
Kafka -- 处理请求
请求协议
- Kafka自定义了一组请求协议,用于实现各种各样的交互操作
- PRODUCE请求用于生产消息,FETCH请求用于消费消息,METADATA请求用于请求Kafka集群元数据信息
- Kafka 2.3总共定义了45种请求格式,所有请求都通过TCP网络以Socket的方式进行通讯
处理请求方案
顺序处理
实现简单,但吞吐量太差,只适用于请求发送非常不频繁的场景
1 | while (true) { |
单独线程处理
为每个请求都创建一个新的线程异步处理,完全异步,但开销极大,只适用于请求发送频率很低的场景
1 | while (true) { |
Reactor模式

- Reactor模式是事件驱动架构的一种实现方式,特别适合应用于处理多个客户端并发向服务器端发起请求的场景
- 多个客户端会发送请求给Reactor,Reactor有个请求分发线程Acceptor,将不同的请求下发到多个工作线程中处理
- Acceptor线程只用于请求分发,不涉及具体的逻辑处理,非常轻量级,有很高的吞吐量
- 工作线程可以根据实际业务处理需要任意增减,从而动态调节系统负载能力
Kafka
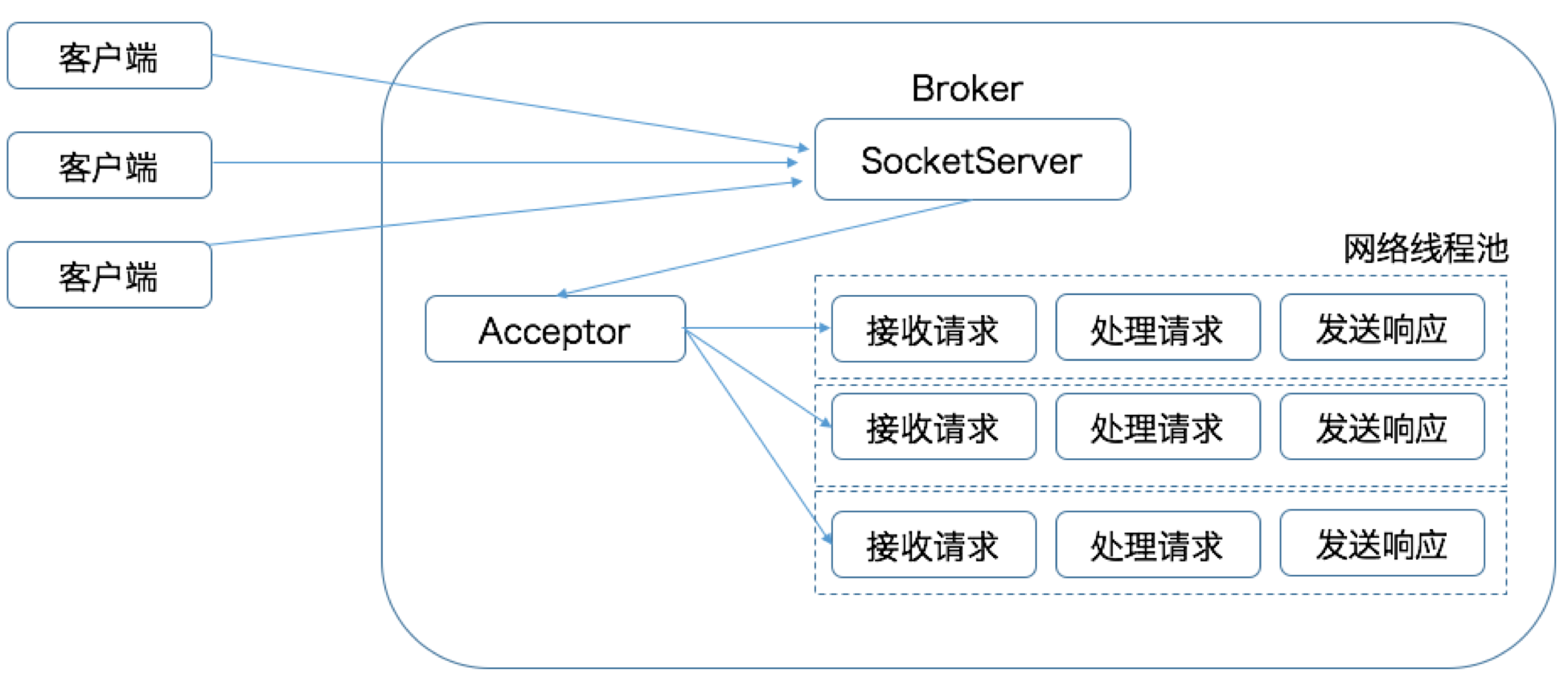
- Broker端有一个SocketServer组件,类似于Reactor模式中的Dispatcher
- 也有对应的Acceptor线程和一个工作线程池(即网络线程池,参数设置
num.network.threads,默认值为3)
- 也有对应的Acceptor线程和一个工作线程池(即网络线程池,参数设置
- Acceptor线程采用轮询的方式将入站请求公平地发到所有网络线程中
- 实现简单,避免了请求处理的倾斜,有利于实现较为公平的请求处理调度
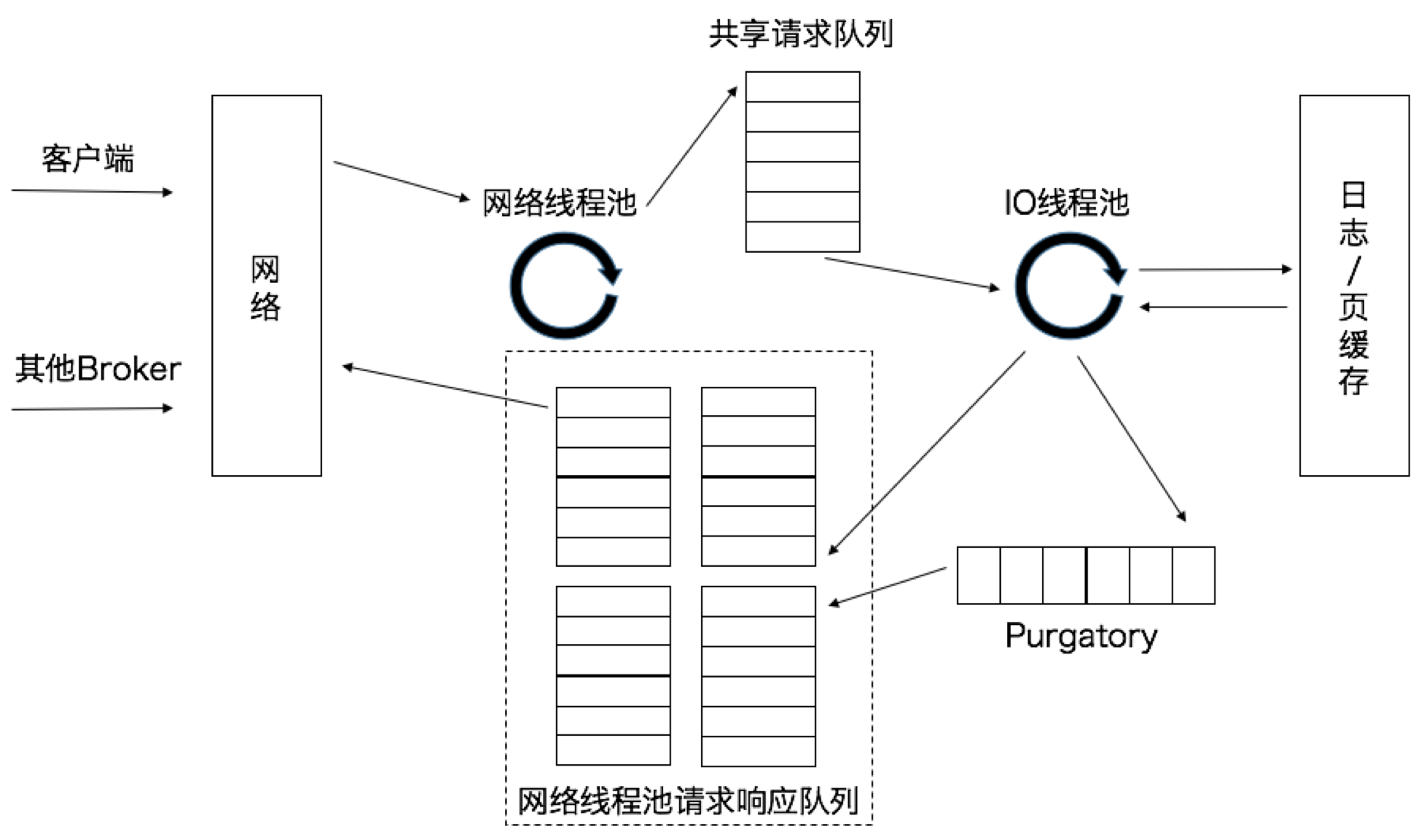
- 当网络线程拿到请求后,并不是自己处理,而是将请求放入到一个共享请求队列中
- Broker端还有一个IO线程池,负责从共享请求队列中取出请求,执行真正的处理
- 如果是PRODUCE请求,将消息写入到底层的磁盘日志中
- 如果是FETCH请求,则从磁盘或页缓存中读取消息
- IO线程池中的线程才是执行请求逻辑的线程,参数
num.io.threads,默认值为8 - 当IO线程处理完请求后,会将生成的响应发送到网络线程池的响应队列中
- 然后由对应的网络线程负责将Response返回给客户端
- 请求队列是所有网络线程共享的,而响应队列是每个网络线程专属的
- Purgatory组件用于_缓存延时请求_
- 如
acks=all的PRODUCE请求,必须等待ISR中所有副本都接收消息后才能返回- 此时处理该请求的IO线程必须等待其他Broker的写入结果,当请求不能处理时,就会暂存在Purgatory中
- 等到条件满足后,IO线程会继续处理该请求,并将Response放入对应网络线程的响应队列中
- Kafka将PRODUCE、FETCH这类请求称为数据类请求,把LeaderAndIsr、StopReplica这类请求称为控制类请求
- 在Kafka 2.3,正式实现了数据类请求和控制类请求的分离(完全拷贝一套组件,实现两类请求的分离)
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2018-10-09
Kafka -- 集群安装与配置(Docker)
配置文件文件列表123$ tree.└── docker-compose.yml docker-compose.yml123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103version: '2'services: zk1: image: confluentinc/cp-zookeeper:latest hostname: zk1 container_name: zk1 restart: always ports: - "12181:2181" environment: ZOOKEEPER_SERVER_ID: 1 ZOOKEEPER_CLIENT_...

2019-09-08
Kafka -- 多线程消费者
Kafka Java Consumer设计原理 Kafka Java Consumer从Kafka 0.10.1.0开始,KafkaConsumer变成了双线程设计,即用户主线程和心跳线程 用户主线程:启动Consumer应用程序main方法的那个线程 心跳线程:只负责定期给对应的Broker机器发送心跳请求,以标识消费者应用的存活性 引入心跳线程的另一个目的 将心跳频率和主线程调用KafkaConsumer.poll方法的频率分开,解耦真实的消息处理逻辑和消费组成员存活性管理 虽然有了心跳线程,但实际的消息获取逻辑依然是在用户主线程中完成 因此在消费消息的这个层面,依然可以安全地认为KafkaConsumer是单线程的设计 老版本Consumer是多线程的架构 每个Consumer实例在内部为所有订阅的主题分区创建对应的消息获取线程,即Fetcher线程 老版本Consumer同时也是阻塞式的,Consumer实例启动后,内部会创建很多阻塞式的消息获取迭代器 但在很多场景下,Consumer端有非阻塞需求,如在流处理应用中执行过滤、分组等操作就不能是阻塞式的 基于这个原因,社区为新版本...

2019-09-10
Kafka -- Java消费者管理TCP连接
创建TCP连接 消费者端的主要程序入口是KafkaConsumer,但构建KafkaConsumer实例不会创建任何TCP连接 构建KafkaProducer实例时,会在后台默默地启动一个Sender线程,Sender线程负责Socket连接的创建 在Java构造函数中启动线程,会造成this指针逃逸,是一个隐患 消费者的TCP连接是在调用**KafkaConsumer.poll**方法时被创建的,poll方法内部有3个时机可以创建TCP连接 发起FindCoordinator请求时 消费者组有个组件叫作协调者(Coordinator) 驻留在Broker端的内存中,负责消费者组的组成员管理和各个消费者的位移提交管理 当消费者程序首次启动调用poll方法时,需要向Kafka集群(集群中的任意Broker)发送FindCoordinator请求 社区优化:消费者程序会向集群中当前负载最小的那台Broker发送请求 单向负载评估(非最优解):消费者连接的所有Broker中,谁的待发送请求最少,谁的负载就越小 连接Coordinator时 Broker处理完FindCoordinator请...

2018-10-16
Kafka -- Avro + Kafka Native API
Schema123456789101112131415{ "namespace": "me.zhongmingmao.avro", "type": "record", "name": "Stock", "fields": [ {"name": "stockCode", "type": "string"}, {"name": "stockName", "type": "string"}, {"name": "tradeTime", "type": "long"}, {&qu...

2018-10-07
Kafka -- 单节点安装与配置(Mac)
安装步骤Kafka与ZookeeperKafka使用Zookeeper保存集群的元数据信息和消费者信息 安装Zookeeper和Kafka12345678910111213$ brew install kafka==> Installing dependencies for kafka: zookeeper==> Caveats==> zookeeperTo have launchd start zookeeper now and restart at login: brew services start zookeeperOr, if you don't want/need a background service you can just run: zkServer start==> kafkaTo have launchd start kafka now and restart at login: brew services start kafkaOr, if you don't want/need a background service...

2019-08-26
Kafka -- 位移主题
ZooKeeper 老版本Consumer的位移管理依托于Apache ZooKeeper,自动或手动地将位移数据提交到ZK中保存 当Consumer重启后,能自动从ZK中读取位移数据,从而在上次消费截止的地方继续消费 这种设计使得Kafka Broker不需要保存位移数据,减少了Broker端需要持有的状态空间,有利于实现高伸缩性 但ZK并不适用于高频的写操作 位移主题 将Consumer的位移数据作为普通的Kafka消息,提交到__consumer_offsets(保存Consumer的位移信息) 提交过程需要实现高持久性,并需要支持高频的写操作 位移主题是普通的Kafka主题,同时也是一个内部主题,交由Kafka管理即可 位移主题的消息格式由Kafka定义,用户不能修改 因此不能随意向位移主题写消息,一旦写入的消息不能满足格式,那Kafka内部无法成功解析,会造成Broker崩溃 Kafka Consumer有API来提交位移(即向位移主题写消息) 消息格式 常用格式:Key-Value Key为消息键值,Value为消息体,在Kafka中都是字节数组 Key <Group ...




