
New Java Feature - Exception
概述
- Java 异常的使用和处理,是滥用最严重,诟病最多,也是最难平衡的一个难题
- Java 语言支持三种异常的状况
- 非正常异常(Error)、运行时异常(Runtime Exception)、检查型异常(Checked Exception)
- 异常,除非特别声明,一般指的是 Checked Exception 和 Checked Exception
- 异常状况的处理会让代码的效率变低 - 不应该使用异常机制来处理正常情况
- 理想情况下,在执行代码时没有任何异常发生,否则业务执行的效率会大打折扣
- 几乎无法完成,不管是 JDK 核心类库还是业务代码,都存在大量的异常处理代码
- 软件都是由很多类库集成的,大部分类库,都只是从自身的角度去考虑问题,使用异常来处理问题
- 很难期望业务执行下来没有任何异常发生
- 抛出异常影响了代码的运行效率,而实际业务又没有办法完全不抛出异常
- 新的编程语言(Go),彻底抛弃类似于 Java 这样的异常机制,重新拥抱 C 语言的错误方式
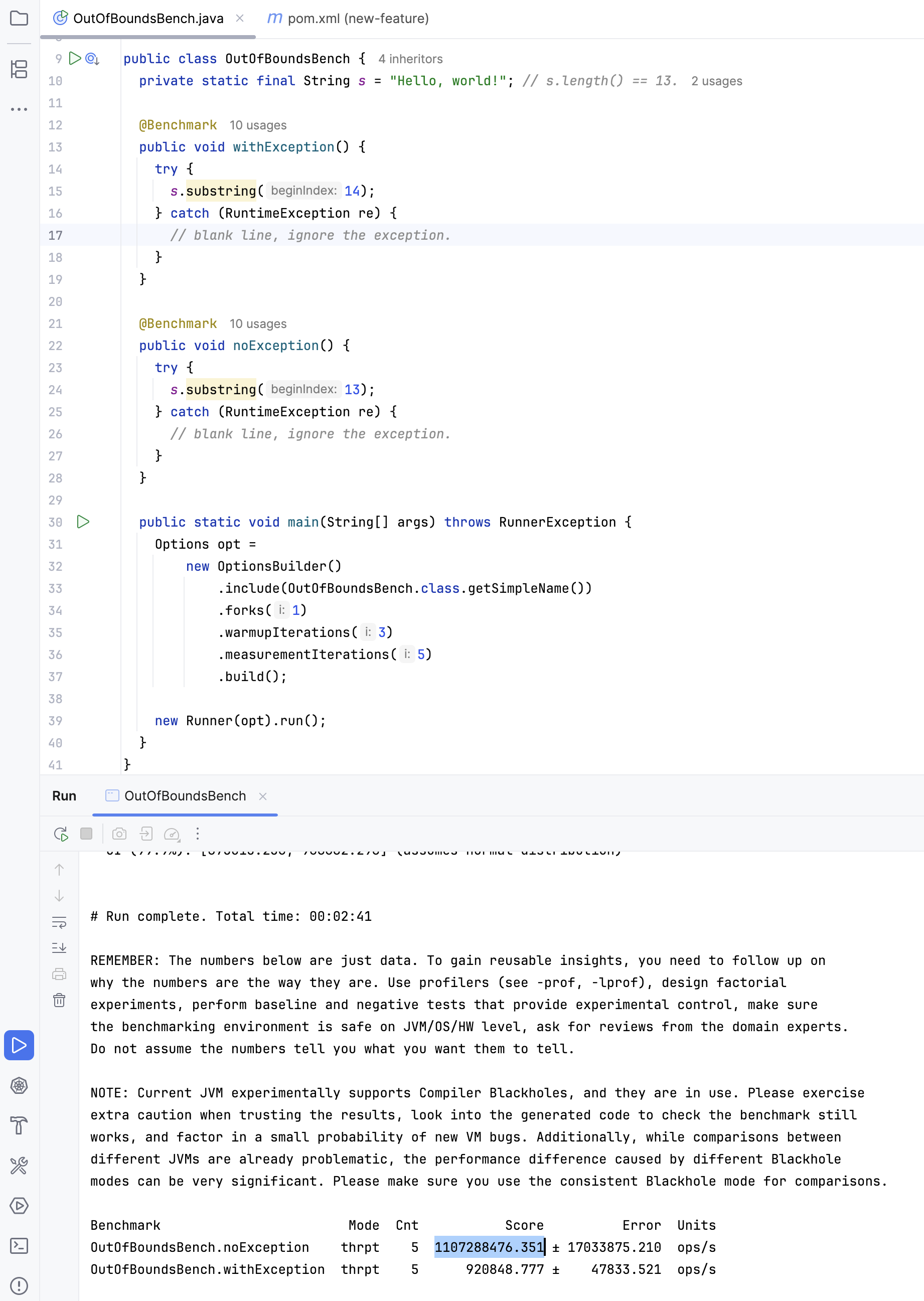
性能
没有抛出异常的用例,能够支持的吞吐量要比抛出异常的用例大 1000 倍
案例
- 在设计算法公开接口时,算法的敏捷性是必须要要考虑的问题
- 算法总是会演进,旧的算法会过时,新的算法会出现
- 一个应用程序,应该能够很方便地升级它的算法,自动地淘汰旧算法,采纳新算法,而不需要太大的改动
- 因此,算法的公开接口经常使用通用的参数和结构
获取一个单向散列函数实例时,通过工厂模式来构造出单向散列函数的实例
1 | public abstract sealed class Digest { |
使用 of 方法,需要处理该 Checked Exception
1 | try { |
错误码
Go
既能返回值,又能返回错误码 - Go
1 | public record Coded<T>(T returned, int errorCode) { |
1 | public static Coded<Digest> of(String algorithm) throws NoSuchAlgorithmException { |
1 | Coded<Digest> coded = Digest.of("SHA-256"); |
基准测试 - 几乎没有差别
1 | Benchmark Mode Cnt Score Error Units |
缺陷
在性能优化的同时,放弃了代码的可读性和可维护性
需要更多的代码
- 使用异常处理的代码,可以在一个 try-catch 语句块里包含多个方法的调用
- 每个方法的调用都可以抛出异常
- 由于异常的分层设计,所有的异常都是 Exception 的子类
- 可以一次性处理多个方法抛出的异常
1 | try { |
- 使用了错误码的方式,每一个方法调用都要检查返回的错误码
- 一般情况下,同样的逻辑和接口结构,使用错误码的方式需要编写更多的代码
对于简单的逻辑和语句,可以使用逻辑运算符合并多个语句 - 紧凑但牺牲了代码的可读性
1 | if (doSomething() != 0 && |
对于复杂的逻辑和语句,需要一个独立的代码块来处理错误码 - 结构重复的代码会增加
1 | if (doSomething() != 0) { |
丢弃调试信息
性能 vs 可维护性
- 最大的代价 - 可维护性大幅度降低
- 使用异常的代码,可以通过异常的调用堆栈,清楚地看到代码的执行轨迹,快速找到出问题的代码
- 使用错误码之后,就不再生成调用堆栈了 - 性能提高
- 快速找到代码的问题,是一个编程语言的竞争力
- 如果回到错误码的处理方式,需要提供快速排查问题的替代方案
- 更详尽的日志 + JFR
易碎的数据结构
- 一个新机制的设计,必须要简单和皮实 - 不容易犯错
- 生成一个 Coded 实例,需遵循以下规则,违反任意规则,都可能产生不可预测的错误
- 错误码的数值必须一致,0 代表没有错误,其它值表示出错了
- 不能同时设置返回值和错误码
- 使用错误码,同样需要遵循规则
- 必须首先检查错误码,然后才能使用返回值
- 需要依赖编码人员的自觉发现,编译器本身不会帮忙检查
1 | public static Coded<Digest> of(String algorithm) { |
1 | Coded<Digest> coded = Digest.of("SHA-256"); |
需要自觉遵循的规则越多,犯错的概率越大
改进方案 - 共用错误码
同时考虑生成错误码和使用错误码两端的需求
1 | public sealed interface Returned<T> { |
- 封闭类的许可子类是可以穷举的
- 把 Returned 的许可子类(ReturnValue 和 ErrorCode)定义成档案类,分别表示返回值和错误代码
要么是返回值(ReturnValue),要么是错误码(ErrorCode)
1 | public static Returned<Digest> of(String algorithm) { |
使用错误码 - switch 匹配 - 必须使用 ReturnValue 或者 ErrorCode - 穷举
1 | public static void main(String[] args) { |
依然存在的缺陷 - 本身没有携带调试信息
小结
错误码 - 封闭类 + 档案类
- 不能携带调试信息
- 提高了错误处理的性能
- 增加了错误排查的困难
- 降低了代码的可维护性
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2025-01-14
New Java Feature - Error Code
概述 Java 的异常处理是对代码性能有着重要影响的因素 Java 的异常处理,有着天生优势,特别是在错误排查方面的作用,很难找到合适的替代方案 用例123456789101112131415161718192021222324252627282930313233343536package me.zhongmingmao;import java.security.NoSuchAlgorithmException;public class UseCase { public static void main(String[] args) { String[] algorithms = {"SHA-128", "SHA-192"}; String availableAlgorithm = null; for (String algorithm : algorithms) { Digest md; try { md = Digest.of(algorit...
2025-01-16
New Java Feature - Foreign Memory API
概述 在讨论代码性能的时候,内存的使用效率是一个绕不开的话题 - Flink/Netty 为了避免 JVM GC 不可预测的行为以及额外的性能开销,一般倾向于使用 JVM 之外的内存来存储和管理数据 - 堆外数据 - off-heap data 使用堆外存储最常用的办法,是使用 ByteBuffer 来分配直接存储空间 - direct buffer JVM 会尽最大努力直接在 direct buffer 上执行 IO 操作,避免数据在本地和 JVM 之间的拷贝 频繁的内存拷贝是性能的主要障碍之一 为了极致的性能,应用程序通常会尽量避免内存的拷贝 理想的情况下,一份数据只需要一份内存空间 - 即零拷贝 ByteBuffer 使用 ByteBuffer 来分配直接存储空间 1public static ByteBuffer allocateDirect(int capacity); ByteBuffer 所在的 Java 包是 java.nio,ByteBuffer 的设计初衷是用于非阻塞编程 ByteBuffer 是异步编程和非阻塞编程的核心类,几乎所有的 Java 异步模...

2025-01-17
New Java Feature - Foreign Function API
概述 Java 的外部函数接口这个特性,与外部内存接口一起,会极大地丰富 Java 语言的生态环境 像 Java 或者 Go 这样的通用编程语言,都需要和其它的编程语言或者环境打交道 - 如操作系统或者 C 语言 Java 通过 Java 本地接口 JNI 来支持该做法 本地方法接口示例1234567891011public class HelloWorld { static { System.loadLibrary("helloWorld"); } public static void main(String[] args) { new HelloWorld().sayHello(); } private native void sayHello();} sayHello 使用了 native 修饰符,是一个本地方法,可以使用 C 语言实现 - 生成对应的 C 语言的头文件 1234$ javac -h . HelloWorld.java$ lsHe...

2025-01-08
New Java Feature - Record
概述 JDK 16 Java 档案类是用来表示不可变数据的透明载体 OOP 封装 + 继承 + 多态 接口不是多线程安全的 - 将 Public 方法设置成同步方法 - 开销很大 更优方案 - 即使不使用线程同步,也能做到多线程安全 - 不可变对象 天生的多线程安全 - 类对象一旦实例化就不能再修改 简化代码 - 删除读取半径的方法,直接公开半径这个变量 - 与 Go 类似 Circle 一直可以用半径来表达,所以并没有带来违反封装原则的实质性后果 进一步简化 使用公开的只读变量 - 使用 final 修饰符来表明只读变量 公开的只读变量,只在在公开的构造方法中赋值 - 解决对象的初始化问题 公开的只读变量,替换掉了读取的方法 - 减少代码量 声明档案类 Java 档案类是用来表示不可变数据的透明载体 record 关键字是 class 关键字的一种特殊表现形式,用来标识档案类 record 关键字可以使用与 class 关键字差不多一样的类修饰符 - public/static 类标识符 Circle 后,用小括号括起来的参数 - 类似于一个构造...

2024-10-09
Java Feature - Text Blocks
概述 Text Blocks 在 JDK 15 正式发布 Text Blocks 是一个由多行文字构成的字符串 丑陋 所见即所得 Text Blocks 是一个由多行文本构成的字符串 Text Blocks 使用新的形式来表达字符串 Text Blocks 尝试消除换行符、连接符、转义字符的影响 使文字对齐和必要的占位符更加清晰,简化多行字符串的表达 消失的特殊字符 - 换行符(\n)、连接字符(**+**)、双引号没有使用转义字符(\) Text Blocks 由零个或多个内容字符组成,从开始分隔符开始,到结束分隔符结束 开始分隔符 - """,后跟零个或者多个空格,以及行结束符组成的序列 - 必须单独成行 结束分隔符 - 只有 """ - 之前的字符,包括换行符,都属于 Text Blocks 的有效内容 Text Blocks 至少两行代码,即便只是一个空字符串,结束分隔符也不能和开始分隔符在同一行 Text Blocks 不再需要特殊字符 - 所见即所得 12345678910$ jshell> St...

2025-01-12
New Java Feature - Switch Matching
案例 假设上面表示形状的封闭类和许可类是版本 1.0,它们被封装在一个基础 API 类库里 - 基础类库 而 isSquare 的实现代码,被封装在另一个 API 类库里 - 扩展类库 新加入一个许可类,用来表示长方形 - 基础类库的升级,扩展类库也要同步升级 - 但不一定能意识到 对于需要更改扩展类库这件事,基础类库的作者,不会通知到扩展类库的作者 一般情况下,基础类库和扩展类库是独立的作品,由不同的团队和社区维护 基础类库的作者不太可能意识到扩展类库的存在,更不可能去研究扩展类库的实现细节 扩展类库维护者也不会注意到基础类库的修改,更不容易想到基础类库的修改会影响到扩展类库的行为 模式匹配的 switch 具有模式匹配能力的 switch - 将模式匹配扩展到 switch 语句和 switch 表达式 允许测试多个模式,每个模式多可以有特定的操作 - 简洁安全地表达复杂的面向数据的查询 扩充的匹配类型 在 JDK 17 之前的 switch 关键字可以匹配的数据类型包括 - 数字、枚举和字符串 - 本质上都是整型的原始类型 在 JDK 17 之后,匹配的目标数据类型,可以...




