
FaaS - Scaling
概述
- Serverless 的弹性扩缩容可以将实例缩容为
0,并根据请求量级自动扩缩容,从而有效地提升资源利用率 极致动态扩缩容是FaaS的核心内涵,是与 PaaS 平台的核心差异 -降本增效
调度形态
- 开源的 Serverless 函数计算引擎核心,一般是基于 Kubernetes
HPA - 云厂商一般有封装好的各种底座服务,可以基于底座服务来做封装
- 云厂商
容器调度服务,通常有两种调度形态- 基于
Node调度 - 基于
容器实例的调度 -Serverless
- 基于
- 云厂商的
函数计算通常是基于容器服务的底座
Node 维度
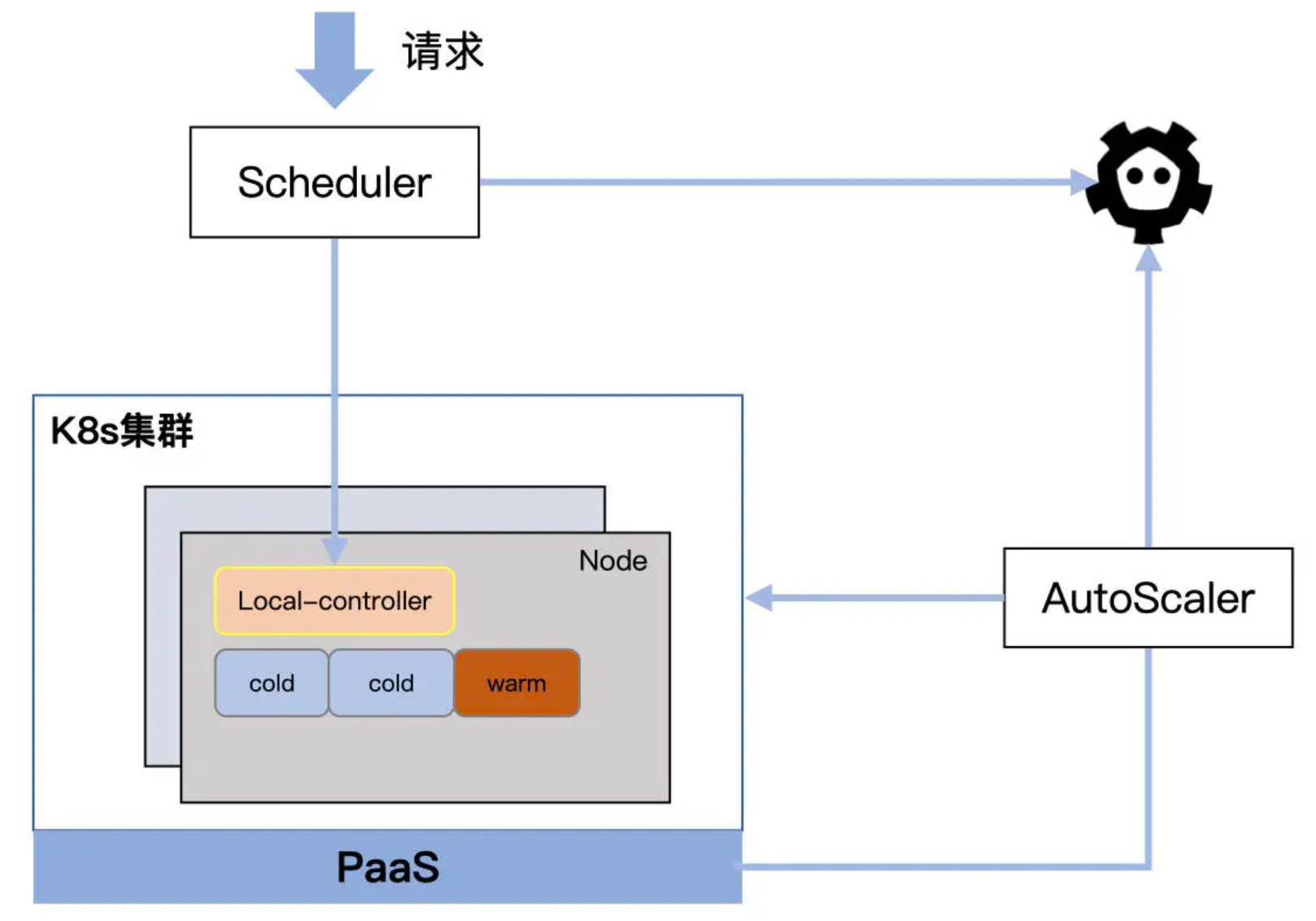
组件
Scheduler- 负责将请求打到指定的函数实例(Pod)上,同时负责为集群中的 Node 标记状态,记录到
etcd
- 负责将请求打到指定的函数实例(Pod)上,同时负责为集群中的 Node 标记状态,记录到
Local-Controller- Node 上的本地控制器,负责管理 Node 上所有
函数实例的生命周期,以DeamonSet形式存在
- Node 上的本地控制器,负责管理 Node 上所有
AutoScaler- 定期检测集群中
Node和Pod的使用情况,并根据策略进行扩缩容 - 在扩容时,向底层的
PaaS平台申请资源
- 定期检测集群中
PodCold表示该 Pod未被使用Warm表示正在被使用或者处于等待回收的状态
Node- 状态:闲置、占用
- 如果一个 Node 上
所有的 Pod都是cold,该Node为闲置状态
过程
- AutoScaler 会
定期检查集群中所有 Node - 如果检测到 Node 处于一个需要扩容的状态,则根据策略(
完全自定义)进行扩容 - 在 Node 形态下,
Pod通常会作为函数实例的通用状态- 代码以及不同运行时以
挂载的形式注入到容器内 -DeamonSet
- 代码以及不同运行时以
- AutoScaler 会在轮询时,根据 Warm Pod 的
闲置时间将其重置为 Cold Pod - 在缩容时,理想情况下,AutoScaler 可以将
Node缩容为0- 但为了应对
突发流量,会预留一部分 Buffer
- 但为了应对
缺点
- 需要
管理 Node 调度,还需要处理 Node 中 Pod 的安全隔离和使用 - 可以通过
空 Pod来提前占用,预加载一部分 Pod
Pod 维度
以
Pod为扩缩容单元,可以更加细粒度地控制函数实例的数量
HPA
The HorizontalPodAutoscaler is implemented as a Kubernetes API resource and a controller. The resource determines the behavior of the controller. The horizontal pod autoscaling controller, running within the Kubernetes control plane, periodically adjusts the desired scale of its target (for example, a Deployment) to match observed metrics such as average CPU utilization, average memory utilization, or any other custom metric you specify.
定期从 Kubernetes控制面获取资源的各项指标数据(CPU 利用率、内存使用率等)- 根据指标数据将资源数量
控制在一个目标范围内
HPA 通过控制 Deployment 或者 RC 来实现对 Pod 实际数量的控制
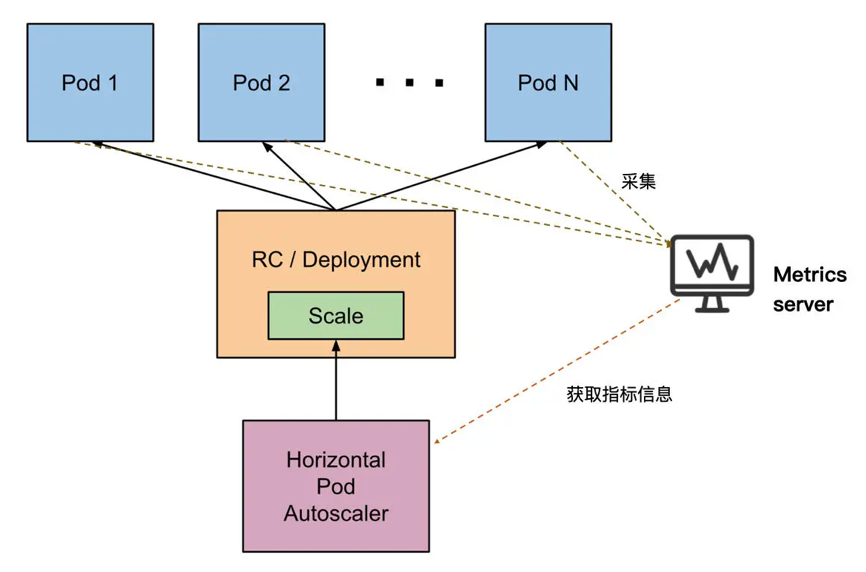
- 在 Kubernetes 中,不同的 Metric 会由对应的
Metric Server持续采集 - HPA 会
定期通过 Metric Server 的 API 或者聚合的 API Server 获取到这些 Metric 指标数据(CPU / Memory)- 然后根据
自定义的扩缩容规则计算出 Pod 的期望数量 - 最后,根据 Pod 当前的实际数量对 Deployment / RC 做出调整,使得 Pod 达到期望数量
- 然后根据
HPA 形态的扩缩容不能直接用于 Serverless
- Serverless 语义下的动态扩缩容可以让服务缩容到
0,而 HPA 不能 - HPA 是通过检测
Pod的Metric来完成 Deployment 的扩缩容- 如果 Deployment 的副本缩容到 0,则 Metric 也变为 0,与 HPA 的机制有
根本冲突
- 如果 Deployment 的副本缩容到 0,则 Metric 也变为 0,与 HPA 的机制有
Knative
从 0 到 1的扩缩容过程,需要额外的机制来支持
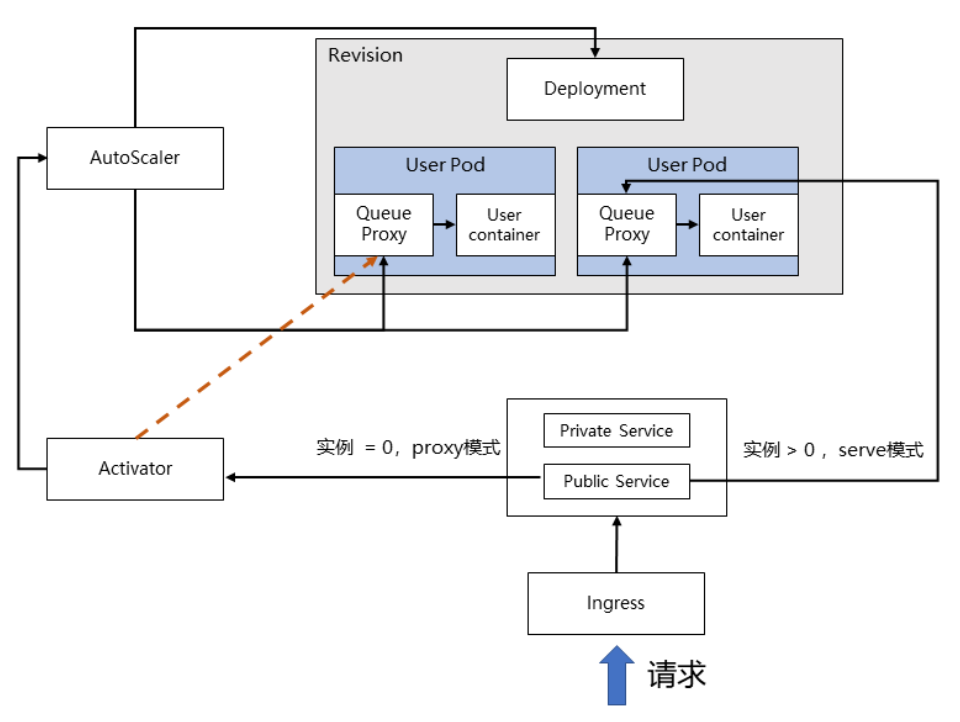
收集流量指标
- 在 Knative 中,
Revision代表一个不变的、某一时刻的代码和 Configuration 的快照 - 每个
Revision会引用一个特定的容器镜像和运行它所需要的任何特定对象(如环境变量和卷)- 再通过
Deployment控制函数实例(User Pod)的副本数
- 再通过
- 每个
User Pod中都有两个容器:Queue Proxy和User Container Queue Proxy- 每个函数实例被创建时,都会被以
Sidecar的方式将Queue Proxy注入 Queue Proxy作为每个User Pod的流量入口,负责限流和流量统计的工作AutoScaler会定时收集Queue Proxy统计的流量数据,作为后续扩缩容的重要依据
- 每个函数实例被创建时,都会被以
调整实例数量
- 当收集到
流量的指标后,AutoScaler 会通过改变实例Deployment来决定实例最终的个数 - 简单算法 - 按照当前总并发
平均划分到期望数量的实例上,使其符合设定的并发值- 当前总并发为 100,设定的并发值为 10,最终调整出来的实例数量为 100/10 = 10
- 实际上,扩缩容的实例数量还会考虑系统负载和调度周期等因素
从 0 到 1
- Knative 专门引入
Activator组件 - 用于流量暂存和代理负载 - 当 AutoScaler 将函数实例缩容为
0时,会控制Activator作为实例为 0 时的流量接收入口 Activator在收到流量后,会将请求和信息暂时缓存,并主动告知AutoScaler进行扩容- 直到
成功扩容出来函数实例,Activator 才会将缓存的流量转发到新生成的函数实例上
- 直到
扩缩容模型
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2023-02-09
FaaS - Cold Start
触发时机 类似于 LoadingCache 首次请求 容器实例在服务请求后被回收 启动过程 容器创建 当所有容器实例都在处理请求时,需要向集群申请创建新的容器 函数计算平台会支持多种语言的运行时 这些运行时一般来说会打包成一个镜像,然后以 DeamonSet 的方式运行在 Kubernetes 中 在冷启动时,会根据不同的参数请求,动态挂载所需的运行时到对应的运行路径 代码包 / 层依赖 是整个冷启动耗时比较长的过程 函数计算本身不具备持久化的能力,代码包和层依赖通常都是从其它存储服务端拉取 代码包通常是压缩包的形式,下载到本地后,再解压 环境变量 / 参数文件 耗时相对较短 主流的函数计算平台往往提供了环境变量注入的能力,发生在冷启动阶段 运行时以及容器本身还需要准备一些参数配置文件 VPC 打通 / 资源准备 如果用户还为函数接入了私有网络,还需要为容器进行一些 VPC 网络打通的初始化工作 如果用户使用了类似分布式文件系统等功能,还需要进行挂载 运行时初始化 通常指的是云厂商标准的 Runtime 环境的启动过程 受编程语言类型的影响比较大(JV...

2023-02-14
FaaS - WebIDE
架构 组成 蓝色部分 WebIDE 客户端的核心 Run VS Code on any machine anywhere and access it in the browser 绿色部分 将 WebIDE 与 FaaS 结合的核心 橘色部分 Serverless 形态下的必备支撑服务 过程 用户在 VS Code 的前端页面向后端发出函数在线编辑的请求 服务端,即 FaaS 的 Controller 在接收到请求并验证权限后,再转给 VS Code Server 容器实例 VS Code Server 容器实例会获取用户代码,然后再加载 FaaS 的资源调度系统 根据目前 Container Pool 中的资源现状,动态扩缩容 WebIDE Pod 资源 VS Code Server 根据用户请求,会调用 Serverless Extension BE 基于此时语言的环境,执行操作,并将执行结果返回给 Client 端 注意 可以将 Serverless Extension 插件提前集成在 VS Code Server 的镜像中 FaaS Runtime 依据原来函数计...

2023-02-13
FaaS - Function Invoke
函数拆分 成本 云函数的收费:调用次数、公网流量、占用资源时间(最贵) 复用 组件化 性能 对于非串行的功能,拆分成多个函数可以提高并发性 调用方式 同步、异步、编排(具有调度和管理的语义) 同步 需要注意调用延迟和超时带来的费用成本 直接调用 使用云厂商提供的 SDK,调用指定的函数,实现直接调用 12345678import fc2client = fc2.Client( endpoint='<Your Endpoint>', accessKeyID='<Your AccessKeyID>', accessKeySecret='<Your AccessKeySecret>')// 同步调用client.invoke_function('service_name', 'function_name') 网关调用 通过 API 网关调用函数,借助 API 网关来...
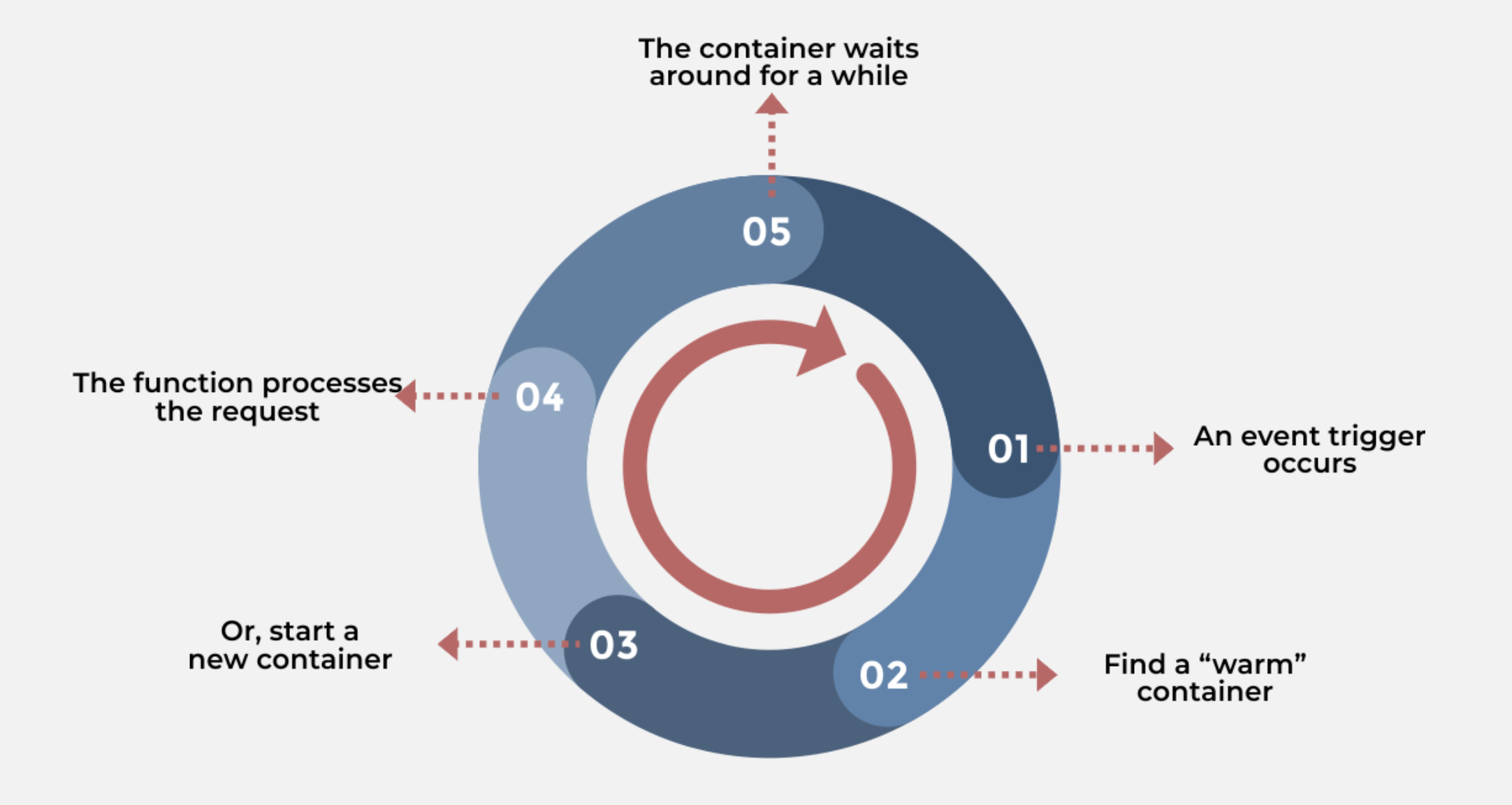
2023-02-06
FaaS - Life Cycle
Serverless概述 Serverless 是一种架构设计理念,并非一个具体的编程框架、类库或者工具 Serverless = FaaS + BaaS 构建和运行不需要服务器管理的应用程序 描述一种更细粒度的部署模型 将应用程序打包上传到 Serverless 平台,然后根据实际需求,执行、扩展和计费 Serverless 能够实现业务和基础设施的分离 通过多种服务器无感知技术,将基础设施抽象成各种开箱即用的服务 以 API 接口的方式提供给用户按需调用,真正做到按需伸缩、按量收费 场景 形成了以函数计算、弹性应用、容器服务为核心的产品形态 函数计算 - 面向函数 用户只需关注函数层级的代码,用于解决轻量型、无状态、有时效的任务 Serverless 应用托管 - 面向应用 应用只需要关注应用本身 与微服务结合,融合应用治理、可观测 降低了新应用的构建成本,老应用的适配改造成本 Serverless 应用服务 - 面向容器 在不改变当前 kubernetes 的前提下,由于不再需要关注 Node,降低了维护成本 FaaS Life Cycle用户视角 开发...
2023-02-07
FaaS - Trigger
事件 事件为系统运行期间发生的动作或者发生的事情,而函数计算,提供了一种事件驱动的计算模型 CloudEvents 期望通过一种通用的格式描述事件数据的规范,以提供跨服务、平台和系统的互操作性 国内云厂商的事件规范程度:在其中一家云产品上开发了函数,一般都需要进行简单的适配才能迁移 CNCF Serverless 工作组针对函数和工作流均定义了相关的格式规范和原语 单函数的事件触发 多个简单函数通过异步调用的方式形成事件触发 复杂场景下通过 WorkFlow 来进行编排的事件交互 触发器概述 由事件驱动连接上下游服务的关系组合称为触发器 函数计算由云函数和触发器组成 触发器描述了一组关系和规则,包括核心要素:事件源、目标函数、触发条件 事件源:事件的生产者 目标函数:事件的处理者 触发条件:当触发条件满足时,就会通知函数计算引擎,调度对应的目标函数执行 触发器的元数据可以由服务方持久存储,也可以由函数托管平台和服务方共同持有 类型集成原则 区别:事件源和事件的规则存储在哪里,以及从哪里触发 单向集成触发器 双向集成触发器 代理集成触发器 设计触发器的主要考虑:事件源和函数计算的...

2023-02-08
FaaS - Advanced Attributes
公共能力 将函数依赖的公共库提炼到层,以减少部署、更新时的代码包体积 对于支持层功能的运行时,函数计算会将特定的目录添加到运行时语言的依赖包搜索路径中 对于自定义层,需要将所有内容打包到一个压缩包,并上传到函数计算平台 函数计算运行时会将层的内容解压并部署到特定的目录 层功能的好处 函数程序包更小 避免在制作函数 zip 包和依赖项过程中出现未知的错误 可以在多个函数中引入使用,减少不必要的存储资源浪费 上传层之后,函数计算会将层的 zip 包上传到对象存储 当调用函数执行时,会从对象存储中下载层的 zip 包并解压到特定目录 应用程序只需要访问特定目录,就能读取层的依赖和公共代码 注意:后序的层会覆盖相同目录下的文件 快速迭代 标准运行时 / 自定义镜像 函数计算系统初始化执行环境之前,会扮演该函数的服务角色,获得临时用户名和密码并拉取镜像 镜像拉取成功后,会根据指定的启动命令、参数和端口,启动自定义的 HTTP Server 该 HTTP Server 会接管函数计算系统所有请求的调用 调用方式不同:事件函数 / HTTP 函数 在创建函...




