eBPF - Overview
eBPF Extended Berkeley Packet Filter eBPF 是一种数据包过滤技术,从 BPF 技术扩展而来 BPF 提供了一种在内核事件和用户程序事件发生时安全注入代码的机制,让非内核开发人员也可以对内核进行控制 随着内核的发展,BPF 从最初的数据包过滤,扩展到网络、内核、安全、跟踪等,扩展后的 BPF 被称为 eBPF,早期的 BPF 被称为经典 BPF,即 cBPF 现代内核所运行的都是 eBPF 特性 在 eBPF 之前,内核模块是注入内核的最主要机制 由于缺乏对内核模块的安全控制,内核的基本功能很容易被一个有缺陷的内核模块破坏 eBPF 借助 JIT,在内核中运行一个虚拟机,保证只有被验证安全的 eBPF 指令才会被内核执行 同时,eBPF 指令依然运行在内核中,无需向用户态复制数据,极大地提高了事件处理的效率 eBPF 在故障诊断、网络优化、安全控制、性能监控等领域获得了大量应用 高性能网络负载均衡器 - Katran 容器网络方案 - Cilium 内核跟踪排错工具 - BCC + bpftrace 概览 技术栈 掌握 eBPF 并不需要掌握内核开发...

Java Feature - Switch Pattern Matching
OOP 存在潜在的兼容性问题 Switch 模式匹配 将模式匹配扩展到 switch 语句和 switch 表达式 允许测试多个模式,每个模式都可以有特定的操作 123456public static boolean isSquare(Shape shape) { return switch (shape) { case null, Shape.Circle c -> false; case Shape.Square s -> true; };} 扩充的匹配类型 在 JDK 17 之前,switch 关键字可以匹配的数据类型 - 数字 + 枚举 + 字符串 - 本质上是整型的原始类型 在 JDK 17 开始,支持引用类型 支持 null - 不会抛出 NPE - 在 JDK 17 之前需要先判空 12345678910public static boolean isSquare(Shape shape) { if (shape == null) { re...

Java Feature - Switch
概述 Switch 表达式在 JDK 14 正式发布 在 Java 规范中,表达式完成对数据的操作 表达式的结果:可以是一个数值(i * 4),也可以是一个变量(i = 4),或者什么都不是(void 类型) Java 语句是 Java 最基本的可执行单位,本身不是一个数值,也不是一个变量 Java 语句的标志符号为分号(代码)和双引号(代码块) Switch 语句 break 语句 常见错误 - break 语句的遗漏或者冗余 凡是使用 switch 语句的代码,都有可能成为黑客们重点关注的对象 在 Code Review 时需重点关注 - 增加代码维护成本 + 降低生产效率 break 语句是一个弊大于利的设计 设计一门现代的语言,需要更多地使用 Switch 语句,但不要再使用 break 语句 - Go 需要依然存在 - 不同的场景共享代码片段 反复出现的赋值语句 本地变量的声明和实际赋值是分开的 在 Switch 语句中,本地变量没有被赋值,编译器也不会报错,使用缺省或者初始化的变量值 为了判断本地变量有没有合适的值,需要通览整个 Switch ...
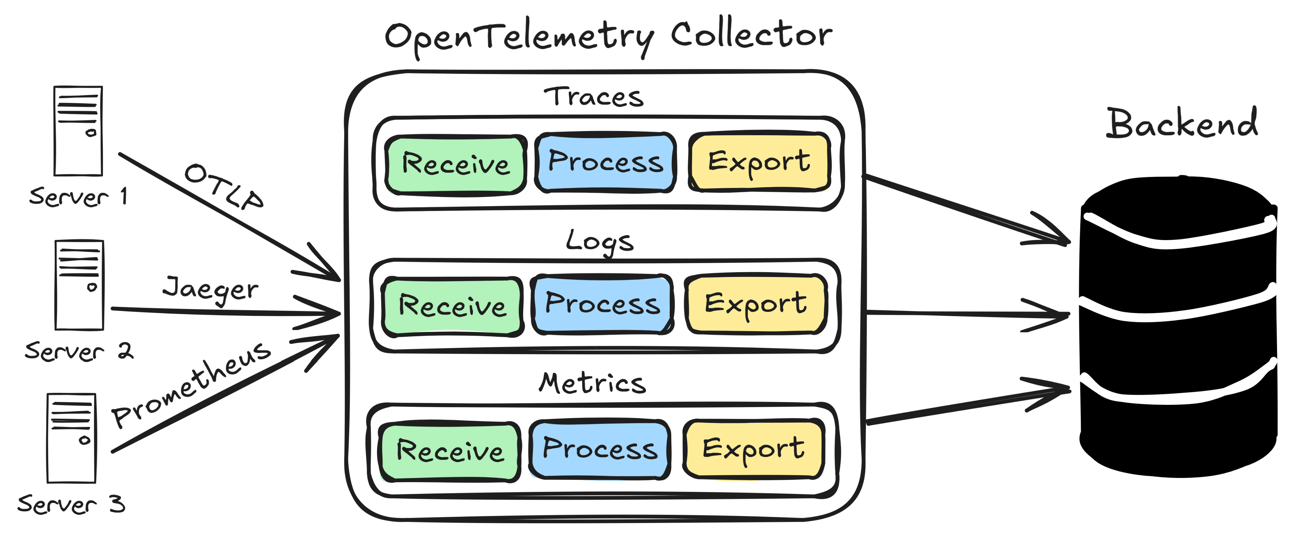
Observability - OpenTelemetry
简介 OpenTelemetry 简称 OTel,是 CNCF 的一个可观测性项目 OpenTelemetry 旨在提供可观测性领域的标准化方案 解决遥测数据的数据建模、采集、处理和导出等标准化问题,并能将数据发送到后端 - 避免厂商锁定 历史 在 OpenTelemetry 之前,已经出现过 OpenTracing 和 OpenCensus 两套标准 在 APM 领域,有 Jaeger、Pinpoint、Zipkin 等多个开源产品,都有独立的数据采集标准和 SDK OpenTracing 制订了一套与平台和厂商无关的协议标准,能够方便地添加或者更换底层 APM 实现 2016 年 11 月,CNCF 接受 OpenTracing 成为第三个项目 - Kubernetes + Prometheus OpenCensus 由谷歌发起,包括 Metrics,而微软也加入了 OpenCensus 在功能和特性上,OpenTracing 和 OpenCensus 差不多,都想统一对方,此时 OpenTelemetry 横空出世 OpenTelemetry 同时兼容 OpenTracing 和 O...

Observability - Concept
概述 可观测性 - 从系统向外部输出的信息来推断出系统内部状态的好坏 可观测强调的是一种度量能力 在不发布新代码(如新增诊断日志)的情况下理解系统内部状态 - 系统具有可观测性 Metrics + Logs + Tracing Metrics + Logs + Tracing 只是遥测数据类型,而 Observability 并非具体技术,而是系统属性,类似于 HA Key Desc Metrics 在一段时间内测量的数值,默认是结构化的,便于查询和存储优化 Logs 对特定时间发生的事件的文本记录,一般是非结构化字符串,会在程序执行期间被写入磁盘 Tracing 表示请求通过分布式系统的端到端的路径,执行的每个操作被称为 Span Tracing 一般会通过可视化的瀑布图展现出来 Metrics 由于 Metrics 最大的特点是聚合性 Metrics 生成的数值是反映预定义时间段内系统状态的汇总报告 - 缺乏颗粒度 Metrics 之间可能彼此不相关 Metrics 常用于 - 静态仪表盘的构建、随时间变化的趋势分析、监控维度是否保持在定义的阈值内 但都...

Java Feature - Type Matching
模式匹配 匹配谓词 + 匹配变量 Java 模式匹配是一个新型的、还在持续快速演进的领域 类型匹配是模式匹配的一个规范,在 JDK 16 正式发布 一个模式是匹配谓词和匹配变量的组合 匹配谓词用来确定模式和目标是否匹配 在模式和目标匹配的情况下,匹配变量是从匹配目标中提取出来的一个或多个变量 对类型匹配来说 匹配谓词用来指定模式的数据类型 匹配变量数属于该类型的数据变量 - 只有一个 类型转换 生产力低下 - 类型判断 + 类型转换 类型判断语句,即匹配谓词 - shape instanceof Rectangle 类型转换语句,使用类型转换运算符 - (Rectangle) shape 声明一个新的本地变量,即匹配变量,来承载类型转换后的数据 - Rectangle rectangle = 类型匹配 都在同一个语句中,只有匹配谓词和本地变量两部分 避免误用 - 编译器不会允许使用没有赋值的匹配变量 作用域 匹配变量的作用域 匹配变量的作用域,即目标变量可以被确认匹配的范围 如果在一个范围内,无法确认目标变量是否被匹配,或者目标变量不能被匹配,都不能使用匹配变...

Java Feature - Sealed
概述 封闭类在 JDK 17 正式发布 OOP 问题根源 - 无限制的扩展性 限制可扩展性 OOP 的最佳实践 - 把可扩展性限制在可控范围,而不是无限的扩展性 继承的安全缺陷 一个可扩展的类,子类和父类可能会相互影响,导致不可预知的行为 涉及敏感信息的类,增加可扩展性并非优先选项,尽量避免父类或者子类的影响 设计 API 一个类,如果没有真实的可扩展需求,使用 final 修饰符 一个方法,子类如果没有重写的必要性,使用 final 修饰符 限制不可预测的可扩展性,可以实现代码的安全性和健壮性 在 JDK 17 之前,限制可扩展性的两种方法 - 使用私有类或者 final 修饰符 私有类不是公开接口,只能内部使用,而 final 修饰符彻底放弃了可扩展性 可扩展性 - 全开放 or 全封闭 从 JDK 17 开始 使用类修饰符 sealed 修饰的类是封闭类,使用类修饰符 sealed 修饰的接口是封闭接口 封闭类和封闭接口 - 限制可以扩展或实现它们的其它类或接口 把可扩展性限制在可控范围 封闭类 被扩展的父类称为封闭类,扩展而来的子类称为许可类 使用类修饰符 seale...

Java Feature - Record
概述 Record 在 JDK 16 正式发布 Record 用来表示不可变数据的透明载体 OOP 封装 + 继承 + 多态 123public interface Shape { double getArea();} 1234567891011121314151617public class Circle implements Shape { private double radius; @Override public double getArea() { return Math.PI * radius * radius; } public void setRadius(double radius) { this.radius = radius; } public double getRadius() { return radius; }} 同步方法 - 吞吐量大幅下降 1234567891011121314151617public class Ci...

Java Feature - Text Blocks
概述 Text Blocks 在 JDK 15 正式发布 Text Blocks 是一个由多行文字构成的字符串 丑陋 所见即所得 Text Blocks 是一个由多行文本构成的字符串 Text Blocks 使用新的形式来表达字符串 Text Blocks 尝试消除换行符、连接符、转义字符的影响 使文字对齐和必要的占位符更加清晰,简化多行字符串的表达 消失的特殊字符 - 换行符(\n)、连接字符(**+**)、双引号没有使用转义字符(\) Text Blocks 由零个或多个内容字符组成,从开始分隔符开始,到结束分隔符结束 开始分隔符 - """,后跟零个或者多个空格,以及行结束符组成的序列 - 必须单独成行 结束分隔符 - 只有 """ - 之前的字符,包括换行符,都属于 Text Blocks 的有效内容 Text Blocks 至少两行代码,即便只是一个空字符串,结束分隔符也不能和开始分隔符在同一行 Text Blocks 不再需要特殊字符 - 所见即所得 12345678910$ jshell> St...

Java Feature - JShell
概述 JShell 在 JDK 9 中正式发布 JShell API 和工具提供了一种在 JShell 状态下交互式评估 Java 编程语言的声明、语句和表达式的方法 JShell 的状态包括不断发展的代码和执行状态 为了快速调查和编码,语句和表达式不需要出现在方法中,变量和方法也不需要出现在类中 JShell 在验证简单问题时,比 IDE 更高效 启动 JShell 12345$ jshell| Welcome to JShell -- Version 17.0.9| For an introduction type: /help introjshell> 详细模式 - 提供更多的反馈结果,观察更多细节 12345$ jshell -v| Welcome to JShell -- Version 17.0.9| For an introduction type: /help introjshell> 退出 JShell 123456$ jshell -v| Welcome to JShell -- Version 17.0.9| For an introd...