

Kubernetes - CSI
运行时存储 运行时存储:镜像只读层 + 容器读写层(写性能不高) 容器启动后,运行时所需文件系统的性能直接影响容器性能 早期 Docker 使用 DeviceMapper 作为容器运行时的存储驱动,因为 OverlayFS 尚未合并进 Linux Kernel 目前 Docker 和 containerd 都默认以 OverlayFS 作为运行时存储驱动 OverlayFS 的性能很好,与操作主机文件的性能几乎一致,比 DeviceMapper 优 20% CSI分类 以插件的形式来实现对不同存储的支持和扩展 Plugin Desc in-tree 代码耦合在 Kubernetes 中,社区不再接受新的 in-tree 存储插件 out-of-tree - FlexVolume - Native Call Kubernetes 通过调用 Node 的本地可执行文件与存储插件进行交互FlexVolume 插件需要 Node 用 root 权限安装插件驱动执行模式跟 CNI 非常类似 out-of-tree - CSI - RPC CSI 通过 RPC 与存储驱动进行交互 ...
Kubernetes - CNI
网络分类 Type Desc CNI Pod 到 Pod 的网络,Node 到 Pod 的网络 kube-proxy 通过 Service 访问 Ingress 入站流量 基础原则 所有 Pod 能够不通过 NAT 就能互相访问 所有 Node 能够不通过 NAT 就能互相访问 容器内看到的 IP 地址和外部组件看到的容器 IP 是一样的 补充说明 在 Kubernetes 集群,IP 地址是以 Pod 为单位进行分配的,每个 Pod 拥有一个独立的 IP 地址 一个 Pod 内部的所有容器共享一个网络栈,即宿主上的一个 Network Namespace Pod 内的所有容器能够通过 localhost:port 来连接对方 在 Kubernetes 中,提供一个轻量的通用容器网络接口 CNI Container Network Interface,用来设置和删除容器的网络连通性 Container Runtime 通过 CNI 调用网络插件来完成容器的网络设置 插件分类 下面的 Plugin 均由 ContainerNetworking 组维护 IPAM ...
Kubernetes - CRI
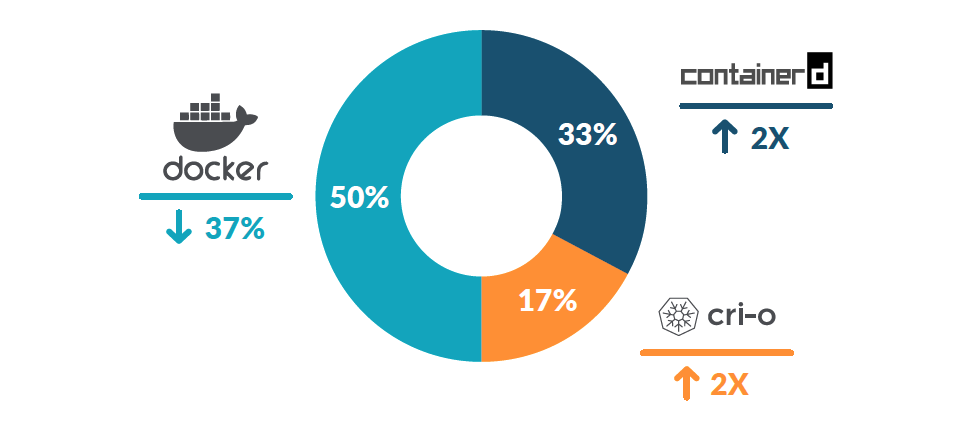
概述 Container Runtime 位于 Node 上,负责容器的整个生命周期,其中 Docker 应用最为广泛 CRI 是 Kubernetes 定义的一组 gRPC 服务 Dockershim 支持 CRI,代码耦合在 kubelet 中 而 Docker 本身是不支持 CRI 的,但 Docker 内部的 containerd 是支持 CRI 的 Kubelet 作为客户端,基于 gRPC 框架,通过 Socket 和 Container Runtime 通信 Container Runtime 提供 gRPC 服务 Image Service - 下载、检查和删除镜像 Runtime Service - 容器生命周期管理 + 与容器交互 区分了 SandBox + Container Push Image 并不在 CRI 中 – 开发环境用 Docker,生产环境用 containerd 运行时分层 Runtime Impl CRI - High-level - gRPC Dockershim / containerd / CRI-O...
Kubernetes - Kubelet
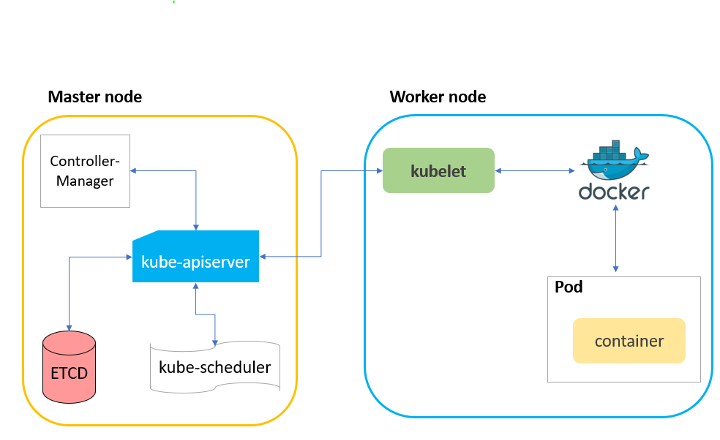
架构 每个 Node 上运行一个 Kubelet 服务进程,默认监听 10250 端口 接收并执行 Master 的指令 管理 Pod 以及 Pod 中的容器 在 API Server 注册 Node 信息,定期向 Master 汇报 Node 的资源使用情况 通过 cAdvisor 监控 Node 和容器的资源 cAdvisor 通过 Cgroups 收集并上报容器的资源用量 Node 管理 Node 自注册 + Node 状态更新 自注册模式:Kubelet 通过启动参数 --register-node 来确定是否向 API Server 注册 Kubelet 没有选择自注册模式 用户需要自己配置 Node 资源信息 告知 Kubelet 集群上的 API Server 的位置 Kubelet 选择自注册模式 Kubelet 定时向 API Server 发送 Node 信息 API Server 在接收到 Node 信息后,转存到 etcd Pod 管理 syncLoop - Kubelet 本身也是控制器模式 computePodActions - 比对 Pod...
Kubernetes - Controller Manager
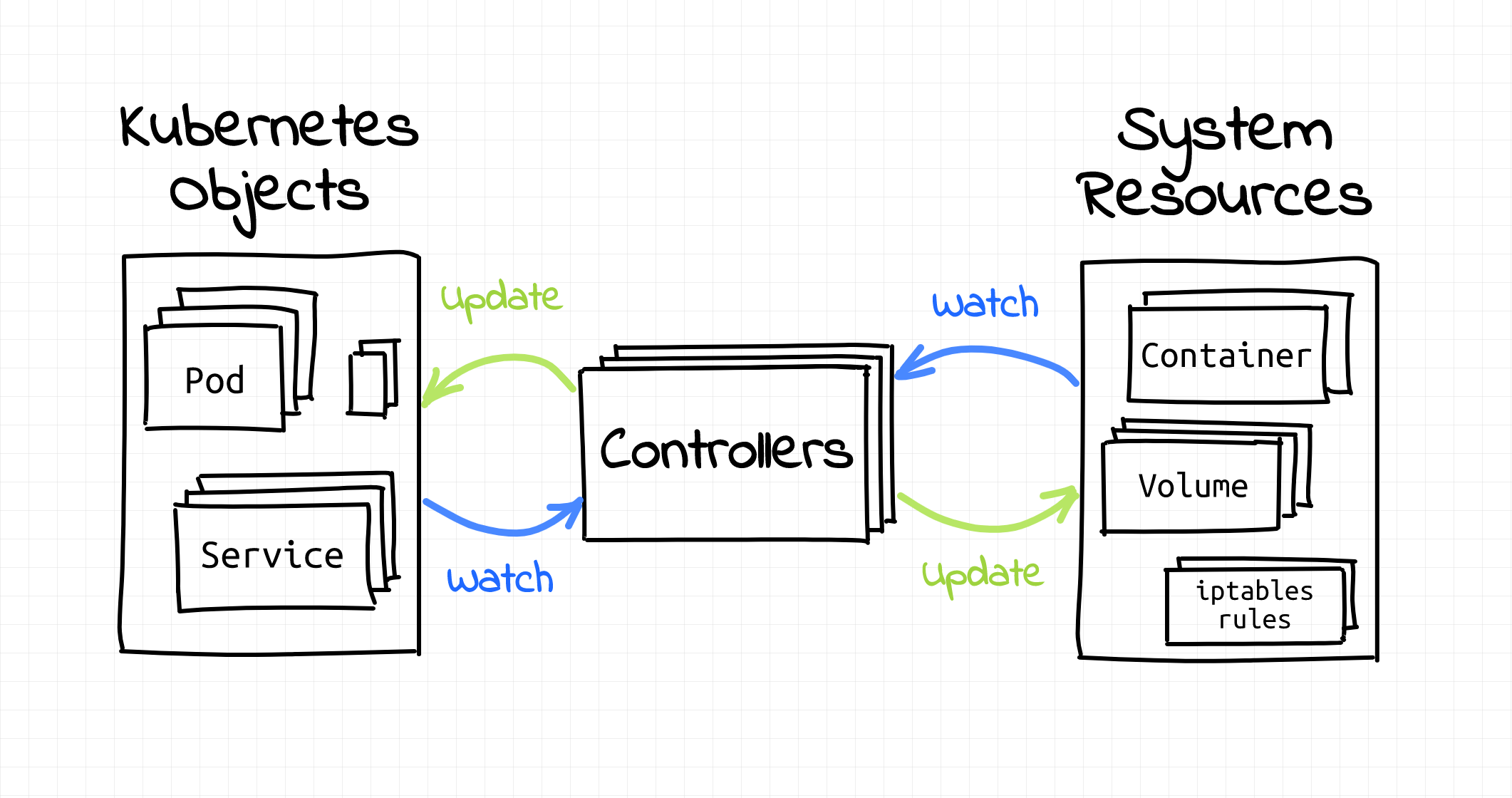
工作流程 Informer Framework 和 Lister Framework 可以借助代码生成器生成 Lister 维护了一份 API Server 的缓存数据(减少对 API Server 的访问压力) Informer 会通过 Indexer 为对象计算一个 Key,然后入队,Worker 会消费队列,并从 Lister 查询缓存数据 核心 Controller Controller Manager 是 Controller 的集合 Controller Desc API Job Controller 处理 Job Cronjob Controller 处理 Cronjob Pod AutoScaler 处理 Pod 的自动扩缩容 HorizontalPodAutoscaler RelicaSet 依据 RelicaSet Spec 创建 Pod Service Controller 依据 Service 的 LoadBalancer Type 创建 LB VIP ServiceAccount Controller 确保 Servi...
Kubernetes - Scheduler
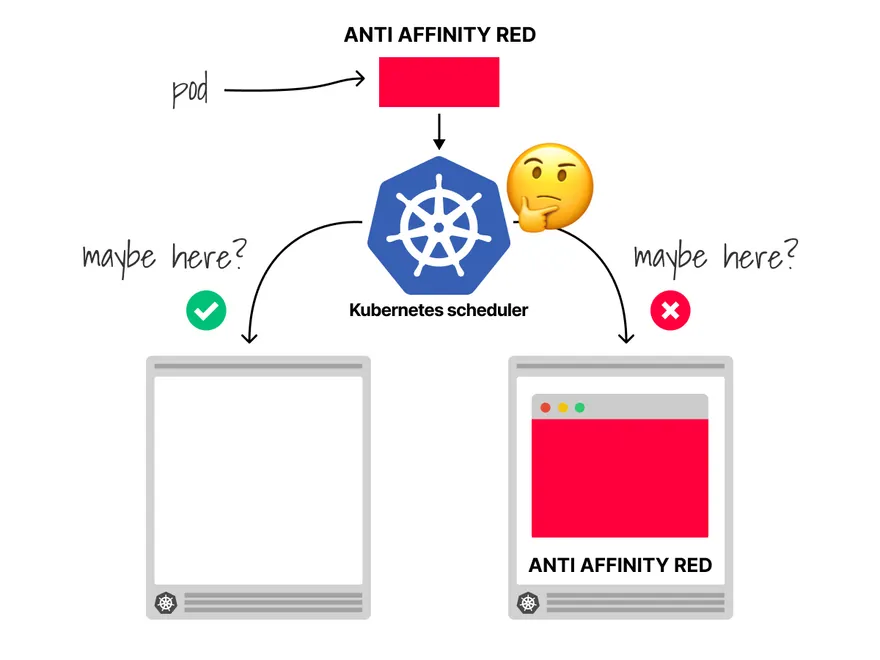
概述 kube-scheduler 负责分配调度 Pod 到集群内的 Node 上 监听 kube-apiserver,查询还未分配 Node 的 Pod,然后根据调度策略为这些 Pod 分配 Node 123456789$ k get po -n kube-system coredns-7f6cbbb7b8-njp2w -oyamlapiVersion: v1kind: Podmetadata: ...spec: ... nodeName: mac-k8s ... 阶段 Stage Desc predicate 过滤不符合条件的 Node priority 优先级排序,选择优先级最高的 Node Predicates 过滤 Strategy Strategy Desc PodFitsHostPorts 检查是否有 Host Ports 冲突 PodFitsPorts 与 PodFitsHostPorts 一致 PodFitsResources 检查 Node 的资源是否充足 HostName 检查候选 Node 与 pod.Spec....
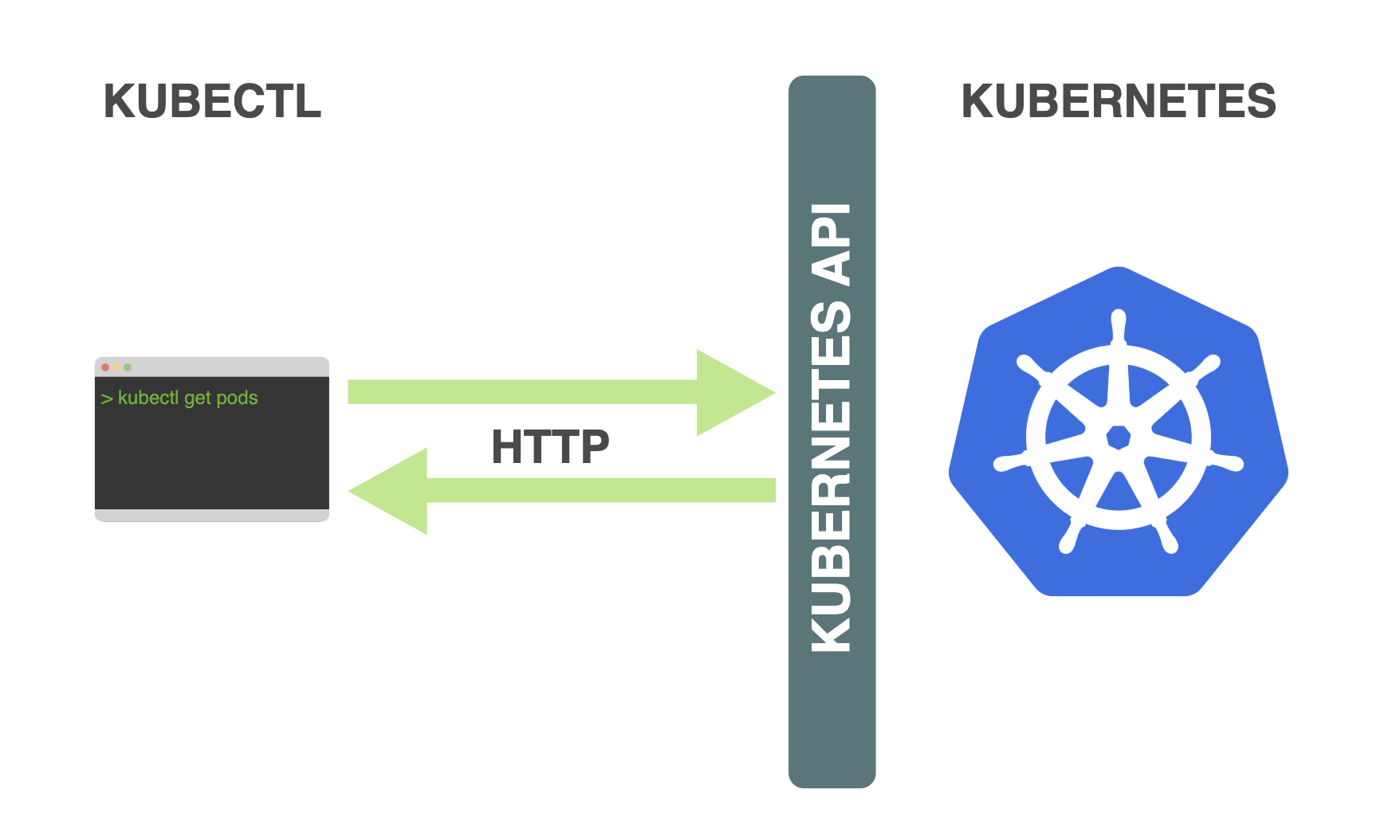
Kubernetes - API Server
概述 API Server 提供集群管理的 REST API 提供其它模块之间数据交互和通信的枢纽 其它模块通过 API Server 查询或者修改数据,只有 API Server 才能直接操作 etcd 访问控制:认证 + 鉴权 + 准入 Mutating Admission 可以修改对象,而 Validating Admission 不可以修改对象 认证 开启 TLS 时,所有请求都需要首先认证 Kubernetes 支持多种认证机制,并支持同时开启多个认证插件(只需要有 1 个认证通过即可) 如果认证成功,进入鉴权模块,如果认证失败,则返回 401 认证插件 X509 证书 在 API Server 启动时配置 --client-ca-file CN 域(CommonName)用作用户名,而O 域(Organization)则用作 Group 名 静态 Token 文件 在 API Server 启动时配置 --token-auth-file 采用 csv 格式:token,user,uid,[group...] 引导 Token 目的:为了支持平滑地启动...
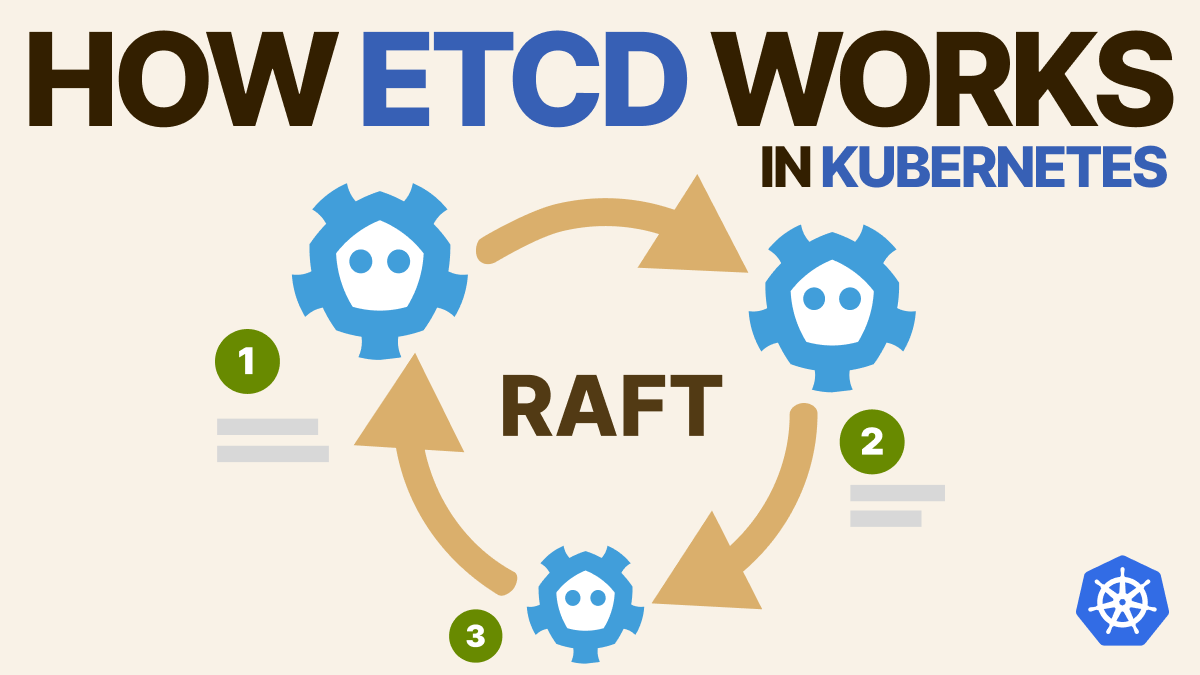
Kubernetes - etcd
概述 CoreOS 基于 Raft 开发的分布式 KV 存储,可用于服务发现、共享配置和一致性保障(Leader 选举、分布式锁) A distributed, reliable key-value store for the most critical data of a distributed system Key Desc KV 存储 将数据存储在分层组织的目录中,类似于标准的文件系统 监测变更 监测特定的 Key 或者目录以进行变更,并对值的更改做出反应 简单 curl: HTTP + JSON 安全 TLS 客户端证书认证,有一套完备的授权认证体系,但 Kubernetes 并没有使用 快速 单实例:1000 TPS、2000 QPS 可靠 使用 Raft 算法保证分布式一致性 主要功能 基本的 KV 存储 - Kubernetes 使用最多 监听机制 Key 的过期和续约机制,用于监控和服务发现 原生支持 Compare And Swap 和 Compare And Delete,用于 Leader 选举和分布式锁 KV 存储 KV...

Kubernetes - Architectural principles
主要功能 基于容器的应用部署、维护和滚动升级 服务发现和负载均衡 跨机器和跨地区的集群调度 自动伸缩 无状态服务和有状态服务 插件机制保证扩展性 命令式 vs 声明式 YAML 命令式关注:如何做 声明式关注:做什么 核心对象 Kubernetes 的所有管理能力是构建在对象抽象的基础上 对象 描述 Node 计算节点的抽象 Namespace 资源隔离的基本单位 Pod 用来描述应用实例,最为核心的对象 Service 如何将应用发布为服务,本质上是负载均衡和域名服务的声明 核心架构 核心组件 Scheduler关注没有与 Node 绑定的 Pod,完成调度后,会将信息写入 etcd,而 kubelet 会监听到 Master 组件 描述 API Server API 网关 Cluster Data Store etcd:分布式 kv 存储,K8S 将所有 API 对象持久存储在 etcd Controller Manager 处理集群日常任务的控制器:节点控制器、副本控制器等 Scheduler 监控新建的 Pods 并将其分配给...

Kubernetes - Cgroups
Namespace 隔离不完备 在 Linux 内核中,有很多资源和对象是不能被 Namespace 化的,例如时间 如果在容器中使用 settimeofday(2) 的系统调用,整个宿主机的时间都会被修改 Cgroups 在 Linux 中,Cgroups 暴露给用户的操作接口是文件系统 1234567891011121314151617181920$ mount -t cgroupcgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,name=systemd)cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)cgroup on /sys/fs/cgroup/devices typ...




