

AI Native Dev - SDD
权力反转 代码服务于规范,前提是规范是可被机器精确理解和执行的 编译意图 由 AI 驱动,将高层级、模糊的、非结构化的人类意图,逐步转换、细化,并最终固化为低层架、精确的、结构化的机器可执行指令 Stage Desc 需求编译器 将用自然语言描述的模糊想法,编译成一份结构化的、无歧义的需求规范 spec.md 方案编译器 将需求规范与技术约束相结合,编译成一份详尽的技术实现蓝图 plan.md 任务编译器 将技术蓝图,编译成一份带依赖关系的,原子化的任务指令集 tasks.md 代码生成器 最终,根据任务指令集,生成最终的可执行代码 SDD - 为 AI 的多阶段编译过程提供高质量的源代码(规范),并监督每一步编译的结果 工作流阶段 1 - 意图定义 Key Value 目标 澄清并固化做什么(WHAT)和为什么做(WHY) 输入 开发者或产品经理提出的高层级、模糊的自然语言想法 核心活动 人机协作进行头脑风暴,挖掘边缘场景,澄清模糊地带,定义验收标准 输出产物 spec.md 需求规范与技术实现完全解耦,只关心用户故事、功能需求和成功标准...
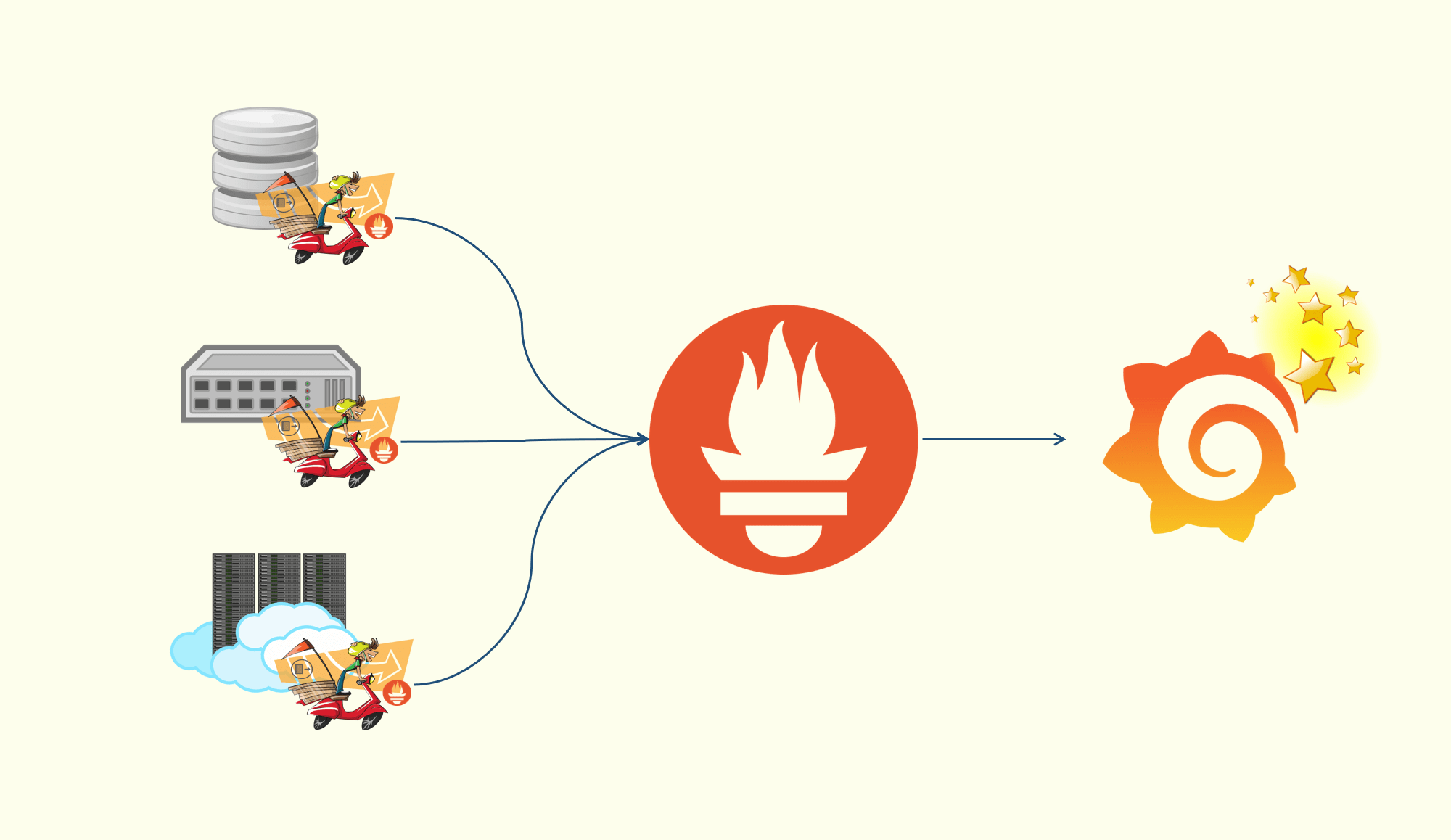
Observability - Prometheus Server V1
OpenTelemetry vs Prometheus123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106关系概述:互补为主,渐趋融合OpenTelemetry 和 Prometheus 在指标领域主要是互补关系,而非冲突。两个项目都在积极合作以实现更好的互操作性。1. 定位差异Prometheus:- 完整的监控系统(采集、存储、查询、告警)- 专注于指标监控- 拉模型(Pull-based)为主- 拥有成熟的时序数据库和查询语言 PromQLOpenTelemetry:- 标准化的遥测数据收集框架- 支持三大信号:指标、追踪、日志- 推模型(Push-based)为主- 不提供存储和查询后端2. 技术模型对比| 特性 | Promet...

Observability - Prometheus Concepts
Data model Prometheus fundamentally stores all data as time series streams of timestamped values belonging to the same metric and the same set of labeled dimensions. Besides stored time series, Prometheus may generate temporary derived time series as the result of queries. Metric names and labelsEvery time series is uniquely identified by its metric name and optional key-value pairs called labels. Metric names Metric names SHOULD specify the general feature of a system that is measured e.g. http_req...

Observability - Prometheus Introduction
Summary Open source metrics and monitoring for your systems and services. Monitor your applications, systems, and services with the leading open source monitoring solution. Instrument, collect, store, and query your metrics for alerting, dashboarding, and other use cases. Feature Desc Dimensional data model Prometheus models time series in a flexible dimensional data model.Time series are identified by a metric name and a set of key-value pairs. Powerful queries The PromQL query language allow...
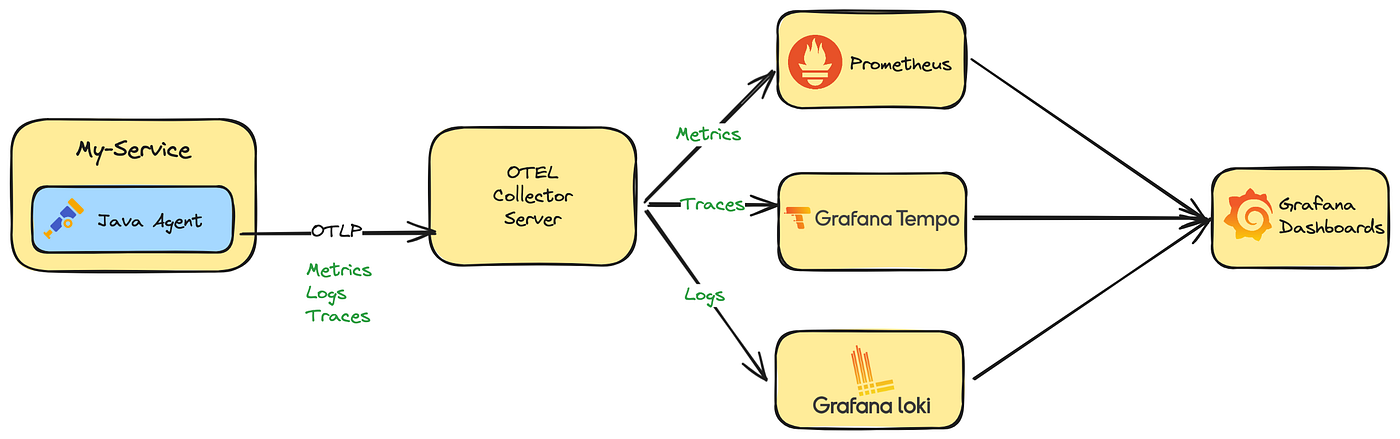
Observability - OpenTelemetry Java Zero Code
Java Agent Zero-code instrumentation with Java uses a Java agent JAR attached to any Java 8+ application. It dynamically injects bytecode to capture telemetry from many popular libraries and frameworks. It can be used to capture telemetry data at the “edges” of an app or service such as inbound requests, outbound HTTP calls, database calls, and so on. Getting startedSetup Download opentelemetry-javaagent.jar from Releases of the opentelemetry-java-instrumentation repository place the JAR in your pre...
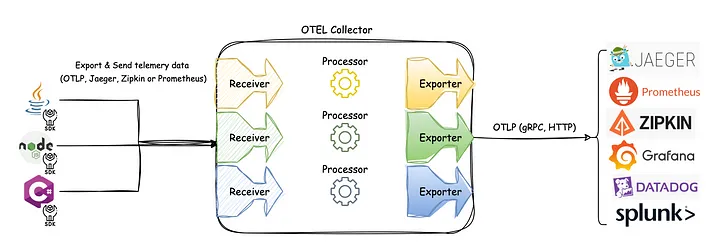
Observability - OpenTelemetry Java
Intro to OpenTelemetry Java OpenTelemetry Java is the set of OpenTelemetry observability tools for the Java ecosystem. At a high level, it consists of the API, the SDK, and instrumentation. Overview The API is a set of classes and interfaces for recording telemetry across key observability signals. It supports multiple implementations, with a low-overhead minimalist Noop and SDK reference implementation provided out of the box. It is designed to be taken as a direct dependency by libraries, framewor...

AI Agent - MCP Overview
提示工程 + RAG LLM 可以开箱即用,通过提示工程和它直接对话并解决问题 随着 LLM 的能力越来越强,尤其是其推理模型的出现,LLM 的回答越来越准确 但 LLM 并非全知全能,预训练的数据有截止时间 - RAG RAG 是一种 LLM 应用开发范式 将 LLM 与外部数据源相结合来提高准确性和相关性 先通过向量之间的相似度,用检索系统从外部数据源搜索数据,以识别与用户查询相关的信息 LLM 随后利用检索到信息生成更精确,更及时的响应 RAG 过程 - 通过 RAG 增加 LLM 的知识,大大提高了 LLM 回答的准确性和相关性 Key Value 检索 通过向量数据库或者其它检索系统,找出与用户查询相关的信息 增强 将检索到的信息作为上下文提供给 LLM 生成 LLM 基于这些额外信息生成回答 Agent + Tool Call RAG 解决的是让 LLM 使用内部知识,同时减少幻觉的问题,但 RAG 本身并没有增强 LLM 的行动能力 - Agent Agent 本质上是赋予 LLM 使用工具并采取行动的开发范式 Agent 的工作流程 K...

AI Agent - Overview
技术更迭 LLM 应用工程化难题 模型与外部世界割裂 LLM 是基于概率计算的新范式,虽然很强大,但仍需要与传统的结构化计算范式相结合,即通过工具调用来完成精确任务 目前传统结构化工具与 LLM 之间是割裂的,LLM 难以直接动态地接入实时数据、数据库或企业工具 传统的 API 调用方式零散且不标准,导致开发效率低下 Agent 协作的孤岛效应 不同 Agent 框架(LangGraph、AutoGen、CrewAI)各自为政,缺乏统一的通信标准,跨平台协作很难实现 复杂场景的工程化瓶颈 从搜索助手到企业知识中台、RAG 与多 Agent 系统需要处理多源数据、多模态交互和长时任务,现有工具链难以提供统一的解决方案 MCP + A2A 标准化 + 可扩展 MCP 模型主控 + 客户端驱动 MCP 是一个为 LLM 更方便地利用外部资源(主要是工具)而设计的标准化接口,旨在打破 LLM 与外部数据、工具之间的壁垒 传统上,将 AI 系统连接到外部工具需要集成多个 API - 代码冗余 + 难以维护 + 扩展性差 MCP 将繁琐细节都隐藏到服务器端 - 开发者只需关心 LLM...

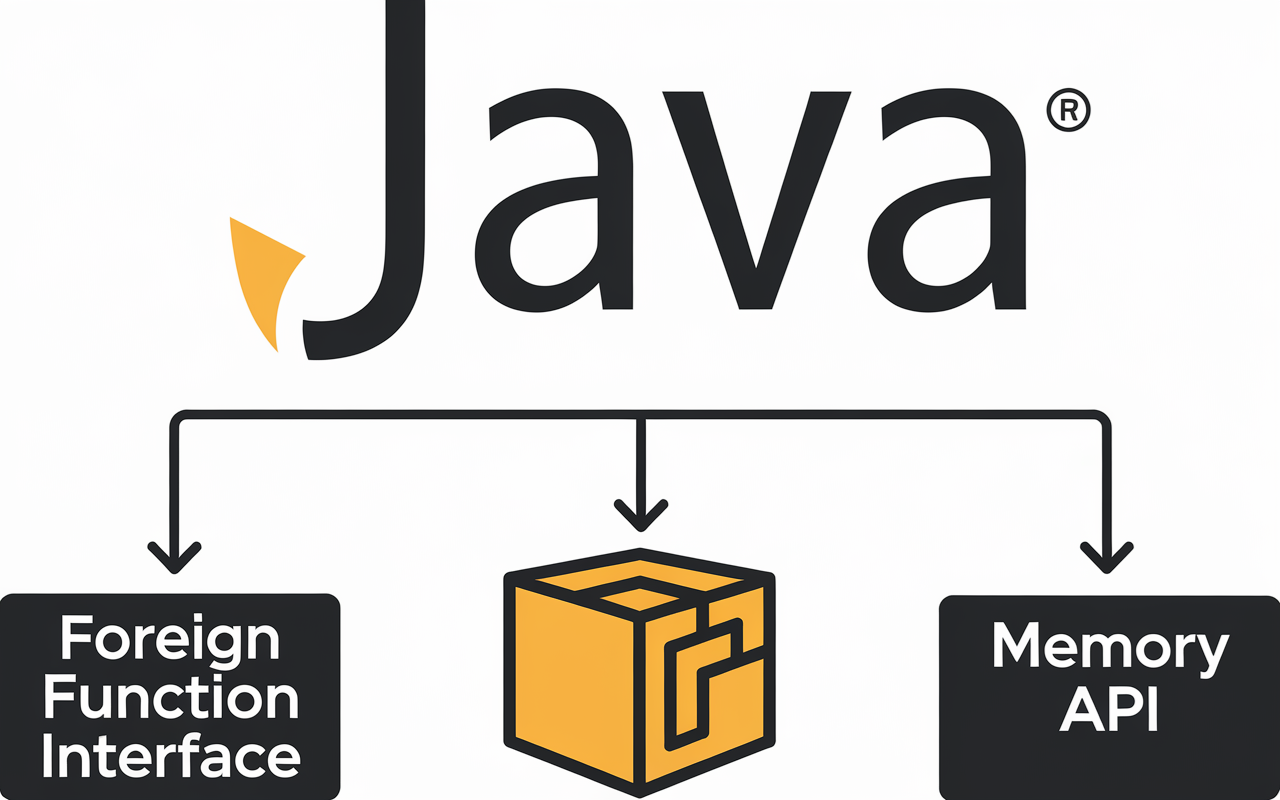
New Java Feature - Foreign Function API
概述 Java 的外部函数接口这个特性,与外部内存接口一起,会极大地丰富 Java 语言的生态环境 像 Java 或者 Go 这样的通用编程语言,都需要和其它的编程语言或者环境打交道 - 如操作系统或者 C 语言 Java 通过 Java 本地接口 JNI 来支持该做法 本地方法接口示例1234567891011public class HelloWorld { static { System.loadLibrary("helloWorld"); } public static void main(String[] args) { new HelloWorld().sayHello(); } private native void sayHello();} sayHello 使用了 native 修饰符,是一个本地方法,可以使用 C 语言实现 - 生成对应的 C 语言的头文件 1234$ javac -h . HelloWorld.java$ lsHe...
New Java Feature - Foreign Memory API
概述 在讨论代码性能的时候,内存的使用效率是一个绕不开的话题 - Flink/Netty 为了避免 JVM GC 不可预测的行为以及额外的性能开销,一般倾向于使用 JVM 之外的内存来存储和管理数据 - 堆外数据 - off-heap data 使用堆外存储最常用的办法,是使用 ByteBuffer 来分配直接存储空间 - direct buffer JVM 会尽最大努力直接在 direct buffer 上执行 IO 操作,避免数据在本地和 JVM 之间的拷贝 频繁的内存拷贝是性能的主要障碍之一 为了极致的性能,应用程序通常会尽量避免内存的拷贝 理想的情况下,一份数据只需要一份内存空间 - 即零拷贝 ByteBuffer 使用 ByteBuffer 来分配直接存储空间 1public static ByteBuffer allocateDirect(int capacity); ByteBuffer 所在的 Java 包是 java.nio,ByteBuffer 的设计初衷是用于非阻塞编程 ByteBuffer 是异步编程和非阻塞编程的核心类,几乎所有的 Java 异步模...




