
Beam - Pipeline Test
Context
- 设计好的 Pipeline 通常需要放在分布式环境下执行,具体每一步的 Transform 都会被分配到任意机器上执行
- 如果 Pipeline 运行出错,则需要定位到具体机器,再到上面去做调试是不现实的
- 另一种办法,读取一些样本数据集,再运行整个 Pipeline 去验证哪一步逻辑出错 - 费时费力
- 正式将 Pipeline 放在分布式环境上运行之前,需要先完整地测试整个 Pipeline 逻辑
Solution
- Beam 提供了一套完整的测试 SDK
- 可以在开发 Pipeline 的同时,能够实现对一个 Transform 逻辑的单元测试
- 也可以对整个 Pipeline 的 End-to-End 测试
- 在 Beam 所支持的各种 Runners 中,有一个 DirectRunner
- DirectRunner 即本地机器,整个 Pipeline 会放在本地机器上运行
- DoFnTester - 让用户传入一个自定义函数来进行测试 - UDF - User Defined Function
- DoFnTester 接收的对象是用户继承实现的 DoFn
- 不应该将 DoFn 当成一个单元来进行测试
- 在 Beam 中,数据转换的逻辑都是被抽象成 Transform,而不是 Transform 里面的 ParDo 的具体实现
- 一个简单的 Transform 可以用一个 ParDo 来表示
- 每个 Runner 具体怎么运行这些 ParDo,对用户来说应该是透明的
- 从 Beam 2.4.0 后,DoFnTester 被标记为 Deprecated,推荐使用 TestPipeline
Unit
- 创建 TestPipeline 实例
- 创建一个静态的、用于测试的输入数据集
- 使用 Create Transform 来创建一个 PCollection 作为输入数据集
- 在测试数据集上调用业务实现的 Transform 并将结果保存在一个 PCollection 上
- 使用 PAssert 类的相关函数来验证输出的 PCollection 是否符合预期
继承 DoFn 类来实现一个产生偶数的 Transform,输入和输出的数据类型都是 Integer
1 | static class EvenNumberFn extends DoFn<Integer, Integer> { |
创建 TestPipeline 实例
1 | ... |
创建静态输入数据集
1 | ... |
使用 Create Transform 创建 PCollection
Create Transform - 将 Java Collection 的数据转换成 Beam 的数据抽象 PCollection
1 | ... |
调用业务 Transform 的处理逻辑
1 | ... |
验证输出结果 - PAssert
1 | ... |
运行 TestPipeline - PAssert 必须在 TestPipeline.run 之前
1 | final class TestClass { |
End-to-End
- 现实应用中,一般都是多步骤 Pipeline,可能会涉及到多个输入数据集,也可能会有多个输出
- 在 Beam 中,端到端的测试与 Transform 的单元测试非常相似
- 唯一不同点,需要为所有的输入数据集创建测试集,而不仅仅只针对一个 Transform
- 对于 Pipeline 中每个应用到 Write Transform 的地方,都需要用到 PAssert 来验证数据集
步骤
- 创建 TestPipeline 实例
- 对于多步骤 Pipeline 的每个输入数据源,创建相对应的静态测试数据集
- 使用 Create Transform,将所有的静态测试数据集转换成 PCollection 作为输入数据集
- 按照真实的 Pipeline 逻辑,调用所有的 Transforms 操作
- 在 Pipeline 中所有应用到 Write Transform 的地方,都使用 PAssert 来替换 Write Transform
- 并验证输出的结果是否符合预期
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2024-09-23
Beam - Context
MapReduce架构思想 提供一套简洁的 API 来表达工程师数据处理的逻辑 在这套 API 底层嵌套一套扩展性很强的容错系统 计算模型 Map 计算模型从输入源中读取数据集合 这些数据经过用户所写的逻辑后生成一个临时的键值对数据集 MapReduce 计算模型会将拥有相同键的数据集集中起来发送到下一阶段,即 Shuffle 阶段 Reduce 接收从 Shuffle 阶段发送过来的数据集 在经过用户所写的逻辑后生成零个或多个结果 划时代意义 Map 和 Reduce 这两种抽象,其实可以适用于非常多的应用场景 MapReduce 的容错系统,可以让数据处理逻辑在分布式环境下有很好的扩展性(Scalability) 不足 使用 MapReduce 来解决一个工程问题,往往会涉及非常多的步骤 每次使用 MapReduce 时,都需要在分布式环境中启动机器来完成 Map 和 Reduce 步骤 并且需要启动 Master 机器来协调两个步骤的中间结果,存在不少的硬件资源开销 FlumeJava 将所有的数据都抽象成名为 PCollection 的数据结构 无论是从内存中读取的数据,...
2024-09-26
Beam - Transform
DAG Transform 是 Beam 中数据处理的最基本单元 Beam 把数据转换抽象成有向图 反直觉 - PCollection 是有向图中的边,而 Transform 是有向图中的节点 区分节点和边的关键是看一个 Transform 是不是有一个多余的输入和输出 每个 Transform 都可能有大于一个的输入 PCollection,也可能输出大于一个的输出 PCollection Apply Beam 中的 PCollection 有一个抽象的成员函数 Apply,使用任何一个 Transform 时,都需要调用 Apply 123final_collection = input_collection.apply(Transform1).apply(Transform2).apply(Transform3) Transform概述 ParDo - Parallel Do - 表达的是很通用的并行处理数据操作 GroupByKey - 把一个 Key/Value 的数据集按照 Key 归并 可以用 ParDo 实现 GroupByKey 简单实现 - 放...
2024-10-01
Beam - Execution Engine
Pipeline 读取输入数据到 PCollection 对读进来的 PCollection 进行 Transform,得到另一个 PCollection 输出结果 PCollection 1234567891011121314// Start by defining the options for the pipeline.PipelineOptions options = PipelineOptionsFactory.create();// Then create the pipeline.Pipeline pipeline = Pipeline.create(options);PCollection<String> lines = pipeline.apply( "ReadLines", TextIO.read().from("gs://some/inputData.txt"));PCollection<String> filteredLines = lines.apply(new FilterLines());filtere...
2024-09-28
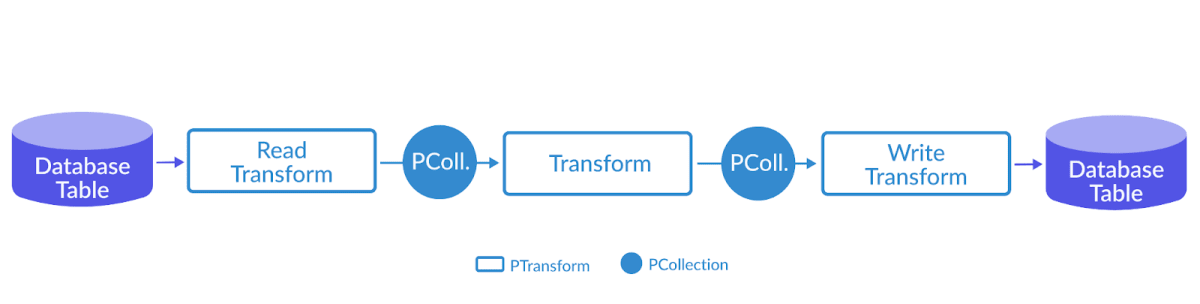
Beam - Pipeline IO
读取数据集 一个输入数据集的读取通常是通过 Read Transform 来完成 Read Transform 从外部源读取数据 - 本地文件、数据库、OSS、MQ Read Transform 返回一个 PCollection,该 PCollection 可以作为一个输入数据集,应用在各种 Transform 上 Pipeline 没有限制调用 Read Transform 的时机 可以在 Pipeline 最开始的时候调用 也可以在经过 N 个步骤的 Transforms 后再调用它来读取另外的数据集 本地文件 1PCollection<String> inputs = p.apply(TextIO.read().from(filepath)); Beam 支持从多个文件路径中读取数据集,文件名匹配规则与 Linux glob 一样 glob 操作符的匹配规则最终要和所使用的底层文件系统挂钩 从不同的外部源读取同一类型的数据来统一作为输入数据集 - 利用 flatten 操作将数据集合并 12345PCollection<String> input1 ...
2024-10-03
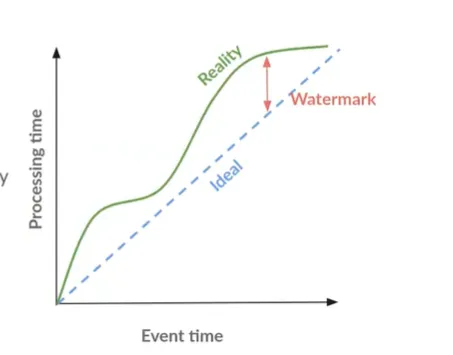
Beam - Window
Window 在 Beam 中,Window 将 PCollection 里的每个元素根据时间戳划分成不同的有限数据集合 要将一些聚合操作应用在 PCollection 上时,或者对不同的 PCollection 进行 Join 操作 Beam 将这些操作应用在这些被 Window 划分好的不同的数据集上 无论是有界数据还是无界数据,Beam 都会按同样的规则进行处理 在用 IO Connector 读取有界数据集的过程中,Read Transform 会默认为每个元素分配一个相同的时间戳 一般情况下,该时间戳为运行 Pipeline 的时间,即处理时间 - Processing Time Beam 会为该 Pipeline 默认分配一个全局窗口 - Global Window - 从无限小到无限大的时间窗口 Global Window 可以显式将一个全局窗口赋予一个有界数据集 12PCollection<String> input = p.apply(TextIO.read().from(filepath));PCollection<String> batchI...
2024-09-29
Beam - Pattern
Copier Pattern 每个数据处理模块的输入都是相同的,并且每个数据处理模块都可以单独并且同步地运行处理 1234567891011121314151617181920212223242526272829303132333435363738394041PCollection<Video> videoDataCollection = ...;// 生成高画质视频PCollection<Video> highResolutionVideoCollection = videoDataCollection.apply("highResolutionTransform", ParDo.of(new DoFn<Video, Video>(){ @ProcessElement public void processElement(ProcessContext c) { c.output(generateHighResolution(c.element())); }}));// 生成低画质视频...




