
JVM进阶 -- 浅谈即时编译
概念
- 即时编译是用来提升应用运行效率的技术
- 代码会先在JVM上解释执行,之后反复执行的热点代码会被即时翻译成为机器码,直接运行在底层硬件上
分层编译
- HotSpot包含多个即时编译器:C1、C2和Graal(Java 10,实验性)
- 在Java 7之前,需要根据程序的特性选择对应的即时编译器
- 对于执行时间较短或对启动性能有要求的程序,采用编译效率较快的C1,对应参数:
-client - 对于执行时间较长或对峰值性能有要求的程序,采用生成代码执行效率较快的C2,对应参数:
-server
- 对于执行时间较短或对启动性能有要求的程序,采用编译效率较快的C1,对应参数:
- Java 7引入了分层编译(-XX:+TieredCompilation),综合了C1的启动性能优势和C2的峰值性能优势
- 分层编译将JVM的执行状态分了5个层次
- 0:解释执行(也会profiling)
- 1:执行不带profiling的C1代码
- 2:执行仅带方法调用次数和循环回边执行次数profiling的C1代码
- 3:执行带所有profiling的C1代码
- 4:执行C2代码
- 通常情况下,C2代码的执行效率比C1代码高出30%以上
- 对于C1代码的三种状态,按执行效率从高至低:1层 > 2层 > 3层
- 1层的性能略高于2层,2层的性能比3层高出30%
- profiling越多,额外的性能开销越大
- profiling:在程序执行过程中,收集能够反映程序执行状态的数据
- profile:收集的数据
- JDK附带的hprof(CPU+Heap)
- JVM内置profiling
- Java 8默认开启了分层编译,无论开启还是关闭分层编译,原本的
-client和-client都是无效的- 如果关闭分层编译,JVM将直接采用C2
- 如果只想用C1,在打开分层编译的同时,使用参数:-XX:TieredStopAtLevel=1
编译路径
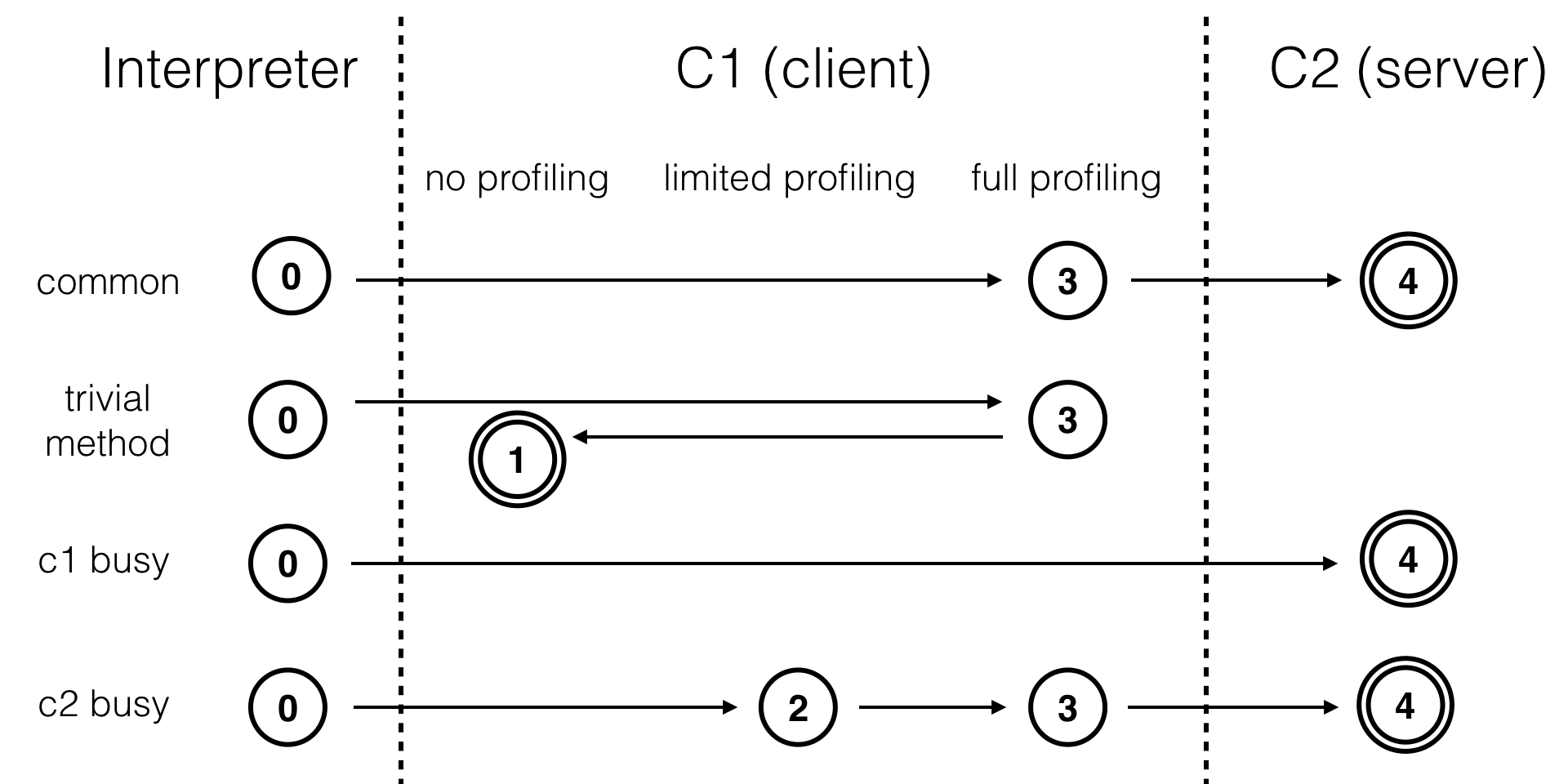
- 1层和4层是终止状态
- 当一个方法被终止状态编译后,如果编译后的代码没有失效,那么JVM不会再次发出该方法的编译请求
- 通常情况下,热点方法会被3层的C1编译,然后再被4层的C2编译
- 如果方法的字节码数目较少(如getter/setter),并且3层的profiling没有可收集的数据
- JVM会断定该方法对于C1和C2的执行效率相同
- JVM会在3层的C1编译后,直接选用1层的C1编译
- 由于1层是终止状态,JVM不会继续用4层的C2编译
- 在C1忙碌的情况下,JVM在解释执行过程中对程序进行profiling,而后直接由4层的C2编译
- 在C2忙碌的情况下,方法会被2层的C1编译,然后再被3层的C1编译,以减少方法在3层的执行时间
触发JIT的条件
- JVM是依据方法的调用次数以及循环回边的执行次数来触发JIT的
- JVM将在0层、2层和3层执行状态时进行profiling,其中包括方法的调用次数和循环回边的执行次数
- 循环回边是一个控制流程图中的概念,在字节码中,可以简单理解为往回跳的指令
- 在即时编译过程中,JVM会识别循环的头部和尾部,循环尾部到循环头部的控制流就是真正意义上的循环回边
- C1将在循环回边插入循环回边计数器的代码
- 解释执行和C1代码中增加循环回边计数的位置并不相同,但这不会对程序造成影响
- JVM不会对这些计数器进行同步操作,因此收集到的执行次数也不是精确值
- 只要该数值足够大,就能表示对应的方法包含热点代码
- 在不启动分层编译时,当方法的调用次数和循环回边的次数的和超过-XX:CompileThreshold,便会触发JIT
- 使用C1时,该值为1500
- 使用C2时,该值为10000
- 当启用分层编译时,阈值大小是动态调整的
- 阈值 * 系数
系数
1 | 系数的计算方法: |
编译线程数
- 在64位JVM中,默认情况下,编译线程的总数目是根据处理器数量来调整的
- -XX:+CICompilerCountPerCPU=true,编译线程数依赖于处理器数量
- -XX:+CICompilerCountPerCPU=false -XX:+CICompilerCount=N,强制设定总编译线程数
- JVM会将这些编译线程按照1:2的比例分配给C1和C2(至少1个),对于4核CPU,总编译线程数为3
1 | // -XX:+CICompilerCountPerCPU=true |
触发条件
当启用分层编译时,触发JIT的条件
1 | i > TierXInvocationThreshold * s || (i > TierXMinInvocationThreshold * s && i + b > TierXCompileThreshold * s) |
Profiling
- 在分层编译中的0层、2层和3层,都会进行profiling,最为基础的是方法的调用次数以及循环回边的执行次数
- 主要拥有触发JIT
- 此外,0层和3层还会收集用于4层C2编译的数据,例如
- branch profiling
- 分支跳转字节码,包括跳转次数和不跳转次数
- type profiling
- 非私有实例方法调用指令:invokevirtual
- 强制类型转换指令:checkcast
- 类型测试指令:instanceof
- 引用类型数组存储指令:aastore
- branch profiling
- branch profiling和type profiling将给应用带来不少的性能开销
- 3层C1的性能比2层C1的性能低30%
- 通常情况下,我们不会在解析执行过程中进行branch profiling和type profiling
- 只有在方法触发C1编译后,JVM认为该方法有可能被C2编译,才会在该方法的C1代码中收集这些profile
- 只有在极端情况下(如等待C1编译的方法数目太多),才会开始在解释执行过程中收集这些profile
- C2可以根据收集得到的数据进行猜测和假设,从而作出比较激进的优化
branch profiling
Java代码
1 | public static int foo(boolean f, int in) { |
字节码
1 | public static int foo(boolean, int); |
优化过程
正常分支
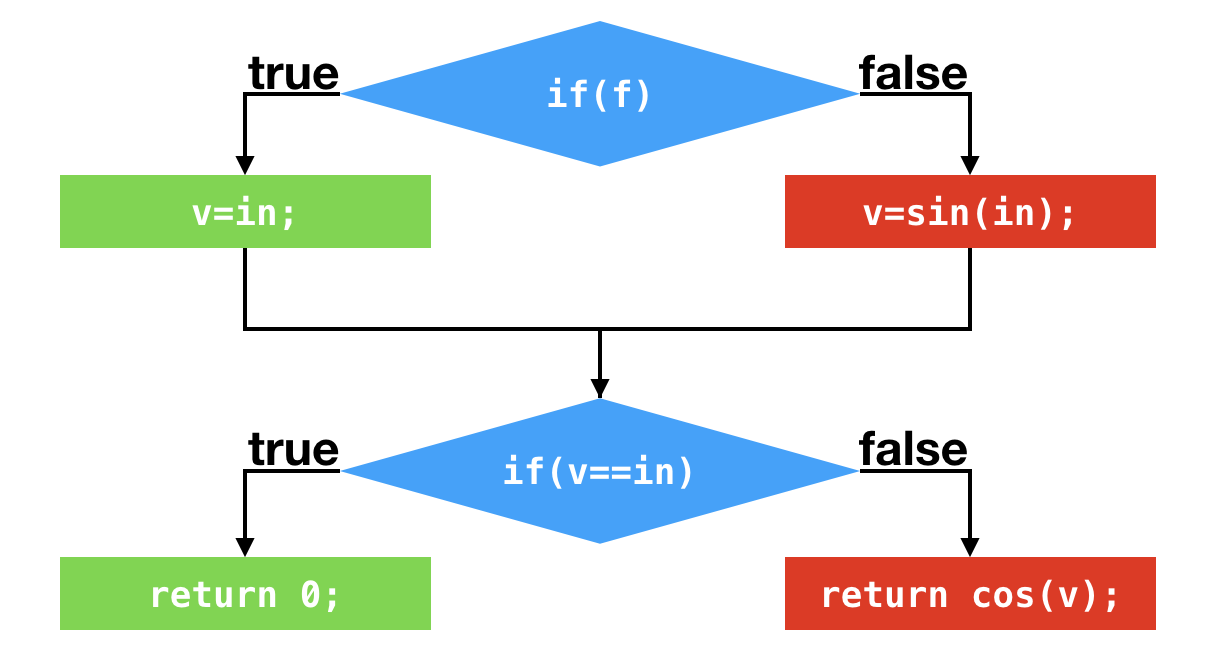
profiling
假设应用程序调用该方法,所传入的都是true,那么偏移量为1和偏移量为18的条件跳转指令所对应的分支profile中,其跳转的次数都是0。实际执行的分支如下:
剪枝
C2根据这两个分支profile作出假设,在后续的执行过程中,这两个条件跳转指令仍旧不会执行,基于这个假设,C2不会在编译这两个条件跳转语句所对应的false分支(剪枝)。最终的结果是在第一个条件跳转之后,C2代码直接返回0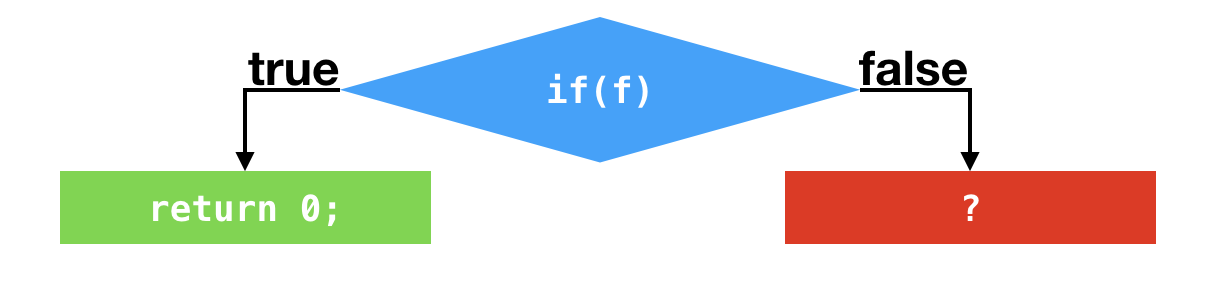
小结
- 根据条件跳转指令的分支profile,即时编译器可以将从未执行过的分支减掉
- 避免编译这些不会用到的代码
- 节省编译时间以及部署代码所要消耗的内存空间
- 剪枝同时也能精简数据流,从而触发更多的优化
- 现实中,分支profile出现仅跳转或者不跳转的情况并不常见
- 即时编译器对分支profile的利用也不仅仅限于剪枝
- 还可以依据分支profile,计算每一条执行路径的概率
- 以便于某些编译器优化优先处理概率较高的路径
type profiling
Java代码
1 | public static int hash(Object in) { |
字节码
1 | public static int hash(java.lang.Object); |
优化过程
正常分支
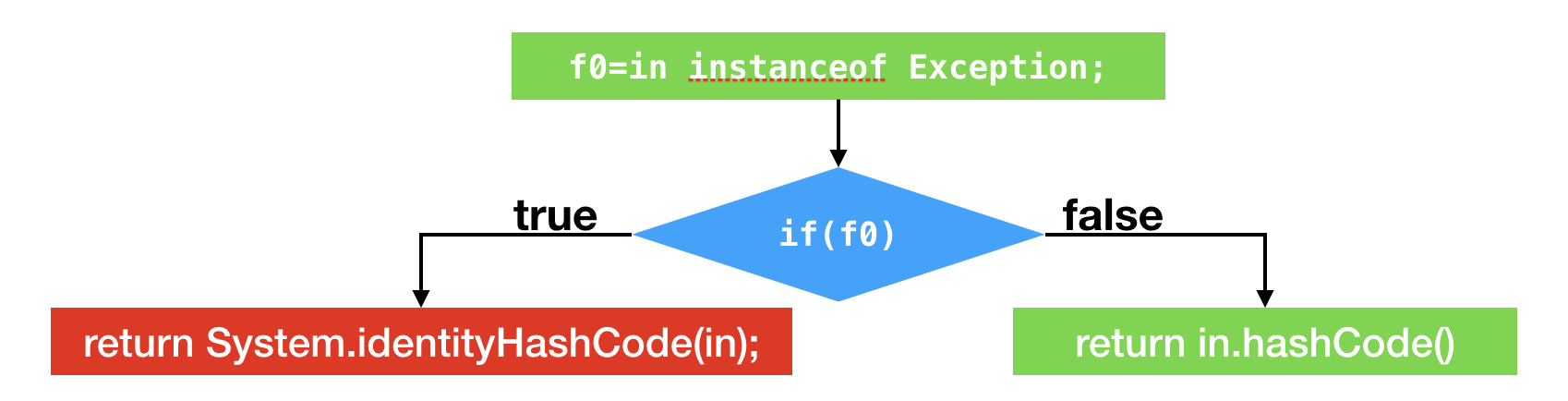
profiling+优化
- 假设应用调用该方法时,所传入的Object皆为Integer实例
- 偏移量为1的instanceof指令的类型profile仅包含Integer
- 偏移量为4的分支跳转语句的分支profile不跳转次数为0
- 偏移量为13的方法调用指令的类型profile仅包含Integer
- 测试instanceof
- 如果instanceof的目标类型是final类型,那么JVM仅需比较测试对象的动态类型是否为该final类型
- 如果目标类型不是final类型,JVM需要依次按下列顺序测试是否与目标类型一致
- 该类本身
- 该类的父类、祖先类
- 该类所直接实现或间接实现的接口
- instanceof指令的类型profile仅包含Integer
- JVM会假设在接下来的执行过程中,所输入的Object对象仍为Integer对象
- 生成的代码将直接测试所输入的动态类型是否为Integer,如果是继续执行接下来的代码
- 然后,即时编译器会采用针对分支profile的优化以及对方法调用的条件去虚化内联
- 内联结果:生成的代码将测试所输入对象的动态类型是否为Integer,如果是,执行
Integer.hashCode()方法的代码
- 内联结果:生成的代码将测试所输入对象的动态类型是否为Integer,如果是,执行
1 | public final class Integer ... { |
针对上面三个profile的分支图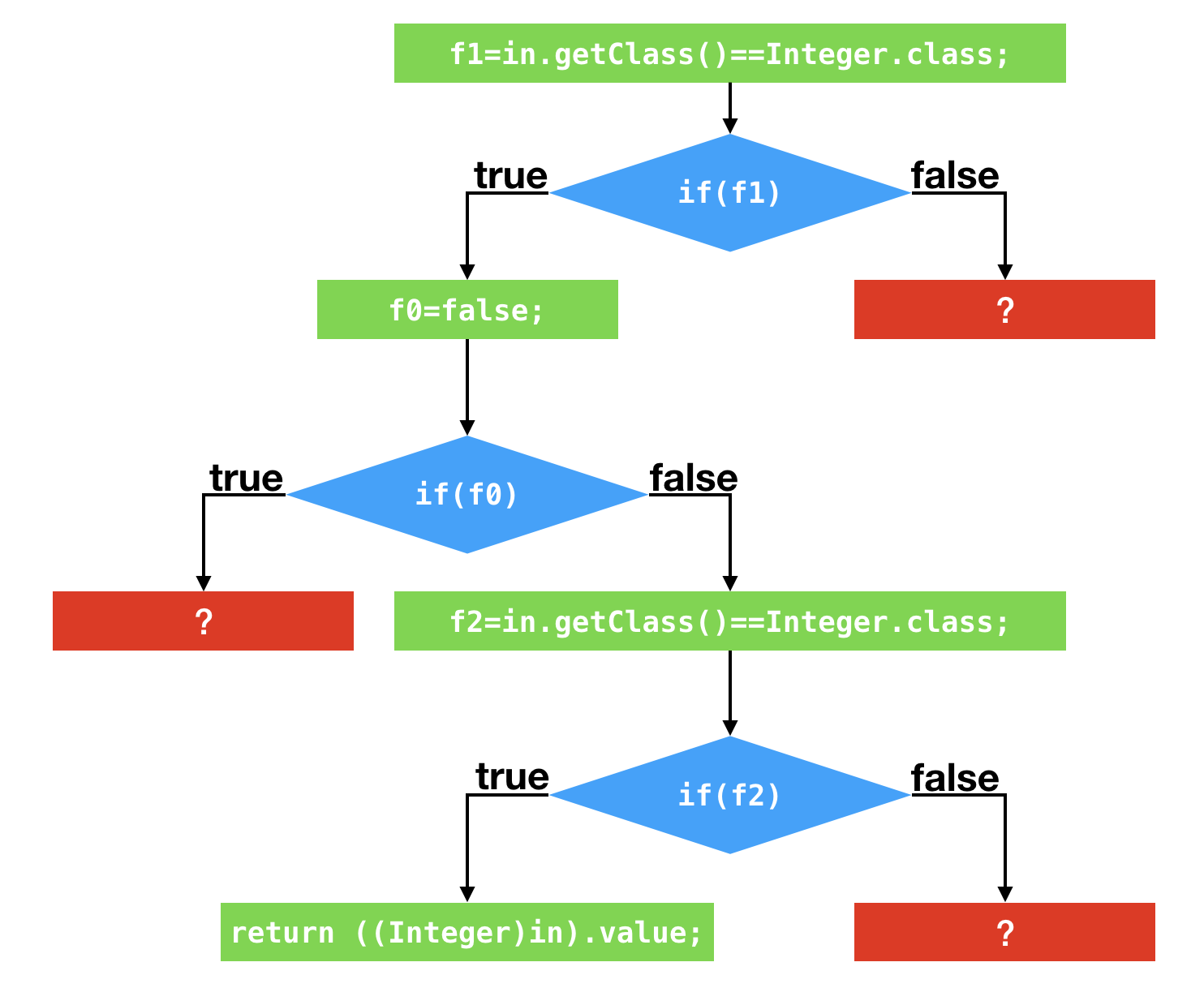
进一步优化(剪枝)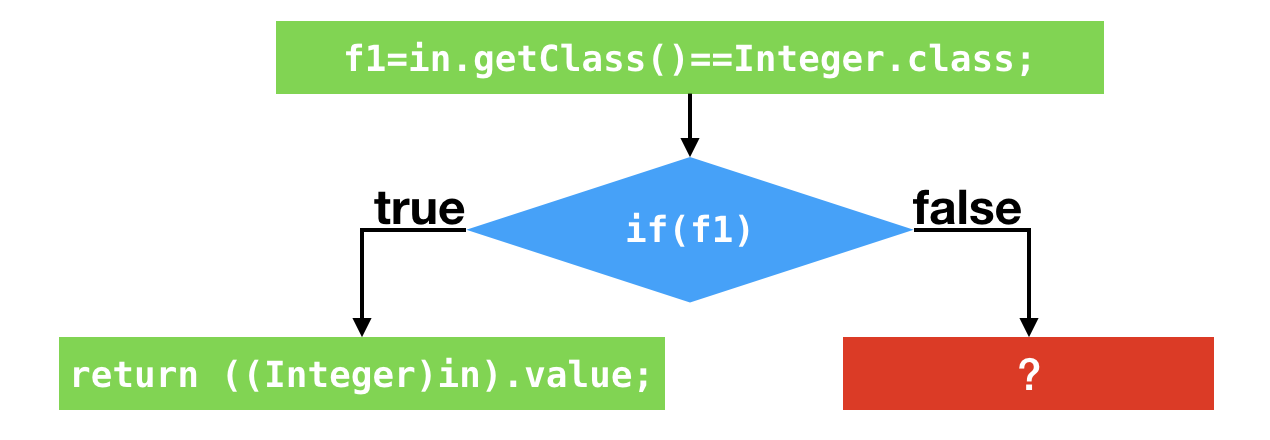
小结
- 和基于分支profile的优化一样,基于类型profile的优化同样也是作出假设,从而精简控制流以及数据流,两者的核心是假设
- 对于分支profile,即时编译器假设仅执行某一分支
- 对于类型profile,即时编译器假设的是对象的动态类型仅为类型profile中的那几个
- 如果假设失败,将进入去优化
去优化
- 去优化:从执行即时编译生成的机器码切回解释执行
- 在生成的机器码中,即时编译器将在假设失败的位置插入一个陷阱(trap)
- 陷阱实际上是一条call指令,调用至JVM专门负责去优化的方法
- 上图红色方框的问号,便代表陷阱
- 去优化的过程很复杂,由于即时编译器采用了许多优化方式,其生成的代码和原本字节码的差异非常大
- 在去优化的过程中,需要将当前机器码的执行状态切换至某一字节码之前的执行状态,并从该字节码开始执行
- 要求即时编译器在编译过程中记录好这两种执行状态的映射
- 在调用JVM的去优化方法时,即时编译器生成的机器码可以根据产生去优化的原因决定是否保留这份机器码,以及何时重新编译对应的Java代码
- 如果去优化的原因与优化无关
- 即使重新编译也不会改变生成的机器码,那么生成的机器码可以在调用去优化代码时传入Action_None
- 表示保留这一份机器码,在下次调用该方法时重新进入这一份机器码
- 如果去优化的原因与静态分析的结果有关,例如类层次分析
- 那么生成的机器码可以在调用去优化方法时传入Action_Recompile
- 表示不保留这一份机器码,但是可以不经过重新收集profile,直接重新编译
- 如果去优化的原因与基于profile的激进优化有关
- 那么生成的机器码需要在调用去优化方法时传入Action_Reinterpret
- 表示不保留这一份机器码,并且需要重新收集profile,再重新编译
- 因为之前收集到的profile已经不能准确反映程序的运行情况,需要重新收集
- 如果去优化的原因与优化无关
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2016-06-27
JVM基础 -- Instrumentation + sa-jdi 工具构建
本文首先介绍测量对象内存布局的其中一种方法,Instrumentation + sa-jdi 核心代码 代码托管在:https://github.com/zhongmingmao/java_object_layout 采用Instrumentation + sa-jdi的方式需要自己编写代码,比较繁琐,OpenJDK提供的JOL (Java Object Layout) 工具则是开箱即用,非常方便,后续博文会进一步介绍JOL的使用 测量对象大小通过Instrumentation测量对象占用的空间大小 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293/** * 对象占用字节大小工具类<br/> * see http://yueyemaitian.iteye.com/blog/2033...

2022-02-22
ASM - Introduction
Glance ASM is an all purpose Java bytecode manipulation and analysis framework. It can be used to modify existing classes or to dynamically generate classes, directly in binary form. ASM provides some common bytecode transformations and analysis algorithms from which custom complex transformations and code analysis tools can be built. ASM offers similar functionality as other Java bytecode frameworks, but is focused on performance. Because it was designed and implemented to be as small and as fast as p...

2016-07-04
JVM基础 -- JOL使用教程 3
本文将通过JOL分析Java对象的内存布局,包括伪共享、DataModel、Externals、数组对齐等内容代码托管在https://github.com/zhongmingmao/java_object_layout 伪共享Java8引入@sun.misc.Contended注解,自动进行缓存行填充,原始支持解决伪共享问题,实现高效并发,关于伪共享,网上已经很多资料,请参考下列连接: https://yq.aliyun.com/articles/62865 http://www.cnblogs.com/Binhua-Liu/p/5620339.html http://blog.csdn.net/zero__007/article/details/54951584 http://blog.csdn.net/aigoogle/article/details/41517213 http://hg.openjdk.java.net/jdk8u/jdk8u/jdk/file/tip/src/share/classes/sun/misc/Contended.java 代码12345678910111...

2019-09-13
Java性能 -- JVM堆内存分配
JVM内存分配性能问题 JVM内存分配不合理最直接的表现就是频繁的GC,这会导致上下文切换,从而降低系统的吞吐量,增加系统的响应时间 对象在堆中的生命周期 在JVM内存模型的堆中,堆被划分为新生代和老年代 新生代又被进一步划分为Eden区和Survivor区,Survivor区由From Survivor和To Survivor组成 当创建一个对象时,对象会被优先分配到新生代的Eden区 此时JVM会给对象定义一个对象年轻计数器(-XX:MaxTenuringThreshold) 当Eden空间不足时,JVM将执行新生代的垃圾回收(Minor GC) JVM会把存活的对象转移到Survivor中,并且对象年龄+1 对象在Survivor中同样也会经历Minor GC,每经历一次Minor GC,对象年龄都会+1 如果分配的对象超过了-XX:PetenureSizeThreshold,对象会直接被分配到老年代 查看JVM堆内存分配 在默认不配置JVM堆内存大小的情况下,JVM根据默认值来配置当前内存大小 在JDK 1.7中,默认情况下新生代和老年代的比例是1:2,可以通过–XX:New...

2019-01-01
JVM基础 -- Java语法糖
自动装拆箱Java代码12345public int foo() { List<Integer> list = new ArrayList<>(); list.add(0); return list.get(0);} 字节码12345678910111213141516171819202122232425public int foo(); descriptor: ()I flags: ACC_PUBLIC Code: stack=2, locals=2, args_size=1 0: new // class java/util/ArrayList 3: dup 4: invokespecial // Method java/util/ArrayList."<init>":()V 7: astore_1 8: aload_1 9: iconst_0 // 自动装箱 ...

2022-02-10
Bytecode Manipulation - Java Agent Practice
概念Instrument Instrument 是 JVM 提供的一个可以修改已加载类的类库,依赖于 JVMTI 的 Attach API 机制 要使用 Instrument 的类修改功能,需要实现 java.lang.instrument.ClassFileTransformer 接口 可以在 ClassFileTransformer#transform 中利用 ASM 或者 Byte Buddy 等工具对字节码进行操作 Instrument 通过与 Java Agent 结合来注入到 JVM 中 JVMTI & Agent JPDA(Java Platform Debugger Architecture)是 JDK 标准,必须实现 如果 JVM 启动时开启了 JPDA,那么类是允许被重新加载的 已加载的旧版类信息被卸载,然后重新加载新版本的类 JVMTI 是 JVM 提供的一套对 JVM 进行操作的工具接口,Agent 是 JVMTI 的一种实现 Attach API 的作用:提供 JVM 进程间通信的能力 Attach 后,目标 JVM 在运行时走到 Agent 中定义的 age...




