

Python - Function
基础 函数为实现了某一功能的代码片段,可以重复利用函数可以返回调用结果(return or yield),也可以不返回 123def name(param1, param2, ..., paramN): statements return/yield value # optional 与编译型语言不同,def 是可执行语句,即函数直到被调用前,都是不存在的 当调用函数时,def 语句才会创建一个新的函数对象,并赋予其名字 在主程序调用函数时,必须保证这个函数已经定义过,否则会报错 12345my_func('hello world') # NameError: name 'my_func' is not defineddef my_func(message): print('Got a message: {}'.format(message)) 在函数内部调用其它函数,则没有定义顺序的限制def 是可执行语句 - 函数在调用之前都不存在,只需保证调用时,所需的函数都已经声明定义即可 ...
Python - Exception
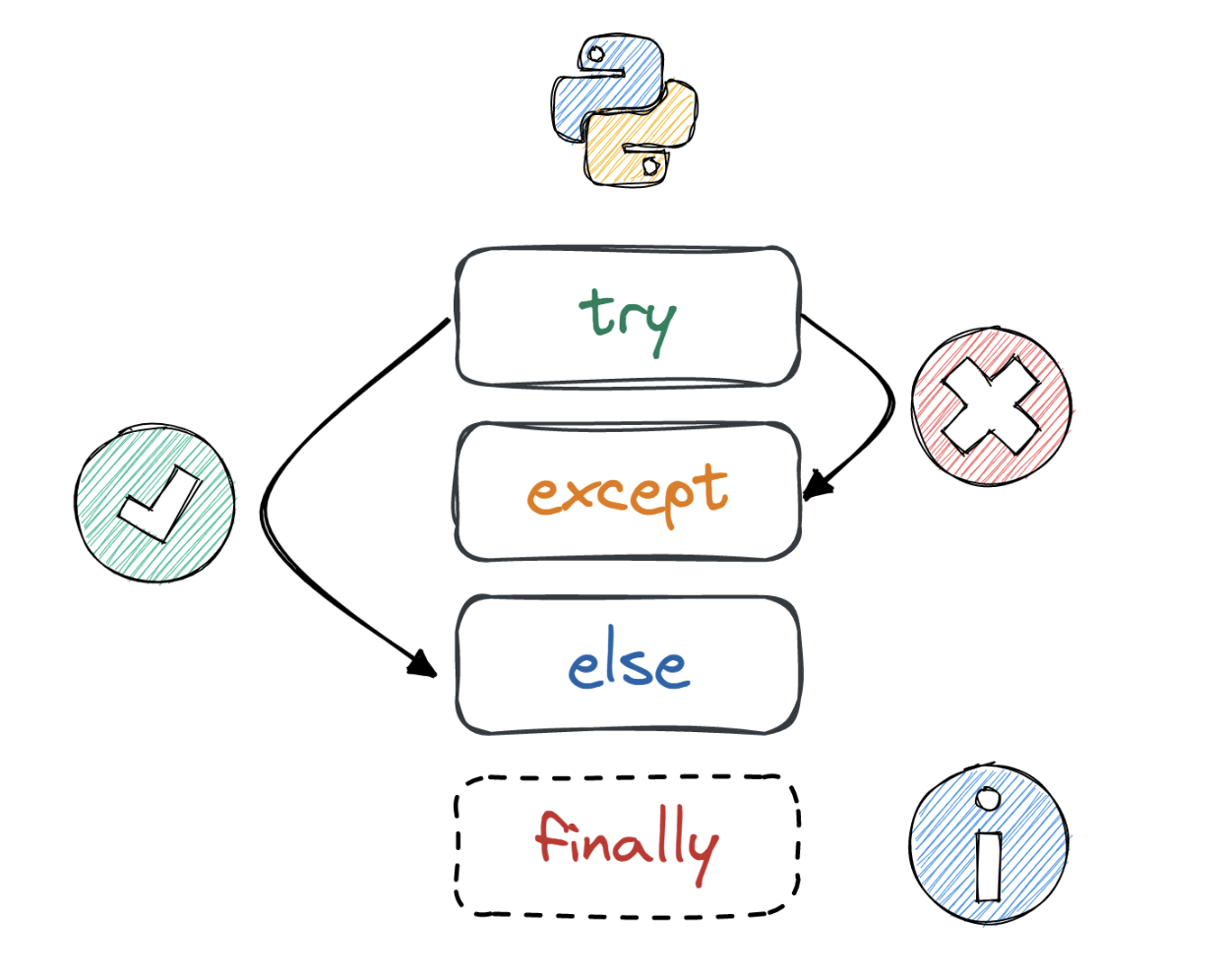
错误 vs 异常 语法错误,无法被识别与执行 123name = 'x'if name is not None # SyntaxError: invalid syntax print(name) 异常 - 语法正确,可以被执行,但在执行过程中遇到错误,抛出异常,并终止程序 123# 10 / 0 # ZeroDivisionError: division by zero# order * 2 # NameError: name 'order' is not defined# 1 + [1, 2] # TypeError: unsupported operand type(s) for +: 'int' and 'list' 处理异常 try-exceptexcept block 只接受与它相匹配的异常类型并执行 123456try: s = input('please enter two numbers separated by comma: ') num1 = ...

Python - Condition + Loop
条件 不能在条件语句中加括号,必须在条件末尾加上 : 12345678x = int(input("Enter a number: "))if x < 0: y = -xelse: y = xprint(f"The absolute value of {x} is {y}.") Python 不支持 switch 语句 - elif - 顺序执行 12345678x = int(input("Enter a number: "))if x == 0: print('red')elif x == 1: print('yellow')else: print('green') 省略用法 - 除了 Boolean 类型的数据,判断条件最好是显性的 循环 for + while 123l = [1, 2, 3, 4]for e in l: print(e) 只要数据结构是 Iterable...

Python - IO
基础1234567891011name = input('your name:')gender = input('you are a boy? (y/n)')welcome_str = 'Welcome to the matrix {prefix} {name}.'welcome_dic = { 'prefix': 'Mr.' if gender == 'y' else 'Mrs.', 'name': name}print('authorizing...')print(welcome_str.format(**welcome_dic)) input() 函数暂停程序运行,等待键盘输入,直到回车被按下 函数的参数为提示语,输入的类型永远都是字符串(string) print() 函数则接受字符串、数字、字典、列表和自定义类 input() 的...
Python - String
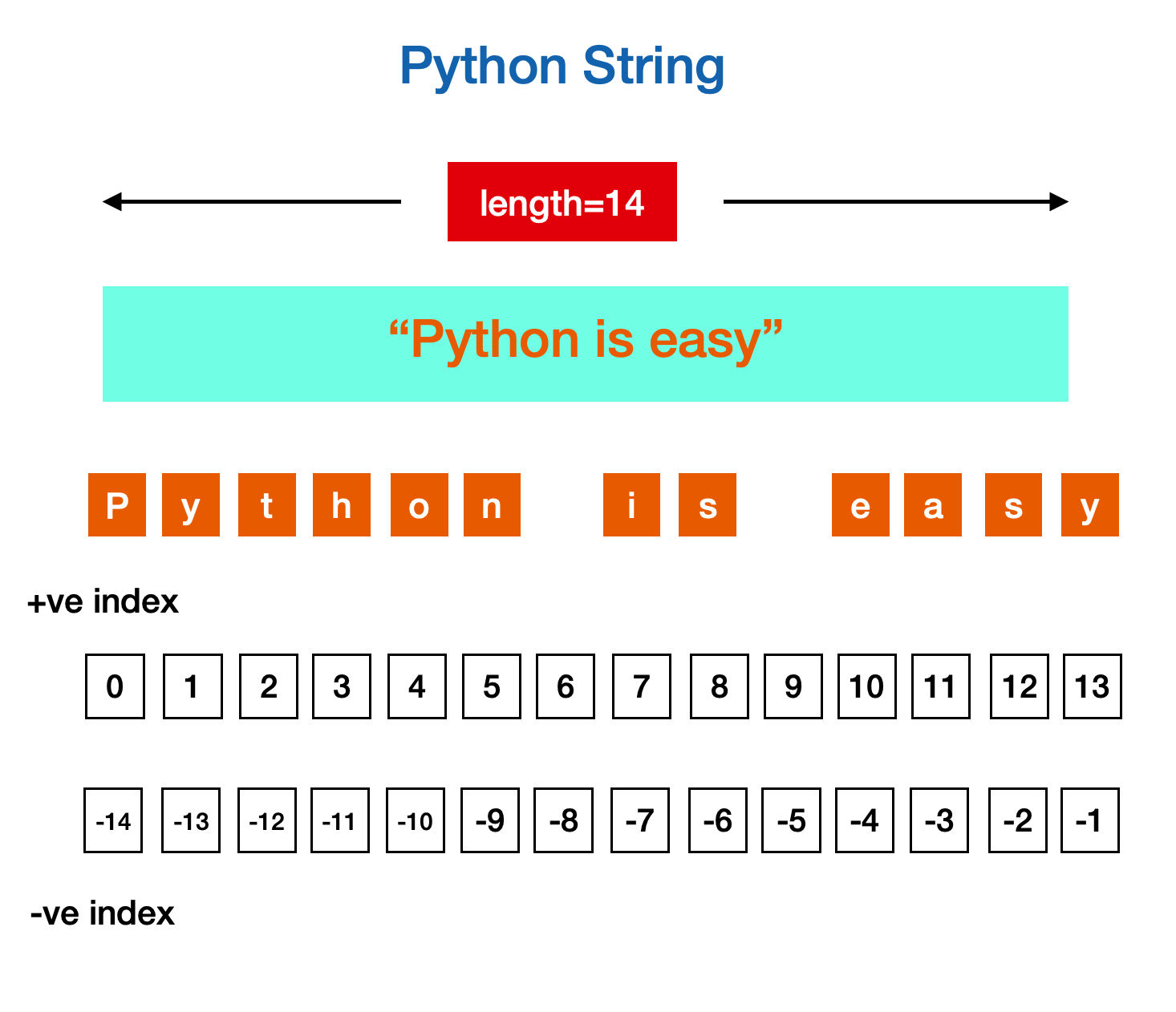
基础 字符串是由独立字符组成的一个序列,通常包含在 '...'、"..."、"""...""" 中 123name = 'jason'city = "guangzhou"desc = """I'm a software engineer""" 1234s1 = 'rust's2 = "rust"s3 = """rust"""print(s1 == s2 == s3) # True 便于在字符串中,内嵌带引号的字符串 12s = "I'm a string"print(s) # I'm a string """...""" 常用于多行字符串,如函数注释 Python 支持转义字...
Python - Dict + Set
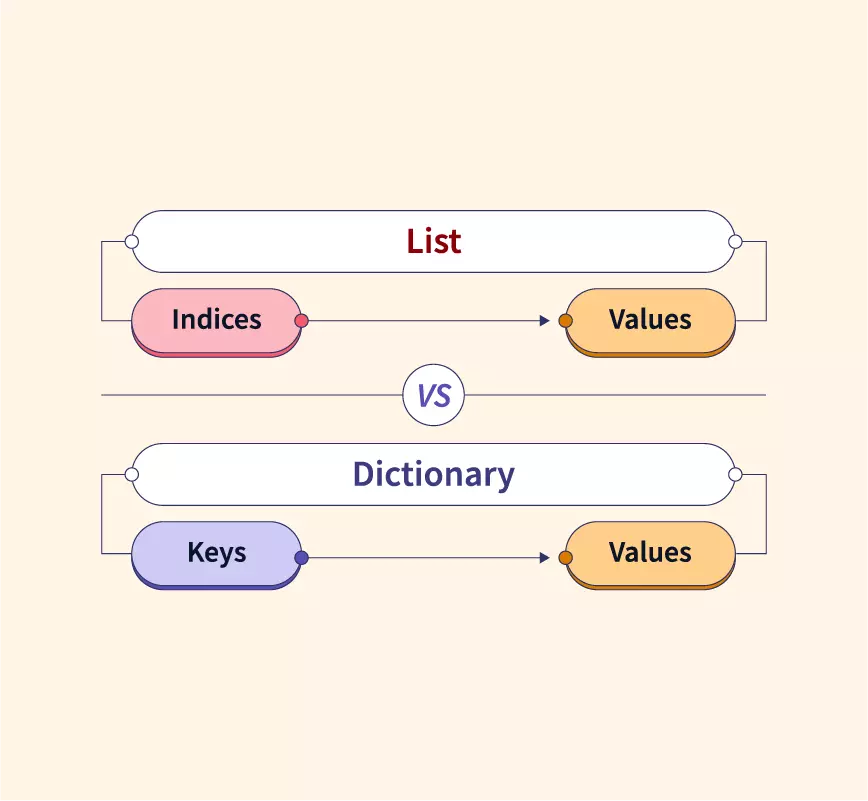
基础 字典是由 kv 对组成的元素的集合,在 Python 3.7+,字典被确定为有序 相比于列表和元组,字典的性能更优,对于查找、添加和删除操作,时间复杂度为 O(1) 集合是一系列唯一无序的元素组合 字典和集合,无论是 Key 还是 Value,都可以是混合类型 字典初始化 123456789d1 = {'name': 'jason', 'age': 20, 'gender': 'male'}d2 = dict({'name': 'jason', 'age': 20, 'gender': 'male'})d3 = dict([('name', 'jason'), ('age', 20), ('gender', 'male')])d4 = dict(name...
Python - List + Tuple
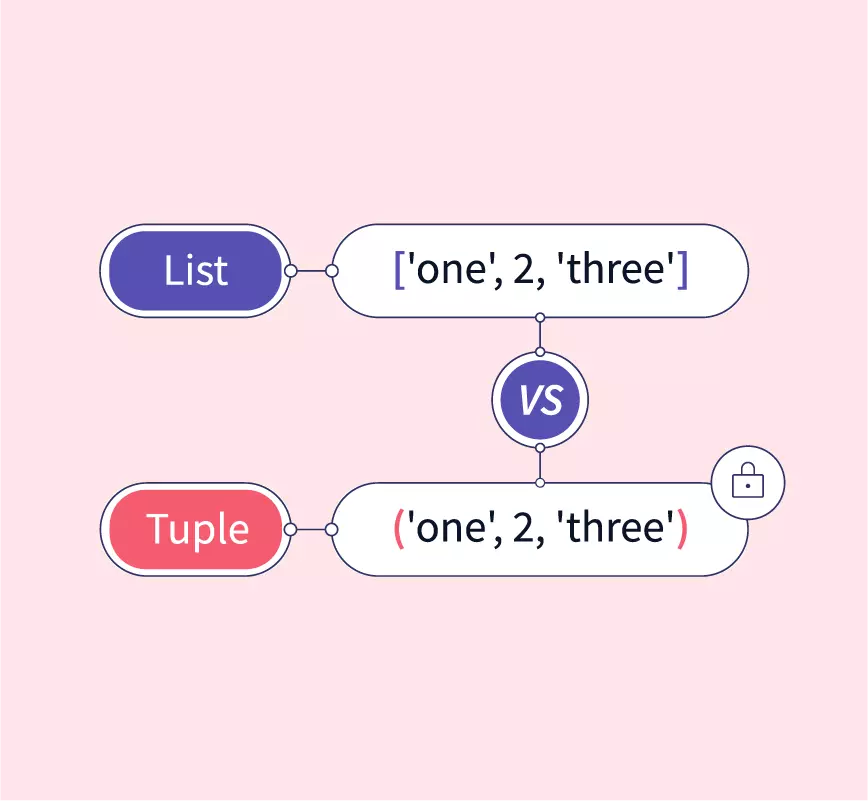
基础 列表和元组都是可以放置任意数据类型的有序集合 - 绝大多数编程语言,集合的数据类型必须一致 12l = [1, 2, 'hello', 'world']t = ('json', 22) 列表是动态的(mutable),而元组是静态的(immutable) 123456l = [1, 2, 3, 4] # mutablel[3] = 40print(l) # [1, 2, 3, 40]t = (1, 2, 3, 4) # immutable# t[3] = 40 # TypeError: 'tuple' object does not support item assignment 为元组追加新元素,只能新建元组 123t1 = (1, 2, 3, 4)t2 = t1 + (5,)print(t2) # (1, 2, 3, 4, 5) 为列表追加新元素,可以直接追加到列表末尾 123l = [1, 2, 3, 4]l.append(5)print(l) # [1, 2, 3, 4, 5...
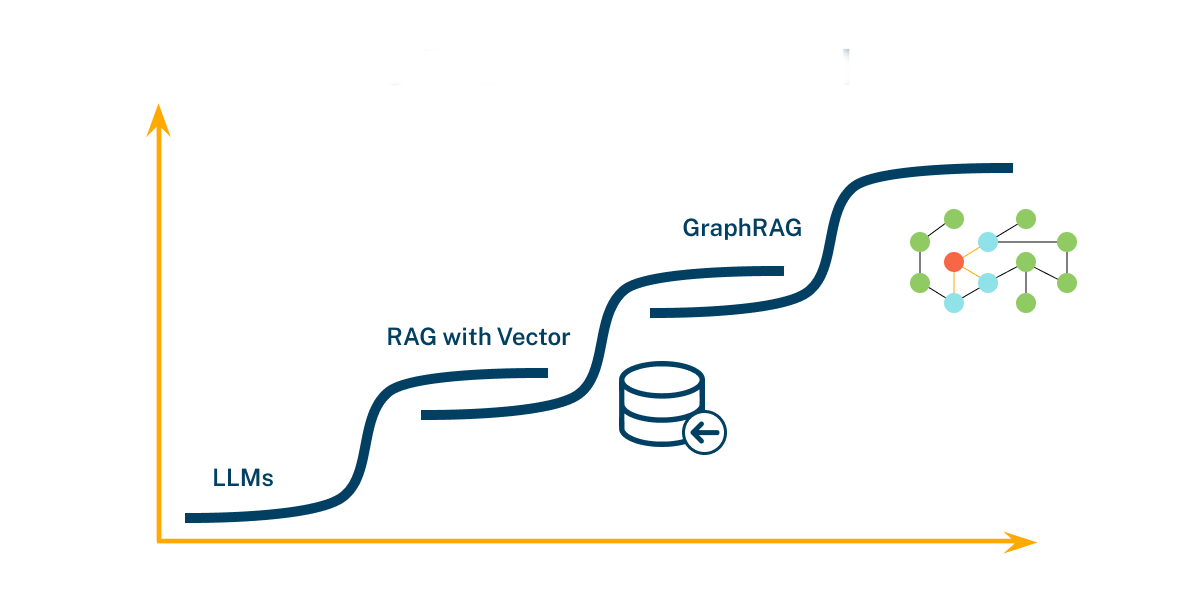
RAG - GraphRAG
向量检索 信息片段之间的连接能力有限 RAG 在跨越多个信息片段以获取综合见解时表现不足 当要回答一个复杂问题时,必须要通过共享属性在不同信息之间建立联系 RAG 无法有效捕捉这些关系 限制了 RAG 在处理需要多跳推理或整合多源数据的复杂查询时的能力 归纳总结能力不足 在处理大型数据集或长文档时,RAG 难以有效地归纳和总结复杂的语义概念 RAG 在需要全面理解和总结复杂语义信息的场景中表现不佳 GraphRAG 利用 LLM 生成的知识图谱来改进 RAG 的检索部分 GraphRAG 利用结构化的实体和关系信息,使得检索过程更加精准和全面 GraphRAG 在处理多跳问题和复杂文档分析时表现出色 GraphRAG 在处理复杂信息处理任务时,显著提升问答性能,提供比 RAG 更为准确和全面的答案 GraphRAG 通过知识图谱有效地连接不同的信息片段 不仅能够提供准确答案,还能展示答案之间的内在联系,提供更丰富和有价值的结果 GraphRAG 先利用知识图谱,关联查询的实体和关系从与知识图谱实体直接相关的文档中检索片段,提供一个更全面、指标化、高信息密度的总结 主...
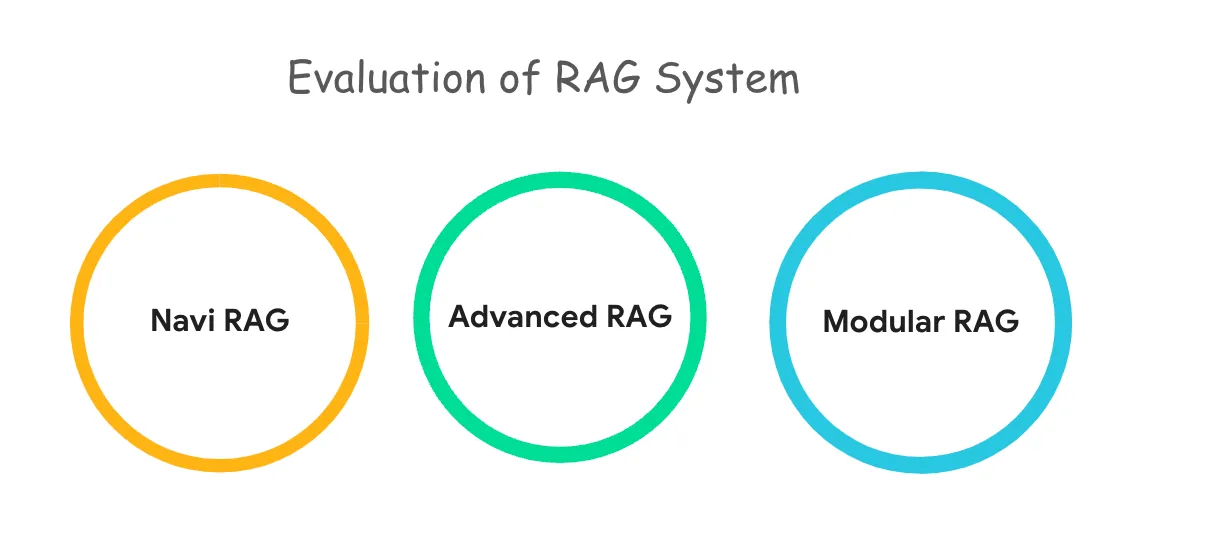
RAG - Evolution
演进 Naive RAG -> Advanced RAG -> Modular RAG 三个范式之间具有继承与发展的关系 Advanced RAG 是 Modular RAG 的一种特例形式 Naive RAG 是 Advanced RAG 的基础特例 RAG 技术不断演进,以适应更复杂的任务和场景需求 Naive RAG Naive RAG 是最基础的形式,依赖核心的索引和检索策略来增强生成模型的输出 Naive RAG 适用于一些基础任务和产品 MVP 阶段 Advanced RAG 通过增加检索前、检索中以及检索后的优化策略,提高检索的准确性和生成的关联性 - 适用于复杂任务 Advanced RAG 通过优化检索前、检索中、检索后的各个环节 在索引质量、检索效果以及生成内容的上下文相关性方面都取得显著提升 检索前 通过索引、分块、查询优化和内容向量化等技术手段,提高检索内容的精确性和生成内容的相关性 滑动窗口 overlap 经典的 Chunking 技术,通过在相邻的 Chunk 之间创建重叠区域,确保关键信息不会因简单的 Chunking 而丢失 在 ...
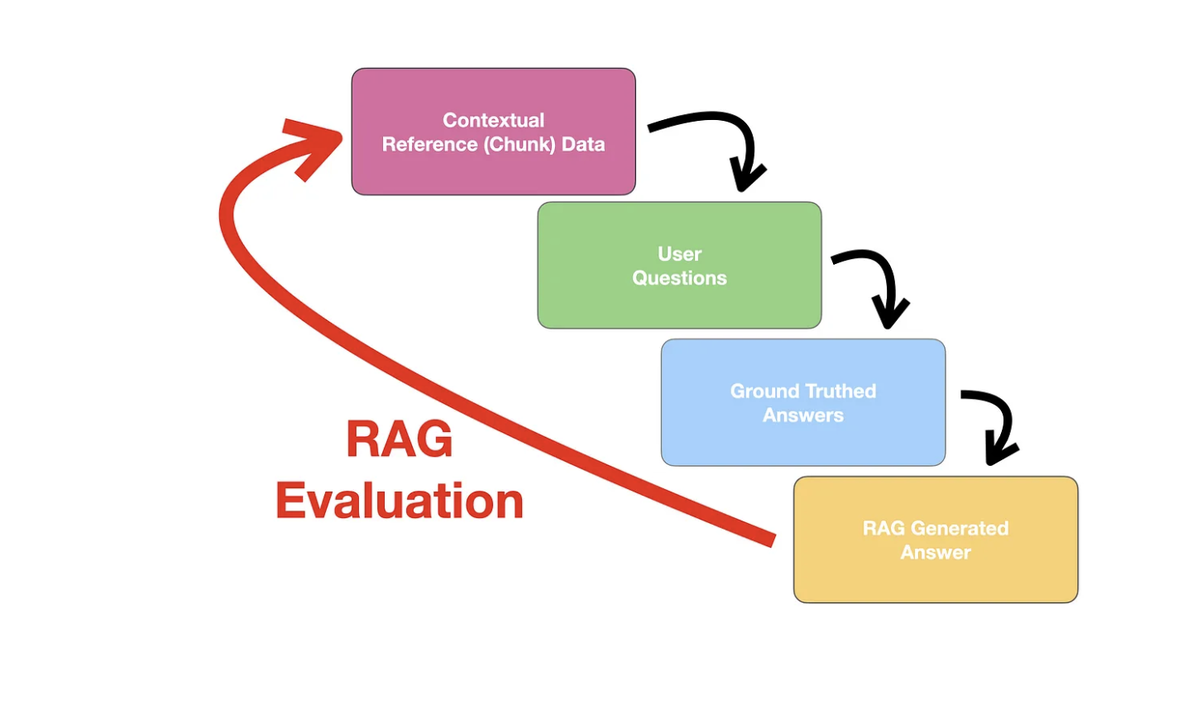
RAG - Optimization + Evaluation
RAG 检索优化数据清洗和预处理 在 RAG 索引流程中,文档解析之后,文档切块之前,进行数据清洗和预处理 减少脏数据和噪音,提升文本的整体质量和信息密度 手段:清除冗余信息、统一格式、处理异常字符等 处理冗余的模板内容 消除文档中的额外空白和格式不一致 去除文档脚注、页眉页脚、版权信息 查询扩写 在 RAG 系统的检索步骤中,用户的查询会转换为向量后进行检索 单个向量查询只能覆盖向量空间中一个有限区域 如果查询中的嵌入向量未能包含所有关键信息,则可能检索到不相关的 Chunk 单点查询的局限性 - 限制系统在庞大文档库中的搜索范围,导致错失与查询语义相关的内容 查询扩写 通过 LLM 从原始查询语句生成多个语义相关的查询,可以覆盖向量空间中的不同区域 提高检索的全面性和准确性 扩写后的查询在被嵌入后,能够击中不同的语义区域 确保系统能够从更广泛的文档中检索到与用户需求相关的有用信息 通过查询扩写,原始问题被分解为多个子查询 每个子查询独立检索相关文档并生成相应的结果 系统将所有子查询的检索结果进行合并和重新排序 能够有效扩展用户的查询意图,确保在复杂信息库中进行更全面的文...




