Kafka -- 避免重平衡
概念
- Rebalance是让Consumer Group下所有的Consumer实例就如何消费订阅主题的所有分区达成共识的过程
- 在Rebalance过程中,所有Consumer实例共同参与,在协调者组件的帮助下,完成订阅主题分区的分配
- 整个Rebalance过程中,所有Consumer实例都不能消费任何消息,因此对Consumer的TPS影响很大
协调者
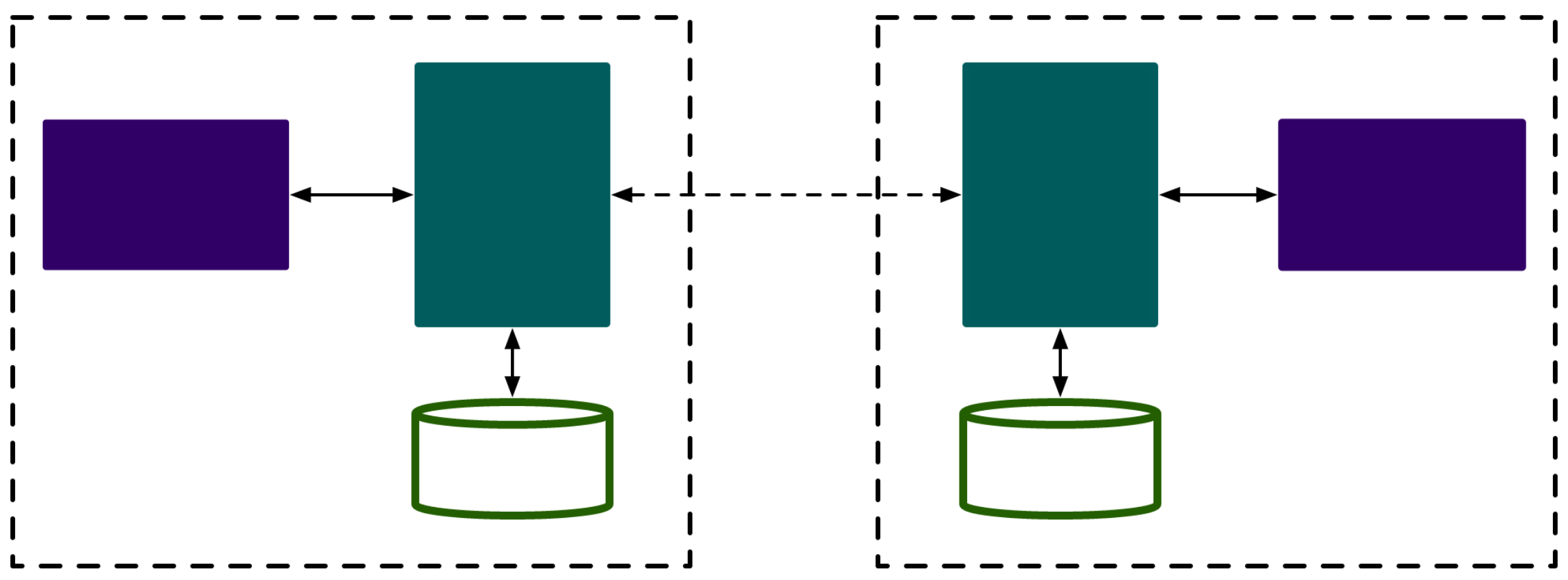
- 协调者,即Coordinator,负责为Consumer Group执行Rebalance以及提供位移管理和组成员管理等
- Consumer端应用程序在提交位移时,其实是向Coordinator所在的Broker提交位移
- Consumer应用启动时,也是向Coordinator所在的Broker发送各种请求
- 然后由Coordinator负责执行消费组的注册、成员管理记录等元数据管理操作
- 所有Broker在启动时,都会创建和开启相应的Coordinator组件,所有Broker都有各自的Coordinator组件
- 内部位移主题
__consumer_offsets记录了为Consumer Group服务的Coordinator在哪一台Broker上 - 为某个Consumer Group确定Coordinator所在的Broker,有两个步骤
- 确定由位移主题的哪个分区来保存该Consumer Group数据
partitionId = Math.abs(groupId.hashCode() % offsetsTopicPartitionCount- offsetsTopicPartitionCount默认为50
- 找出该分区Leader副本所在的Broker,该Broker即为对应的Coordinator
- 确定由位移主题的哪个分区来保存该Consumer Group数据
弊端
- Rebalance影响Consumer端TPS
- Rebalance很慢
- Rebalance效率不高
- 每次Rebalance,Consumer Group下所有成员都需要参与,而且不考虑局部性原理,_之前的分配方案都不会被保留_
- 为了解决这个问题,社区于0.11.0.0版本推出StickyAssignor,即粘性的分区分配策略
- 粘性指的是每次Rebalance,都尽可能地保留之前的分配方案,尽量实现分区分配的最小改动
- 但该策略存在一些Bug,而且需要升级到0.11.0.0才能使用,实际生产环境中用得不多
- 影响Consumer端TPS + 慢属于无解,因此尽量_减少不必要的Rebalance_
发生时机
- 组成员数量发生变化 – 最常见
- Consumer实例增加:一般是基于增加TPS或者提高伸缩性的需要,属于计划内的操作,不属于不必要的Rebalance
- Consumer实例减少:在某些情况下Consumer实例会被Coordinator错误地认为已停止而被踢出Consumer Group
- 订阅主题数量发生变化
- 一般是运维主动操作,很难避免
- 订阅主题的分区数量发生变化
- 一般是运维主动操作,很难避免
实例减少
Consumer端参数
- 当Consumer Group完成Rebalance后,每个Consumer实例都会定期地向Coordinator发送心跳
- 如果某个Consumer实例不能及时地发送心跳
- Coordinator会认为该Consumer已死,并将其从Consumer Group中移除,开启新一轮的Rebalance
- Consumer端有一个参数
session.timeout.ms,默认值为10秒- 如果Coordinator在10秒内没有收到Consumer Group下某个Consumer实例的心跳,就会认为该Consumer已死
- Consumer端还有另一个参数
heartbeat.interval.ms,默认值为3秒- 设置得越小,Consumer实例发送心跳的频率就会越高,会额外消耗带宽资源,但能更快地知道是否开启Rebalance
- Coordinator通过将REBALANCE_NEEDED标志封装进心跳响应中,来通知Consumer实例开启Rebalance
- Consumer端还有另一个参数
max.poll.interval.ms,默认值为5分钟- 该参数用于控制Consumer实际消费能力对Rebalance的影响,限定了Consumer端两次调用poll方法的最大时间间隔
- Consumer如果在5分钟内无法消费完poll方法返回的消息,就会主动发起离开组的请求,开启新一轮的Rebalance
非必要的Rebalance
- Consumer未及时发送心跳,导致被踢出Consumer Group而引发的Rebalance
- 生产配置:
session.timeout.ms=6000+heartbeat.interval.ms=2000session.timeout.ms=6000:为了让Coordinator能够更快地定位已经挂掉的Consumer
session.timeout.ms > 3 * heartbeat.interval.ms
- 生产配置:
- Consumer消费时间过长,主动发起离开组的请求而引发的Rebalance
- 如果消费逻辑很重(如DB操作),可以将
max.poll.interval.ms设置得大一点
- 如果消费逻辑很重(如DB操作),可以将
- 关注Consumer端的GC表现,频繁的Full GC会引起非预期的Rebalance
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-08-22
Kafka -- 消费者组
消费者组 消费者组(Consumer Group)是Kafka提供的可扩展且具有容错性的消费者机制 一个消费者组内可以有多个消费者或消费者实例(进程/线程),它们共享一个Group ID(字符串) 组内的所有消费者协调在一起来消费订阅主题的所有分区 每个分区只能由同一个消费者组内的一个Consumer实例来消费,Consumer实例对分区有所有权 消息引擎模型 两种模型:点对点模型(消息队列)、发布订阅模型 点对点模型(传统的消息队列模型) 缺陷/特性:消息一旦被消费、就会从队列中被删除,而且只能被下游的一个Consumer消费 伸缩性很差,下游的多个Consumer需要抢占共享消息队列中的消息 发布订阅模型 缺陷:伸缩性不高,每个订阅者都必须订阅主题的所有分区(全量订阅) Consumer Group 当Consumer Group订阅了多个主题之后 组内的每个Consumer实例不要求一定要订阅主题的所有分区,只会消费部分分区的消息 Consumer Group之间彼此独立,互不影响,它们能够订阅相同主题而互不干涉 Kafka使用Consumer Group...

2019-09-16
Kafka -- 重平衡
触发重平衡 组成员数量发生变化 – 最常见 订阅主题数量发生变化 订阅主题的分区数发生变化 通知 重平衡过程是通过消费者的心跳线程通知到其它消费者实例的 Kafka Java消费者需要定期地发送心跳请求到Broker端的协调者,表明它还活着 在Kafka 0.10.1.0之前,发送心跳请求是在消费者主线程完成的,即调用poll方法的那个线程 弊端 消息处理逻辑是也在主线程完成的 一旦消息处理消耗了很长时间,心跳请求将无法及时发送给协调者,导致协调者误以为消费者已死 从Kafka 0.10.1.0开始,社区引入了单独的心跳线程 重平衡的通知机制是通过心跳线程来完成的 当协调者决定开启新一轮重平衡后,会将REBALANCE_IN_PROGRESS封装进心跳请求的响应中 当消费者实例发现心跳响应中包含REBALANCE_IN_PROGRESS,就知道重平衡要开始了,这是重平衡的通知机制 heartbeat.interval.ms的真正作用是控制重平衡通知的频率 消费者组状态机 状态 描述 Empty 组内没有任何成员,但消费者组可能存在已提交的位移数据,而且这些位移尚未过期 ...

2018-10-11
Kafka -- 生产者
生产者概述 创建一个ProducerRecord对象,ProducerRecord对象包含Topic和Value,还可以指定Key或Partition 在发送ProducerRecord对象时,生产者先将Key和Partition序列化成字节数组,以便于在网络上传输 字节数组被传给分区器 如果在ProducerRecord对象里指定了Partition 那么分区器就不会做任何事情,直接返回指定的分区 如果没有指定分区,那么分区器会根据ProducerRecord对象的Key来选择一个Partition 选择好分区后,生产者就知道该往哪个主题和分区发送这条记录 这条记录会被添加到一个记录批次里,一个批次内的所有消息都会被发送到相同的Topic和Partition上 有一个单独的线程负责把这些记录批次发送到相应的Broker 服务器在收到这些消息时会返回一个响应 如果消息成功写入Kafka,就会返回一个RecordMetaData对象 包含了Topic和Partition信息,以及记录在分区里的偏移量 如果写入失败,就会返回一个错误 生产者在收到错误之后会尝试重新发送消息,几次之后如果还...

2019-06-18
Kafka -- 消息引擎系统
术语 Apache Kafka是一款开源的消息引擎系统 消息队列:给人某种暗示,仿佛Kafka是利用队列实现的 消息中间件:过度强调中间件,而不能清晰地表达实际解决的问题 解决的问题 系统A发送消息给消息引擎系统,系统B从消息引擎系统中读取A发送的消息 消息引擎传输的对象是消息 如何传输消息属于消息引擎设计机制的一部分 消息格式 成熟解决方案:CSV、XML、JSON 序列化框架:Google Protocol Buffer、Facebook Thrift Kafka:纯二进制的字节序列 消息引擎模型 点对点模型 即消息队列模型,系统A发送的消息只能被系统B接收,其他任何系统不能读取A发送的消息 发布订阅模型 主题(Topic)、发布者(Publisher)、订阅者(Subscriber) 多个发布者可以向相同的主题发送消息,多个订阅者可以接收相同主题的消息 Kafka同时支持上面两种消息引擎模型 JMS JMS:Java Message Service JMS也支持上面的两种消息引擎模型 JMS并非传输协议,而是一组API JMS非常出名,很多主流的消息引擎系统都支持JMS规范 A...

2018-10-08
Kafka -- 集群安装与配置(Ubuntu)
单节点安装Java添加ppa12$ sudo add-apt-repository ppa:webupd8team/java$ sudo apt-get update 安装oracle-java8-installer1$ sudo apt-get install oracle-java8-installer 设置系统默认JDK1$ sudo update-java-alternatives -s java-8-oracle 下载解压Kafka12345$ mkdir ~/Downloads & cd ~/Downloads$ wget http://mirrors.hust.edu.cn/apache/kafka/2.0.0/kafka_2.11-2.0.0.tgz$ mkdir ~/kafka && cd ~/kafka$ kafka tar -xvzf ~/Downloads/kafka_2.11-2.0.0.tgz --strip 1 允许Kafka删除主题1234$ vim ~/kafka/config/server.properties# 添加delete...

2019-09-23
Kafka -- 主题管理
日常管理创建主题1$ kafka-topics --bootstrap-server localhost:9092 --create --topic t1 --partitions 1 --replication-factor 1 从Kafka 2.2版本开始,推荐使用--bootstrap-server代替--zookeeper(标记为已过期) 原因 使用--zookeeper会绕过Kafka的安全体系,不受认证体系的约束 使用--bootstrap-server与集群交互是未来的趋势 查询主题列表12345$ kafka-topics --bootstrap-server localhost:9092 --list__consumer_offsets_schemast1transaction 查询单个主题1234567$ kafka-topics --bootstrap-server localhost:9092 --describe --topic __consumer_offsetsTopic:__consumer_offsets PartitionCount:50 Repl...