
Java并发 -- Fork + Join
任务视角
- 线程池+Future:简单并行任务
- CompletableFuture:聚合任务
- CompletionService:批量并行任务
- Fork/Join:_分治_
分治任务模型
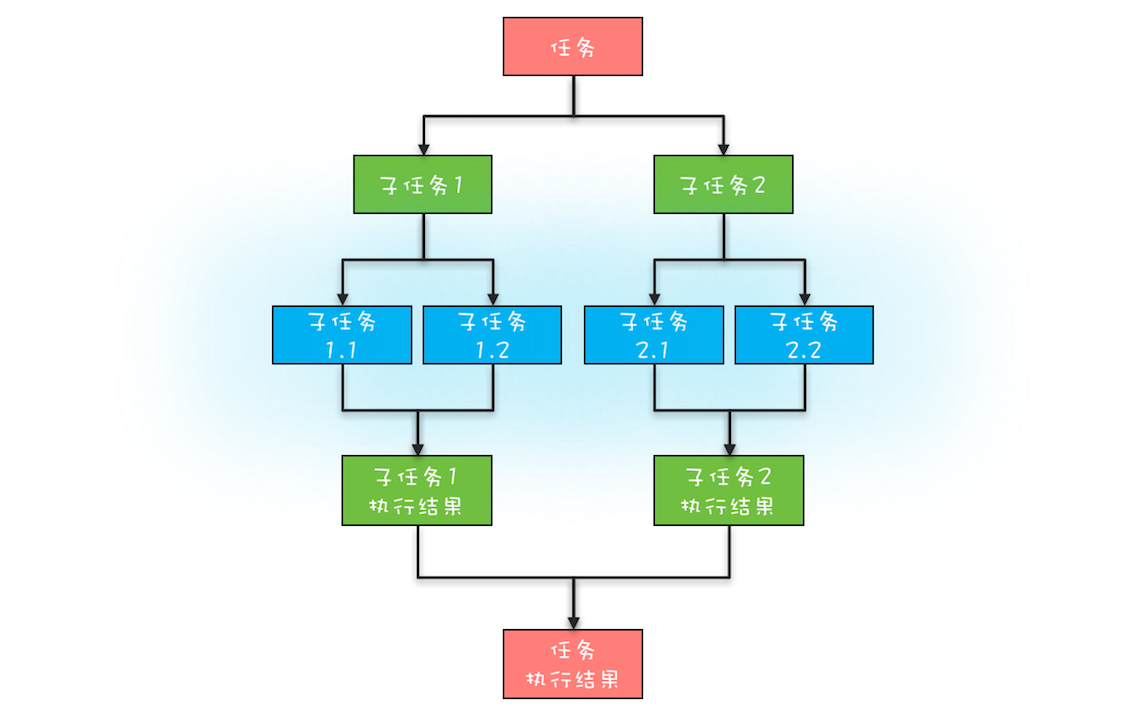
- 分治任务模型分为两个阶段:任务分解 + 结果合并
- 任务分解:将任务迭代地分解为子任务,直至子任务可以直接计算出结果
- 任务和分解后的子任务具有相似性(算法相同,只是计算的数据规模不同,往往采用递归算法)
- 结果合并:逐层合并子任务的执行结果,直至获得最终结果
Fork/Join
概述
- Fork/Join是并行计算的框架,主要用来支持分治任务模型,Fork对应任务分解,Join对应结果合并
- Fork/Join框架包含两部分:分治任务ForkJoinTask + 分治任务线程池ForkJoinPool
- 类似于Runnable + ThreadPoolExecutor
- ForkJoinTask最核心的方法是fork和join
- fork:异步地执行一个子任务
- join:阻塞当前线程,等待子任务的执行结果
- ForkJoinTask有两个子类:RecursiveAction + RecursiveTask
- Recursive:通过递归的方式来处理分治任务
- RecursiveAction.compute:没有返回值
- RecursiveTask.compute:有返回值
简单使用
1 | // 递归任务 |
ForkJoinPool的工作原理
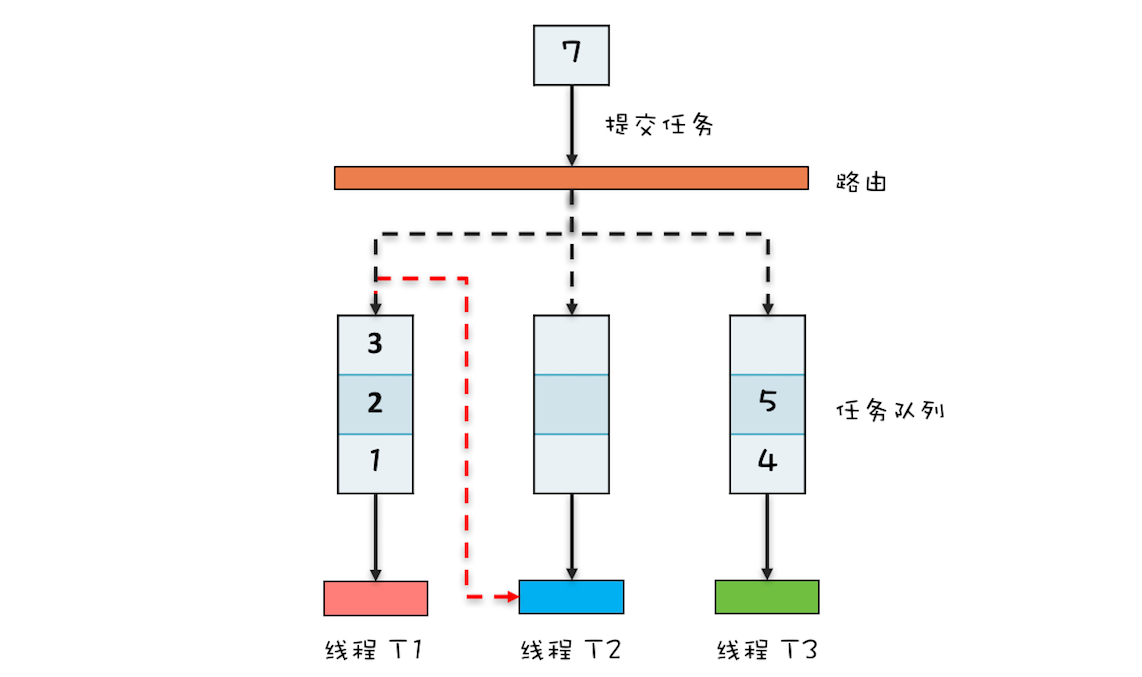
- Fork/Join并行计算的核心组件是ForkJoinPool
- ThreadPoolExecutor本质上是生产者-消费者模式的实现
- 内部有一个任务队列,该任务队列是生产者和消费者通信的媒介
- ThreadPoolExecutor可以有多个工作线程,但这些工作线程都_共享一个任务队列_
- ForkJoinPool本质上也是生产者-消费者模式的实现,但更加智能
- ThreadPoolExecutor内部只有一个任务队列,而ForkJoinPool内部有多个任务队列
- 当通过invoke或submit提交任务时,ForkJoinPool会根据一定的路由规则把任务提交到一个任务队列
- 如果任务在执行过程中创建子任务,那么该子任务被会提交到工作线程对应的任务队列中
- ForkJoinPool支持任务窃取,如果工作线程空闲了,那么它会窃取其他任务队列里的任务
- ForkJoinPool的任务队列是_双端队列_
- 工作线程正常获取任务和窃取任务分别从任务队列不同的端消费,避免不必要的数据竞争
统计单词数量
1 |
|
小结
- Fork/Join并行计算框架主要解决的是分治任务,分治的核心思想是_分而治之_
- Fork/Join并行计算框架的核心组件是ForkJoinPool,支持任务窃取,让所有线程的工作量基本均衡
- Java 1.8提供的Stream API里的并行流是以ForkJoinPool为基础的
- 默认情况下,所有并行流计算都共享一个ForkJoinPool,该共享的ForkJoinPool的线程数是CPU核数
- 如果存在IO密集型的并行流计算,那可能会因为一个很慢的IO计算而影响整个系统的性能
- 因此,建议_用不同的ForkJoinPool执行不同类型的计算任务_
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-05-24
Java并发 -- Worker Thread模式
Worker Thread模式 Worker Thread模式可以类比现实世界里车间的工作模式,Worker Thread对应车间里的工人(人数确定) 用阻塞队列做任务池,然后创建固定数量的线程消费阻塞队列中的任务 – 这就是Java中的线程池方案 echo服务123456789101112131415161718192021222324252627private ExecutorService pool = Executors.newFixedThreadPool(500);public void handle() throws IOException { // 处理请求 try (ServerSocketChannel ssc = ServerSocketChannel.open().bind(new InetSocketAddress(8080))) { while (true) { // 接收请求 SocketChannel sc = ssc.accept(); /...
2019-06-04
Java并发 -- Actor模型
Actor模型 Actor模型在本质上是一种计算模型,基本的计算单元称为Actor,在Actor模型中,所有的计算都在Actor中执行 在面向对象编程里,一切都是对象,在Actor模型里,一切都是Actor,并且Actor之间是完全隔离的,不会共享任何变量 Java本身并不支持Actor模型,如果需要在Java里使用Actor模型,需要借助第三方类库,比较完备的是Akka Hello Actor12345678910111213141516public class HelloActor extends UntypedAbstractActor { // 该Actor在收到消息message后,会打印Hello message @Override public void onReceive(Object message) throws Throwable { System.out.printf("Hello %s%n", message); } public static void main(String[...

2016-07-04
JVM基础 -- JOL使用教程 3
本文将通过JOL分析Java对象的内存布局,包括伪共享、DataModel、Externals、数组对齐等内容代码托管在https://github.com/zhongmingmao/java_object_layout 伪共享Java8引入@sun.misc.Contended注解,自动进行缓存行填充,原始支持解决伪共享问题,实现高效并发,关于伪共享,网上已经很多资料,请参考下列连接: https://yq.aliyun.com/articles/62865 http://www.cnblogs.com/Binhua-Liu/p/5620339.html http://blog.csdn.net/zero__007/article/details/54951584 http://blog.csdn.net/aigoogle/article/details/41517213 http://hg.openjdk.java.net/jdk8u/jdk8u/jdk/file/tip/src/share/classes/sun/misc/Contended.java 代码12345678910111...

2019-05-26
Java并发 -- 生产者-消费者模式
生产者-消费者模式 生产者-消费者模式的核心是一个_任务队列_ 生产者线程生产任务,并将任务添加到任务队列中,消费者线程从任务队列中获取任务并执行 从架构设计的角度来看,生产者-消费者模式有一个很重要的优点:_解耦_ 生产者-消费者模式另一个重要的优点是支持异步,并且能够平衡生产者和消费者的速度差异(任务队列) 支持批量执行 往数据库INSERT 1000条数据,有两种方案 第一种方案:用1000个线程并发执行,每个线程INSERT一条数据 第二种方案(更优):用1个线程,执行一个批量的SQL,一次性把1000条数据INSERT进去 将原来直接INSERT数据到数据库的线程作为生产者线程,而生产者线程只需将数据添加到任务队列 然后消费者线程负责将任务从任务队列中批量取出并批量执行 1234567891011121314151617181920212223242526272829303132333435363738// 任务队列private BlockingQueue<Task> queue = new LinkedBlockingQueue<>(2...

2019-05-25
Java并发 -- 两阶段终止模式
两阶段终止模式第一阶段线程T1向线程T2发送终止指令,第二阶段是线程T2响应终止指令 Java线程生命周期 Java线程进入终止状态的前提是线程进入RUNNABLE状态,而实际上线程可能处于休眠状态 因为如果要终止处于休眠状态的线程,要先通过interrupt把线程的状态从休眠状态转换到RUNNABLE状态 RUNNABLE状态转换到终止状态,优雅的方式是让Java线程自己执行完run方法 设置一个标志位,然后线程会在合适的时机检查这个标志位 如果发现符合终止条件,就会自动退出run方法 第二阶段:响应终止指令 终止监控操作 监控系统需要动态采集一些数据,监控系统发送采集指令给被监控系统的的监控代理 监控代理接收到指令后,从监控目标收集数据,然后回传给监控系统 处于性能的考虑,动态采集一般都会有终止操作 12345678910111213141516171819202122232425262728293031323334353637383940public class Proxy { private boolean started = false; // 采...

2019-04-29
Java并发 -- 线程数量
多线程的目的 使用多线程的目的是为了_提高程序性能_ 度量程序性能的核心指标:_延迟 + 吞吐量_ 延迟:发出请求到收到响应的时间,延迟越短,意味着程序执行得越快,性能越好 吞吐量:在单位时间内能处理请求的数量,吞吐量越大,意味着程序能处理的请求越多,性能越好 同等条件下,延迟越短,吞吐量越大,但两者隶属于不同的维度(一个时间维度,一个空间维度),并不能互相转换 提升程序性能:_降低延迟,提高吞吐量_ 多线程的应用场景 要达到降低延迟,提高吞吐量的目的,有两个方向:一个是优化算法,一个是_将硬件的性能发挥到极致_ 前者属于算法范畴,后者与并发编程息息相关 在并发编程领域,_提高性能本质上就是要提高硬件的利用率_,主要是提升IO利用率和CPU利用率 操作系统解决硬件利用率问题的对象往往是单一的硬件设备,而并发编程要解决CPU和IO设备综合利用率的问题 综合利用率假设程序按照CPU计算和IO操作交叉执行的方式运行,而且CPU计算和IO操作的耗时是1:1 单线程 单线程时,执行CPU计算的时候,IO设备空闲,执行IO操作时,CPU空闲,所以CPU利用率和IO设备的利用率都是50% 两线程...




