
Cloud Computing - PaaS
概述
PaaS 在 IaaS 的基础上,构建了很多
关键抽象和可复用的单元,让用户更聚焦业务
优势
- PaaS 更符合云的初衷,代表了一种
完全托管的理想主义,代表对研发生产力的极致追求 - 核心优势:
生产力(搭建 + 运维)
维度
- PaaS 服务是否带有
内生的运行环境(Web 服务带有编程语言运行时、数据库服务带有SQL 执行引擎) - PaaS 存在的
位置和范围,以及开放给用户的控制粒度–Region/Availability zone/VPC - PaaS 服务是否
有状态(数据属性) - PaaS 服务的
虚拟机是否对外暴露暴露虚拟机的 PaaS 服务,拥有更高的开放程度,与IaaS的结合也更加紧密,成本更低不暴露虚拟机的 PaaS 服务,拥有更好的独立性和封装性– 数据库服务
权衡
PaaS 的核心理念在于
封装:封装提升了效率,但牺牲了灵活性
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2022-10-20
Cloud Computing - Container
历史 相辅相成:云承载着容器的运行,容器生态驱动着云的发展 初期的首要目标:Docker 容器在云上能够顺畅运行 帮助用户创建底层虚拟机集群,免去用户自己手动管理虚拟机的麻烦 随着容器应用的复杂化,容器编排成为了用户最迫切的需求 Kubernetes 赢得了编排框架大战,成为了事实标准 自建 vs 托管 由于云端的多租户特性,云平台会统一提供和托管 Master 节点,降低运维成本 只需要创建 Worker 节点,并为之付费即可 Kubernetes 的抽象设计非常出色,能够支持大量灵活的扩展 云厂商会让尽量多的 IaaS 和 PaaS 功能组件,渗透到 Kubernetes 的体系中 Cloud Service Operator 通过云服务来扩展 Kubernetes 的能力,并反过来使用 Kubernetes 来管理这些云服务 成熟:容器和云一体化架构 多集群 降低了建立 Kubernetes 集群的门槛,如果业务关联较小,可以为不同的业务创建单独的 Kubernetes 集群 全托管 容器服务实例,无需关心底层基础设施 适合场景:只有一个容器镜像,且为无状态...

2022-10-19
Cloud Computing - Cloud database
RDS Relational Database Service 一般针对每个数据库引擎,都会有对应的服务:RDS for MySQL、RDS for PostgreSQL 同一个数据库按照不同的版本,会有比较严格的分支选项,在创建时指定 RDS vs 传统关系型数据库 编程接口 + 使用体验:几乎完全一致 云厂商会把功能、内部机制完整地保留下来,获得最大程度的兼容性 运维(开箱即用):智能化 + 自动化 读写分离 自动调优:自动发现性能热点,智能给出调整建议 云原生数据库 完全为云设计、充分发挥云的特点和优势 出于生态发展和降低学习难度的需要,绝大多数的云原生数据库仍然保留了 SQL 接口 不同领域的云原生数据库:关系型、键值型、文档型、图数据库、分析型 优势 更强的可扩展性 计算:可以利用云快速进行水平扩展 存储:基于原生设计的计算存储分离架构,可以支撑更大规模的数据量 更高的可用性和可靠性 原生机制:默认多副本高可用 基于原生数据同步机制的底层设计,可以方便地支持跨区域的实例复制(增强冗余 + 就近服务用户) 支持多种数据模型 兼容关系型数据库后,针对不同场景,...
2022-10-18
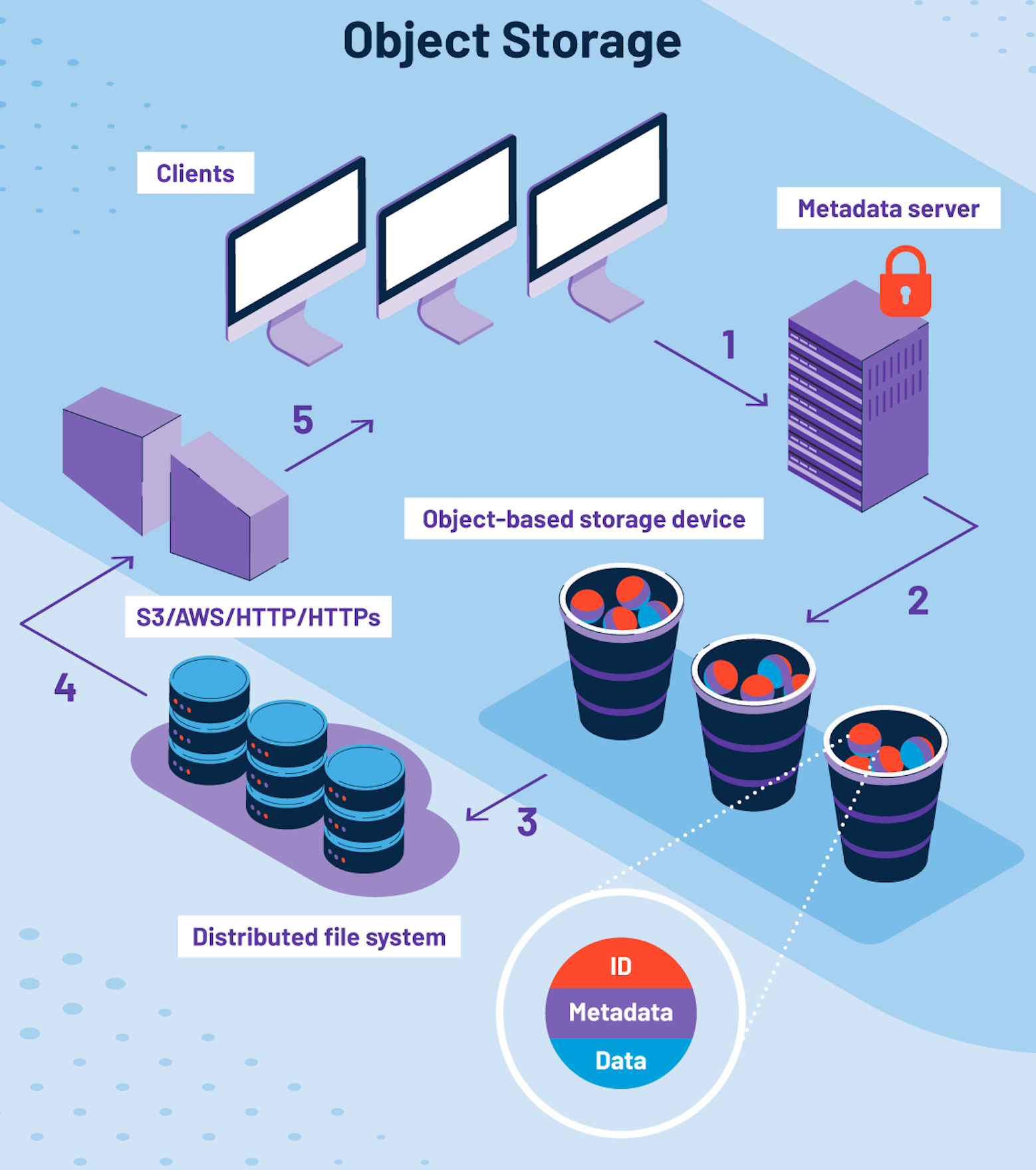
Cloud Computing - Object storage
概述 对象:任意二进制文件,包括结构化和非结构化的数据,可随时执行:上传、下载、修改、删除 对象存储 vs 云硬盘 访问接口和形式 云硬盘是挂载到虚拟机的虚拟硬盘,是通过实现 OS 的底层接口,作为虚拟机的块存储设备而存在 必须连接到相关的虚拟机,才能访问到云硬盘里面的数据 对象存储,本质上是一个网络化的服务,调用方主要通过高层的 API 或者 SDK 来和它进行交互 提供类似 HTTP 的网络接口来实现,独立性很强 S3FS 和 OSSFS 等工具可以通过模拟磁盘(基于对象存储的 API )并挂载到虚拟机 并没有改变对象存储是网络化服务的本质 云硬盘位于 IaaS 层,而对象存储位于 PaaS 层 KV 系统 vs 文件系统 Key 为存储对象的路径,Value 为存储对象的二进制文件 文件系统保存了更多的元数据(如:实现目录结构和目录操作),KV 系统的目录是通过共享前缀路径来模拟的 KV 系统的优劣 简化了对象存储的逻辑和设计,云厂商可以更聚焦于对象存储的分布式架构和服务高可用上 但对象存储中的"目录"操作的代价变高了 目录删除/重命名...

2022-10-21
Cloud Computing - Serverless
Serverless vs Container Serverless 是云计算中资源抽象的极致体现:用户专注于业务逻辑,而无需关注基础设施 Container 给予了用户很大的定制空间,按需对应用进行拆分和封装 Serverless 完全屏蔽了计算资源,引导用户不再关注基础设施,只需遵循标准的方式编写业务代码即可 更细的拆分粒度 FaaS:将每一个具有独立功能的函数,作为一个单独的服务进行部署和运行 计费机制 底层没有固化的资源,一般会按照调用次数和调用时长来计费,可以精确到毫秒 从成本上,非常适合那些偶尔触发、短时间运行的工作负载 事件模型 事件模型是 Serverless 的核心编程模型和运行逻辑,非常适合基于事件驱动的开发场景 上游:触发器 Serverless 一般都会提供多种触发器:API 触发器、OSS 触发器、MQ 触发器、定时触发器等 下游 在函数内访问其他云服务(如 RDS、MQ 等外部存储) Serverless Computing 本身是无状态的,所有持久化需求都需要借助外部存储来实现 架构范式 FaaS + MQ:关注数据流,是数据的传递和流向...
2022-10-09
Cloud Computing - Region + Availability zone
Region 云计算厂商在某个地理位置提供的所有云服务的组合,是厂商对外提供云服务的基本单位和容器 绝大多数的云服务,通常都会按照 Region 进行部署 用户使用的所有云资源,都会隶属于某个 Region,通常在创建资源时确定 每个 Region 都会有个由字母数字构成的 Region 代号(Region ID or Region Code),一般为全局唯一 Region 的设立与分布,体现了云厂商的业务重点和地区倾向 不同 Region 之间的距离,一般为数百公里或以上 Region 的选址思路 人口稠密的中心城市 - 离用户和商业更近 相对偏远的地区 - 维护成本低 选择 Region 地理位置 尽可能地靠近应用所面向的最终用户 混合云架构(本地数据中心与云端互联) 混合云的专线接入,一般以同城或短距离接入为主(控制费用 + 提高线路稳定性) Region 之间云服务的差异 同一个云在不同的 Region,所能提供的服务和规模可能是不同的 Region 的服役时间,往往与 Region 内云服务的可用性有较大的关联 新 Region - 最新的硬件和云端服务 旧 Regi...

2022-10-12
Cloud Computing - Virtual machine
体系结构 计算存储分离 传统虚拟化 对单一物理机器资源的纵向分割,计算、存储、网络等能力都是一台物理机的子集,可伸缩性有较大局限 云虚拟机 云端有大规模的专属硬件和高速的内部网络 除了核心的 CPU 和内存仍属于同一台宿主机外,硬盘和网络等可以享受云端的基础设施 在可扩展性(硬盘、网卡、公网 IP)和故障隔离方面,有很大优势 名称 阿里云:ECS - Elastic Compute Service AWS:EC2 - Elastic Compute Cloud Azure:Virtual Machines 腾讯云:CVM - Cloud Virtual Machine 网络安全组 Network Security Group 网络安全组:一层覆盖在虚拟机之外的网络防火墙,能够控制虚拟机入站流量和出站流量 网络安全组并不工作在 OS 层,是额外的一层防护,非法流量不会到达 OS 的网络堆栈,不会影响 VM 的性能 网络安全组是一种可复用的配置,可以同时应用于多个虚拟机,软件定义网络 网络安全组非常灵活,规则会动态生效 类型规格类型 具有同一类设计目的或者性能特点的虚拟机类别:...




