
Python - Futures
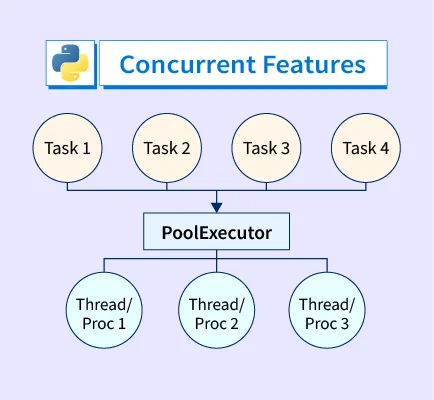
并行 vs 并发 并发(Concurrency) - 在某个特定的时刻,只允许有一个操作发生,线程和任务之间会相互切换,交替运行 并行(Parallelism) - 在同一时刻,有多个操作同时进行 Python 中有两种并发形式 - threading + asyncio threading 操作系统知道每个线程的所有信息,在适当的时候做线程切换 优点 - 代码易于编写,程序员不需要做任何切换操作 缺点 - 容易出现 race condition asyncio 主程序想要切换任务时,必须得到此任务可以切换的通知 避免了 race condition 的情况 场景 并发通常用于 IO 密集的场景 - Web 应用 并行通常用于 CPU 密集的场景 - MapReduce 线程池 vs 进程池 大部分时间是浪费在 IO 等待上 多线程(并发) - 16.8s -> 3.5s 12with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor: executor.map(down...

Python - Coroutine
基础 协程是实现并发编程的一种方式 多线程/多进程模型,是解决并发问题的经典模式 C10K - 线程/进程上下文切换占用大量资源 Nginx Event loop 启动一个统一的调度器,让调度器来决定一个时刻去运行哪个任务 节省了多线程中启动线程、管理线程、同步锁等各种开销 相比于 Apache,用更低的资源支持更多的并发连接 Callback hell - JavaScript 继承了 Event loop 的优越性,同时还提供 async / await 语法糖,解决了执行性和可读性共存的难题 协程开始崭露头角,尝试使用 Node.js 实现后端 Python 3.7 提供基于 asyncio 的 async / await 方法 同步 简单实现 12345678910111213141516import timedef crawl_page(url): print('crawling {}'.format(url)) sleep_time = int(url.split('_&...
Python - Iterator + Generator
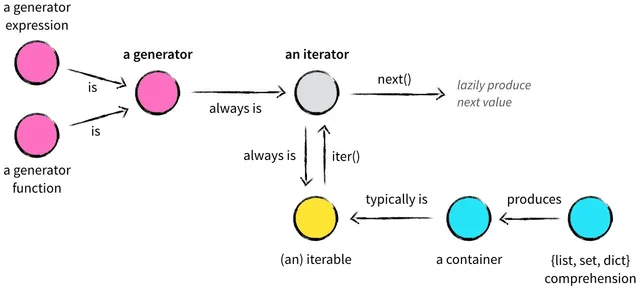
迭代器 Python 中一切皆对象,对象的抽象就是类,对象的集合为容器(列表、元组、字典、集合) 所有的容器都是可迭代的(iterable) 迭代器(iterator)提供了一个 next 的方法 得到容器的下一个对象,或者得到一个 StopIteration 的错误 可迭代对象,通过 iter() 函数返回一个迭代器(iterator),再通过 next() 函数实现遍历 for in 语句隐式化了该迭代过程 判断一个对象是否可迭代 - iter(obj) 或者 isinstance(obj, Iterable) 1234567891011121314151617181920212223from typing import Iterabledef is_iterable(param): try: iter(param) return True except TypeError: return Falseparams = [ 1234, # False '1234', # True [1, ...

Python - Metaclass
超越变形 YAMLObject 的一个超越变形能力,即的任意子类支持序列化和反序列化 123456789101112131415161718192021222324252627282930import yamlclass Monster(yaml.YAMLObject): yaml_tag = u'!Monster' def __init__(self, name, hp, ac, attacks): self.name = name self.hp = hp self.ac = ac self.attacks = attacks def __repr__(self): return "%s(name=%r, hp=%r, ac=%r, attacks=%r)" % ( self.__class__.__name__, self.name, self.hp, self.ac, self.attacks)yaml.load("...
Python - Decorator
函数 在 Python 中,函数是一等公民,函数是对象,可以将函数赋予变量 将函数赋值给变量 123456789def func(message): print('Got a message: {}'.format(message))send_message = func # assign the function to a variableprint(type(func)) # <class 'function'>print(type(send_message)) # <class 'function'>send_message('hello world') # call the function 将函数当成函数参数传递给另一个函数 12345678910def get_message(message): return 'Got a message: ' + messagedef root_call(func, messag...
Python - Parameter Passing
值传递 vs 引用传递 值传递 - 拷贝参数的值,然后传递给函数里面的新变量,原变量和新变量之间互相独立,互不影响 引用传递 - 把参数的引用传递给新变量,原变量和新变量会指向同一块内存地址 如果改变其中任何一个变量的值,另一个变量的值也会随之变化 变量赋值123456a = 1 # a points to 1 objectb = a # b points to the same object as aa = a + 1 # int is immutable, so a points to a new objectprint(a) # 2print(b) # 1 简单的赋值 b=a,不表示重新创建新对象,而是让同一个对象被多个变量指向或者引用 指向同一个对象,并不意味着两个变量绑定,如果给其中一个变量重新赋值,不会影响其它变量的值 123456l1 = [1, 2, 3] # l1 is a reference to the list [1, 2, 3]l2 = l1 # l2 is a reference to the list [1, 2, 3] as wel...
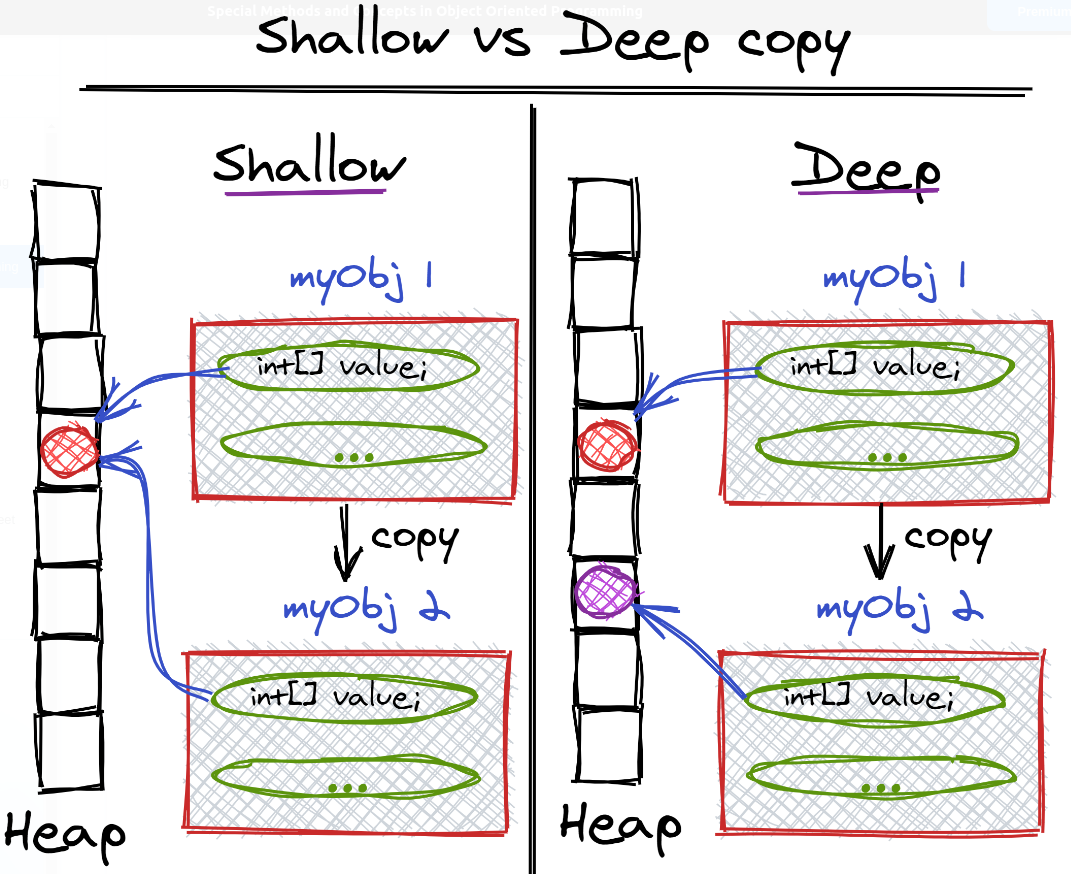
Python - Compare + Copy
== vs is == 比较对象之间的值是否相等,类似于 Java 中的 equals is 比较的是对象的身份标识是否相等,即是否为同一个对象,是否指向同一个内存地址,类似于 Java 中的 == is None or is not None 在 Python 中,每个对象的身份标识,都能通过 id(object) 函数获得,is 比较的是对象之间的 ID 是否相等 类似于 Java 对象的 HashCode 在实际工作中,**== 更常用,一般关心的是两个变量的值,而非内部存储地址** 12345678a = 10 # allocate memory for 10b = 10 # point to the same memory location as aprint(a == b) # Trueprint(id(a)) # 4376158344print(id(b)) # 4376158344print(a is b) # True a is b 为 True,仅适用于 -5 ~ 256 范...

Python - Module
简单模块化 把函数、类、常量拆分到不同的文件,但放置在同一个文件夹中 使用 from your_file import function_name, class_name 的方式进行调用 12345678910111213141516$ tree.├── main.py└── utils.py$ cat utils.pydef get_sum(a, b): return a + b $ cat main.pyfrom utils import get_sumprint(get_sum(1, 2)) # 3$ python main.py3 项目模块化 相对的绝对路径 - 从项目的根目录开始追溯 所有的模块调用,都要通过项目根目录来 import 12345678910111213141516$ tree.├── proto│ └── mat.py├── src│ └── main.py└── utils └── mat_mul.py$ cd src/$ python main.pyTraceback (most recent call last): File &...

Python - OOP
命令式 Python 的命令式语言是图灵完备的 - 即理论上可以做到其它任何语言能够做到的所有事情 仅依靠汇编语言的 MOV 指令,就能实现图灵完备编程 传统的命令式语言有着无数重复性代码,虽然函数的诞生减缓了许多重复性 但只有函数是不够的,需要把更加抽象的概念引入计算机才能缓解 – OOP 基本概念12345678910111213141516171819202122232425class Document(): def __init__(self, title, author, context): print('init function called') self.title = title self.author = author self.__context = context # __context is private def get_context_length(self): return len(self.__context) def intercept_cont...
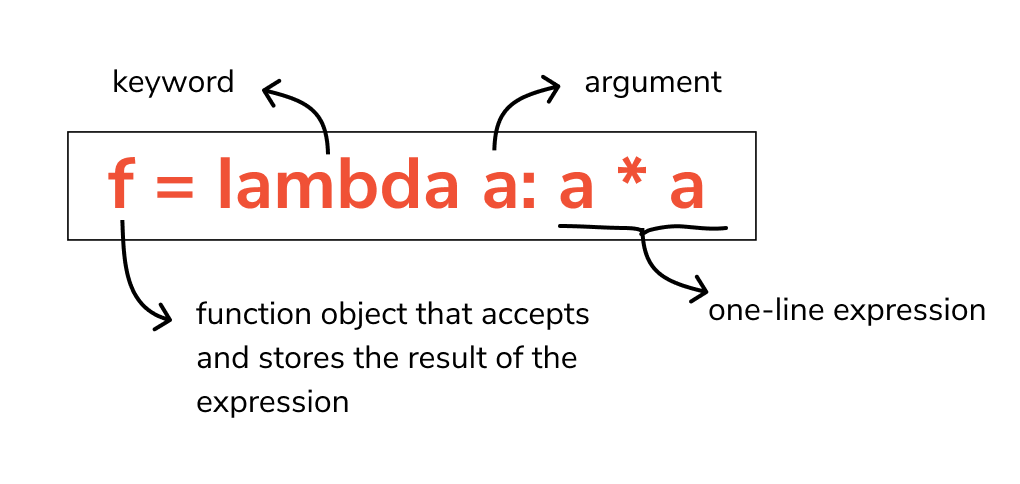
Python - Lambda
基础 匿名函数的关键字为 lambda 1lambda argument1, argument2,... argumentN : expression 1234square = lambda x: x ** 2print(type(square)) # <class 'function'>print(square(5)) # 25 lambda 是一个表达式(expression),而非一个语句(statement) 表达式 - 用一系列公式去表达 语句 - 完成某些功能 lambda 可以用在列表内部,而常规函数 def 不能 lambda 可以用作函数参数,而常规函数 def 不能 常规函数 def 必须通过其函数名被调用,因此必须首先被定义 lambda 是一个表达式,返回的函数对象不需要名字,即匿名函数 lambda 的主体只有一行的简单表达式,并不能扩展成多行的代码块 lambda 专注于简单任务,而常规函数 def 负责更复杂的多行逻辑 12y = [(lambda x: x * x)(x) for x in range(10)]...




