

Beam - Context
MapReduce架构思想 提供一套简洁的 API 来表达工程师数据处理的逻辑 在这套 API 底层嵌套一套扩展性很强的容错系统 计算模型 Map 计算模型从输入源中读取数据集合 这些数据经过用户所写的逻辑后生成一个临时的键值对数据集 MapReduce 计算模型会将拥有相同键的数据集集中起来发送到下一阶段,即 Shuffle 阶段 Reduce 接收从 Shuffle 阶段发送过来的数据集 在经过用户所写的逻辑后生成零个或多个结果 划时代意义 Map 和 Reduce 这两种抽象,其实可以适用于非常多的应用场景 MapReduce 的容错系统,可以让数据处理逻辑在分布式环境下有很好的扩展性(Scalability) 不足 使用 MapReduce 来解决一个工程问题,往往会涉及非常多的步骤 每次使用 MapReduce 时,都需要在分布式环境中启动机器来完成 Map 和 Reduce 步骤 并且需要启动 Master 机器来协调两个步骤的中间结果,存在不少的硬件资源开销 FlumeJava 将所有的数据都抽象成名为 PCollection 的数据结构 无论是从内存中读取的数据,...

Big Data - Spark + Flink
Spark 实时性 无论是 Spark Streaming 还是 Structured Streaming,Spark 流处理的实时性还不够 无法应对实时性要求很高的流处理场景 Spark 的流处理是基于微批处理的思想 把流处理看做批处理的一种特殊形式,没接收到一个时间间隔的数据才会去处理 虽然在 Spark 2.3 中提出连续处理模型,但只支持有限的功能,并不能在大项目中使用 要在流处理的实时性提升,就不能继续用微批处理的模式,而是有数据数据就立即处理,不做等待 Apache Flink 采用了基于操作符(Operator)的连续流模型,可以做到微秒级别的延迟 Flink模型 Flink 中最核心的数据结构是 Stream,代表一个运行在多个分区上的并行流 在 Stream 上可以进行各种转换(Transformation)操作 与 Spark RDD 不同的是,Stream 代表一个数据流而不是静态数据的集合 Stream 所包含的数据随着时间增长而变化的 而且 Stream 上的转换操作都是逐条进行的 - 每当有新数据进入,整个流程都会被执行并更新结果 Flink 比 Spark...

Spark - Structured Streaming
背景 Spark Streaming 将无边界的流数据抽象成 DStream 按特定的时间间隔,把数据流分割成一个个 RDD 进行批处理 DStream API 与 RDD API 高度相似,拥有 RDD 的各种性质 DataSet/DataFrame DataSet/DataFrame 是高级 API,提供类似于 SQL 的查询接口,方便熟悉关系型数据库的开发人员使用 Spark SQL 执行引擎会自动优化 DataSet/DataFrame 程序 用 RDD API 开发的程序本质上需要开发人员手工构造 RDD 的 DAG 执行图,依赖于手工优化 如果拥有 DataSet/DataFrame API 的流处理模块 无需去用相对底层的 DStream API 去处理无边界数据,大大提升开发效率 在 2016 年,Spark 2.0 中推出结构化流处理的模块 - Structured Streaming Structured Streaming 基于 Spark SQL 引擎实现 在开发视角,流数据和静态数据没有区别,可以像批处理静态数据那样处理流...

Spark - Streaming
流处理 Spark SQL 中的 DataFrame API 和 DataSet API 都是基于批处理模式对静态数据进行处理 在 2013,Spark 的流处理组件 Spark Streaming 发布,现在的 Spark Streaming 已经非常成熟,应用非常广泛 原理 Spark Streaming 的原理与微积分的思想很类似 微分是无限细分,而积分是对无限细分的每一段进行求和 本质 - 将一个连续的问题转换成了无限个离散的问题 流处理的数据是一系列连续不断变化,且无边界的,永远无法预测下一秒的数据 Spark Streaming 用时间片拆分了无限的数据流 然后对每个数据片用类似于批处理的方法进行处理,输出的数据也是分块的 Spark Streaming 提供一个对于流数据的抽象 DStream DStream 可以由 Kafka、Flume 或者 HDFS 的流数据生成,也可以由别的 DStream 经过各种转换操作得到 底层 DStream 由多个序列化的 RDD 构成,按时间片(如一秒)切分成的每个数据单位都是一个 RDD Spark 核心引擎将对 DStream ...

Spark - SQL
历史Hive 一开始,Hadoop/MapReduce 在企业生产中大量使用,在 HDFS 上积累了大量数据 MapReduce 对于开发者而言使用难度较大,大部分开发人员最熟悉的还是传统的关系型数据库 为了方便大多数开发人员使用 Hadoop,诞生了 Hive Hive 提供类似 SQL 的编程接口,HQL 经过语法解析、逻辑计划、物理计划转化成 MapReduce 程序执行 使得开发人员很容易对 HDFS 上存储的数据进行查询和分析 Shark 在 Spark 刚问世时,Spark 团队开发了 Shark 来支持用 SQL 来查询 Spark 的数据 Shark 的本质是 Hive,Shark 修改了 Hive 的内存管理模块,大幅优化了运行速度 Shark 依赖于 Hive,严重影响了 Spark 的发展,Spark 要定义一个统一的技术栈和完整的生态 依赖于 Hive 还会制约 Spark 各个组件的相互集成,Spark 无法利用 Spark 的特性进行深度优化 2014 年 7 月 1 日,Spark 团队将 Shark 交给 Hive 进行管理,即 Hive on Spa...
Spark - RDD
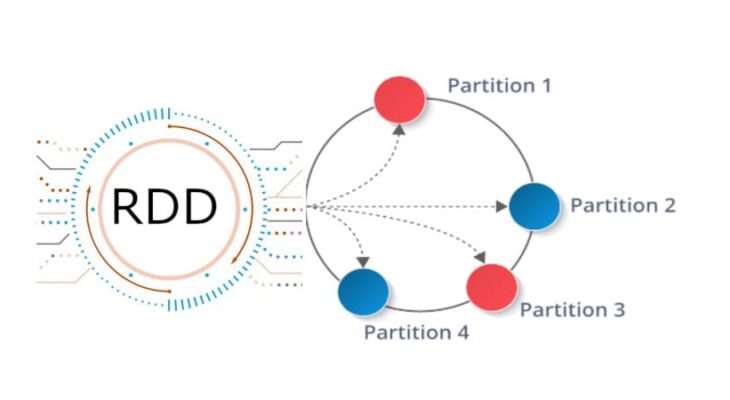
分布式内存 传统的 MapReduce 框架运行缓慢,主要原因是 DAG 的中间计算结果需要写入硬盘来防止运行结果丢失 每次调用中间计算结果都需要进行一次硬盘的读取 反复对硬盘进行读写操作以及潜在的数据复制和序列化操作会大大地提高了计算延迟 新的分布式存储方案 - 保持之前系统的稳定性、错误恢复和可扩展性,并尽可能地减少硬盘 IO 操作 RDD 是基于分布式内存的数据抽象,不仅支持基于工作集的应用,同时具有数据流模型的特点 定义分区 分区代表同一个 RDD 包含的数据被存储在系统的不同节点上,这是可以被并行处理的前提 在逻辑上,可以认为 RDD 是一个大数组,数组中的每个元素代表一个分区(Partition) 在物理存储中,每个分区指向一个存放在内存或者硬盘中的数据块(Block) Block 是独立的,可以被存放在分布式系统中的不同节点 RDD 只是抽象意义的数据集合,分区内部并不会存储具体的数据 RDD 中的每个分区都有它在该 RDD 中的 Index 通过 RDD_ID 和 Partition_Index 可以唯一确定对应 Block 的编号 从而通过底层存储层的接口中提取...
Spark - Overview
MapReduce概述 MapReduce 通过简单的 Map 和 Reduce 的抽象提供了一个编程模型 可以在一个由上百台机器组成的集群上并发处理大量的数据集,而把计算细节隐藏起来 各种各样的复杂数据处理都可以分解为 Map 和 Reduce 的基本元素 复杂的数据处理可以分解成由多个 Job(包含一个 Mapper 和一个 Reducer)组成的 DAG 然后,将每个 Mapper 和 Reducer 放到 Hadoop 集群上执行,得到最终结果 不足 高昂的维护成本 时间性能不达标 MapReduce 模型的抽象层次低 大量的底层逻辑需要开发者手工完成 - 用汇编语言开发游戏 只提供 Map 和 Reduce 操作 很多现实的数据处理场景并不适合用这个模型来描述 实现复杂的操作需要技巧,让整个工程变得庞大且难以维护 维护一个多任务协调的状态机成本很高,且扩展性很差 在 Hadoop 中,每个 Job 的计算结果都会存储在 HDFS 文件存储系统中 每一步计算都要进行硬盘的读取和写入,大大增加了系统的延迟 MapReduce 对于迭代算法的处理性能很差,而且非常耗资源 因...
Big Data - Kappa
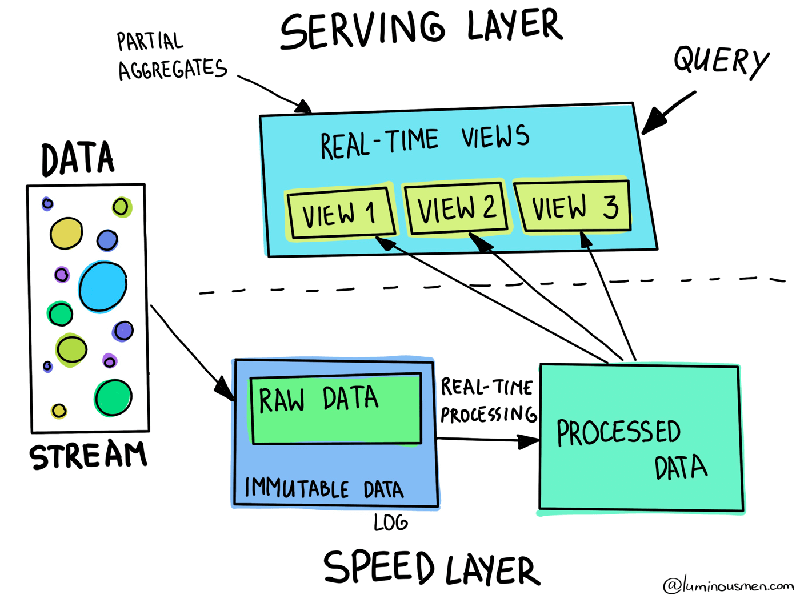
Lambda概述 Lambda 架构结合了批处理和流处理的架构思想 将进入系统的大规模数据同时送入两套架构层中,即 Batch Layer 和 Speed Layer 同时产生两套数据结果并存入 Serving Layer 中 优点 Batch Layer 有很好的容错性,同时由于保存着所有的历史记录,使得产生的数据具有很好的准确性 Speed Layer 可以及时处理流入的数据,具有低延迟性 最终 Serving Layer 将两套数据结合,并生成一个完整的数据视图提供给用户 Lambda 架构也具有很好的灵活性,可以将不同开源组件嵌入到该架构中 不足 使用 Lambda 架构,需要维护两个复杂的分布式系统,并保证它们逻辑上产生相同的结果输出到 Serving Layer 在分布式框架中进行编程是非常复杂的,尤其需要对不同的框架进行专门的优化 – 高昂的维护成本 维护 Lambda 架构的复杂性 – 同时维护两套系统架构 方向 - 改进其中一层的架构,让其具有另一层架构的特性 Kappa架构 Apache Kafka 具有永久保存数据日志的功能,基于该特性,可以让 Speed Laye...
Big Data - Lambda
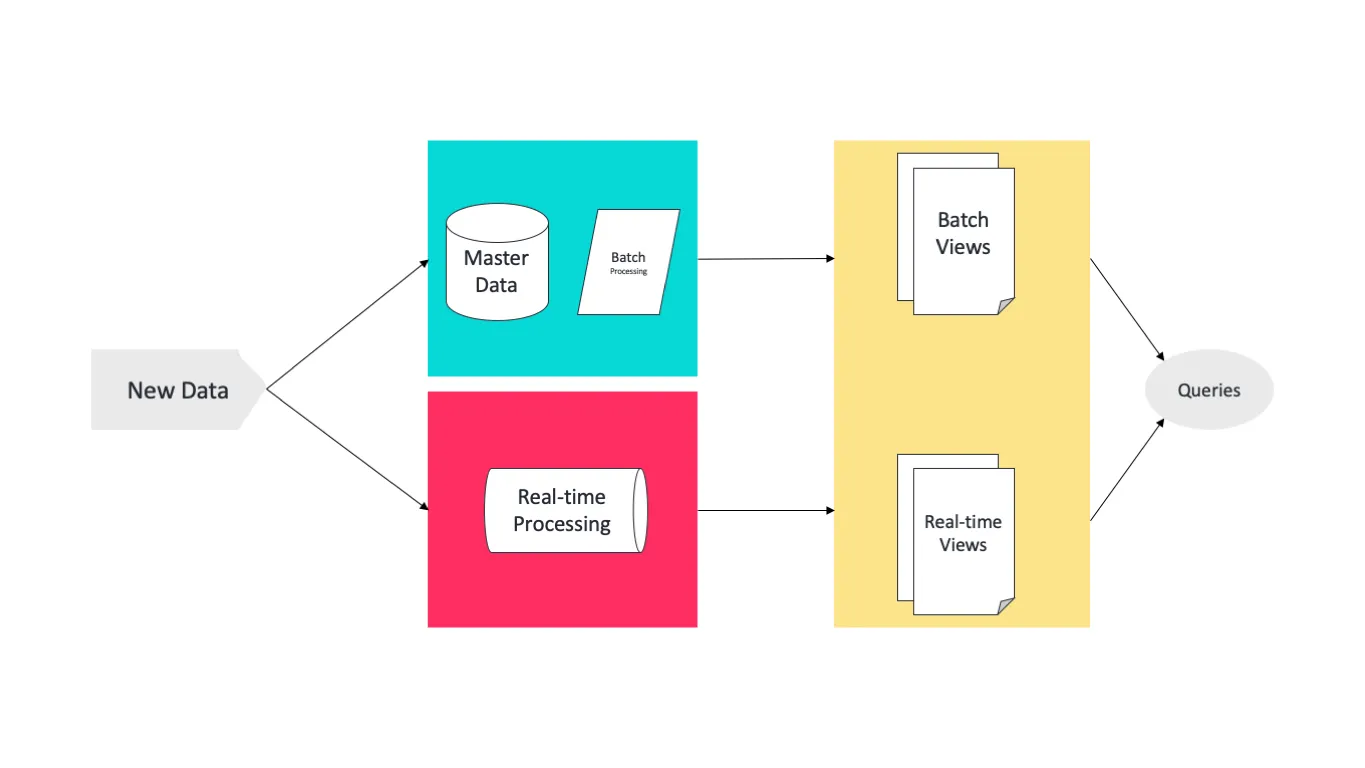
Architecture Batch Layer Batch Layer 存储管理主数据集(不可变数据集)和预先批处理好计算好的视图 Batch Layer 使用可处理大量数据的分布式处理系统预先计算结果 通过处理所有的已有历史数据来实现数据的准确性 基于完整的数据集来重新计算,能够修复任何错误,然后更新现有的数据视图 输出通常存储在只读数据库中,更新则完全取代现有的预先计算好的视图 Speed Layer Speed Layer 会实时处理新来的大数据 Speed Layer 通过提供最新数据的实时视图来最小化延迟 Speed Layer 生成的数据视图可能不如 Batch Layer 最终生成的视图那么准确和完整 在收到数据后立即可用,而当同样的数据被 Batch Layer 处理完成后,在 Speed Layer 的数据可以被替换掉 本质上,Speed Layer 弥补了 Batch Layer 所导致的数据视图滞后 Serving Layer 所有在 Batch Layer 和 Speed Layer 处理完的结果都输出存储在 Serving Layer 中 Serving La...
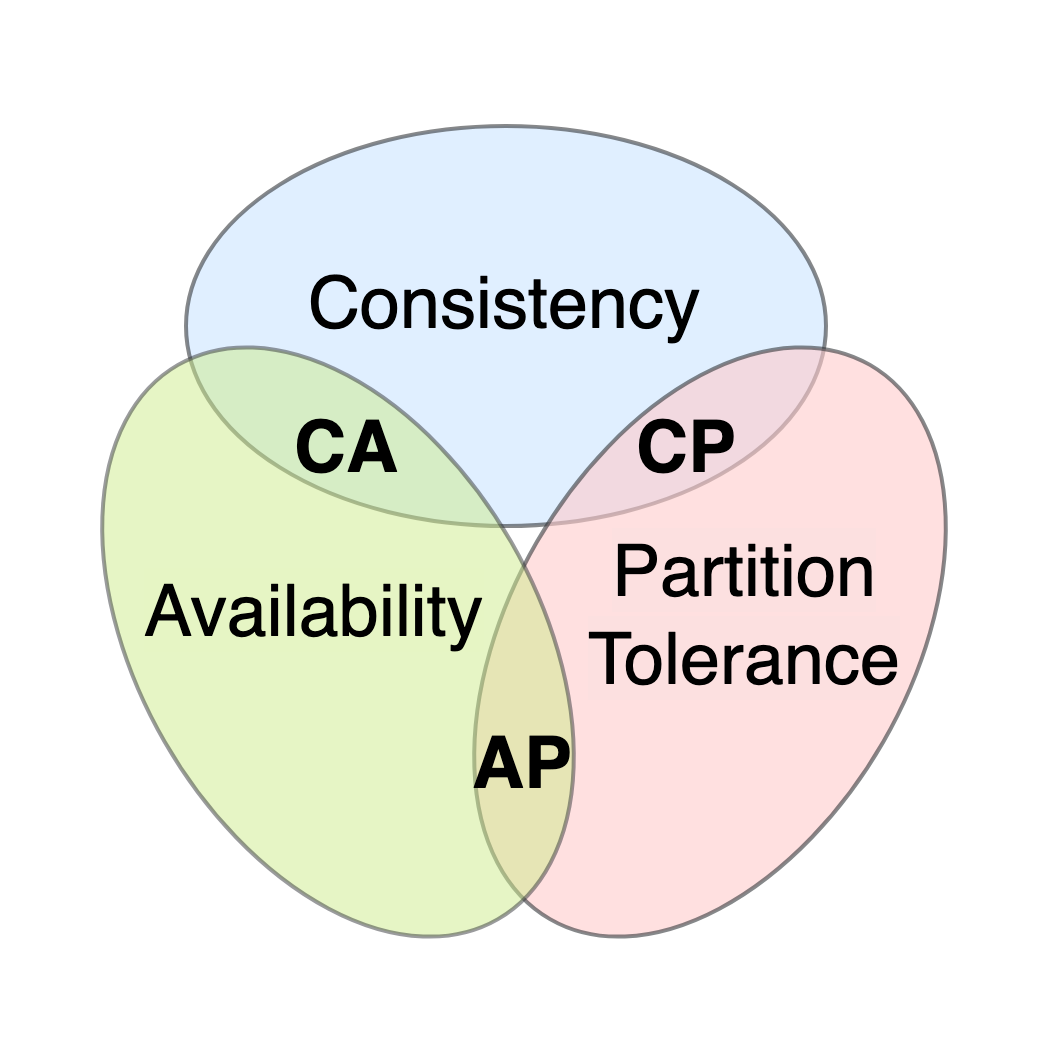
Big Data - CAP
CAP 在任意的分布式系统中,最多只能同时满足两个:Consistency、Availability、Partition-tolerance Consistency Consistency 指的是 Linearizability Consistency 在 Linearizability Consistency 的保证下,所有分布式环境下的操作都像在单机上一样 所有节点的状态一直是一致的 Availability 在分布式系统中,任意非故障的节点都必须对客户的请求产生响应 当系统满足 Availability 时,除非所有节点全部崩溃,不然都能返回消息 - Netflix Eureka Partition Tolerance 在一个分布式系统中,如果出现了一些故障,可能会使得部分节点之间无法连通 由于故障节点无法连通,造成整个网络会被分成几块区域 从而使数据分散在这些无法连通的区域中的情况,从而发生了分区错误 如上图,如果需要的数据只在 Sever A 中,当出现分区错误时,无法获取到数据 如果能分区容错,既即便出现这种情况,分布式系统也能容忍,并能返回消息 Partition...




