
Beam - Streaming
有界数据 vs 无界数据
- 在 Beam 中,可以用同一个 Pipeline 处理有界数据和无界数据
- 无论是有界数据还是无界数据,在 Beam 中,都可以用窗口把数据按时间分割成一些有限大小的集合
- 对于无界数据,必须使用窗口对数据进行分割,然后对每个窗口内的数据集进行处理
读取无界数据
withLogAppendTime - 使用 Kafka 的 log append time 作为 PCollection 的时间戳
1 | Pipeline pipeline = Pipeline.create(); |
PCollection + Timestamp
- 一般情况下,窗口的使用场景中,时间戳都是原生的
- 从 Kafka 读取消息记录,每一条 Kafka 消息都有时间戳
- Beam 允许手动给 PCollection 中的元素添加时间戳
1 | 2019-07-05: HAMLET |
outputWithTimestamp - 对每一个 PCollection 中的元素附上它所对应的时间戳
1 | static class ExtractTimestampFn extends DoFn<String, String> { |
PCollection + Window
- 在无界数据的应用场景中,时间戳往往是数据记录自带的
- 在有界数据的应用场景中,时间戳往往需要指定的
- PCollection 元素有了时间戳后,就能根据时间戳应用窗口对数据进行划分 - 固定、滑动、会话
- 将特定的窗口应用到 PCollection 上,同样使用 PCollection 的 apply 方法
1 | PCollection<String> windowedWords = input |
复用 DoFn 和 PTransform
- Beam 的 Transform 不区分有界数据还是无界数据,可以直接复用
- 应用了窗口后,Beam 的 Transform 是在每个窗口内进行数据处理
1 | PCollection<KV<String, Long>> wordCounts = windowedWords.apply(new WordCount.CountWords()); |
输出无界数据
输出结果也是针对每个窗口的
1 | pipeline.apply("Write to PubSub", PubsubIO.writeStrings().to(options.getOutputTopic())); |
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2024-10-02
Beam - WordCount
步骤 用 Pipeline IO 读取文本 用 Transform 对文本进行分词和词频统计 用 Pipeline IO 输出结果 将所有步骤打包成一个 Pipeline 创建 Pipeline 默认情况下,将采用 DirectRunner 在本地运行 1PipelineOptions options = PipelineOptionsFactory.create(); 一个 Pipeline 实例会构建数据处理的 DAG,以及这个 DAG 所需要的 Transform 1Pipeline p = Pipeline.create(options); 应用 Transform TextIO.Read - 读取外部文件,生成一个 PCollection,包含所有文本行,每个元素都是文本中的一行 123String filepattern = "file:///Users/zhongmingmao/workspace/java/hello-beam/corpus/shakespeare.txt";PCollection<String> lines = ...
2024-09-26
Beam - Transform
DAG Transform 是 Beam 中数据处理的最基本单元 Beam 把数据转换抽象成有向图 反直觉 - PCollection 是有向图中的边,而 Transform 是有向图中的节点 区分节点和边的关键是看一个 Transform 是不是有一个多余的输入和输出 每个 Transform 都可能有大于一个的输入 PCollection,也可能输出大于一个的输出 PCollection Apply Beam 中的 PCollection 有一个抽象的成员函数 Apply,使用任何一个 Transform 时,都需要调用 Apply 123final_collection = input_collection.apply(Transform1).apply(Transform2).apply(Transform3) Transform概述 ParDo - Parallel Do - 表达的是很通用的并行处理数据操作 GroupByKey - 把一个 Key/Value 的数据集按照 Key 归并 可以用 ParDo 实现 GroupByKey 简单实现 - 放...
2024-09-24
Beam - Paradigm
Why Apache Beam 本身并不是一个数据处理平台,本身也无法对数据进行处理 Apache Beam 所提供的是一个统一的编程模型思想 通过 Apache Beam 统一的 API 来编写处理逻辑,该处理逻辑会被转化为底层运行引擎相应的 API 去运行 SDK 会变,但背后的设计原理却不会改变 生态 Layer Desc Runner 现有的各种大数据处理平台,如 Apache Spark、Apache Flink 可移植的统一模型层 各个 Runner 将会依据中间抽象出来的模型思想Runner 将提供一套符合该模型的 APIs 出来,以供上层转换 SDK 提供不同语言版本的 API 来编写数据处理逻辑这些数据处理逻辑会被转换成 Runner 中相应的 API 来运行 基本概念 数据可以分成有界数据和无界数据 其中有界数据是无界数据的特例,可以将所有的数据抽象看作无界数据 每个数据都有两个时域,即事件时间和处理时间 处理无界数据时,数据会有延迟、丢失的情况 因此,无法保证是否接收完了所有发生在某一时刻之前的数据 - 事件时间 流处理必须在数据的完整性和数据...
2024-10-03
Beam - Window
Window 在 Beam 中,Window 将 PCollection 里的每个元素根据时间戳划分成不同的有限数据集合 要将一些聚合操作应用在 PCollection 上时,或者对不同的 PCollection 进行 Join 操作 Beam 将这些操作应用在这些被 Window 划分好的不同的数据集上 无论是有界数据还是无界数据,Beam 都会按同样的规则进行处理 在用 IO Connector 读取有界数据集的过程中,Read Transform 会默认为每个元素分配一个相同的时间戳 一般情况下,该时间戳为运行 Pipeline 的时间,即处理时间 - Processing Time Beam 会为该 Pipeline 默认分配一个全局窗口 - Global Window - 从无限小到无限大的时间窗口 Global Window 可以显式将一个全局窗口赋予一个有界数据集 12PCollection<String> input = p.apply(TextIO.read().from(filepath));PCollection<String> batchI...
2024-09-25
Beam - PCollection
数据抽象 Spark RDD 不同的技术系统有不同的数据结构, 如在 C++ 中有 vector、unordered_map 几乎所有的 Beam 数据都能表达为 PCollection PCollection - Parallel Collection - 可并行计算的数据集,与 Spark RDD 非常类似 在一个分布式计算系统中,需要为用户隐藏实现细节,包括数据是怎样表达和存储的 数据可能来自于内存的数据,也可能来自于外部文件,或者来自于 MySQL 数据库 如果没有一个统一的数据抽象的话,开发者需要不停地修改代码,无法专注于业务逻辑 Coder 将数据类型进行序列化和反序列化,便于在网络上传输 需要为 PCollection 的元素编写 Coder Coder 的作用与 Beam 的本质紧密相关 计算流程最终会运行在一个分布式系统 所有的数据都可能在网络上的计算机之间相互传递 Coder 就是告诉 Beam 如何将数据类型进行序列化和反序列化,以便于在网络上传输 Coder 需要注册进全局的 CoderRegistry 为自定义的数据类型建立与 Coder 的对应关系,无...
2024-09-28
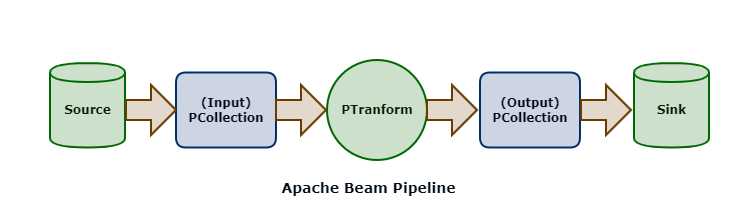
Beam - Pipeline IO
读取数据集 一个输入数据集的读取通常是通过 Read Transform 来完成 Read Transform 从外部源读取数据 - 本地文件、数据库、OSS、MQ Read Transform 返回一个 PCollection,该 PCollection 可以作为一个输入数据集,应用在各种 Transform 上 Pipeline 没有限制调用 Read Transform 的时机 可以在 Pipeline 最开始的时候调用 也可以在经过 N 个步骤的 Transforms 后再调用它来读取另外的数据集 本地文件 1PCollection<String> inputs = p.apply(TextIO.read().from(filepath)); Beam 支持从多个文件路径中读取数据集,文件名匹配规则与 Linux glob 一样 glob 操作符的匹配规则最终要和所使用的底层文件系统挂钩 从不同的外部源读取同一类型的数据来统一作为输入数据集 - 利用 flatten 操作将数据集合并 12345PCollection<String> input1 ...




