

Observability - Concept
概述 可观测性 - 从系统向外部输出的信息来推断出系统内部状态的好坏 可观测强调的是一种度量能力 在不发布新代码(如新增诊断日志)的情况下理解系统内部状态 - 系统具有可观测性 Metrics + Logs + Tracing Metrics + Logs + Tracing 只是遥测数据类型,而 Observability 并非具体技术,而是系统属性,类似于 HA Key Desc Metrics 在一段时间内测量的数值,默认是结构化的,便于查询和存储优化 Logs 对特定时间发生的事件的文本记录,一般是非结构化字符串,会在程序执行期间被写入磁盘 Tracing 表示请求通过分布式系统的端到端的路径,执行的每个操作被称为 Span Tracing 一般会通过可视化的瀑布图展现出来 Metrics 由于 Metrics 最大的特点是聚合性 Metrics 生成的数值是反映预定义时间段内系统状态的汇总报告 - 缺乏颗粒度 Metrics 之间可能彼此不相关 Metrics 常用于 - 静态仪表盘的构建、随时间变化的趋势分析、监控维度是否保持在定义的阈值内 但都...

Java Feature - Type Matching
模式匹配 匹配谓词 + 匹配变量 Java 模式匹配是一个新型的、还在持续快速演进的领域 类型匹配是模式匹配的一个规范,在 JDK 16 正式发布 一个模式是匹配谓词和匹配变量的组合 匹配谓词用来确定模式和目标是否匹配 在模式和目标匹配的情况下,匹配变量是从匹配目标中提取出来的一个或多个变量 对类型匹配来说 匹配谓词用来指定模式的数据类型 匹配变量数属于该类型的数据变量 - 只有一个 类型转换 生产力低下 - 类型判断 + 类型转换 类型判断语句,即匹配谓词 - shape instanceof Rectangle 类型转换语句,使用类型转换运算符 - (Rectangle) shape 声明一个新的本地变量,即匹配变量,来承载类型转换后的数据 - Rectangle rectangle = 类型匹配 都在同一个语句中,只有匹配谓词和本地变量两部分 避免误用 - 编译器不会允许使用没有赋值的匹配变量 作用域 匹配变量的作用域 匹配变量的作用域,即目标变量可以被确认匹配的范围 如果在一个范围内,无法确认目标变量是否被匹配,或者目标变量不能被匹配,都不能使用匹配变...

Java Feature - Sealed
概述 封闭类在 JDK 17 正式发布 OOP 问题根源 - 无限制的扩展性 限制可扩展性 OOP 的最佳实践 - 把可扩展性限制在可控范围,而不是无限的扩展性 继承的安全缺陷 一个可扩展的类,子类和父类可能会相互影响,导致不可预知的行为 涉及敏感信息的类,增加可扩展性并非优先选项,尽量避免父类或者子类的影响 设计 API 一个类,如果没有真实的可扩展需求,使用 final 修饰符 一个方法,子类如果没有重写的必要性,使用 final 修饰符 限制不可预测的可扩展性,可以实现代码的安全性和健壮性 在 JDK 17 之前,限制可扩展性的两种方法 - 使用私有类或者 final 修饰符 私有类不是公开接口,只能内部使用,而 final 修饰符彻底放弃了可扩展性 可扩展性 - 全开放 or 全封闭 从 JDK 17 开始 使用类修饰符 sealed 修饰的类是封闭类,使用类修饰符 sealed 修饰的接口是封闭接口 封闭类和封闭接口 - 限制可以扩展或实现它们的其它类或接口 把可扩展性限制在可控范围 封闭类 被扩展的父类称为封闭类,扩展而来的子类称为许可类 使用类修饰符 seale...

Java Feature - Record
概述 Record 在 JDK 16 正式发布 Record 用来表示不可变数据的透明载体 OOP 封装 + 继承 + 多态 123public interface Shape { double getArea();} 1234567891011121314151617public class Circle implements Shape { private double radius; @Override public double getArea() { return Math.PI * radius * radius; } public void setRadius(double radius) { this.radius = radius; } public double getRadius() { return radius; }} 同步方法 - 吞吐量大幅下降 1234567891011121314151617public class Ci...

Java Feature - Text Blocks
概述 Text Blocks 在 JDK 15 正式发布 Text Blocks 是一个由多行文字构成的字符串 丑陋 所见即所得 Text Blocks 是一个由多行文本构成的字符串 Text Blocks 使用新的形式来表达字符串 Text Blocks 尝试消除换行符、连接符、转义字符的影响 使文字对齐和必要的占位符更加清晰,简化多行字符串的表达 消失的特殊字符 - 换行符(\n)、连接字符(**+**)、双引号没有使用转义字符(\) Text Blocks 由零个或多个内容字符组成,从开始分隔符开始,到结束分隔符结束 开始分隔符 - """,后跟零个或者多个空格,以及行结束符组成的序列 - 必须单独成行 结束分隔符 - 只有 """ - 之前的字符,包括换行符,都属于 Text Blocks 的有效内容 Text Blocks 至少两行代码,即便只是一个空字符串,结束分隔符也不能和开始分隔符在同一行 Text Blocks 不再需要特殊字符 - 所见即所得 12345678910$ jshell> St...

Java Feature - JShell
概述 JShell 在 JDK 9 中正式发布 JShell API 和工具提供了一种在 JShell 状态下交互式评估 Java 编程语言的声明、语句和表达式的方法 JShell 的状态包括不断发展的代码和执行状态 为了快速调查和编码,语句和表达式不需要出现在方法中,变量和方法也不需要出现在类中 JShell 在验证简单问题时,比 IDE 更高效 启动 JShell 12345$ jshell| Welcome to JShell -- Version 17.0.9| For an introduction type: /help introjshell> 详细模式 - 提供更多的反馈结果,观察更多细节 12345$ jshell -v| Welcome to JShell -- Version 17.0.9| For an introduction type: /help introjshell> 退出 JShell 123456$ jshell -v| Welcome to JShell -- Version 17.0.9| For an introd...
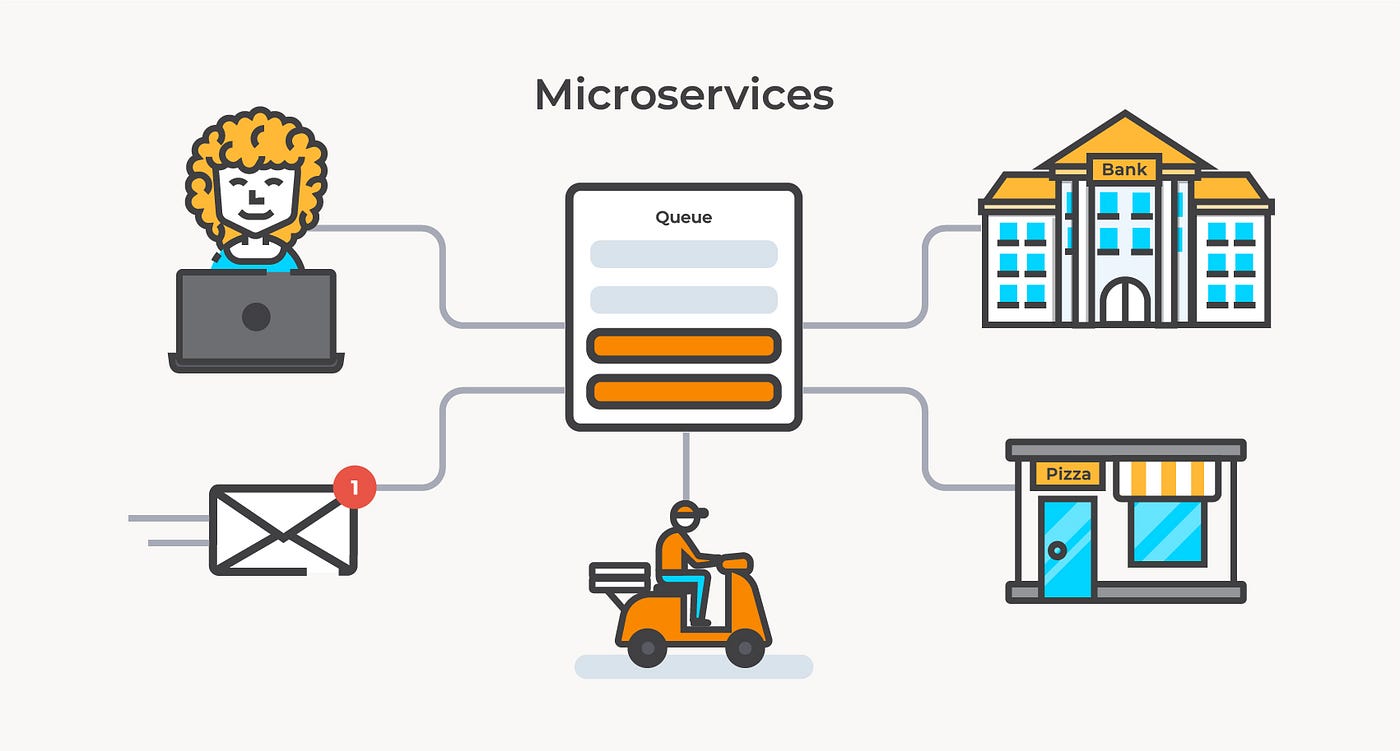
MQ - Concept
消息管道 在系统架构中,MQ 的定位是消息和管道,主要起到解耦上下游系统,数据缓存的作用,主要操作为生产和消息 架构 Broker Broker 本质上是一个进程 在实际部署过程中,通常一个物理节点只会起一个进程,在大部分情况下,Broker 表示一个节点 Topic 在大部分 MQ 中,Topic 都是用来组织分区关系的一个逻辑概念 通常情况下,一个 Topic 会包含多个分区 在 RabbitMQ 中,Topic 是指具体的一种主题模式 Partition Queue / MessageQueue 在 MQ 中,分区、分片、Partition、Queue、MessageQueue 是一个概念,用来表示数据存储的最小单位 可以将消息写入到一个分区中,也可以将消息写入到 Topic 中,再分发到具体的某个分区 一个 Topic 通常会包含一个或多个分区 Producer 消息的发送方,即发送消息的客户端 Consumer 消息的接收方,即接收消息的客户端 ConsumerGroup Subscription 一般情况下,MQ 中的 ConsumerGroup 和 ...
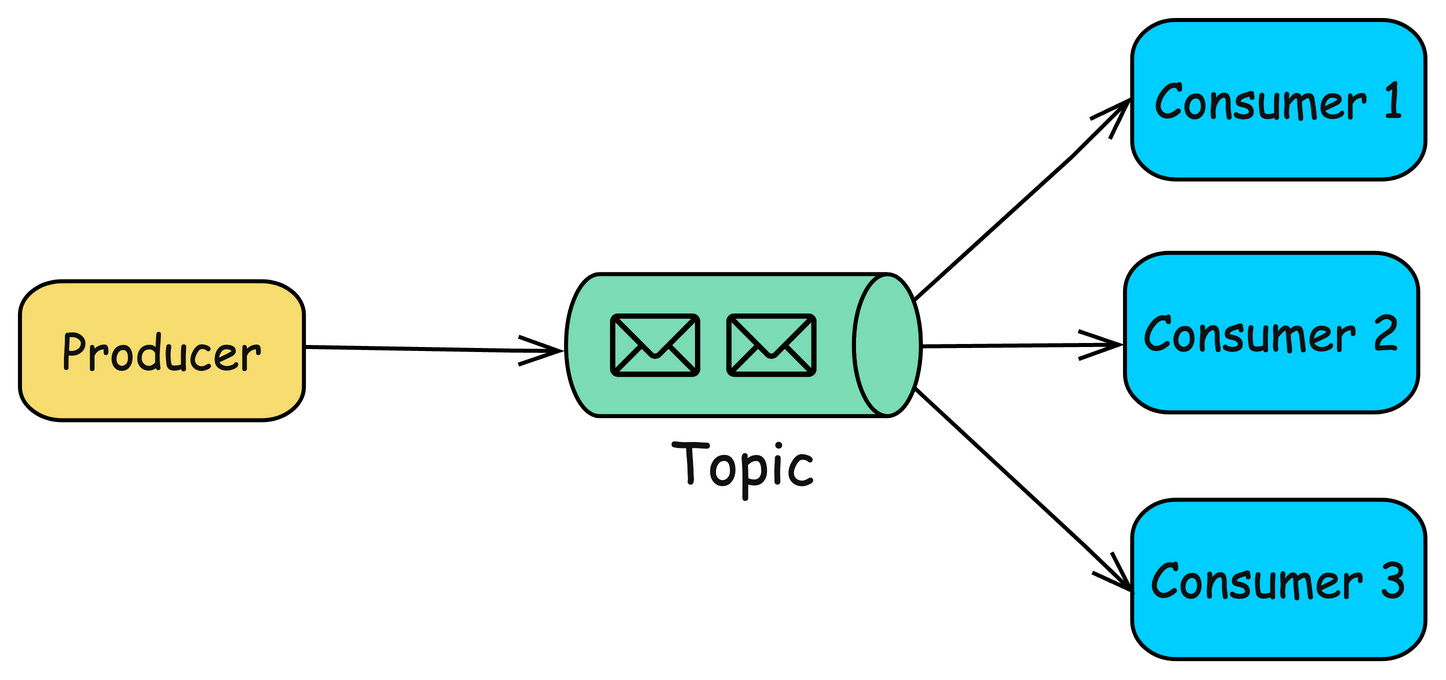
MQ - Context
MQ 消息队列 - 具有缓冲作用、具备发布和订阅能力的存储引擎 消息队列的最基本功能 - 生产 + 消费 标准消息队列 - 功能齐全 在发布订阅的基础上,高阶能力 - 死信队列、顺序消息、延时消息等 实现高吞吐、低延时、高可靠的特征 社区 Year MQ < 2000 史前消息队列 2001 JMS - ActiveMQ 2006 AMQP 2007 RabbitMQ 2011 Kafka 2013 RocketMQ 2017 Pulsar TimelineKafka Kafka 于 2011 年贡献给 ASF,主要满足大数据领域中的高吞吐量、低延迟的场景 核心功能简单,只提供生产和消费,后来加入了幂等和事务 RabbitMQ RabbitMQ 于 2007 年开源,使用 Erlang,主要满足业务中消息总线的场景 特点为功能丰富(支持延时消息、死信队列、优先级队列、事务消息等),在低流量下稳定性较高 缺点 - 在大流量的情况下,会有明显的性能瓶颈和稳定性分险 ActiveMQ 基于 JMS 协议(国内较少使用),而 RabbitMQ 基于 AMQ...
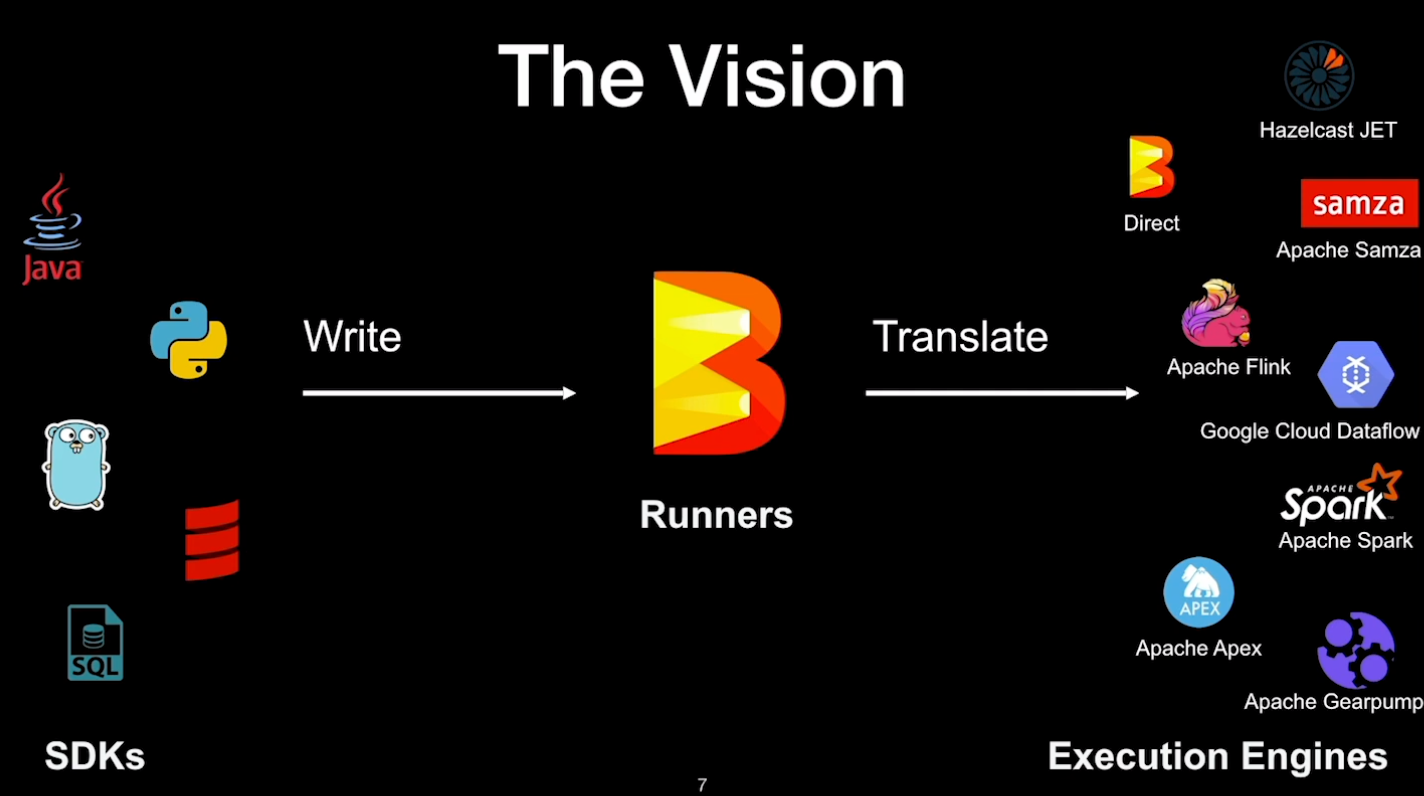
Beam - Future
技术迭代 2006,Apache Hadoop 发布,基于 MapReduce 计算模型 2009,Spark 计算框架在 加州伯克利大学诞生,于 2010 年开源,于 2014 年成为 Apache 的顶级项目 Spark 的数据处理效率远在 Hadoop 之上 2014,Flink 面世,流批一体,于 2018 年被阿里收购 Apache Beam Apache Beam 根据 Dataflow Model API 实现的,能完全胜任批流一体的任务 Apache Beam 有中间的抽象转换层,工程师无需学习新 Runner 的 API 的语法,减少学习新技术的时间成本 Runner 可以专心优化效率和迭代功能,而不必担心迁移 Beam Runner 迭代非常快 - 如 Flink
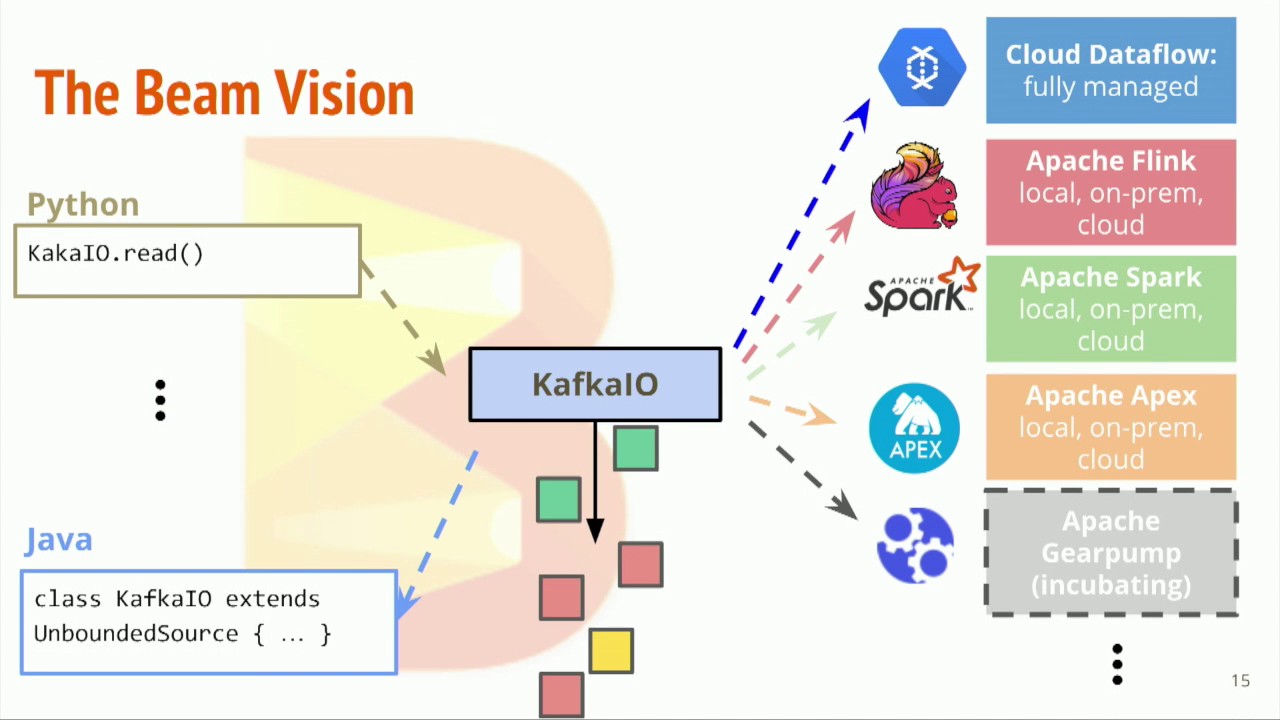
Beam - Streaming
有界数据 vs 无界数据 在 Beam 中,可以用同一个 Pipeline 处理有界数据和无界数据 无论是有界数据还是无界数据,在 Beam 中,都可以用窗口把数据按时间分割成一些有限大小的集合 对于无界数据,必须使用窗口对数据进行分割,然后对每个窗口内的数据集进行处理 读取无界数据 withLogAppendTime - 使用 Kafka 的 log append time 作为 PCollection 的时间戳 12345678Pipeline pipeline = Pipeline.create();pipeline.apply( KafkaIO.<String, String>read() .withBootstrapServers("broker_1:9092,broker_2:9092") .withTopic("shakespeare") // use withTopics(List<String>) to read from multiple topics. .wi...




