
RAG - In Action
技术选型
LangChain
- LangChain 是专门为开发基于 LLM 应用而设计的全面框架
- LangChain 的核心目标是简化开发者的构建流程,使其能够高效地创建 LLM 驱动的应用
索引
文档解析
- pypdf 专门用于处理 PDF 文档
- pypdf 支持 PDF 文档的创建、读取、编辑和转换,能够有效地提取和处理文本、图像及页面内容
文档分块
- RecursiveCharacterTextSplitter 是 LangChain 默认的文本分割器
- RecursiveCharacterTextSplitter 通过层次化的分隔符(从双换行符到单字符)拆分文本
- 旨在保持文本的结构和连贯性,优先考虑自然边界(如段落和句子)
索引 + 检索
向量化模型
- bge-small-zh-v1.5 是由北京智源人工智能研究院(BAAI)开发的开源向量模型
- bge-small-zh-v1.5 的模型体积较小,但仍能提供高精度和高效的中文向量检索
- bge-small-zh-v1.5 的向量维度为 512,最大输入长度同样为 512
向量库
- Faiss - Facebook AI Similarity Search
- Faiss 由 Facebook AI Research 开源的向量库,非常稳定和高效
生成
LLM
- Qwen 是阿里云推出的一款超大规模语言模型
- Qwen 支持多轮对话、文案创造、逻辑推理、多模态理解和语言处理
- Qwen 在模型性能和工程应用中表现出色
- Qwen 支持云端 API 服务
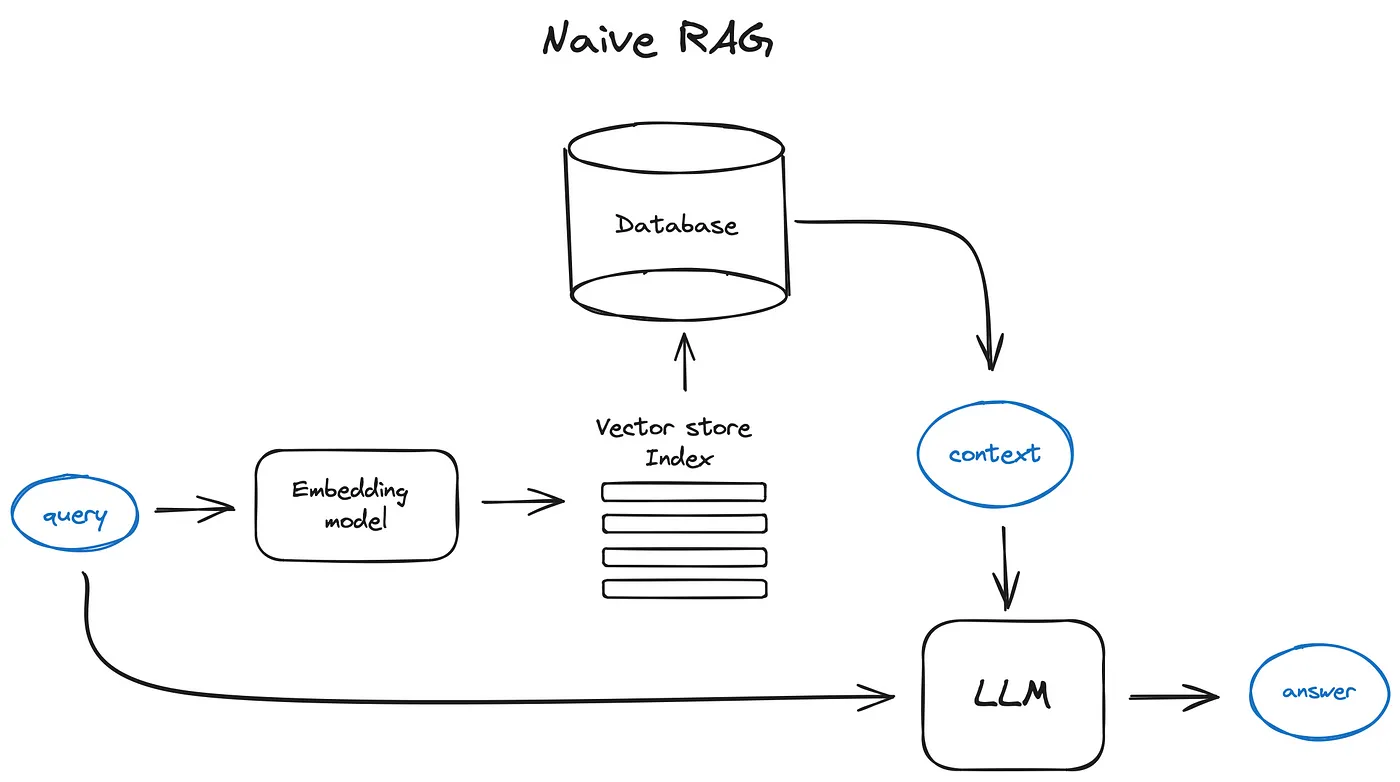
RAG

- LangChain
- 提供用于构建 LLM RAG 的应用程序框架
- 索引流程
- 使用 pypdf 对文档进行解析并提取信息
- 采用 RecursiveCharacterTextSplitter 对文档内容进行分块(Chunk)
- 使用 bge-small-zh-v1.5 将 Chunk 进行向量化处理,并将生成的向量存储到 Faiss 向量库中
- 检索流程
- 使用 bge-small-zh-v1.5 对 Query 进行向量化处理
- 通过 Faiss 向量库对 Query 向量和 Chunk 向量进行相似度匹配
- 从而检索出与 Query 最相似的 Top K 个 Chunk
- 生成流程
- 设定提示模板(Prompt)
- 将 Query 与 Chunk 填充到提示模板,生成增强提示,输入到 Qwen LLM,生成最终的 RAG 回答
开发环境
虚拟环境
1 | $ python3 -m venv rag_env |
安装依赖
1 | $ pip install --upgrade pip |
向量化模型
bge-small-zh-v1.5 - 95.8MB - pytorch_model.bin
1 | $ git clone https://huggingface.co/BAAI/bge-small-zh-v1.5 |
核心代码
依赖
1 | from langchain_community.document_loaders import PyPDFLoader # PDF文档提取 |
索引
Embedding
SentenceTransformer - map sentences / text to embeddings
1 | def load_embedding_model(): |
Indexing
chunk_size + chunk_overlap
- chunk_size
- 对输入文本序列进行切分的最大长度
- GPT-3 的最大输入长度为 2048 个 Token
- chunk_overlap
- 相邻的两个 Chunk 之间的重叠 Token 数量
- 为了保证文本语义的连贯性,相邻 Chunk 会有一定的重叠
- chunk_size = 1024,chunk_overlap = 128,对于长度为 2560 Token 的文本序列,会切分成 3 个 Chunk
- 1 ~ 1024 = 1024
- 897~1920 = 1024
- 1793~2560 = 768
索引
1 | def indexing_process(pdf_file, embedding_model): |
- 使用 PyPDFLoader 加载并预处理 PDF 文档,将其内容提取并合并为完整文本
- 利用 RecursiveCharacterTextSplitter 将文本分割为每块 512 字符(非 Token)、重叠 128 字符(非 Token)的文本块
- 通过预加载的 bge-small-zh-v1.5 嵌入模型将文本块转化为归一化的嵌入向量
- 将嵌入向量存储在基于余弦相似度的 Faiss 向量库中,以支持后续的相似性检索和生成任务
余弦相似度 - Cosine Similarity - 在 N 维空间中,两个 N 维向量之间角度的余弦 - 值越大越相似
$$
Similarity(A,B) = \frac{A\cdot{B}}{|A|\times|B|} = \frac{\sum_{i=1}^n(A_i\times{B_i})}{\sqrt{\sum_{i=1}^n{A_i^2}}\times\sqrt{\sum_{i=1}^n{B_i^2}}}
$$
待优化项
- 多文档处理
- 嵌入模型的效率优化与并行处理
- Faiss 采用持久化存储 - 目前仅在内存中存储
检索
1 | def retrieval_process(query, index, chunks, embedding_model, top_k=3): |
- Query 被预加载的 bge-small-zh-v1.5 嵌入模型转化为归一化的嵌入向量
- 进一步转换为 numpy 数组以适配 Faiss 向量库的输入格式
- 利用 Faiss 向量库中的向量检索功能
- 计算 Query 与存储向量之间余弦相似度,从而筛选出与 Query 最相似的 Top K 个文本块
- 相似文本块存储在结果列表中,供后续生成过程使用
生成
1 | def generate_process(query, chunks): |
- 结合 Query 与检索到的文本块组织成 LLM Prompt
- 调用 Qwen 云端 API,将 Prompt 发送给 LLM
- 利用流式输出的方式逐步获取 LLM 生成的响应内容,实时输出并汇总成最终的生成结果
输出
1 | 生成过程开始: |
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2024-08-05
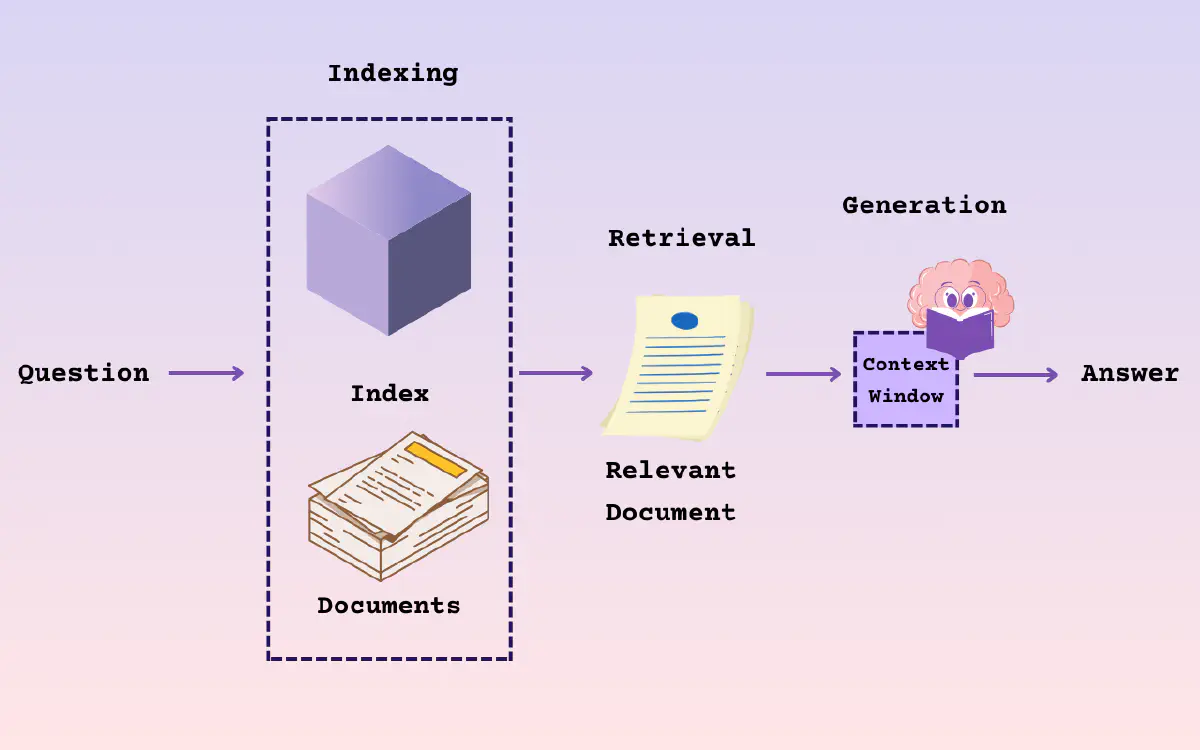
RAG - Document Parsing
文档解析 文档解析的本质 - 将格式各异、版本多样、元素多种的文档数据,转化为阅读顺序正确的字符串信息 Quality in, Quality out 是 LLM 的典型特征 高质量的文档解析能够从各种复杂格式的非结构化数据中提取出高精度信息 对 RAG 系统的最终效果起到决定性作用 RAG 系统的应用场景主要集中在专业领域和企业场景 除了数据库,更多的数据以 PDF、Word 等多种格式存储 PDF 文件有统一的排版和多样化的结构形式,是最为常见的文档数据格式和交换格式 Quality in, Quality out LangChainDocument Loaders LangChain 提供了一套功能强大的文档加载器(Document Loaders) LangChain 定义了 BaseLoader 类和 Document 类 BaseLoader - 定义如何从不同数据源加载文档 Document - 统一描述不同文档类型的元数据 开发者可以基于 BaseLoader 为特定数据源创建自定义加载器,将其内容加载为 Document 对象 Document Loader 模...
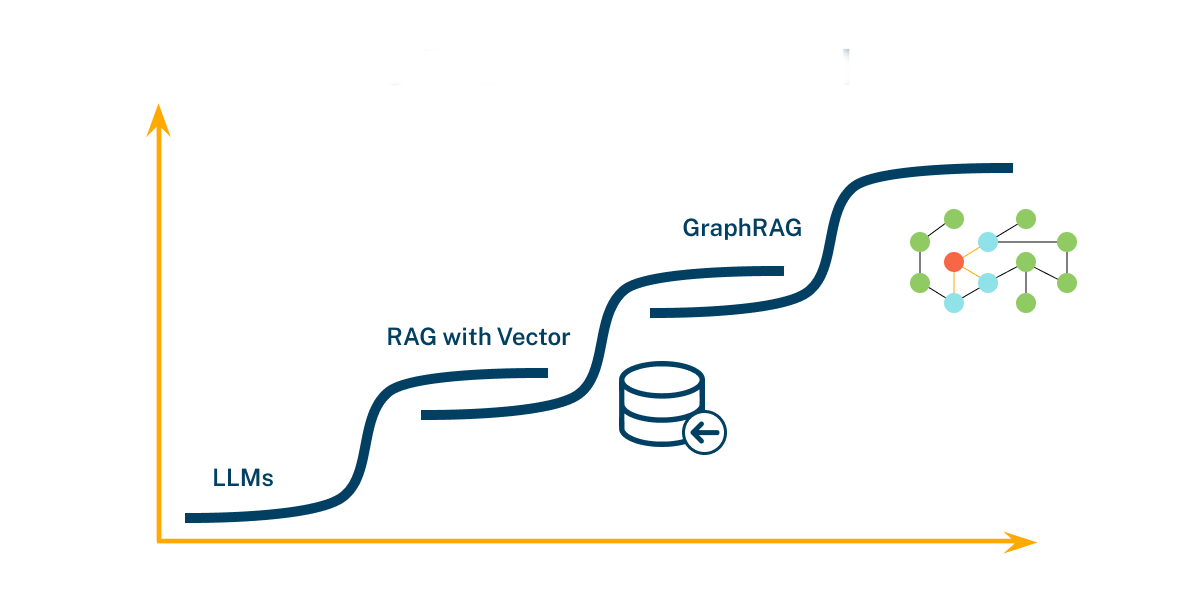
2024-08-17
RAG - GraphRAG
向量检索 信息片段之间的连接能力有限 RAG 在跨越多个信息片段以获取综合见解时表现不足 当要回答一个复杂问题时,必须要通过共享属性在不同信息之间建立联系 RAG 无法有效捕捉这些关系 限制了 RAG 在处理需要多跳推理或整合多源数据的复杂查询时的能力 归纳总结能力不足 在处理大型数据集或长文档时,RAG 难以有效地归纳和总结复杂的语义概念 RAG 在需要全面理解和总结复杂语义信息的场景中表现不佳 GraphRAG 利用 LLM 生成的知识图谱来改进 RAG 的检索部分 GraphRAG 利用结构化的实体和关系信息,使得检索过程更加精准和全面 GraphRAG 在处理多跳问题和复杂文档分析时表现出色 GraphRAG 在处理复杂信息处理任务时,显著提升问答性能,提供比 RAG 更为准确和全面的答案 GraphRAG 通过知识图谱有效地连接不同的信息片段 不仅能够提供准确答案,还能展示答案之间的内在联系,提供更丰富和有价值的结果 GraphRAG 先利用知识图谱,关联查询的实体和关系从与知识图谱实体直接相关的文档中检索片段,提供一个更全面、指标化、高信息密度的总结 主...
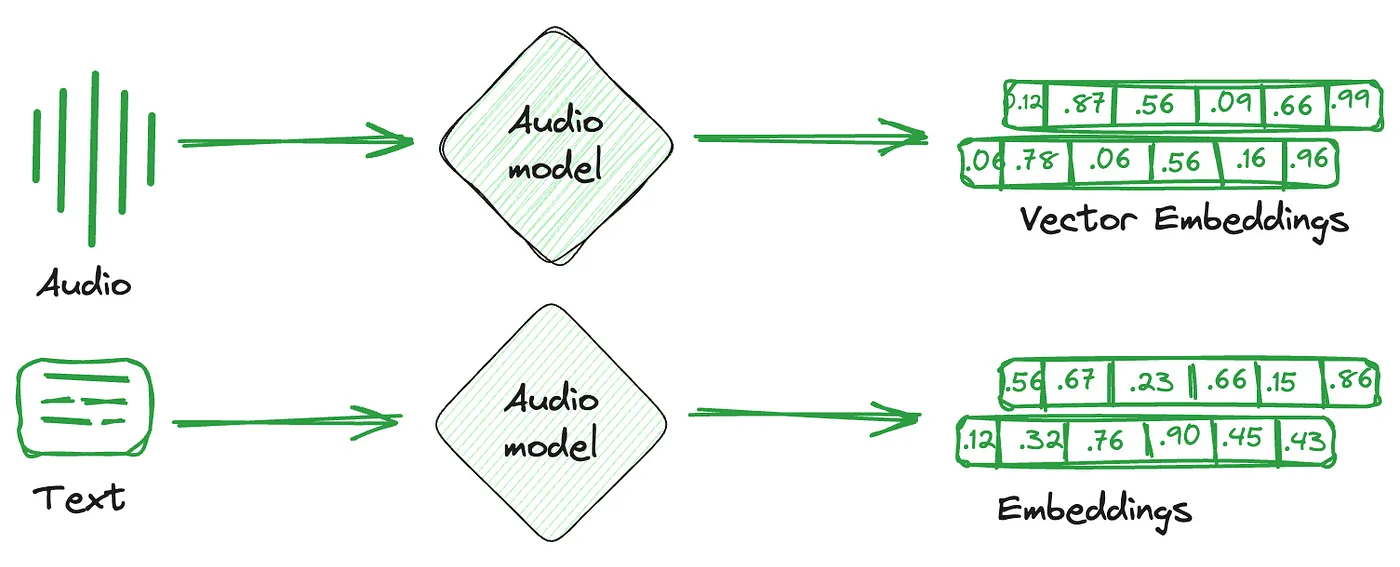
2024-08-12
RAG - Vector Stores
Embedding Vector Store概述 在 AI 时代,文字、图像、语音、视频等多模态数据的复杂性显著增加 多模态数据具有非结构化和多维特征 向量表示能够有效表示语义和捕捉潜在的语义关系 促使向量数据库成为存储、检索和分析高维向量的关键工具 Qdrant / Milvus 优势 SQL vs NoSQL 传统数据库通常分为关系型(SQL)数据库和非关系型(NoSQL)数据库 存储复杂、非结构化或半结构化信息的需求,主要依赖于 NoSQL 的能力 Store Desc Note Key-Value 用于简单的数据存储,通过 Key 来快速访问数据 精准定位信息 Document 用于存储文档结构的数据,如 JSON 格式 复杂的结构化信息 Graph 用于表示和存储复杂的关系数据,常用于社交网络、推荐等场景 复杂的关系数据 Vector 用于存储和检索基于向量表示的数据,用于 AI 模型的高维度和复杂的嵌入向量 语义最相关的数据 向量数据库的核心在于能够基于向量之间的相似性,能够快速、精确地定位和检索数据 向量数据库不仅为嵌入向量提供了...
2024-08-06
RAG - Methodology
场景识别 分析业务流程,找出业务中依赖大量知识和信息处理的环节 复杂决策环节 在需要多维度信息综合分析与判断的业务流程中,RAG 可以为决策者提供实时的信息支持 使用 LLM 从各种来源的信息提炼出关键点,加权求和 - 压缩和整理非格式化信息 重复性内容生成 企业中有大量重复且标准化的内容生成任务 可以用程序去归纳流程,用 LLM 和 RAG 去填充每个环节 用户交互场景 增加自然语言交互 识别问题,找出流程痛点,并识别 LLM 和 RAG 能发挥的作用 信息碎片化 + 难以系统化输出 使用 LLM 和 RAG 能够通过自动化整合固定信息源,定期获取信息 统一整理(或生成)到统一的知识库,将分散的知识转化为结构化输出 人工处理效率低下 通过 LLM 自动化任务,可以更专注于更有创造力的工作 小步快跑 + 快速迭代 - LLM 技术变化极快 MVP Minimum viable product 数据驱动的迭代优化 持续收集用户行为数据和反馈,通过 A/B 测试等方法,不断优化系统表现
2024-06-27
LLM - LangChain + RAG
局限 大模型的核心能力 - 意图理解 + 文本生成 局限 描述 数据的及时性 大部分 AI 大模型都是预训练的,如果要问一些最新的消息,大模型是不知道的 复杂任务处理 AI 大模型在问答方面表现出色,但不总是能够处理复杂任务AI 大模型主要是基于文本的交互(多模态除外) 代码生成与下载 根据需求描述生成对应的代码,并提供下载链接 - 暂时不支持 与企业应用场景的集成 读取关系型数据库里面的数据,并根据提示进行任务处理 - 暂时不支持 在实际应用过程中,输入数据和输出数据,不仅仅是纯文本 AI Agent - 需要解析用户的输入输出 AI Agent AI Agent 是以 LLM 为核心控制器的一套代理系统 控制端处于核心地位,承担记忆、思考以及决策等基础工作 感知模块负责接收和处理来自于外部环境的多样化信息 - 文字、声音、图片、位置等 行动模块通过生成文本、API 调用、使用工具等方式来执行任务以及改变环境 LangChain - 开源 + 提供一整套围绕 LLM 的 Agent 工具 AI Agent 很有可能在未来一段时间内成为 AI 发展的一...
2024-08-16
RAG - Evolution
演进 Naive RAG -> Advanced RAG -> Modular RAG 三个范式之间具有继承与发展的关系 Advanced RAG 是 Modular RAG 的一种特例形式 Naive RAG 是 Advanced RAG 的基础特例 RAG 技术不断演进,以适应更复杂的任务和场景需求 Naive RAG Naive RAG 是最基础的形式,依赖核心的索引和检索策略来增强生成模型的输出 Naive RAG 适用于一些基础任务和产品 MVP 阶段 Advanced RAG 通过增加检索前、检索中以及检索后的优化策略,提高检索的准确性和生成的关联性 - 适用于复杂任务 Advanced RAG 通过优化检索前、检索中、检索后的各个环节 在索引质量、检索效果以及生成内容的上下文相关性方面都取得显著提升 检索前 通过索引、分块、查询优化和内容向量化等技术手段,提高检索内容的精确性和生成内容的相关性 滑动窗口 overlap 经典的 Chunking 技术,通过在相邻的 Chunk 之间创建重叠区域,确保关键信息不会因简单的 Chunking 而丢失 在 ...




