
LLM Deploy - ChatGLM3-6B
LLM 选择
核心玩家
厂家很多,但没多少真正在研究技术 - 成本 - 不少厂商是基于 LLaMA 套壳
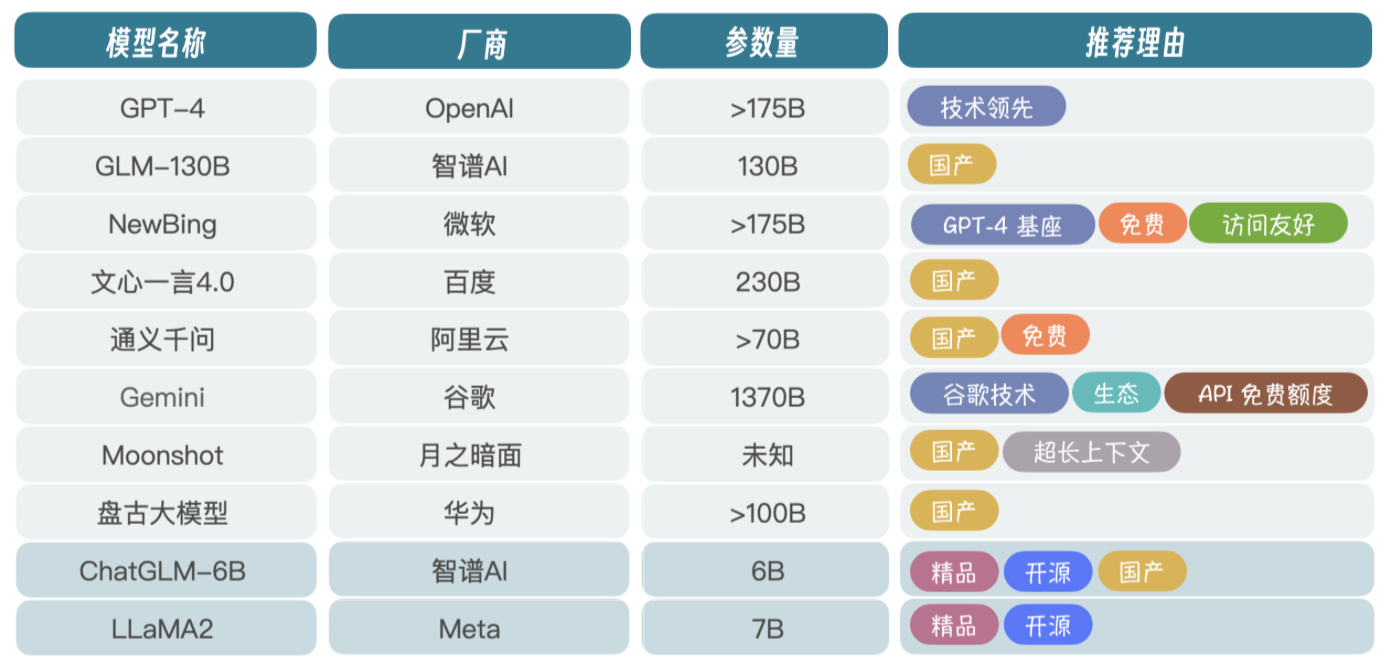
ChatGLM-6B
- ChatGLM-6B 和 LLaMA2 是比较热门的开源项目,国产 LLM 是首选
- 企业布局 LLM
- 选择 MaaS 服务,调用大厂 LLM API,但会面临数据安全问题
- 选择开源 LLM,自己微调、部署、为上层应用提供服务
- 企业一般会选择私有化部署 + 公有云 MaaS 的混合架构
- 在国产厂商中,从技术角度来看,智谱 AI 是国内 LLM 研发水平最高的厂商
- 6B 的参数规模为 62 亿,单张 3090 显卡就可以进行微调和推理
- 企业预算充足(百万以上,GPU 费用 + 商业授权)
- 可以尝试 GLM-130B,千亿参数规模,推理能力更强
- GLM-130B 轻量化后,可以在 3090 × 4 上进行推理
- 训练 GLM-130B 大概需要 96 台 A100(320G),历时两个多月
计算资源
- 适合 CPU 计算的 LLM 不多
- 有些 LLM 可以在 CPU 上进行推理,但需要使用低精度轻量化的 LLM
- 但在低精度下,LLM 会失真,效果较差
- 要真正体验并应用到实际项目,需要 GPU
ChatGLM3-6B
简介
- ChatGLM-6B 目前已经发展到第 3 代 ChatGLM3-6B - 中英文推理 + 数学 + 代码等推理能力
- 在语义、数学、推理、代码、知识等不同角度的数据集上测评
- ChatGLM3-6B-Base 在 10B 以下的基础模型中是性能最强的
- 除此之外,还具有 8K、32K、128K 等多个长文本理解能力版本
环境
| Key | Value |
|---|---|
| OS | Ubuntu / CentOS |
| Python | 3.10~3.11 |
| Transformers | 4.36.2 |
| Torch | ≥ 2.0 - 最佳的推理性能 |
算力
| Key | Value |
|---|---|
| CPU 运行 | 内存 ≥ 32GB - 很慢,不推荐 |
| 低精度运行 | 内存 ≥ 8GB 显存 ≥ 5GB |
| 高精度运行 | 内存 ≥ 16GB 显存 ≥ 13GB |
代码
1 | $ git clone https://github.com/THUDM/ChatGLM3 |
依赖
1 | $ cd ChatGLM3 |

Git
Git Large File Storage
1 | $ sudo apt-get install git-lfs |
模型
1 | $ git clone https://huggingface.co/THUDM/chatglm3-6b |
启动
命令行
修改 basic_demo/cli_demo.py
1 | MODEL_PATH = os.environ.get('MODEL_PATH', '../chatglm3-6b') |
1 | $ cd basic_demo/ |

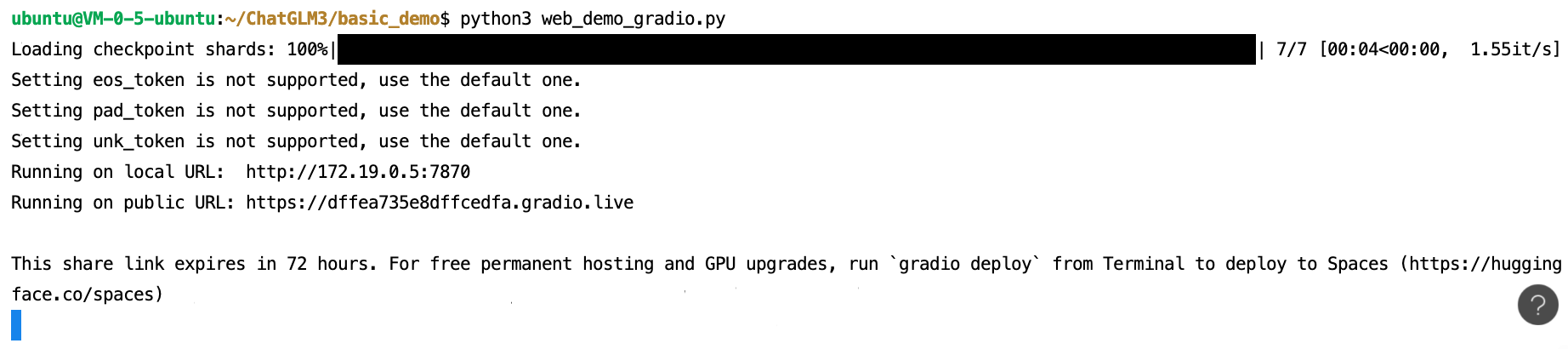
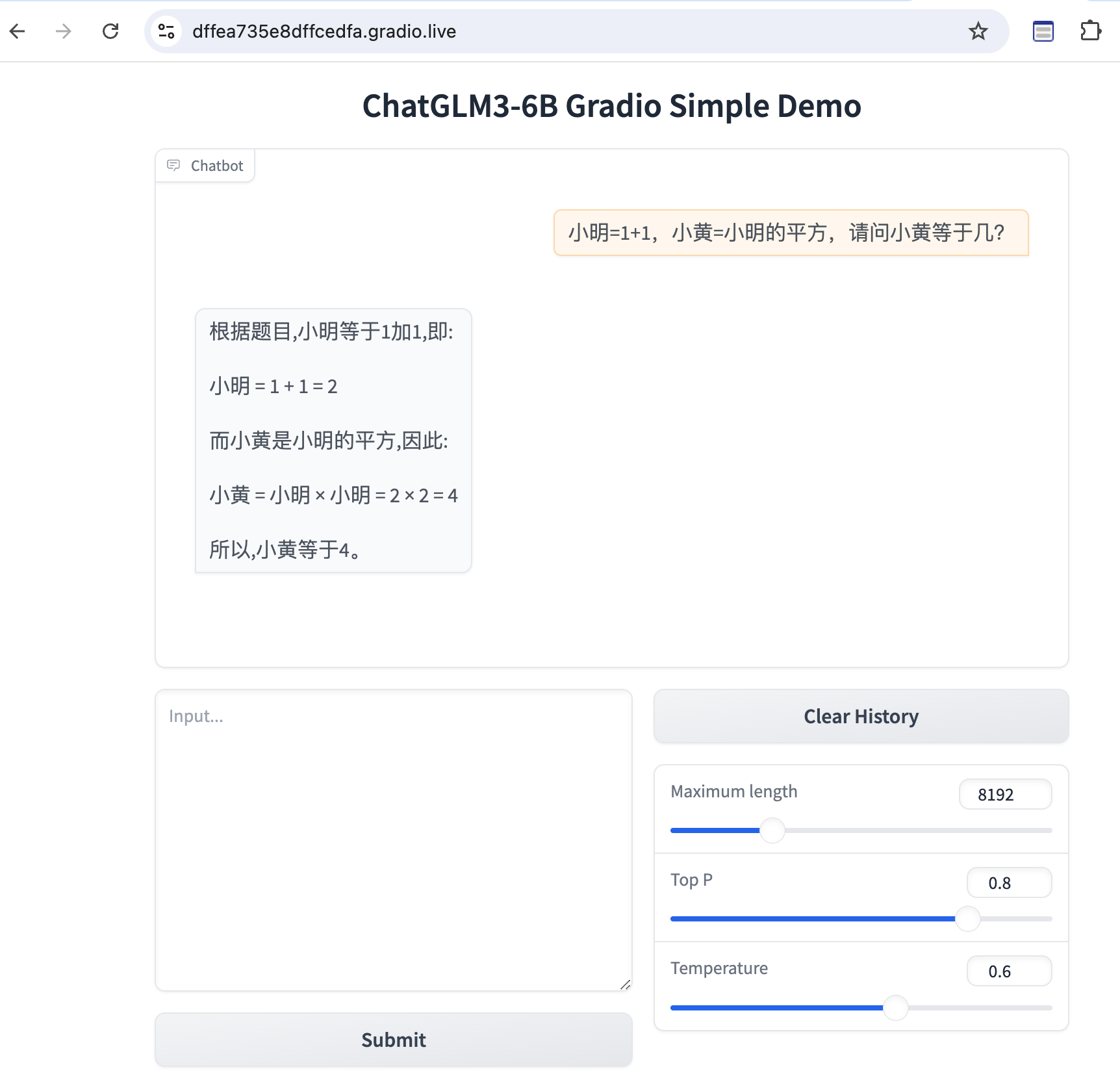
Web Console
修改 basic_demo/web_demo_gradio.py
1 | MODEL_PATH = os.environ.get('MODEL_PATH', '../chatglm3-6b') |
python3 web_demo_gradio.py
Composite
支持 Chat、Tool、Code Interpreter
1 | $ cd composite_demo |
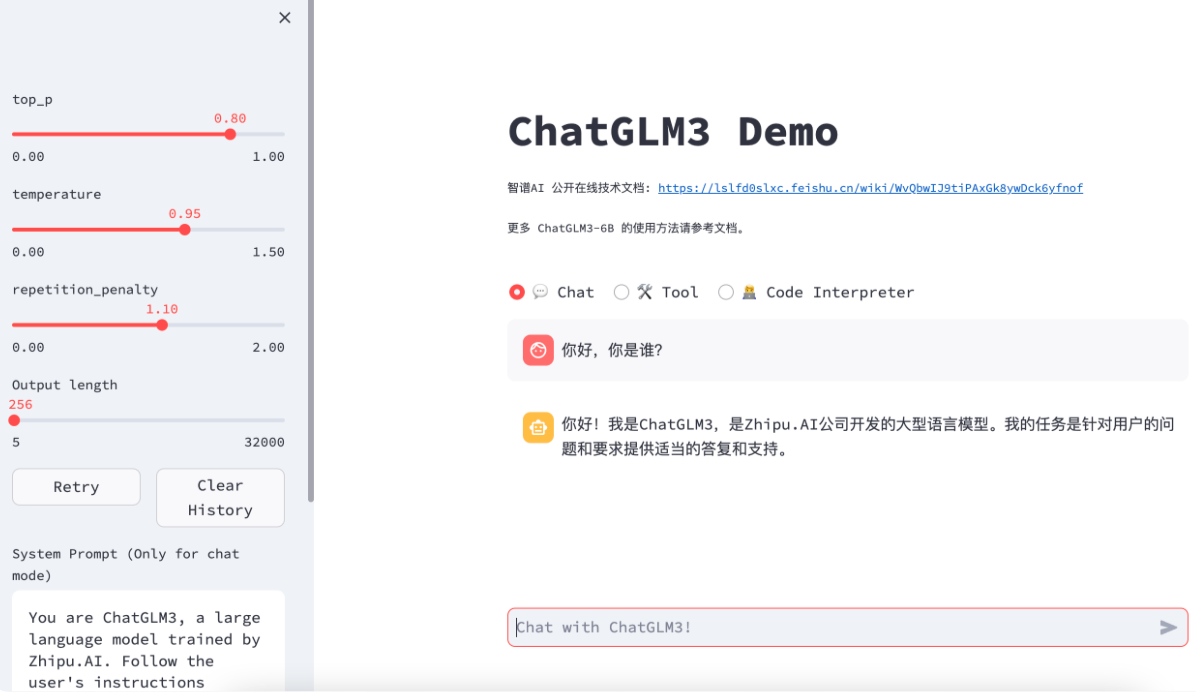
精度
- 默认情况下,模型以 FP16 精度加载,大概需要 13GB 显存
- 也可以通过 CPU 启动,大概需要 32GB 内存
- 如果显存不足,可以在 4-bit 量化下运行,大概需要 6GB 显存
超参数
- 超参数用来控制模型的推理准确度
- LLM 推理每次给的回答可能都不一样,因此 LLM 不能用于处理精确度要求很高的任务
ChatGLM3-6B
| Parameter | Value |
|---|---|
| max_length | 模型的总 Token 限制 - 输入和输出 |
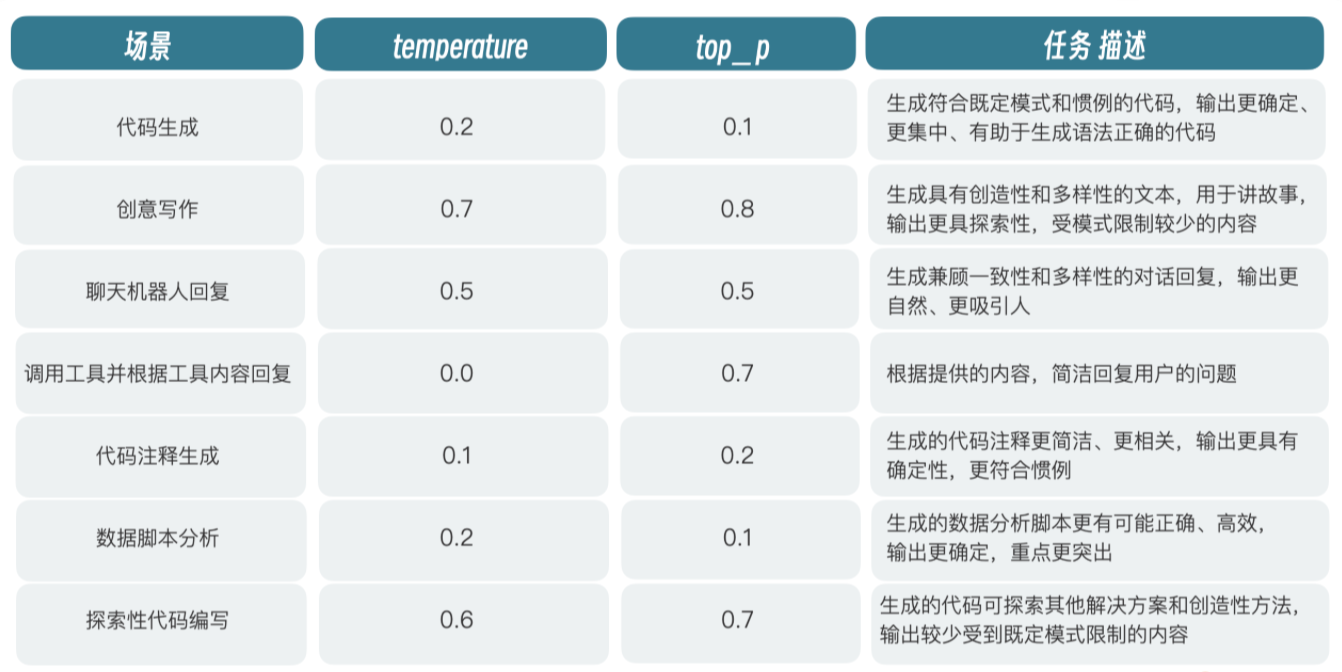
| temperature | 模型的温度 - 调整单词的概率分布 在较低温度下,模型更具有确定性 - 数字越小,给出的答案越精确 |
| top_p | 模型采样策略参数 每一步只从累计概率超过某个阈值 p 的最小单词集合中进行随机采样 不考虑其它低概率的词,只关注分布的核心部分,忽略尾部 |
Prompt
在对话场景中,有且仅有三种角色
| Role | Desc |
|---|---|
| system | 系统信息,出现在消息的最前面,可以指定回答问题的角色 |
| user | 我们提出的问题 |
| assistant | LLM 给出的回复 |
在代码场景中,有且仅有 user、assistant、system、observation 四种角色
- observation 是外部返回的结果 - 调用外部 API、代码执行逻辑等返回结果
- observation 必须放在 assistant 之后
1 | <|system|> |
- 当前阶段的 LLM 经过训练后,都可以遵循系统消息
- 系统消息不算用户对话的一部分,与用户隔离
- 系统消息可以控制 LLM 与用户的交互范围
- 在 system 角色指定模型充当 Java 技术专家
- 则可以指导 LLM 的输出偏向于 Java 技术范围
- 可以防止用户进行输入注入攻击
- 在进行多轮对话时,每次新的对话都会把历史对话带进去
- 如果在前面的对话中,告诉 LLM 错误的提示
- 那么这些错误的提示会在后续的对话中被当成正确的上下文带进去
- 基于自回归的模型,会根据上下文进行内容推理,因此可能会生成错误内容
- 角色可以使内容更加容易区分,增加注入攻击的复杂度
- 只能尽量减少,无法完全避免
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2024-06-27
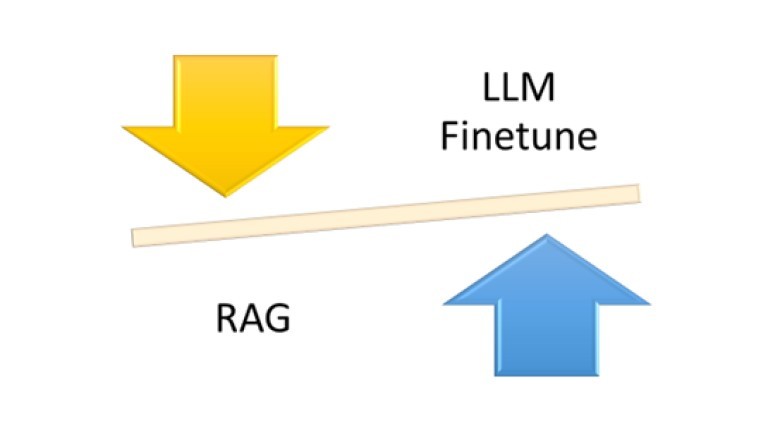
LLM - LangChain + RAG
局限 大模型的核心能力 - 意图理解 + 文本生成 局限 描述 数据的及时性 大部分 AI 大模型都是预训练的,如果要问一些最新的消息,大模型是不知道的 复杂任务处理 AI 大模型在问答方面表现出色,但不总是能够处理复杂任务AI 大模型主要是基于文本的交互(多模态除外) 代码生成与下载 根据需求描述生成对应的代码,并提供下载链接 - 暂时不支持 与企业应用场景的集成 读取关系型数据库里面的数据,并根据提示进行任务处理 - 暂时不支持 在实际应用过程中,输入数据和输出数据,不仅仅是纯文本 AI Agent - 需要解析用户的输入输出 AI Agent AI Agent 是以 LLM 为核心控制器的一套代理系统 控制端处于核心地位,承担记忆、思考以及决策等基础工作 感知模块负责接收和处理来自于外部环境的多样化信息 - 文字、声音、图片、位置等 行动模块通过生成文本、API 调用、使用工具等方式来执行任务以及改变环境 LangChain - 开源 + 提供一整套围绕 LLM 的 Agent 工具 AI Agent 很有可能在未来一段时间内成为 AI 发展的一...
2024-06-30
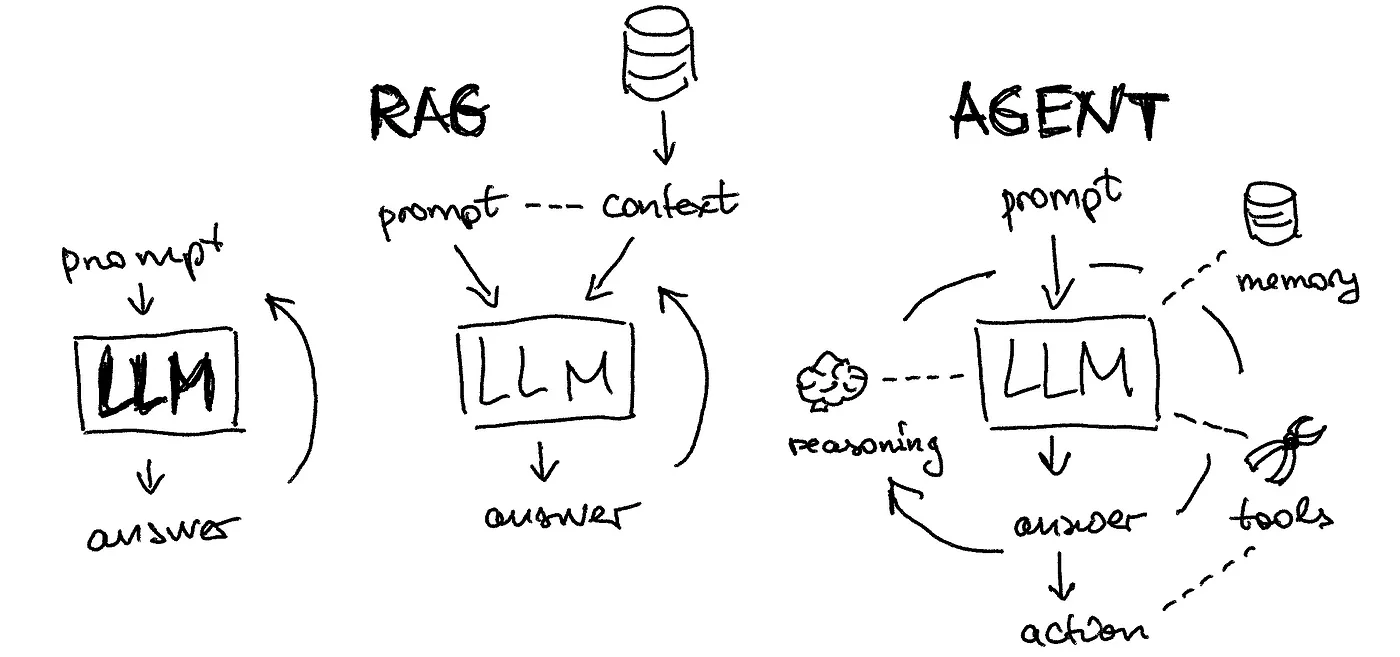
LLM RAG - ChatGLM3-6B + LangChain + Faiss
RAG 使用知识库,用来增强 LLM 信息检索的能力 知识准确 先把知识进行向量化,存储到向量数据库中 使用的时候通过向量检索从向量数据库中将知识检索出来,确保知识的准确性 更新频率快 当发现知识库里面的知识不全时,可以随时补充 不需要像微调一样,重新跑微调任务、验证结果、重新部署等 应用场景 ChatOps 知识库模式适用于相对固定的场景做推理 如企业内部使用的员工小助手,不需要太多的逻辑推理 使用知识库模式检索精度高,且可以随时更新 LLM 基础能力 + Agent 进行堆叠,可以产生智能化的效果 LangChain-Chatchat组成模块 模块 作用 支持列表 大语言模型 智能体核心引擎 ChatGLM / Qwen / Baichuan / LLaMa Embedding 模型 文本向量化 m3e-* / bge-* 分词器 按照规则将句子分成短句或者单词 LangChain Text Splitter 向量数据库 向量化数据存储 Faiss / Milvus Agent Tools 调用第三方...
2024-06-29
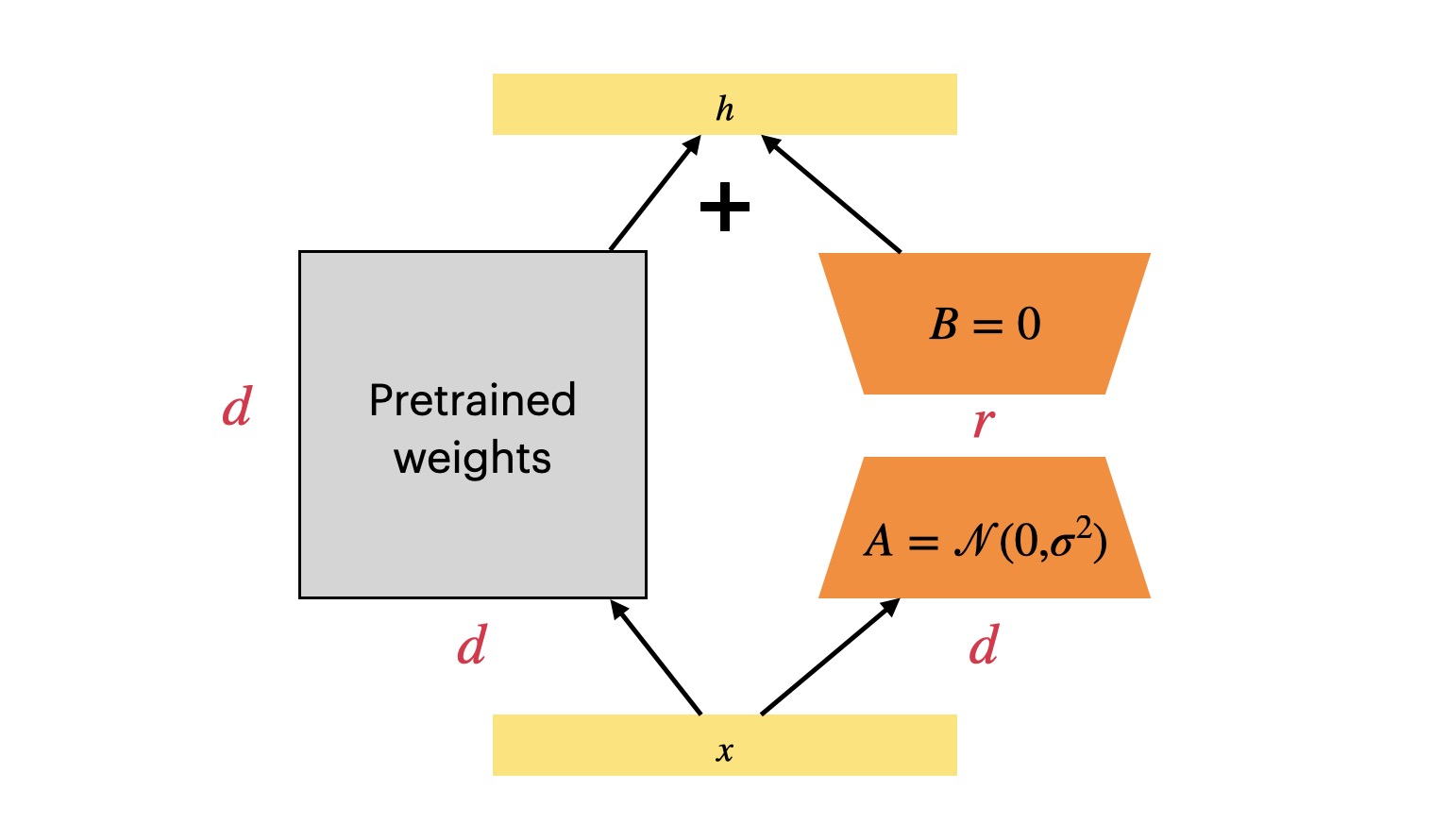
LLM PEFT - ChatGLM3-6B + LoRA
通用 LLM 千亿大模型(130B、ChatGPT)和小规模的大模型(6B、LLaMA2)都是通用 LLM 通用 LLM 都是通过常识进行预训练的 在实际使用过程中,需要 LLM 具备某一特定领域知识的能力 - 对 LLM 的能力进行增强 增强方式 Method Desc 微调 让预先训练好的 LLM 适应特定任务或数据集的方案,成本相对低LLM 学会训练者提供的微调数据,并具备一定的理解能力 知识库 使用向量数据库或者其它数据库存储数据,为 LLM 提供信息来源外挂 API 与知识库类似,为 LLM 提供信息来源外挂 互不冲突,可以同时使用几种方案来优化 LLM,提升内容输出能力 LoRA / QLoRA / 知识库 / API LLM Performance = 推理效果 落地过程 Method Pipeline 微调 准备数据 -> 微调 -> 验证 -> 提供服务 知识库 准备数据 -> 构建向量库 -> 构建智能体 -> 提供服务 API 准备数据 -&g...
2024-08-04
RAG - LangChain
Practice LangChain RAG https://github.com/langchain-ai/rag-from-scratch RAG 如何随着长期 LLM 而改变 Is RAG Really Dead? https://www.youtube.com/watch?v=SsHUNfhF32s 自适应 RAG 根据复杂程度动态地将查询路由到不同的 RAG 方法 - Command-R @ LangGraph Adaptive RAG https://www.youtube.com/watch?v=04ighIjMcAI Code https://github.com/langchain-ai/langgraph/blob/main/examples/rag/langgraph_adaptive_rag_cohere.ipynb Paper https://arxiv.org/abs/2403.14403 Adaptive RAG 在循环单元测试中自我纠正检索错误,以确定文档相关性并返回到网络搜索 在 LangGraph 中实现 Mistral 7B + Ol...

2024-08-08
RAG - Frameworks
Overview Retrieval-Augmented Generation (RAG) is an AI framework that enhances the capabilities of large language models (LLMs) by incorporating external knowledge sources. It helps overcome limitations such as knowledge cutoff dates and reduces the risk of hallucinations in LLM outputs. RAG works by retrieving relevant information from a knowledge base and using it to augment the LLM’s input, allowing the model to generate more accurate, up-to-date, and contextually relevant responses. Haystack Hays...
2024-07-03
LLM Core - Machine Learning Algorithm
线性回归概述 线性回归是一种预测分析技术,用于研究两个或者多个变量之间的关系 尝试用一条直线(二维)或者一个平面(三维)的去拟合数据点 这条直线或者平面,可以用来预测或者估计一个变量基于另一个变量的值 数学 假设有一个因变量 y 和一个自变量 x 线性回归会尝试找到一条直线 y=ax+b a 为斜率,而 b 为截距 以便这条直线尽可能地接近所有数据点 $$y=ax+b$$ sklearn 房价预测 - 房价是因变量 y,而房屋面积是自变量 x 12345678910111213141516171819202122232425import matplotlib.pyplot as pltimport numpy as npfrom sklearn.linear_model import LinearRegression# 定义数据X = np.array([35, 45, 40, 60, 65]).reshape(-1, 1) # 面积y = np.array([30, 40, 35, 60, 65]) # 价格# 创建并拟合模型model = LinearRegre...




