
RAG -Principle
LLM 局限
- 当设计一个 LLM 问答应用,模型需要处理用户的领域问题时,LLM 通常表现出色
- 但有时提供的答案并不准确,甚至出现错误
- 当用户需要获取实时信息时,LLM 无法及时提供最新的答案
- LLM 在知识、理解和推理方面展现了卓越的能力,在复杂交互场景中表现尤为突出
- LLM 存在无法忽略的局限性
LLM 局限
| Limitation | Desc |
|---|---|
| 领域知识缺乏 | LLM 的知识来源于训练数据,主要为公开数据集,无法覆盖特定领域或高度专业化的内部知识 |
| 信息过时 | LLM 难以处理实时信息,训练过程耗时且成本高昂,模型一旦训练完成,就难以处理和获取信息 |
| 幻觉 | 模型基于概率生成文本,有时会输出看似合理但实际错误的答案 |
| 数据安全 | 需要在确保数据安全的前提下,使 LLM 有效利用私有数据进行推理和生成 |
RAG 应运而生
- 将非参数化的外部知识库和文档与 LLM 结合
- RAG 使 LLM 在生成内容之前,能够先检索相关信息
- 弥补 LLM 在知识专业性和时效性的不足
- 在确保数据安全的同时,充分利用领域知识和私有数据
选择 RAG 而不是直接将所有知识库数据交给 LLM
- LLM 能够处理的 Token 数有限,输入过多的 Token 会增加成本
- 提供少量相关的关键信息能够带来更优质的回答
将相关的实时信息转化为知识库内容,并通过检索模块检索到与用户查询高度相关的文档片段,提供更有价值的回答

RAG 定义
- RAG 是一种结合检索和生成的 NLP 模型架构
- RAG 由 Facebook AI 于 2022 提出,主要是为了提升生成式模型在处理开放域问答、对话生成等复杂任务中的性能
- RAG 通过引入外部知识库
- 利用检索模块(Retriever)从大量文档中提取相关信息
- 然后将这些信息传递给生成模块(Generator),从而生成更准确且有用的回答
- 核心思想 - 通过检索与生成的有机结合,弥补 LLM 在处理领域问题和实时任务时的不足
- 传统的生成模型在面对复杂问题时,由于知识储备不足,会生成出错误或无关的回答
- RAG 通过 Retriever 获取相关的背景信息,使 Generator 能够参考这些信息,生成更具可信度和准确性的答案
- 增强了生成内容的准确性,提高了 LLM 在应对特定领域知识和动态信息的适应能力
RAG 应用
RAG 的应用有效优化了 LLM 的固有缺陷,为 LLM 应用提供了更高的可靠性和场景可落地性
- RAG 结合了检索和生成,满足了 LLM 在实时性、高准确性和领域专有知识获取的需求
- 企业或领域的知识管理与问答系统
- RAG 能实时从企业或领域的私有知识库中检索相关信息
- 确保生成的回答不仅准确且符合企业内部的最新动态,解决了 LLM 在处理特定领域知识时的局限性
- 客户支持与智能客服系统
- RAG 可以动态地将用户的询问与最新的产品信息、客服知识等外部数据相结合
- 生成的回答更加贴合用户的实际需求,且满足企业需求
- 医疗 + 金融
- 对数据准确性和时效性有极高的要求,RAG 通过实时检索最新的研究成果、市场动态或文档资料
- RAG 确保生成的内容不仅基于最新信息,同时具备领域专有知识的深度分析能力
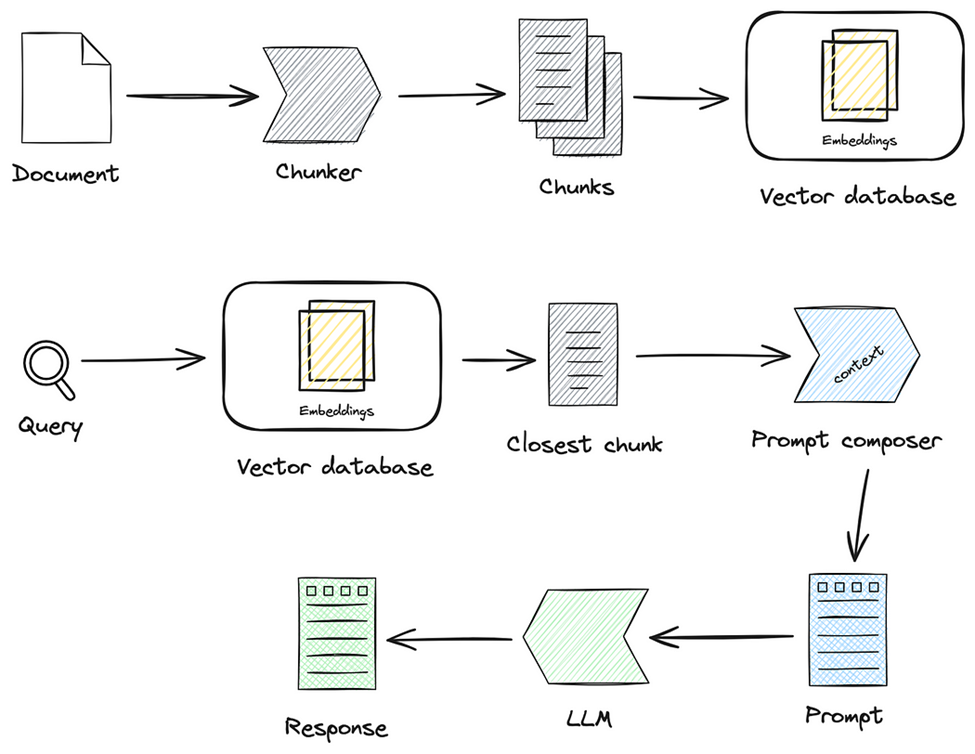
RAG 流程
实现了检索和生成的有机结合,显著提升了 LLM 在领域任务中的准确性和实时性

Indexing
将外部文档转化为可检索的向量,支撑后续的检索和生成环节
- 将各类数据源及其格式统一解析为纯文本格式
- 根据文本的语义或结构,将文档分割成为小而语义完整的文本块(chunk)
- 确保系统能够高效检索和利用 chunk 中包含的信息
- 然后,使用文本嵌入模型(embedding model),将这些 chunk 进行向量化
- 生成高维稠密向量,转换为计算机能够理解的语义表示
- 最后,将这些向量存储在向量数据库(vector database)中,并构建索引,完成知识库的构建
Retrieval
连接用户查询和知识库
- 将用户查询(query)通过同样的文本嵌入模型(embedding model)转换为向量表示
- 将查询(query)映射到知识库内容相同的向量空间中
- 通过相似度度量方法,Retriever 从向量数据库中筛选出与 query 最相关的前 K 个 chunk
- 通过相似性搜索,Retriever 有效获取了与 query 切实相关的外部知识
- 为生成阶段提供了精确且有意义的上下文支持
- 这些 chunk 将作为生成阶段输入的一部分
Generation
具备领域知识和私有信息的精确内容生成
- 检索到的文本块(chunk)与原始查询(query)共同构成增强提示词(prompt),输入到 LLM
- LLM 生成精确且具备上下文关联的回答
- 符合用户的查询意图 + 充分利用检索到的上下文信息
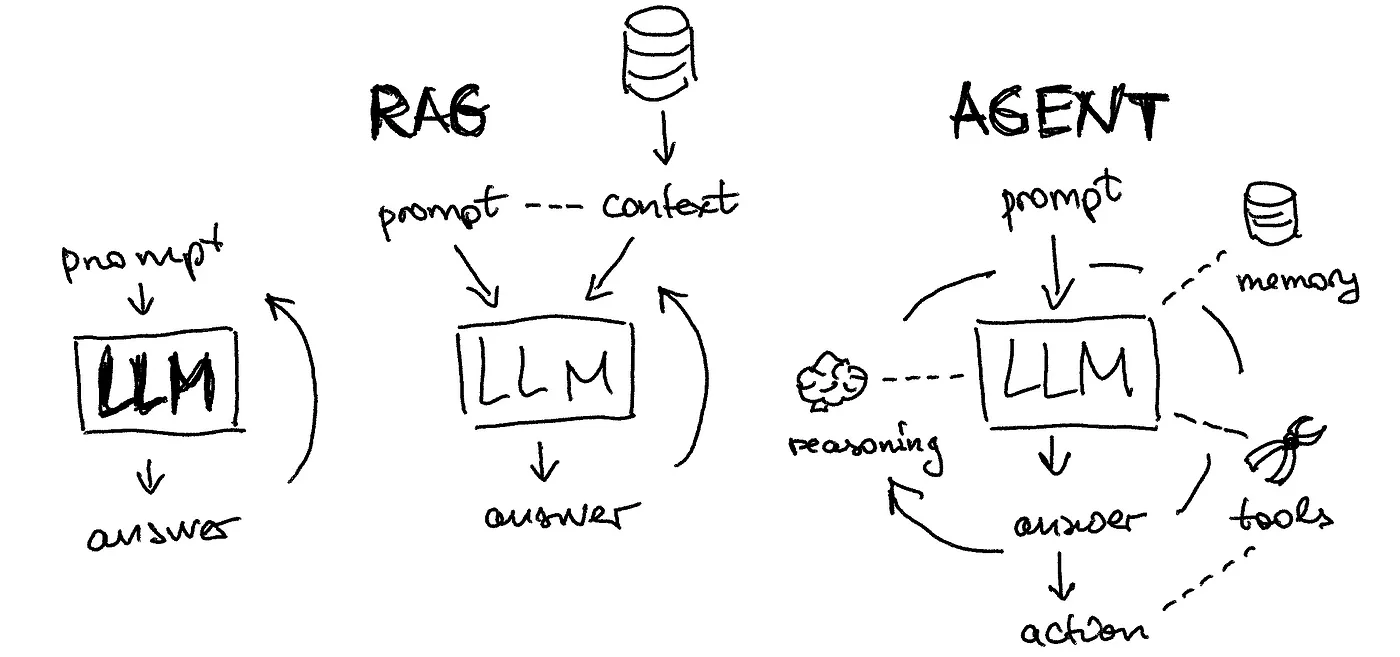
RAG vs Fine-tuning

- 在 LLM 专业领域场景的应用中,RAG(外部知识) 和 Fine-tuning(领域能力) 都是可行的选择
- RAG - 外部知识 - 动态响应 - 频繁更新
- 场景 - 频繁处理实时信息、回答复杂且依赖外部知识的问题、回答需具备可解释性
- RAG 通过结合检索系统和生成模型,能够实时利用最新信息,生成上下文相关且准确的答案
- Fine-tuning - 领域能力 - 深度优化推理
- 场景 - 需求稳定、领域知识固定、不需要频繁更新知识库的场景
- 通过使用特定领域的数据对模型进行深度优化
- Fine-tuning 可以提升模型在特定任务或领域中的推理能力,确保输出内容的专业性和一致性
如果即需要利用最新的外部知识,又需要保持高水平的领域推理能力,可以结合 RAG 和 Fine-tuning,以实现最佳的性能和效果
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2024-08-07
RAG - Data Processing
数据存储 LLM 变成生产力,有两个制约因素 - 交互过程中的长文本 + 内容的实时更新 在传统的应用开发中,数据存储在数据库中,保留了应用的全部记忆 在 AI 时代,向量数据库充当了这一角色 在 RAG 系统中,数据被转换为高维向量形式,使得语言模型能够进行高效的语义相似度计算和检索 在向量数据库中,查找变成了计算每条记录的向量近似度,然后按照分值倒序返回结果 RAG 就如何存储向量的方法论,根据不同的实现策略,衍生出了不同的 RAG 技术 利用图结构表示和检索知识的 GraphRAG 结合知识图谱增强生成能力的 KG-RAG - Knowledge Graph Augmented Generation AI 应用的数据建模强调的是数据的语义表示和关联,以支持更灵活的查询和推理 高质量的数据处理,不仅影响检索的准确性,还直接决定了 LLM 生成内容的质量和可靠性 Embedding 将所有内容转成文本 + 额外数据(用来关联数据) 选择一个 Embedding 模型,把文本转成向量,并存储到向量数据库中 厂商 LLM Embedding 国产 百度 文心一言 Embeddi...
2024-08-12
RAG - Vector Stores
Embedding Vector Store概述 在 AI 时代,文字、图像、语音、视频等多模态数据的复杂性显著增加 多模态数据具有非结构化和多维特征 向量表示能够有效表示语义和捕捉潜在的语义关系 促使向量数据库成为存储、检索和分析高维向量的关键工具 Qdrant / Milvus 优势 SQL vs NoSQL 传统数据库通常分为关系型(SQL)数据库和非关系型(NoSQL)数据库 存储复杂、非结构化或半结构化信息的需求,主要依赖于 NoSQL 的能力 Store Desc Note Key-Value 用于简单的数据存储,通过 Key 来快速访问数据 精准定位信息 Document 用于存储文档结构的数据,如 JSON 格式 复杂的结构化信息 Graph 用于表示和存储复杂的关系数据,常用于社交网络、推荐等场景 复杂的关系数据 Vector 用于存储和检索基于向量表示的数据,用于 AI 模型的高维度和复杂的嵌入向量 语义最相关的数据 向量数据库的核心在于能够基于向量之间的相似性,能够快速、精确地定位和检索数据 向量数据库不仅为嵌入向量提供了...
2024-08-11
RAG - KG-RAG
Knowledge Graph 知识图谱也称为语义网络,表示现实世界实体的网络,并说明它们之间的关系 信息通常存储在图形数据库中,并以图形结构直观呈现 知识图谱由三部分组成 - 节点 + 边 + 标签 Why 降噪 + 提召 + 提准 传统 RAG 中的 Chunking 方式会召回一些噪音的 Chunk 引入 KG,可以通过实体层级特征来增强相关性 传统 RAG 中的 Chunk 之间是彼此孤立的,缺乏关联,在跨文档回答任务上表现不太好 引入 KG,增强 Chunk 之间的关联,并提升召回的相关性 假设已有 KG 数据存在,可以将 KG 作为一路召回信息源,补充上下文信息 Chunk 之间形成的 KG,可以提供 Graph 视角的 Embedding,来补充召回特征 构建一个高质量、灵活更新、计算简单的大规模图谱的代价很高 - RAG 会很慢 https://hub.baai.ac.cn/view/30017 https://hub.baai.ac.cn/view/33147 https://hub.baai.ac.cn/view/33390 https://hub.baa...
2024-08-04
RAG - LangChain
Practice LangChain RAG https://github.com/langchain-ai/rag-from-scratch RAG 如何随着长期 LLM 而改变 Is RAG Really Dead? https://www.youtube.com/watch?v=SsHUNfhF32s 自适应 RAG 根据复杂程度动态地将查询路由到不同的 RAG 方法 - Command-R @ LangGraph Adaptive RAG https://www.youtube.com/watch?v=04ighIjMcAI Code https://github.com/langchain-ai/langgraph/blob/main/examples/rag/langgraph_adaptive_rag_cohere.ipynb Paper https://arxiv.org/abs/2403.14403 Adaptive RAG 在循环单元测试中自我纠正检索错误,以确定文档相关性并返回到网络搜索 在 LangGraph 中实现 Mistral 7B + Ol...
2024-08-15
RAG - Optimization + Evaluation
RAG 检索优化数据清洗和预处理 在 RAG 索引流程中,文档解析之后,文档切块之前,进行数据清洗和预处理 减少脏数据和噪音,提升文本的整体质量和信息密度 手段:清除冗余信息、统一格式、处理异常字符等 处理冗余的模板内容 消除文档中的额外空白和格式不一致 去除文档脚注、页眉页脚、版权信息 查询扩写 在 RAG 系统的检索步骤中,用户的查询会转换为向量后进行检索 单个向量查询只能覆盖向量空间中一个有限区域 如果查询中的嵌入向量未能包含所有关键信息,则可能检索到不相关的 Chunk 单点查询的局限性 - 限制系统在庞大文档库中的搜索范围,导致错失与查询语义相关的内容 查询扩写 通过 LLM 从原始查询语句生成多个语义相关的查询,可以覆盖向量空间中的不同区域 提高检索的全面性和准确性 扩写后的查询在被嵌入后,能够击中不同的语义区域 确保系统能够从更广泛的文档中检索到与用户需求相关的有用信息 通过查询扩写,原始问题被分解为多个子查询 每个子查询独立检索相关文档并生成相应的结果 系统将所有子查询的检索结果进行合并和重新排序 能够有效扩展用户的查询意图,确保在复杂信息库中进行更全面的文...
2024-08-14
RAG - LLM + Prompt Engineering
RAG 生成流程 经过 RAG 索引流程(外部知识的解析和向量化)和 RAG 检索流程(语义相似性的匹配及混合检索),进入到 RAG 生成流程 在 RAG 生成流程中,需要组合指令,即携带查询问题及检索到的相关信息输入的 LLM,由 LLM 理解并生成最终的回复 RAG 的本质是通过 LLM 提供外部知识来增强其理解和回答领域问题的能力 LLM 在 RAG 系统中起到了大脑的作用 在面对复杂且多样化的 RAG 任务时,LLM 的性能直接决定了系统的整体效果 提示词工程是生成流程中的另一个关键环节 通过有效的指令的设计和组合,可以帮助 LLM 更好地理解输入内容,从而生成更加精确和相关的回答 精心设计的问题提示词,往往能提升生成效果 LLM发展 RAG 目前更关注通用大模型 原理 Google 于 2017 年发布论文 Attention Is All You Need,引入了 Transformer 模型 Transformer 模型是深度学习领域的一个突破性架构,LLM 的成功得益于对 Transformer 模型的应用 与传统的 RNN(循环神经网络) 相比,Transform...




