
MQ - Concept
消息管道
在系统架构中,MQ 的定位是消息和管道,主要起到解耦上下游系统,数据缓存的作用,主要操作为生产和消息
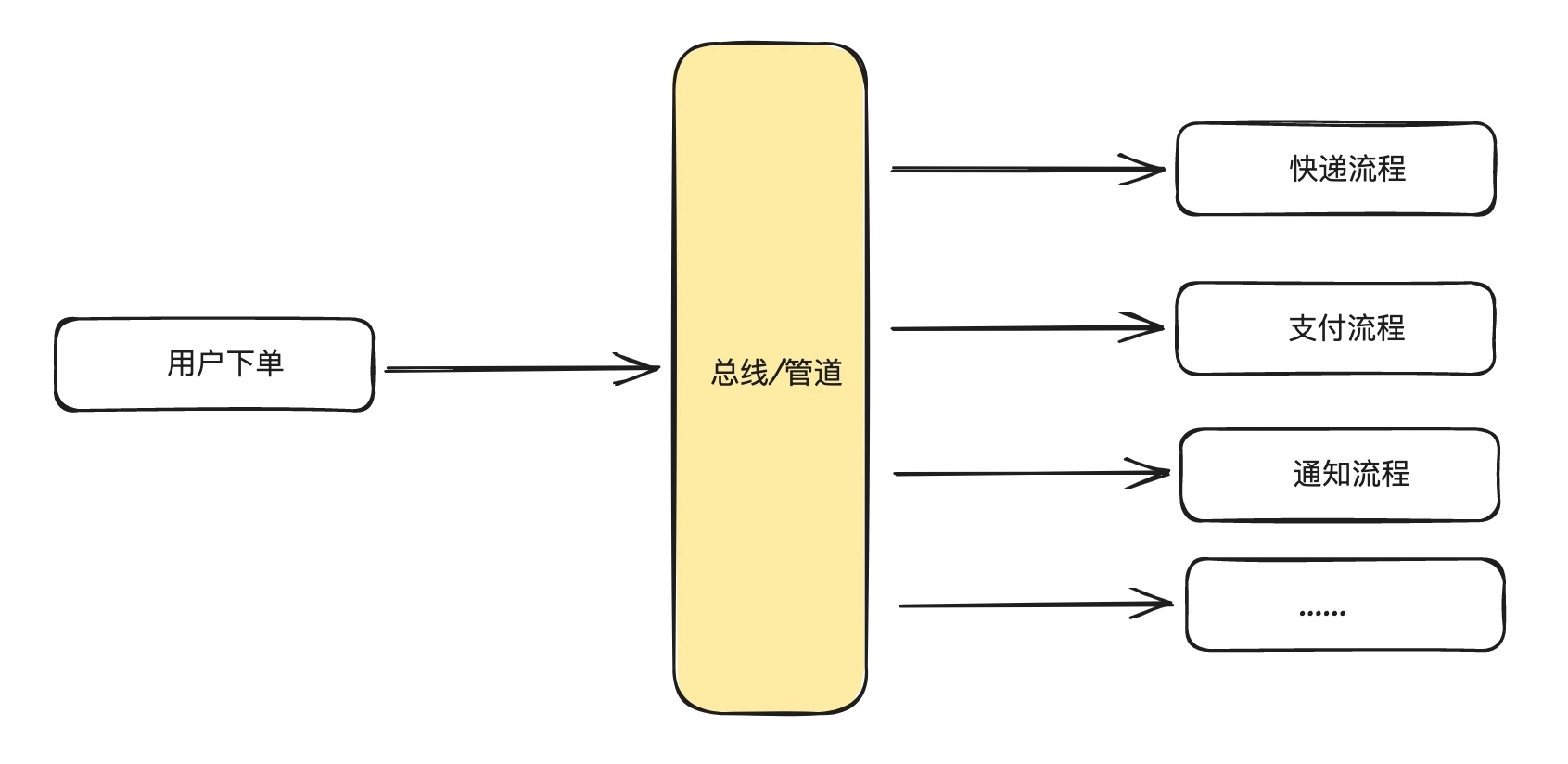
架构
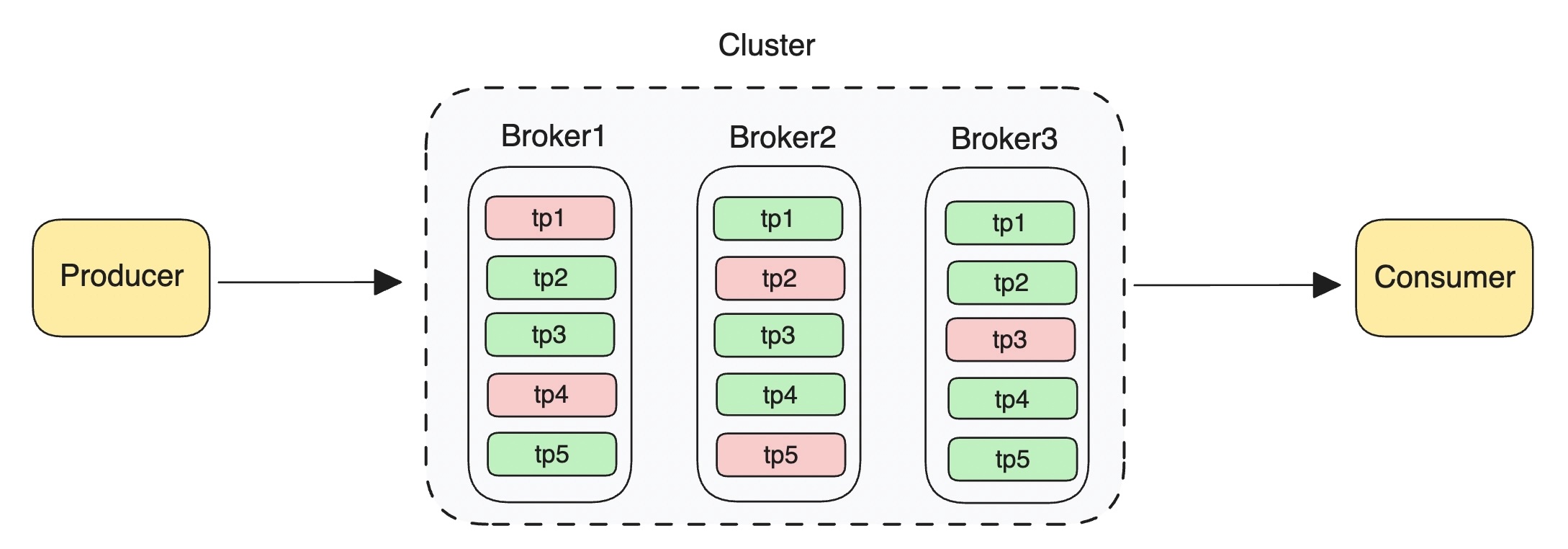
Broker
- Broker 本质上是一个进程
- 在实际部署过程中,通常一个物理节点只会起一个进程,在大部分情况下,Broker 表示一个节点
Topic
- 在大部分 MQ 中,Topic 都是用来组织分区关系的一个逻辑概念
- 通常情况下,一个 Topic 会包含多个分区
- 在 RabbitMQ 中,Topic 是指具体的一种主题模式
Partition
Queue / MessageQueue
- 在 MQ 中,分区、分片、Partition、Queue、MessageQueue 是一个概念,用来表示数据存储的最小单位
- 可以将消息写入到一个分区中,也可以将消息写入到 Topic 中,再分发到具体的某个分区
- 一个 Topic 通常会包含一个或多个分区
Producer
- 消息的发送方,即发送消息的客户端
Consumer
- 消息的接收方,即接收消息的客户端
ConsumerGroup
Subscription
- 一般情况下,MQ 中的 ConsumerGroup 和 Subscription 是同一概念
- 用来组织消费者和分区关系的逻辑概念,也可用于保存消费进度
Message
- 一条真实的业务数据,MQ 中的每条数据一般都叫做一条消息
Offset
ConsumerOffset / Cursor
- 指消费者消费分区的进度
- 每个消费者都会去消费分区,为了避免重复消费,都会保存消费者消费分区的进度信息
ACK
OffsetCommit
- 提交消费进度的操作,即数据消费成功后,提交当前的消费位点,确保不重复消费
Leader + Follower
- Leader 和 Follower 一般是分区维度副本的概念
- 一个分区一般会有多个副本,副本有主从概念,一般是一个主副本和多个从副本
Segment
- 指消息数据在底层具体存储时,分为多个文件存储时的文件,该文件叫做分区的数据段
- 如每超过 1G 的文件就新起一个文件来存储,即 Segment
- 几乎所有的 MQ 都有 Segment 的概念,如 Kafka 的 Segment,Pulsar 的 Ledger
StartOffset + EndOffset
- StartOffset 和 EndOffset 是分区维度的概念
- 数据是顺序写入分区的,一般从 0 位置开始往后写,此时 StartOffset 为 0
- 数据会过期,分区维度较早的数据会被清理,此时 StartOffset 会往后移,表示当前最早的有效数据的位点
- EndOffset 即最新的那条数据的写入位点
- StartOffset 和 EndOffset 是一直动态变化的
ACL
- 用来对集群中的资源进行权限控制,如控制 Topic 或 Partition 的读写操作等
功能
顺序消息
- Consumer 按 Producer 写入的顺序来消费消息
延时消息
定时消息
- Producer 发送消息到 Broker 时,设置该消息在多久后会被消费到,当时间到了,消息会被消费到
- 延时以 Broker 收到消息的时间为准,多久后消息能被 Consumer 消费
- 定时是指消息在设置的时间才能被看到
- 在技术上,延时和定时是一样的
事务消息
- 不同的 MQ 关于事务的定义,也是不太一样的
- 正常情况下,事务表示多个操作的原子性
- 在 MQ 中,一般指的是发送一批消息,要么同时成功,要么同时失败
消息重试
- Producer 重试 - 当消息发送失败后,可以设置重试策略
- Consumer 重试 - 当消费的消息处理失败后,会自动重试消费消息
消息回溯
- 消息可以被多次消费
- 某条消息消费成功后,该消息不会被删除,后续还能再重复消费到该消息
广播消费
- 一条消息可以被多个消费者消费
死信队列
- 当某条消息无法成功处理时,把该消息写入到一个死信队列中,继续处理后续消息
- 大部分情况下,死信队列在 Consumer 中使用
优先级队列
- 给 Partition 中消息设置权重,权重大的消息能够被优先消费到
- 大部分情况下,MQ 的消息处理是 FIFO 的规则
- 优先级是在消息维度设置的
消息过滤
- 给每条消息打上 Tag,在消费的时候根据 Tag 去消费消息
- 通过 Tag 去查询过滤消息 - 在 Consumer 端
TTL
- MQ 中的消息会在一定时间或者超过一定大小后会被删除
- MQ 的主要是缓冲作用,一般会要求消息在一定的策略后自动被清理
消息轨迹
- 记录一条消息从 Producer 发送、Broker 保存、Consumer 消费的全生命周期的流程信息
消息查询
- 根据某些信息查询到消息队列中的信息
- 根据消息 ID 或者消费位点来查询消息 - SQL Select
消息压缩
- Producer 发送消息的时候,是否支持将消息进行压缩,以节省物理资源
- 压缩可以在 Producer 完成,也可以在 Broker 完成,一般会在 Producer 完成
多租户
- 同一个集群存在逻辑隔离
- Namespace / Tenant
消息持久化
- 消息被发送到 Broker 后,会不会持久化存储
- 有些 MQ 为了保证性能,只会把消息存储在内存中,在节点重启后,数据会丢失
消息流控
- 对读写集群的消息进行限制
- 限流维度 - Topic / Partition / ConsumerGroup 等
选型
业务消息 - RocketMQ
流消息 - Kafka
RabbitMQ + RocketMQ
业务消息 - 及时性、更多的功能特性、消息可追踪
- RabbitMQ 和 RocketMQ 属于业务消息类的 MQ
- RabbitMQ 发展较早,RocketMQ 是新生的消息类的消息队列
- 从功能、集群化、稳定性、性能来看,RocketMQ 都优于 RabbitMQ - RocketMQ 替代 RabbitMQ
- 国内 - RocketMQ;国外 - RabbitMQ
Kafka
流消息 - 大流量、高吞吐
- Kafka 属于流场景的 MQ - 高吞吐、大流量
- 功能简单 - 不支持死信队列、延时消息等功能
- 非常稳定 + 吞吐性能非常高,能承担超大流量的业务场景 - 流场景下的消息管道的不二之选
Pulsar
- Pulsar 定位 - 消息和流融合
- 目标 - 满足所有消息和流的场景,同时满足功能和性能两方面的需求
- 发展时间较短,不太稳定,处于快速发展阶段
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-09-12
Kafka -- 监控消费进度
Consumer Lag Consumer Lag(滞后程度):消费者当前落后于生产者的程度 Lag的单位是消息数,一般是在主题的级别上讨论Lag,但Kafka是在分区的级别上监控Lag,因此需要手动汇总 对于消费者而言,Lag是最重要的监控指标,直接反应了一个消费者的运行情况 一个正常工作的消费者,它的Lag值应该很小,甚至接近于0,滞后程度很小 如果Lag很大,表明消费者无法跟上生产者的速度,Lag会越来越大 极有可能导致消费者消费的数据已经不在操作系统的页缓存中了,这些数据会失去享有Zero Copy技术的资格 这样消费者不得不从磁盘读取这些数据,这将进一步拉大与生产者的差距 马太效应:_Lag原本就很大的消费者会越来越慢,Lag也会也来越大_ 监控LagKafka自带命令 kafka-consumer-groups是Kafka提供的最直接的监控消费者消费进度的工具 也能监控独立消费者的Lag,独立消费者是没有使用消费者组机制的消费者程序,也要配置group.id 消费者组要调用KafkaConsumer.subscribe,独立消费者要调用KafkaConsumer.assign直...

2019-09-15
Kafka -- 处理请求
请求协议 Kafka自定义了一组请求协议,用于实现各种各样的交互操作 PRODUCE请求用于生产消息,FETCH请求用于消费消息,METADATA请求用于请求Kafka集群元数据信息 Kafka 2.3总共定义了45种请求格式,所有请求都通过TCP网络以Socket的方式进行通讯 处理请求方案顺序处理实现简单,但吞吐量太差,只适用于请求发送非常不频繁的场景 1234while (true) { Request request = accept(connection); handle(request);} 单独线程处理为每个请求都创建一个新的线程异步处理,完全异步,但开销极大,只适用于请求发送频率很低的场景 12345while (true) { Request request = accept(connection); Thread thread = new Thread(() -> { handle(request); }); thread.start();} Reactor模式 Reac...

2019-09-28
Kafka -- KafkaAdminClient
背景 命令行脚本只能运行在控制台上,在应用程序、运维框架或者监控平台中集成它们,会非常困难 很多命令行脚本都是通过连接ZK来提供服务的,这会存在潜在的问题,即绕过Kafka的安全设置 运行这些命令行脚本需要使用Kafka内部的类实现,也就是Kafka服务端的代码 社区是希望用户使用Kafka客户端代码,通过现有的请求机制来运维管理集群 基于上述原因,社区于0.11版本正式推出Java客户端版的KafkaAdminClient 功能 主题管理 主题的创建、删除、查询 权限管理 具体权限的配置和删除 配置参数管理 Kafka各种资源(Broker、主题、用户、Client-Id等)的参数设置、查询 副本日志管理 副本底层日志路径的变更和详情查询 分区管理 创建额外的主题分区 消息删除 删除指定位移之前的分区消息 Delegation Token管理 Delegation Token的创建、更新、过期、查询 消费者组管理 消费者组的查询、位移查询和删除 Preferred领导者选举 推选指定主题分区的Preferred Broker为领导者 工作原理 Kaf...

2019-08-09
Kafka -- 无消息丢失
持久化保证 Kafka只对已提交的消息做有限度的持久化保证 已提交的消息 当Kafka的若干个Broker成功地接收到一条消息并写入到日志文件后,会告诉生产者这条消息已经成功提交 有限度的持久化保证 Kafka不保证在任何情况下都能做到不丢失消息,例如机房着火等极端情况 消息丢失生产者丢失 目前Kafka Producer是异步发送消息的,Producer.send(record)立即返回,但不能认为消息已经发送成功 丢失场景:网络抖动,导致消息没有到达Broker;消息太大,超过Broker的承受能力,Broker拒收 解决方案:Producer永远要使用带有回调通知的发送API,即**Producer.send(record, callback)** callback能够准确地告知Producer消息是不是真的提交成功,一旦出现消息提交失败,可以进行针对性的处理 消费者丢失 Consumer端丢失数据主要体现在Consumer端要消费的消息不见了 Consumer程序有位移的概念,表示该Consumer当前消费到Topic分区的位置 丢失原因:Consumer接收一批消息后,在未...

2018-10-18
Kafka -- 消费者
基本概念消费者 + 消费者群组 消费者从属于消费者群组 一个消费者群组里的消费者订阅的是同一个主题,每个消费者接收主题的部分分区的消息 消费者横向扩展1个消费者 主题T1有4个分区,然后创建消费者C1,C1是消费者群组G1里唯一的消费者,C1订阅T1 消费者C1将接收主题T1的全部4个分区的消息 2个消费者 如果群组G1新增一个消费者C2,那么每个消费者将分别从两个分区接收消息 假设C1接收分区0和分区2的消息,C2接收分区1和分区3的消息 4个消费者 如果群组G1有4个消费者,那么每个消费者可以分配到一个分区 5个消费者 如果群组G1有5个消费者,_**消费者数量超过主题的分区数量**_,那么有1个消费者就会被**闲置**,不会接收到任何消息 总结 往群组里增加消费者是横向伸缩消费能力的主要方式 消费者经常会做一些高延迟的操作,比如把数据写到数据库或HDFS,或者使用数据进行比较耗时的计算 有必要为主题创建大量的分区,在负载增长时可以加入更多的消费者,减少消息堆积 不要让消费者的数量超过主题分区的数量,多余的消费者只会被闲置 消费者群组横向扩展 Kafka设计的主要目标...

2019-08-16
Kafka -- 生产者管理TCP连接
建立TCP连接创建KafkaProducer实例123456789101112Properties properties = new Properties();properties.put("bootstrap.servers", "localhost:9092");properties.put("key.serializer", StringSerializer.class.getName());properties.put("value.serializer", StringSerializer.class.getName());// try-with-resources// 创建KafkaProducer实例时,会在后台创建并启动Sender线程,Sender线程开始运行时首先会创建与Broker的TCP连接try (Producer<String, String> producer = new KafkaProducer<>(properties)) { ProducerRec...




