Python - Compare + Copy
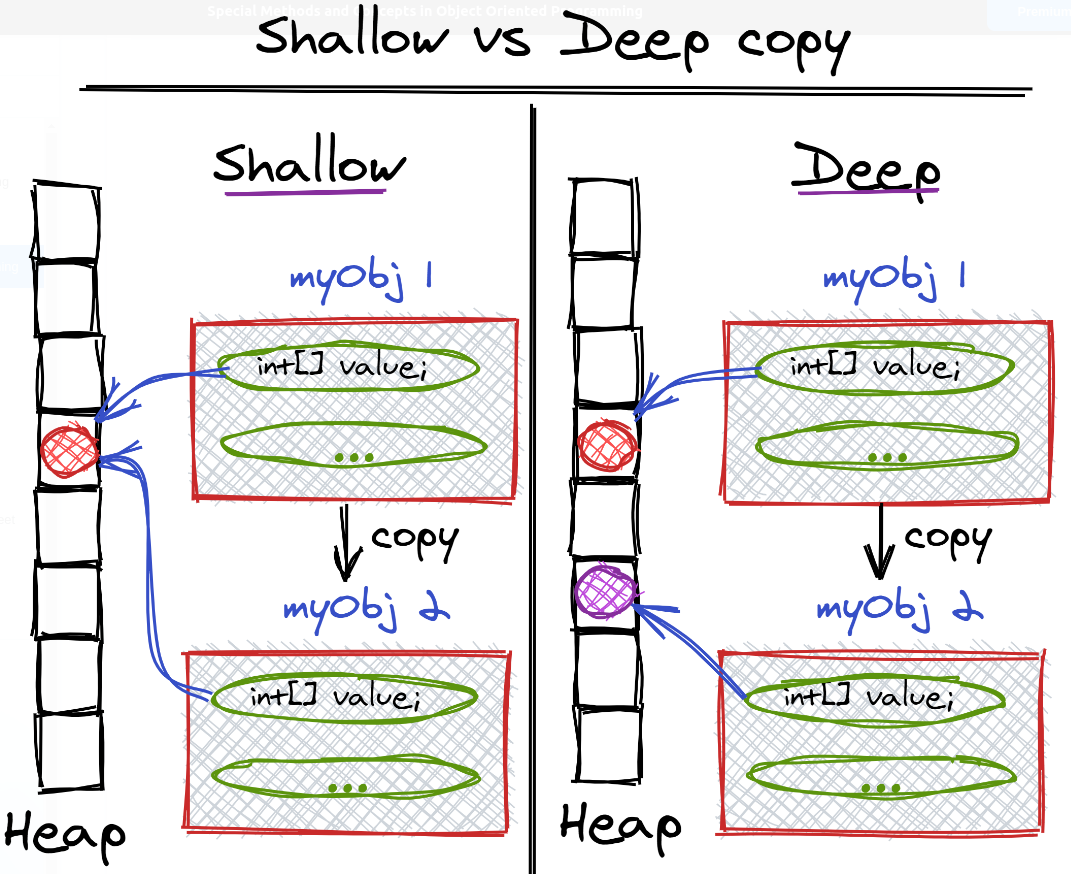
== vs is == 比较对象之间的值是否相等,类似于 Java 中的 equals is 比较的是对象的身份标识是否相等,即是否为同一个对象,是否指向同一个内存地址,类似于 Java 中的 == is None or is not None 在 Python 中,每个对象的身份标识,都能通过 id(object) 函数获得,is 比较的是对象之间的 ID 是否相等 类似于 Java 对象的 HashCode 在实际工作中,**== 更常用,一般关心的是两个变量的值,而非内部存储地址** 12345678a = 10 # allocate memory for 10b = 10 # point to the same memory location as aprint(a == b) # Trueprint(id(a)) # 4376158344print(id(b)) # 4376158344print(a is b) # True a is b 为 True,仅适用于 -5 ~ 256 范...

Python - Module
简单模块化 把函数、类、常量拆分到不同的文件,但放置在同一个文件夹中 使用 from your_file import function_name, class_name 的方式进行调用 12345678910111213141516$ tree.├── main.py└── utils.py$ cat utils.pydef get_sum(a, b): return a + b $ cat main.pyfrom utils import get_sumprint(get_sum(1, 2)) # 3$ python main.py3 项目模块化 相对的绝对路径 - 从项目的根目录开始追溯 所有的模块调用,都要通过项目根目录来 import 12345678910111213141516$ tree.├── proto│ └── mat.py├── src│ └── main.py└── utils └── mat_mul.py$ cd src/$ python main.pyTraceback (most recent call last): File &...

Python - OOP
命令式 Python 的命令式语言是图灵完备的 - 即理论上可以做到其它任何语言能够做到的所有事情 仅依靠汇编语言的 MOV 指令,就能实现图灵完备编程 传统的命令式语言有着无数重复性代码,虽然函数的诞生减缓了许多重复性 但只有函数是不够的,需要把更加抽象的概念引入计算机才能缓解 – OOP 基本概念12345678910111213141516171819202122232425class Document(): def __init__(self, title, author, context): print('init function called') self.title = title self.author = author self.__context = context # __context is private def get_context_length(self): return len(self.__context) def intercept_cont...
Python - Lambda
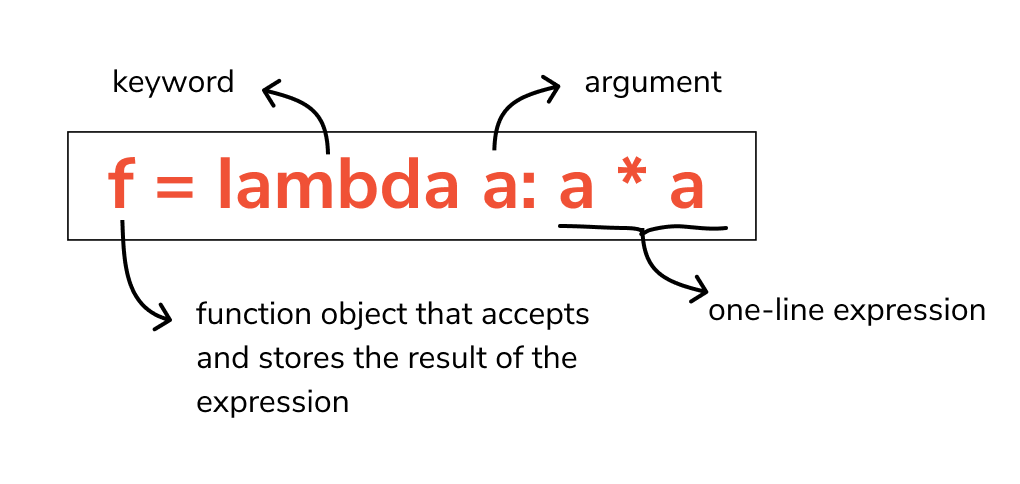
基础 匿名函数的关键字为 lambda 1lambda argument1, argument2,... argumentN : expression 1234square = lambda x: x ** 2print(type(square)) # <class 'function'>print(square(5)) # 25 lambda 是一个表达式(expression),而非一个语句(statement) 表达式 - 用一系列公式去表达 语句 - 完成某些功能 lambda 可以用在列表内部,而常规函数 def 不能 lambda 可以用作函数参数,而常规函数 def 不能 常规函数 def 必须通过其函数名被调用,因此必须首先被定义 lambda 是一个表达式,返回的函数对象不需要名字,即匿名函数 lambda 的主体只有一行的简单表达式,并不能扩展成多行的代码块 lambda 专注于简单任务,而常规函数 def 负责更复杂的多行逻辑 12y = [(lambda x: x * x)(x) for x in range(10)]...

Python - Function
基础 函数为实现了某一功能的代码片段,可以重复利用函数可以返回调用结果(return or yield),也可以不返回 123def name(param1, param2, ..., paramN): statements return/yield value # optional 与编译型语言不同,def 是可执行语句,即函数直到被调用前,都是不存在的 当调用函数时,def 语句才会创建一个新的函数对象,并赋予其名字 在主程序调用函数时,必须保证这个函数已经定义过,否则会报错 12345my_func('hello world') # NameError: name 'my_func' is not defineddef my_func(message): print('Got a message: {}'.format(message)) 在函数内部调用其它函数,则没有定义顺序的限制def 是可执行语句 - 函数在调用之前都不存在,只需保证调用时,所需的函数都已经声明定义即可 ...
Python - Exception
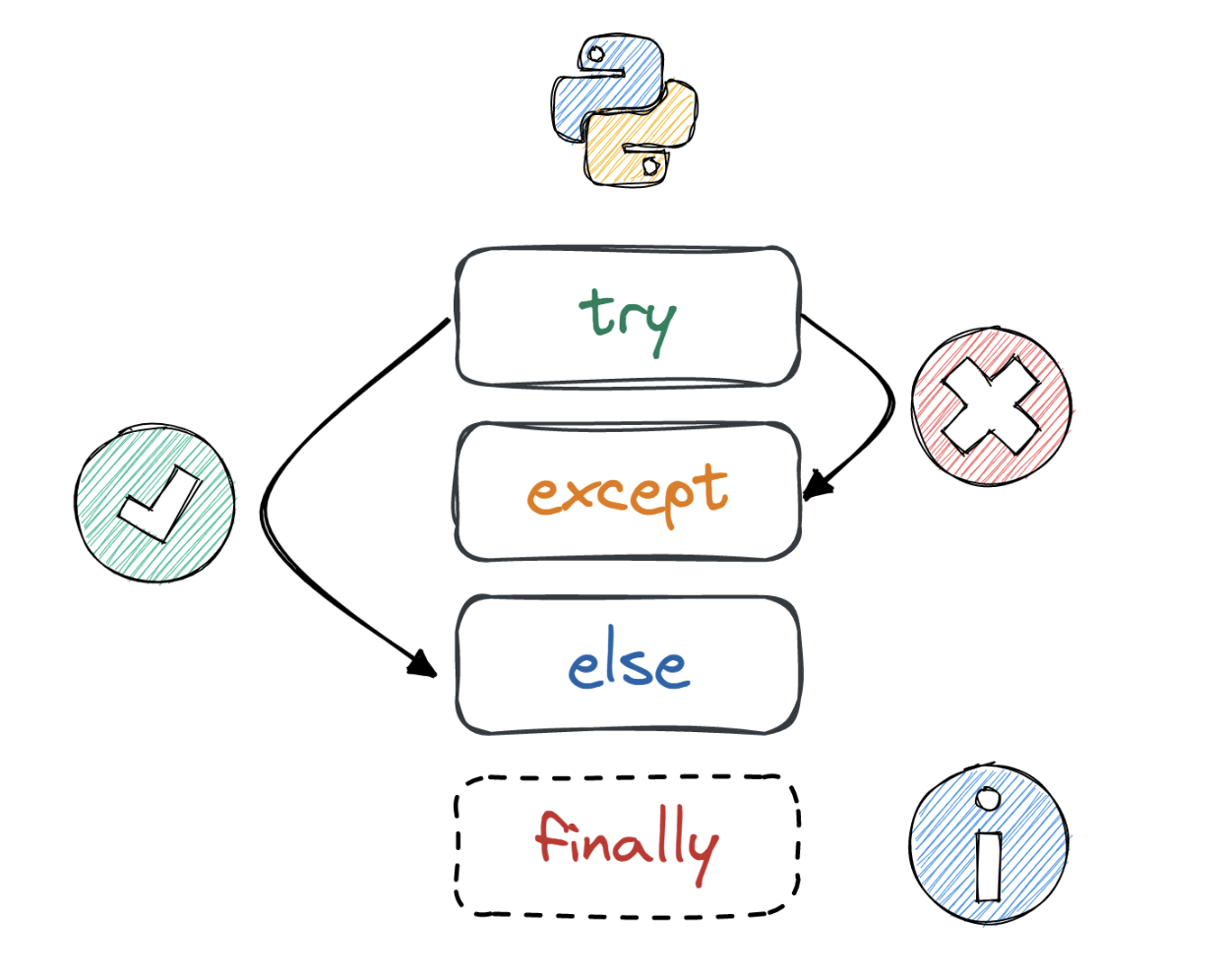
错误 vs 异常 语法错误,无法被识别与执行 123name = 'x'if name is not None # SyntaxError: invalid syntax print(name) 异常 - 语法正确,可以被执行,但在执行过程中遇到错误,抛出异常,并终止程序 123# 10 / 0 # ZeroDivisionError: division by zero# order * 2 # NameError: name 'order' is not defined# 1 + [1, 2] # TypeError: unsupported operand type(s) for +: 'int' and 'list' 处理异常 try-exceptexcept block 只接受与它相匹配的异常类型并执行 123456try: s = input('please enter two numbers separated by comma: ') num1 = ...

Python - Condition + Loop
条件 不能在条件语句中加括号,必须在条件末尾加上 : 12345678x = int(input("Enter a number: "))if x < 0: y = -xelse: y = xprint(f"The absolute value of {x} is {y}.") Python 不支持 switch 语句 - elif - 顺序执行 12345678x = int(input("Enter a number: "))if x == 0: print('red')elif x == 1: print('yellow')else: print('green') 省略用法 - 除了 Boolean 类型的数据,判断条件最好是显性的 循环 for + while 123l = [1, 2, 3, 4]for e in l: print(e) 只要数据结构是 Iterable...

Python - IO
基础1234567891011name = input('your name:')gender = input('you are a boy? (y/n)')welcome_str = 'Welcome to the matrix {prefix} {name}.'welcome_dic = { 'prefix': 'Mr.' if gender == 'y' else 'Mrs.', 'name': name}print('authorizing...')print(welcome_str.format(**welcome_dic)) input() 函数暂停程序运行,等待键盘输入,直到回车被按下 函数的参数为提示语,输入的类型永远都是字符串(string) print() 函数则接受字符串、数字、字典、列表和自定义类 input() 的...
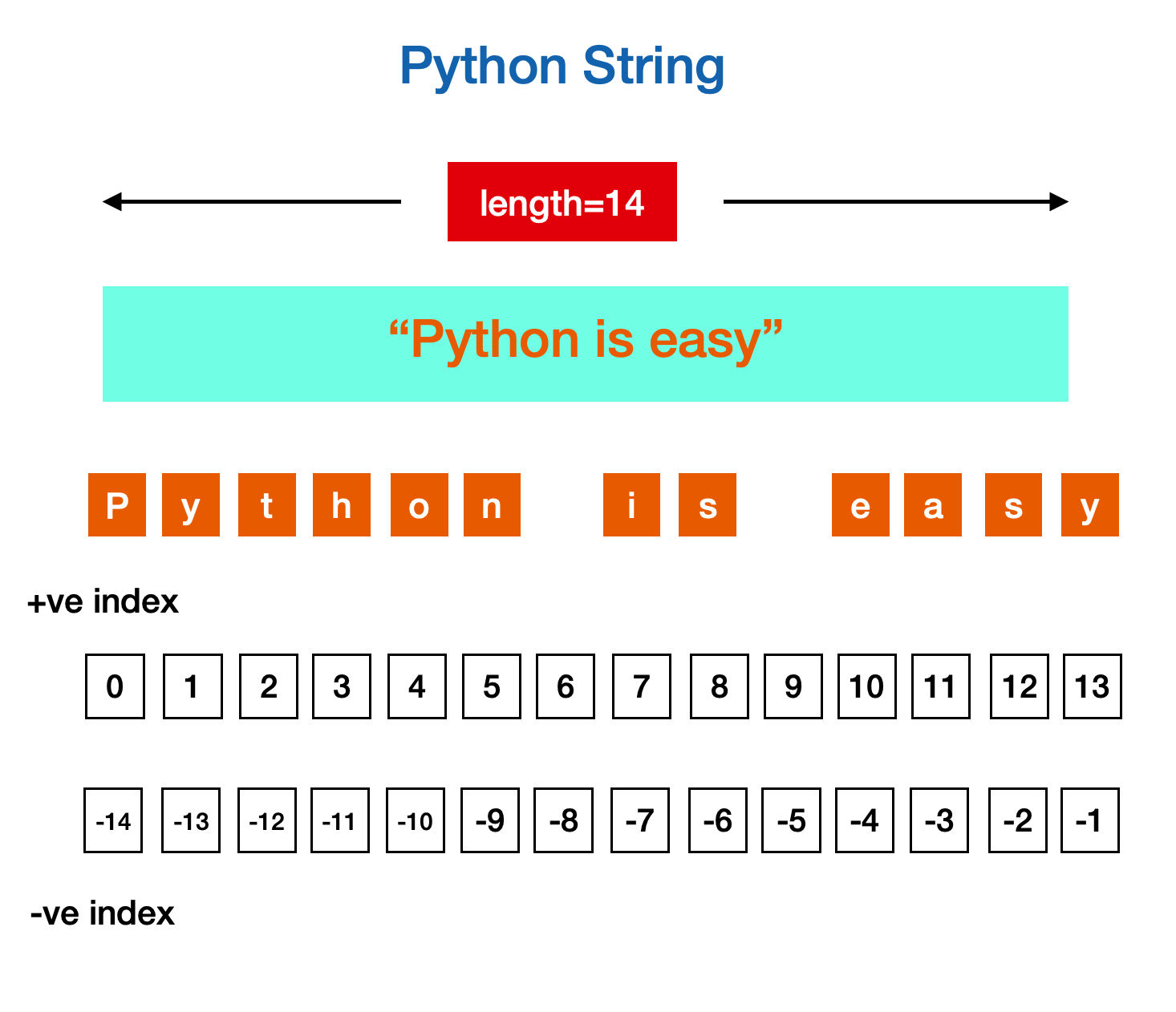
Python - String
基础 字符串是由独立字符组成的一个序列,通常包含在 '...'、"..."、"""...""" 中 123name = 'jason'city = "guangzhou"desc = """I'm a software engineer""" 1234s1 = 'rust's2 = "rust"s3 = """rust"""print(s1 == s2 == s3) # True 便于在字符串中,内嵌带引号的字符串 12s = "I'm a string"print(s) # I'm a string """...""" 常用于多行字符串,如函数注释 Python 支持转义字...
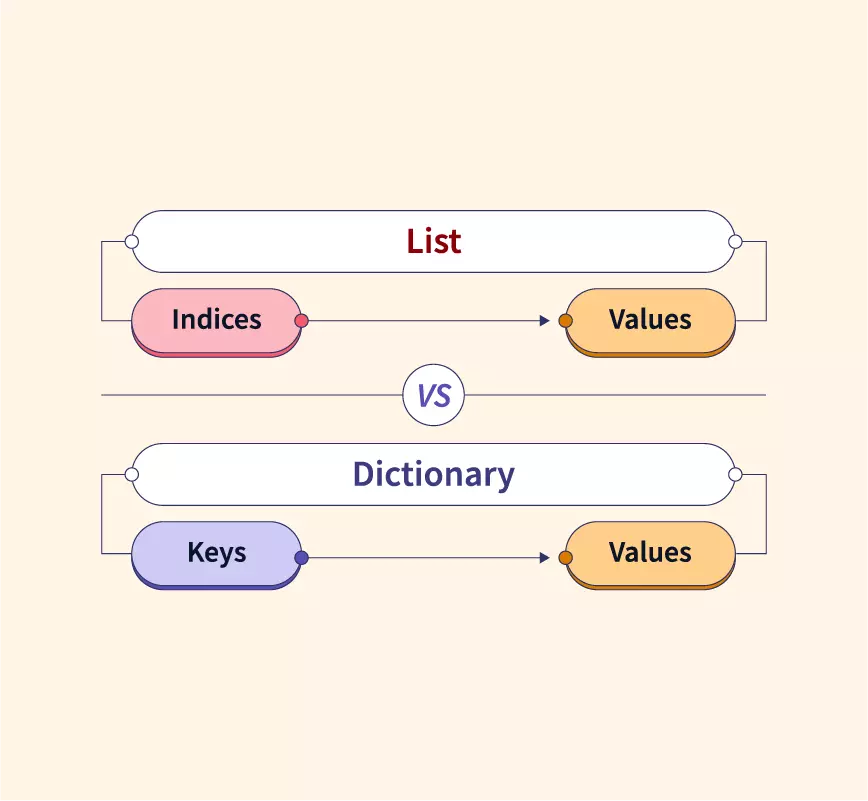
Python - Dict + Set
基础 字典是由 kv 对组成的元素的集合,在 Python 3.7+,字典被确定为有序 相比于列表和元组,字典的性能更优,对于查找、添加和删除操作,时间复杂度为 O(1) 集合是一系列唯一无序的元素组合 字典和集合,无论是 Key 还是 Value,都可以是混合类型 字典初始化 123456789d1 = {'name': 'jason', 'age': 20, 'gender': 'male'}d2 = dict({'name': 'jason', 'age': 20, 'gender': 'male'})d3 = dict([('name', 'jason'), ('age', 20), ('gender', 'male')])d4 = dict(name...