
Kafka -- 监控消费进度
Consumer Lag
- Consumer Lag(滞后程度):消费者当前落后于生产者的程度
- Lag的单位是消息数,一般是在主题的级别上讨论Lag,但Kafka是在分区的级别上监控Lag,因此需要手动汇总
- 对于消费者而言,Lag是最重要的监控指标,直接反应了一个消费者的运行情况
- 一个正常工作的消费者,它的Lag值应该很小,甚至接近于0,滞后程度很小
- 如果Lag很大,表明消费者无法跟上生产者的速度,Lag会越来越大
- 极有可能导致消费者消费的数据已经不在操作系统的页缓存中了,这些数据会失去享有Zero Copy技术的资格
- 这样消费者不得不从磁盘读取这些数据,这将进一步拉大与生产者的差距
- 马太效应:_Lag原本就很大的消费者会越来越慢,Lag也会也来越大_
监控Lag
Kafka自带命令
kafka-consumer-groups是Kafka提供的最直接的监控消费者消费进度的工具- 也能监控独立消费者的Lag,独立消费者是没有使用消费者组机制的消费者程序,也要配置
group.id - 消费者组要调用
KafkaConsumer.subscribe,独立消费者要调用KafkaConsumer.assign直接消费指定分区
- 也能监控独立消费者的Lag,独立消费者是没有使用消费者组机制的消费者程序,也要配置
- 输出信息
- 消费者组、主题、分区、消费者实例ID、消费者连接Broker的主机名、消费者的CLIENT-ID信息
- CURRENT-OFFSET:消费者组当前最新消费消息的位移值
- LOG-END-OFFSET:每个分区当前最新生产的消息的位移值
- LAG:LOG-END-OFFSET和CURRENT-OFFSET的差值
1 | $ kafka-consumer-groups --bootstrap-server localhost:9092 --describe --group zhongmingmao |
Kafka Java Consumer API
1 | private Map<TopicPartition, Long> lagOf(String groupId, String bootstrapServers) throws TimeoutException { |
1 | partition: zhongmingmao-1, lag: 0 |
Kafka JMX 监控指标
- 上面的两种方式,都可以很方便地查询到给定消费者组的Lag信息
- 但在实际监控场景中,往往需要借助现成的监控框架(如Zabbix/Grafana)
- 此时可以选择Kafka默认提供的JMX监控指标来监控消费者的Lag值
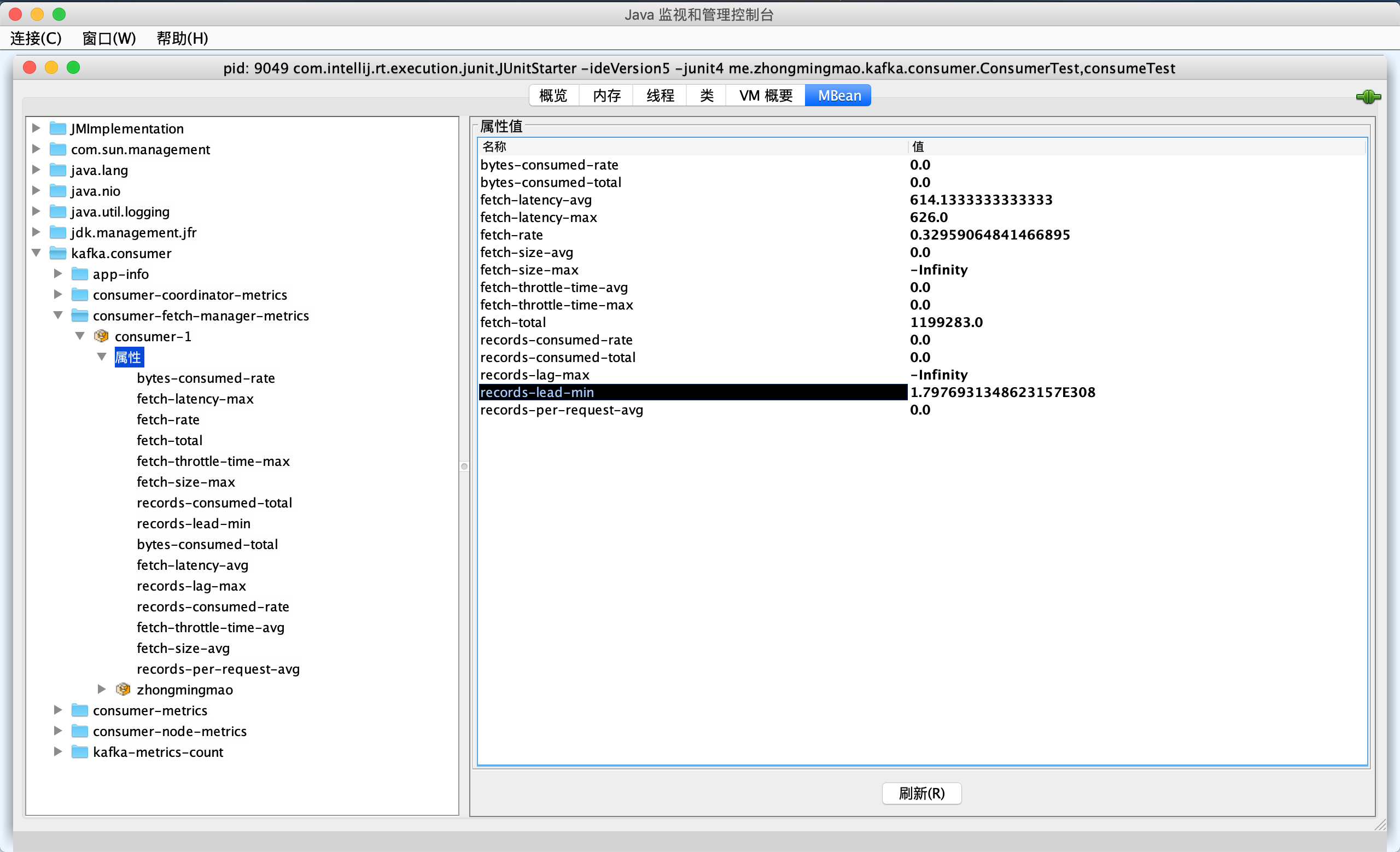
- 消费者提供了
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{client-id}"的JMX指标records-lag-max和records-lead-min分别代表此消费者在测试窗口时间内曾经达到的最大Lag值和最小Lead值- Lead:消费者最新消费消息的位移与当前分区第一条消息位移的差值,_Lag越大,Lead越小_
- 一旦监测到Lead越来越小,甚至快接近于0,预示着消费者端要丢消息了
- Kafka消息是有留存时间的,默认是1周,如果消费者程序足够慢,慢到它要消费的数据快被Kafka删除
- 一旦出现消息被删除,从而导致消费者程序重新调整位移值的情况,可能产生两个后果
- 一个是消费者从头消费一遍数据
- 另一个是消费者从最新的消息位移处开始消费,之前没来得及消费的消息全部被跳过,造成丢消息的假象
- Lag值从100W增加到200W,远不如Lead值从200减少到100重要,实际生产环境中,要同时监控Lag值和Lead值
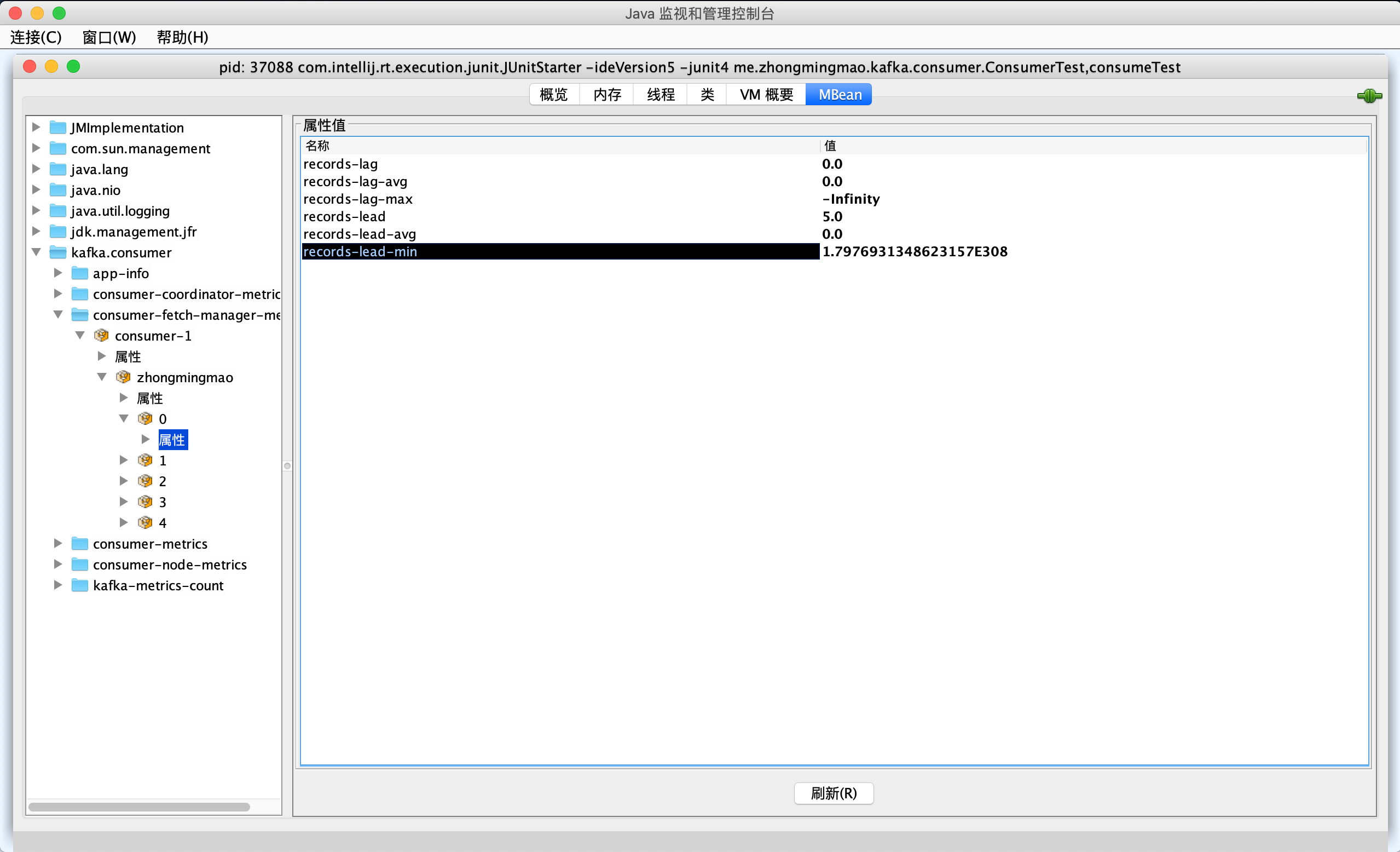
- 消费者还在分区级别提供了额外的JMX指标,用于单独监控分区级别的Lag和Lead值
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{client-id}",topic="{topic}",partition="{partition}"- 多了
records-lag-avg和records-lead-avg,可以计算平均的Lag值和Lead值,经常使用
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-08-19
Kafka -- 幂等性生产者 + 事务生产者
消息交付可靠性保障 消息交付可靠性保障:Kafka对Producer和Consumer要处理的消息所提供的承诺 常见的承诺 最多一次(at most once):消息可能会丢失,但绝不会被重复发送 至少一次(at least once):消息不会丢失,但有可能被重复发送 精确一次(exactly once):消息不会丢失,也不会被重复发送 Kafka默认提供的交付可靠性保障:_至少一次_ 只有Broker成功提交消息且Producer接到Broker的应答才会认为该消息成功发送 如果Broker成功提交消息,但Broker的应答没有成功送回Producer端,Producer只能选择重试 最多一次 Kafka也可以提供最多一次交付可靠性保证,只需要让Producer禁止重试即可,但大部分场景下并不希望出现消息丢失 精确一次 消息不会丢失,也不会被重复处理,即使Producer端重复发送了相同的消息,Broker端也能自动去重 两种机制:幂等性、事务 幂等性 幂等原是数学中的概念:某些操作或者函数能够被执行多次,但每次得到的结果都是不变的 幂等操作:乘1,取整函数;非幂等操作:加1 ...

2019-09-08
Kafka -- 多线程消费者
Kafka Java Consumer设计原理 Kafka Java Consumer从Kafka 0.10.1.0开始,KafkaConsumer变成了双线程设计,即用户主线程和心跳线程 用户主线程:启动Consumer应用程序main方法的那个线程 心跳线程:只负责定期给对应的Broker机器发送心跳请求,以标识消费者应用的存活性 引入心跳线程的另一个目的 将心跳频率和主线程调用KafkaConsumer.poll方法的频率分开,解耦真实的消息处理逻辑和消费组成员存活性管理 虽然有了心跳线程,但实际的消息获取逻辑依然是在用户主线程中完成 因此在消费消息的这个层面,依然可以安全地认为KafkaConsumer是单线程的设计 老版本Consumer是多线程的架构 每个Consumer实例在内部为所有订阅的主题分区创建对应的消息获取线程,即Fetcher线程 老版本Consumer同时也是阻塞式的,Consumer实例启动后,内部会创建很多阻塞式的消息获取迭代器 但在很多场景下,Consumer端有非阻塞需求,如在流处理应用中执行过滤、分组等操作就不能是阻塞式的 基于这个原因,社区为新版本...

2018-10-17
Kafka -- Avro + Twitter Bijection
Avro + Kafka Native API 比较繁琐 编译Schema 依赖于Avro实现自定义的序列化器和反序列化器 引入依赖12345<dependency> <groupId>com.twitter</groupId> <artifactId>bijection-avro_2.12</artifactId> <version>0.9.6</version></dependency> Schema路径:src/main/resources/user.json 123456789{ "type": "record", "name": "User", "fields": [ {"name": "id", "type": "int"
...

2019-09-23
Kafka -- 主题管理
日常管理创建主题1$ kafka-topics --bootstrap-server localhost:9092 --create --topic t1 --partitions 1 --replication-factor 1 从Kafka 2.2版本开始,推荐使用--bootstrap-server代替--zookeeper(标记为已过期) 原因 使用--zookeeper会绕过Kafka的安全体系,不受认证体系的约束 使用--bootstrap-server与集群交互是未来的趋势 查询主题列表12345$ kafka-topics --bootstrap-server localhost:9092 --list__consumer_offsets_schemast1transaction 查询单个主题1234567$ kafka-topics --bootstrap-server localhost:9092 --describe --topic __consumer_offsetsTopic:__consumer_offsets PartitionCount:50 Repl...

2019-07-15
Kafka -- 线上部署
操作系统Linux的表现更胜一筹:IO模型的使用、网络传输效率、社区支持度 IO模型 主流的IO模型:阻塞式IO、非阻塞式IO、IO多路复用、信号驱动IO、异步IO,后一种模型比前一种高级 Java中的Socket对象的阻塞模式和非阻塞模式,对应阻塞式IO和非阻塞式IO Linux中的系统调用select函数属于IO多路复用模型 大名鼎鼎的epoll系统调用则介于第三种模型和第四种模型之间 很少有Linux系统支持异步IO,Windows系统提供的IOCP线程模型属于异步IO Kafka客户端底层使用了Java的selector,selector在Linux上的实现机制是epoll,在Windows上是select Kafka部署在Linux上,能够获得更高效的IO性能 网络传输效率 Kafka生产和消费的消息都是通过网络传输的,而消息是保存在磁盘上的 因此Kafka需要在磁盘和网络间进行大量的数据传输 Linux支持零拷贝技术 当数据在磁盘和网络进行传输时,避免昂贵的内核态数据拷贝,从而实现快速的数据传输 在Windows平台必须等待Java 8 Update 60才能享受到类似Li...
2019-09-03
Kafka -- 提交位移
消费位移 Consumer的消费位移,记录了Consumer要消费的下一条消息的位移 假设一个分区中有10条消息,位移分别为0到9 某个Consumer消费了5条消息,实际消费了位移0到4的5条消息,此时Consumer的位移为5,指向下一条消息的位移 Consumer需要向Kafka汇报自己的位移数据,这个汇报过程就是提交位移 Consumer能够同时消费多个分区的数据,所以位移的提交实际上是在分区粒度上进行的 Consumer需要为分配给它的每个分区提交各自的位移数据 提交位移主要是为了表征Consumer的消费进度 当Consumer发生故障重启后,能够从Kafka中读取之前提交的位移值,然后从相应的位移处继续消费 位移提交的语义 如果提交了位移X,那么Kafka会认为位移值小于X的消息都已经被成功消费了 灵活 位移提交非常灵活,可以提交任何位移值,但要承担相应的后果 假设Consumer消费了位移为0~9的10条消息 如果提交的位移为20,位移位于10~19的消息可能会丢失 如果提交的位移为5,位移位于5~9的消息可能会被重复消费 位移提交的语义保障由应用程序保证,Ka...




