
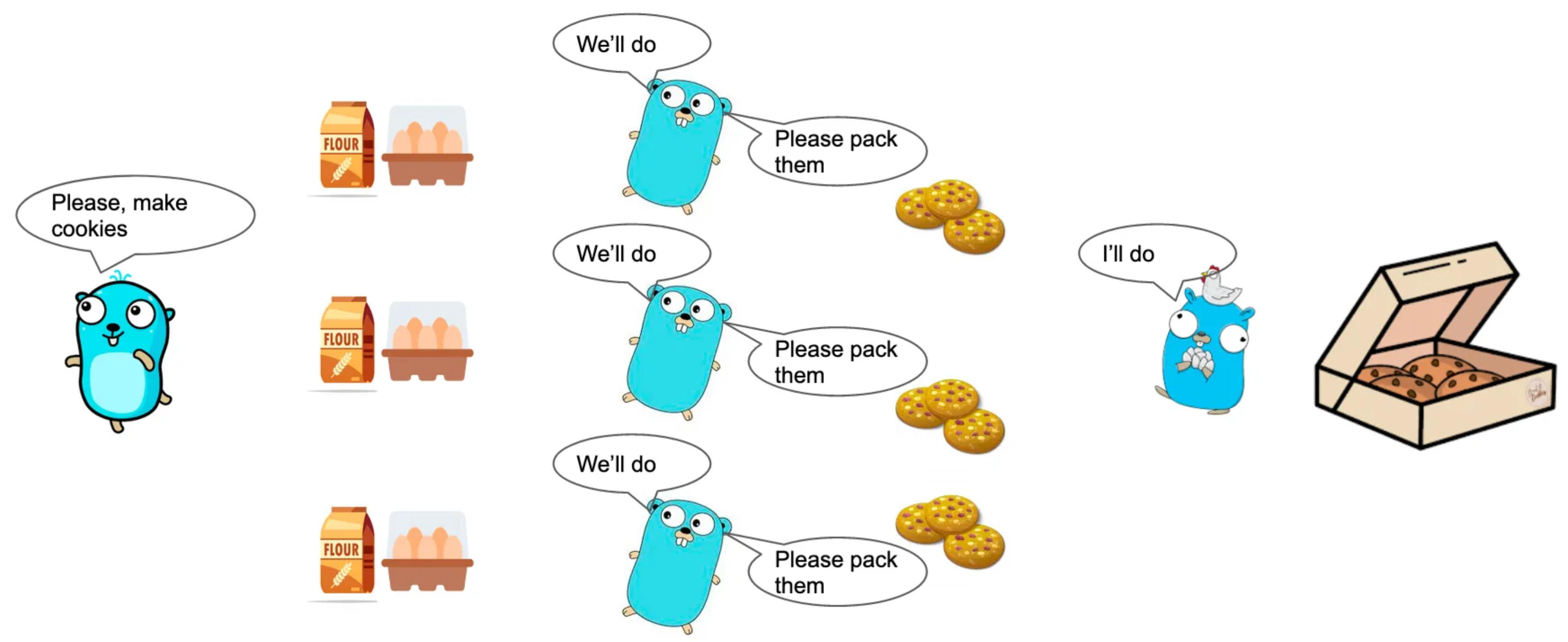
Go Paradigm - MapReduce
IntroductionMap1234567891011121314151617181920212223242526272829func MapStrToStr(arr []string, fn func(s string) string) []string { var sl []string for _, s := range arr { sl = append(sl, fn(s)) } return sl}func MapStrToInt(arr []string, fn func(s string) int) []int { var sl []int for _, s := range arr { sl = append(sl, fn(s)) } return sl}func main() { list := []string{"hello", "world"} ...

Go Paradigm - Delegation + IoC
嵌入委托123456789101112131415161718192021222324252627package maintype Widget struct { X, Y int}type Label struct { Widget // type embedding - delegation Text string // aggregation}type Button struct { Label // type embedding - delegation}type ListBox struct { Widget // type embedding - delegation Texts []string // aggregation Index int // aggregation}func main() { label := Label{Widget{10, 10}, "...

Go Paradigm - Functional Options
配置问题12345678type Server struct { Addr string Port int Protocol string Timeout time.Duration MaxConns int TLS *tls.Config} Go 不支持函数重载,需要使用不同的函数名来应对不同的配置选项 123456789101112131415func NewDefaultServer(addr string, port int) (*Server, error) { return &Server{addr, port, "tcp", 30 * time.Second, 100, nil}, nil}func NewTLSServer(addr string, port int, tls *tls.Config) (*Server, error) { return &Server{addr, port, &q...

Cloud Native Foundation - Overview
基本概念 在包括公有云、私有云、混合云等动态环境中构建和运行规模化应用的能力 云原生是一种思想,是技术、企业管理方法的集合 技术层面 应用程序从设计之初就为在云上运行而做好准备 云平台基于自动化体系 流程层面 基于 DevOps CI/CD 基于多种手段 应用容器化封装 服务网格 不可变基础设施 声明式API - 核心 + 标准 意义 提升系统的适应性、可管理性、可观测性 使工程师能以最小成本进行频繁和可预测的系统变更 提升速度和效率,助力业务成长,缩短I2M(Idea to Market) 核心项目

Web -- SAML
背景 近期工作与SAML相关,用Wireshark抓包,记录下相关网络包,以作备忘 案例:https://opendistro.github.io/for-elasticsearch-docs/docs/security/configuration/saml/ Wireshark文件:https://web-1253868755.cos.ap-guangzhou.myqcloud.com/uPic/saml.pcapng Bootstrap Login Logout

Web -- Cookie
背景 之前的工作接触Cookie相关的内容比较少,故记录下相关领域知识,以作备忘 Cookie是什么 Cookie是浏览器存储在用户电脑上的一小段文本文件 Cookie为纯文本格式,不包含任何可执行的代码 一个Web页面或者服务器告知浏览器按照一定规范来存储Cookie,并在随后的请求中将这些信息发送至服务器 Web服务器可以通过使用这些信息来识别不同的用户 大多数需要登录的网站在用户验证成功后都会设置一个Cookie 只要该Cookie存在并且合法,用户就可以自由浏览该网站的任意页面 创建Cookie12345== HTTP ResponseSet-Cookie: value[; expires=date][; domain=domain][; path=path][; secure]== HTTP RequestCookie: value Web服务器通过发送一个名为Set-Cookie的HTTP的Header来创建一个Cookie value:通常为name=value的格式 通过Set-Cookie指定的可选项只会在浏览器端使用,而不会被再次发送至服务器 Cookie会在...

应用配置管理
Pod 配置管理 Key Value 独立资源 ConfigMap Secret ServiceAccount Pod.spec Resources SecurityContext InitContainers ConfigMap用途 管理容器运行时所需要的配置文件、环境变量、命令行参数等可变配置 用于解耦容器镜像和可变配置,从而保证工作负载(Pod)的可移植性 创建指定键值对12345678910111213141516$ kubectl create configmap special-config --from-literal=special.how=very --from-literal=special.type=charmconfigmap/special-config created$ kubectl get configmaps special-config -o yamlapiVersion: v1data: special.how: very special.type: charmkind: ConfigMapmetadata: ...

应用编排与管理 -- DaemonSet
作用 保证集群内每一个或者一些节点都运行一组相同的 Pod 跟踪集群节点状态,保证新加入的节点自动创建对应的 Pod 跟踪集群节点状态,保证移除的节点删除对应的 Pod 跟踪 Pod 状态,保证每个节点 Pod 处于运行状态 实践YAML 文件ds.yaml12345678910111213141516171819apiVersion: apps/v1kind: DaemonSetmetadata: name: fluentd-elasticsearch namespace: kube-system labels: k8s-app: fluentd-loggingspec: selector: matchLabels: name: fluentd-elasticsearch template: # Pod Template metadata: labels: name: fluentd-elasticsearch spec: containers: - name: fluentd-elasticsearch...

应用编排与管理 -- Job + CronJob
Job作用 创建一个或多个 Pod 来确保指定数量的 Pod 可以成功地运行终止 跟踪 Pod 状态,根据配置及时重试失败的 Pod 确定依赖关系,保证上一个任务运行完毕后再运行下一个任务 控制任务并行度,并根据配置确保 Pod 队列大小 实践YAML 文件job.yaml123456789101112131415161718apiVersion: batch/v1kind: Jobmetadata: name: pispec: backoffLimit: 4 # 重试次数 template: # Pod Selector spec: containers: - name: pi image: perl ports: null command: - perl - '-Mbignum=bpi' - '-wle' - print bpi(2000) restartP...

应用编排与管理 -- Deployment
作用每个 Deployment 管理一组相同的应用 Pod(相同的一个副本) 实践YAML 文件nginx-deployment123456789101112131415161718192021apiVersion: apps/v1kind: Deploymentmetadata: name: nginx-deployment labels: app: nginxspec: replicas: 3 # 期望的 Pod 数量 selector: # Pod Selector matchLabels: app: nginx template: # Pod Template metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80 查看 Deployment123456789$ kubectl g...




