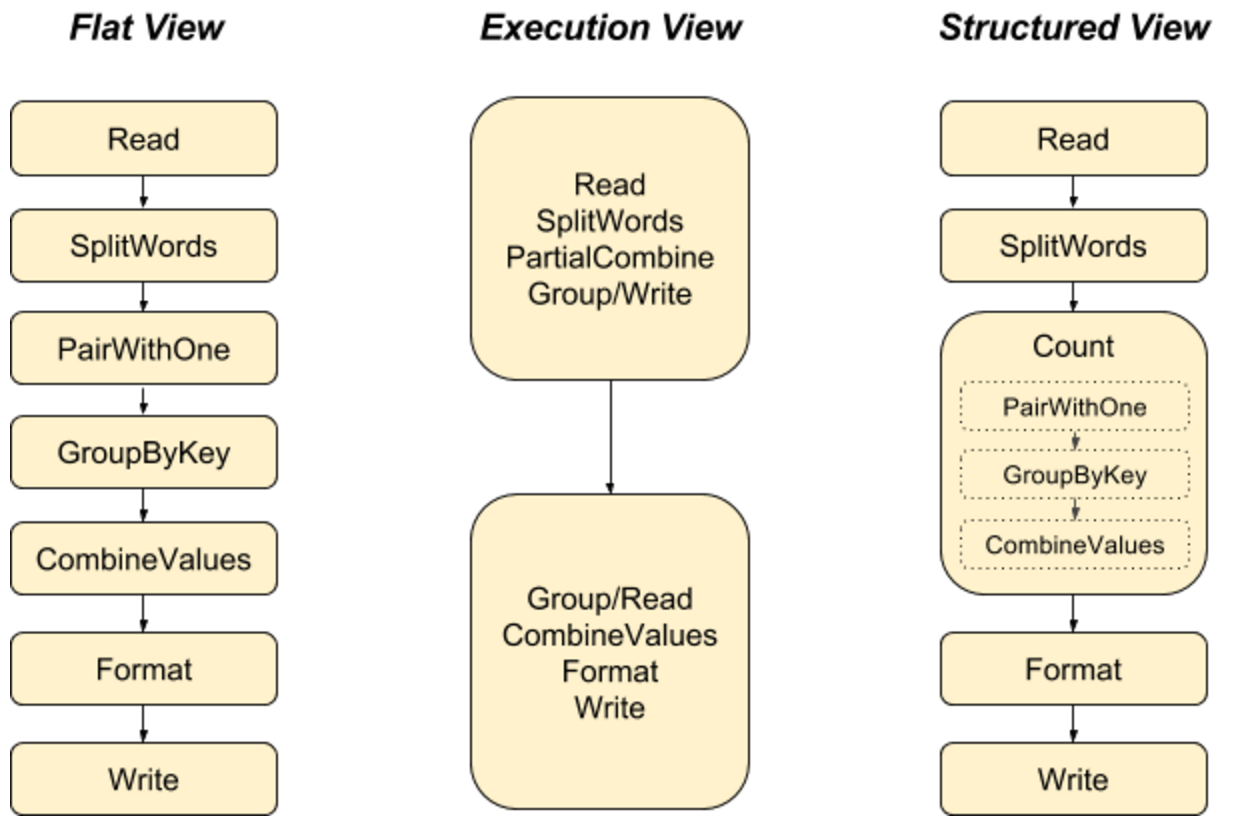
2024-10-02
Beam - WordCount
步骤 用 Pipeline IO 读取文本 用 Transform 对文本进行分词和词频统计 用 Pipeline IO 输出结果 将所有步骤打包成一个 Pipeline 创建 Pipeline 默认情况下,将采用 DirectRunner 在本地运行 1PipelineOptions options = PipelineOptionsFactory.create(); 一个 Pipeline 实例会构建数据处理的 DAG,以及这个 DAG 所需要的 Transform 1Pipeline p = Pipeline.create(options); 应用 Transform TextIO.Read - 读取外部文件,生成一个 PCollection,包含所有文本行,每个元素都是文本中的一行 123String filepattern = "file:///Users/zhongmingmao/workspace/java/hello-beam/corpus/shakespeare.txt";PCollection<String> lines = ...
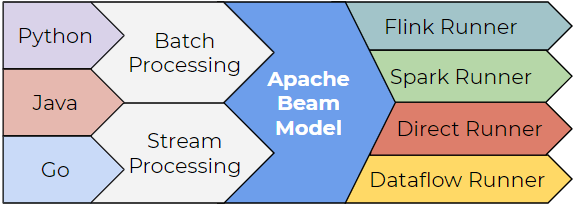
2024-09-30
Beam - Pipeline Test
Context 设计好的 Pipeline 通常需要放在分布式环境下执行,具体每一步的 Transform 都会被分配到任意机器上执行 如果 Pipeline 运行出错,则需要定位到具体机器,再到上面去做调试是不现实的 另一种办法,读取一些样本数据集,再运行整个 Pipeline 去验证哪一步逻辑出错 - 费时费力 正式将 Pipeline 放在分布式环境上运行之前,需要先完整地测试整个 Pipeline 逻辑 Solution Beam 提供了一套完整的测试 SDK 可以在开发 Pipeline 的同时,能够实现对一个 Transform 逻辑的单元测试 也可以对整个 Pipeline 的 End-to-End 测试 在 Beam 所支持的各种 Runners 中,有一个 DirectRunner DirectRunner 即本地机器,整个 Pipeline 会放在本地机器上运行 DoFnTester - 让用户传入一个自定义函数来进行测试 - UDF - User Defined Function DoFnTester 接收的对象是用户继承实现的 DoFn 不应该将 DoFn 当成...




