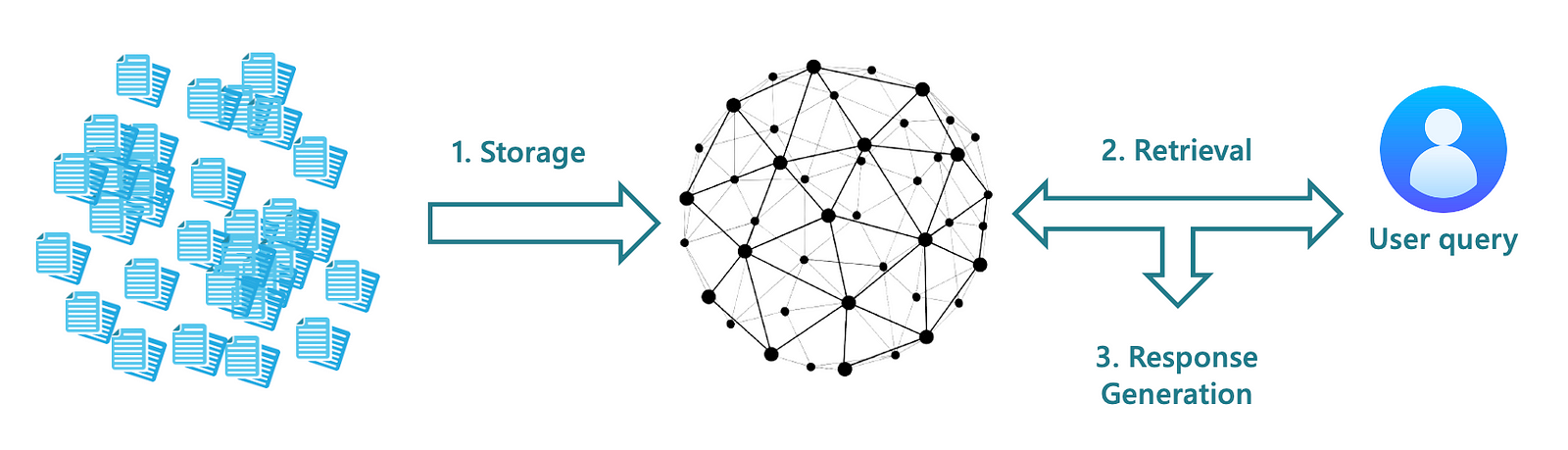
RAG - LangChain
Practice
- LangChain RAG
- RAG 如何随着长期 LLM 而改变
- Is RAG Really Dead?
- 自适应 RAG
- 根据复杂程度动态地将查询路由到不同的 RAG 方法 - Command-R @ LangGraph
- Adaptive RAG
- Code
- Paper
- Adaptive RAG
- 在循环单元测试中自我纠正检索错误,以确定文档相关性并返回到网络搜索
- 在 LangGraph 中实现 Mistral 7B + Ollama,以便在本地运行
- Local CRAG + LangGraph
- Code
- Paper
- Self-RAG
- 查询路由
- 将问题引导至正确数据源的各种方法(如逻辑、语义等)
- Routing
- Code
- 查询结构
- 使用 LLM 将自然语言转换为 DSL(如 SQL 等)
- Query Structuring
- Code
- Blog
- https://blog.langchain.dev/query-construction/
- https://blog.langchain.dev/enhancing-rag-based-applications-accuracy-by-constructing-and-leveraging-knowledge-graphs/
- https://python.langchain.com/v0.1/docs/use_cases/query_analysis/techniques/structuring/
- https://python.langchain.com/v0.1/docs/modules/data_connection/retrievers/self_query/
- 多表示索引
- 使用 LLM 生成针对检索进行优化的文档摘要(命题)
- 嵌入这些摘要以进行相似性搜索,但将完整文档返回给 LLM 进行生成
- Multi-Representation Indexing
- Code
- Paper
- RAPTOR
- 将语料库中的文档聚类,并递归地总结相似的文档
- 将它们全部编入索引,生成较低级别的文档和摘要
- 可以检索这些文档和摘要来回答更高级别的问题
- RAPTOR
- Code
- Paper
- ColBERT Token 级检索
- 使用受上下文影响的嵌入来提高文档和查询中每个 Token 的嵌入粒度
- ColBERT
- Code
- Paper
- 多次查询
- 从多个角度重写用户问题,为每个重写的问题检索文档,返回所有查询的唯一文档
- Query Translation – Multi Query
- Code
- Paper
- RAG 融合
- 从多个角度重写用户问题,检索每个重写问题的文档
- 并组合成多个搜索结果列表的排名,以使用倒数排名融合生成单一统一的排名
- Query Translation – RAG Fusion
- Code
- Project
- 问题分解
- 将问题分解成一组子问题
- 可以按串行解决(使用第一个问题的答案和检索来回答第二个问题)
- 也可以并行解决(将每个答案合并为最终答案)
- 各种工作,如从最少到最多提示和 IRCoT 提出了可以利用的想法
- Query Translation – Decomposition
- Paper
- 回退提示
- 首先提示 LLM 提出一个关于高级概念或原则的通用后退问题,并检索相关事实
- 使用此基础来帮助回答用户问题
- Query Translation – Step Back
- Code
- Paper
- HyDE 混合匹配
- LLM 将问题转换为回答问题的假设文档,使用嵌入的假设文档检索真实文档
- 前提是 doc-doc 相似性搜索可以产生更多相关匹配
- Query Translation – HyDE
- Code
- Paper
Query Translation
Query Translation - 侧重于重写或者修改问题以便于检索
Multi Query
https://python.langchain.com/v0.1/docs/modules/data_connection/retrievers/MultiQueryRetriever/
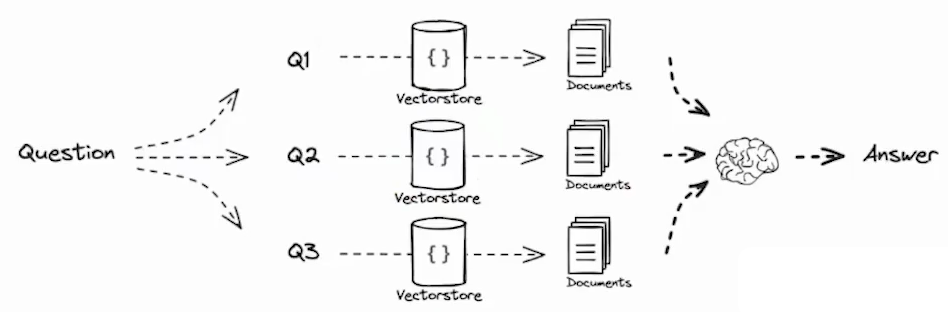
- 从多个角度重写用户问题,为每个重写的问题检索文档,返回所有查询的唯一文档
- 在实现上,将一个查询变成多个查询
- 本质上是用 LLM 生成 Query
RAG Fusion
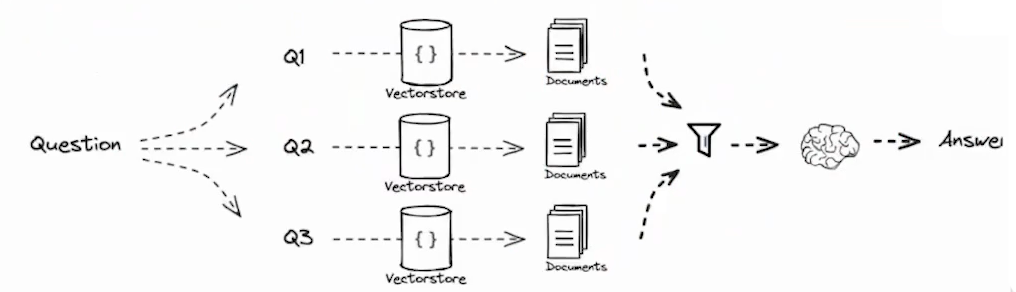
- 从多个角度重写用户问题,检索每个重写问题的文档,并组合多个搜索结果列表的排名
- 以使用倒数排名融合(RRF)生成单一统一的排名
- 核心思想 - 将多个召回查询的结果进行合并
- https://github.com/langchain-ai/langchain/blob/master/cookbook/rag_fusion.ipynb
- https://towardsdatascience.com/forget-rag-the-future-is-rag-fusion-1147298d8ad1
Decomposition
- 将一个复杂问题分解成多个子问题
- 可以串行解决 - 使用前一个问题的答案和检索来回答第二个问题
- 可以并行解决 - 将每个答案合并为最终答案
- Decomposition 是向下分解,与 Multi Query 不同
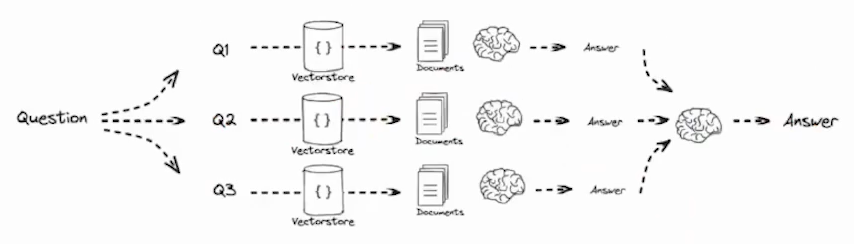
串行 - 迭代式回答 - 在问题分解的基础上,逐步迭代出答案
https://arxiv.org/pdf/2205.10625
https://arxiv.org/pdf/2212.10509
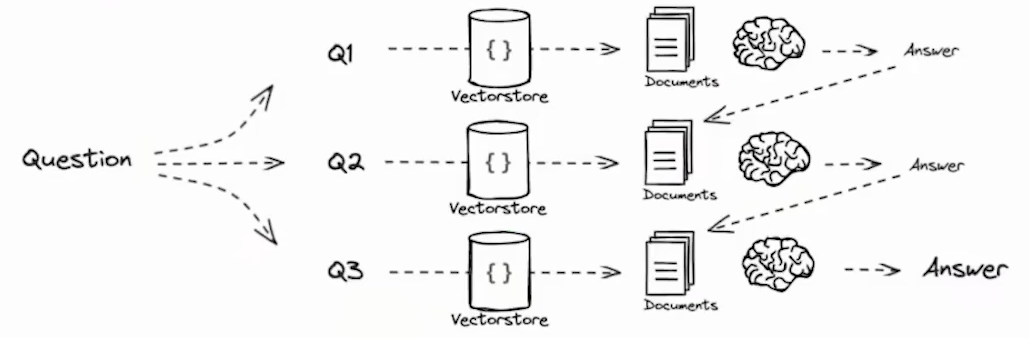
并行 - 让每个 SubQuery 分别进行处理,然后得到答案,再拼接成一个 QA Pairs Prompt 最终形成答案
Step Back
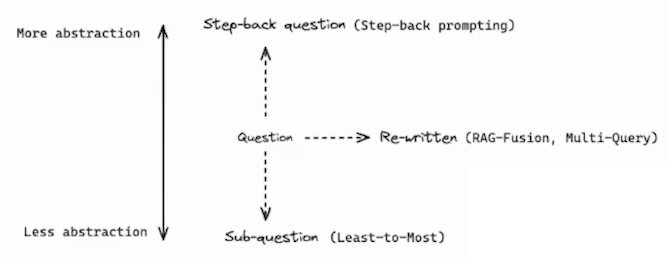
- 首先提示 LLM 提出一个关于高级概念或原则的通用后退问题,并检索有关它们的相关事实
- 使用此基础来帮助回答用户问题
- 构成上包括抽象(Abstraction)和推理(Reasoning)两步
- 给定一个问题,提示 LLM,找到回答该问题的一个前置问题
- 得到前置问题及其答案后,再将其整体和当前问题进行合并,最后送入 LLM 进行问答,得到最终答案
- https://arxiv.org/pdf/2310.06117
HyDE
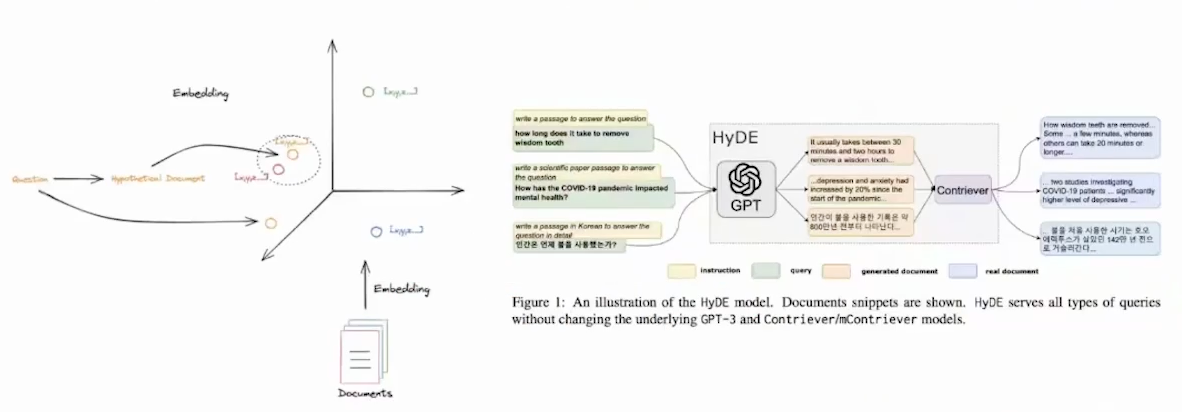
- LLM 将问题转换为回答问题的假设文档(很容易引入幻觉),使用嵌入的假设文档检索真实文档
- 前提是 Doc-Doc 相似性搜索可以产生更多相关匹配
- 由于 Query 和 Doc 之间是不对称检索
- 先根据 Query 生成一个 Doc,然后根据该 Doc 生成对应的 Embedding
- 再跟原先的 Docs 进行检索
- https://arxiv.org/abs/2212.10496
- https://github.com/langchain-ai/langchain/blob/master/cookbook/hypothetical_document_embeddings.ipynb
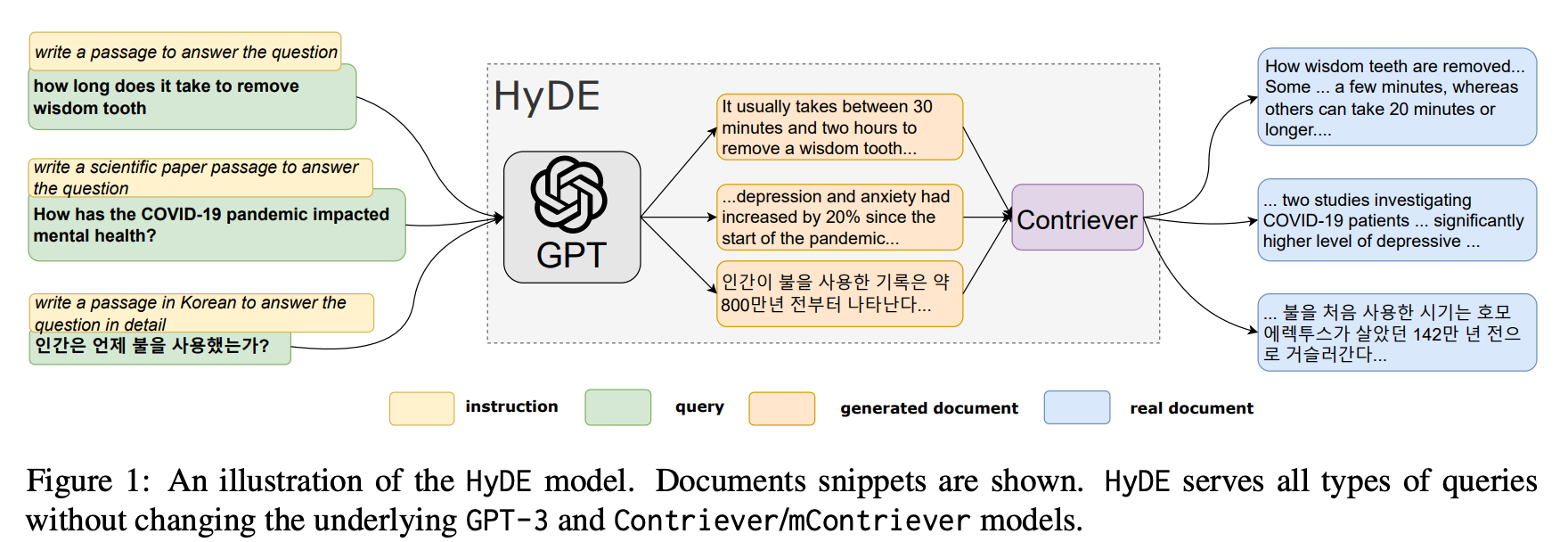
- 每个 query 都有对应的 instruction
- 通过 ChatGPT 生成 generated document,然后以此进行召回,最后生成 real document
Routing
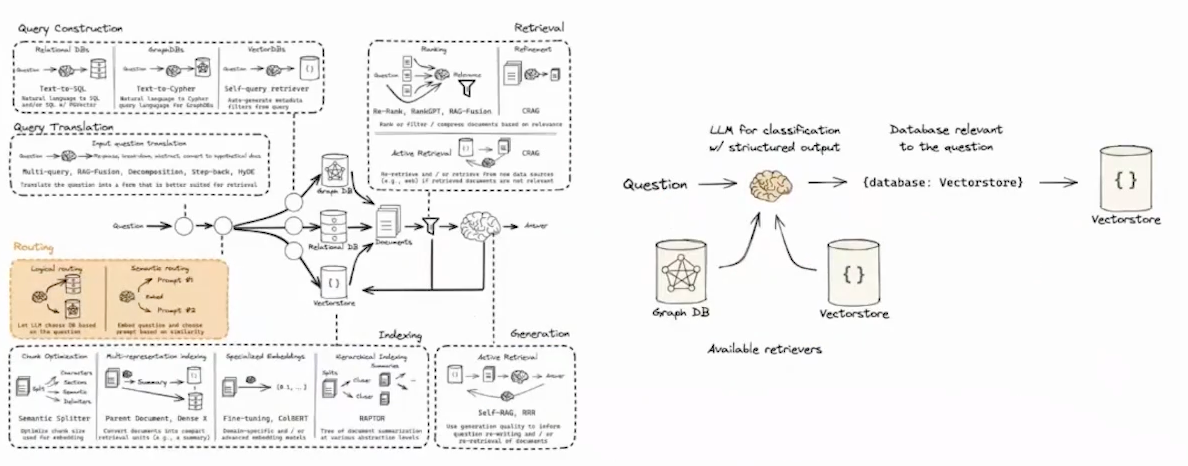

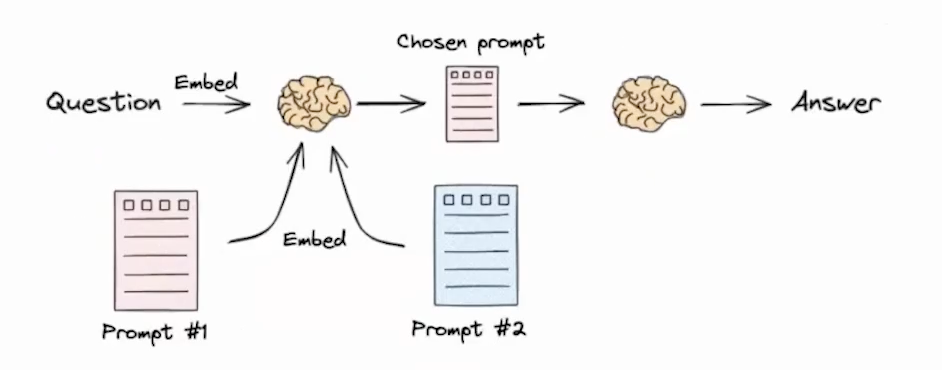
- 从获取 query 之后,所需要执行的问题意图分类的问题,处理的是问题域选择问题
- 可用方案 1 - Logical and Semantic routing - 基于逻辑和语义的路由分发
- 可用方案 2 - Semantic routing - 基于语义来实现分发
Query Structuring
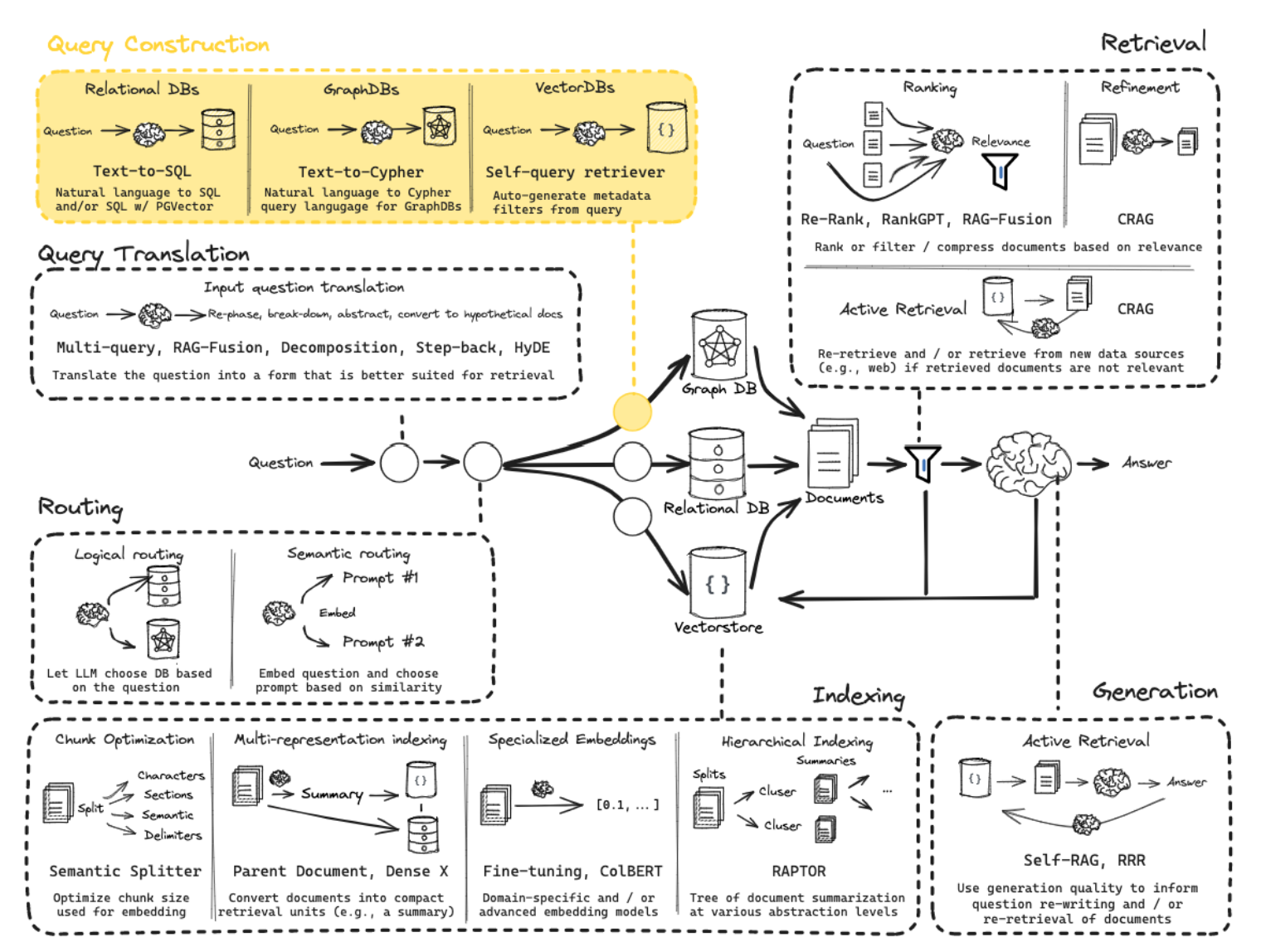

- 不同的检索知识库,如 MySQL、GraphDB、VectorDB 的查询转换
- 使用 LLM 将自然语言转换为其中一种 DSL - 借助 Text to SQL 模型
- https://blog.langchain.dev/query-construction/
- https://blog.langchain.dev/enhancing-rag-based-applications-accuracy-by-constructing-and-leveraging-knowledge-graphs/
- 可用方案 - query structuring for metadata filter - 基于元数据过滤器的问题构建
- 许多向量化存储都包含元数据字段,可以根据元数据过滤特定的数据 Chunk
- https://python.langchain.com/v0.1/docs/use_cases/query_analysis/techniques/structuring/
Indexing
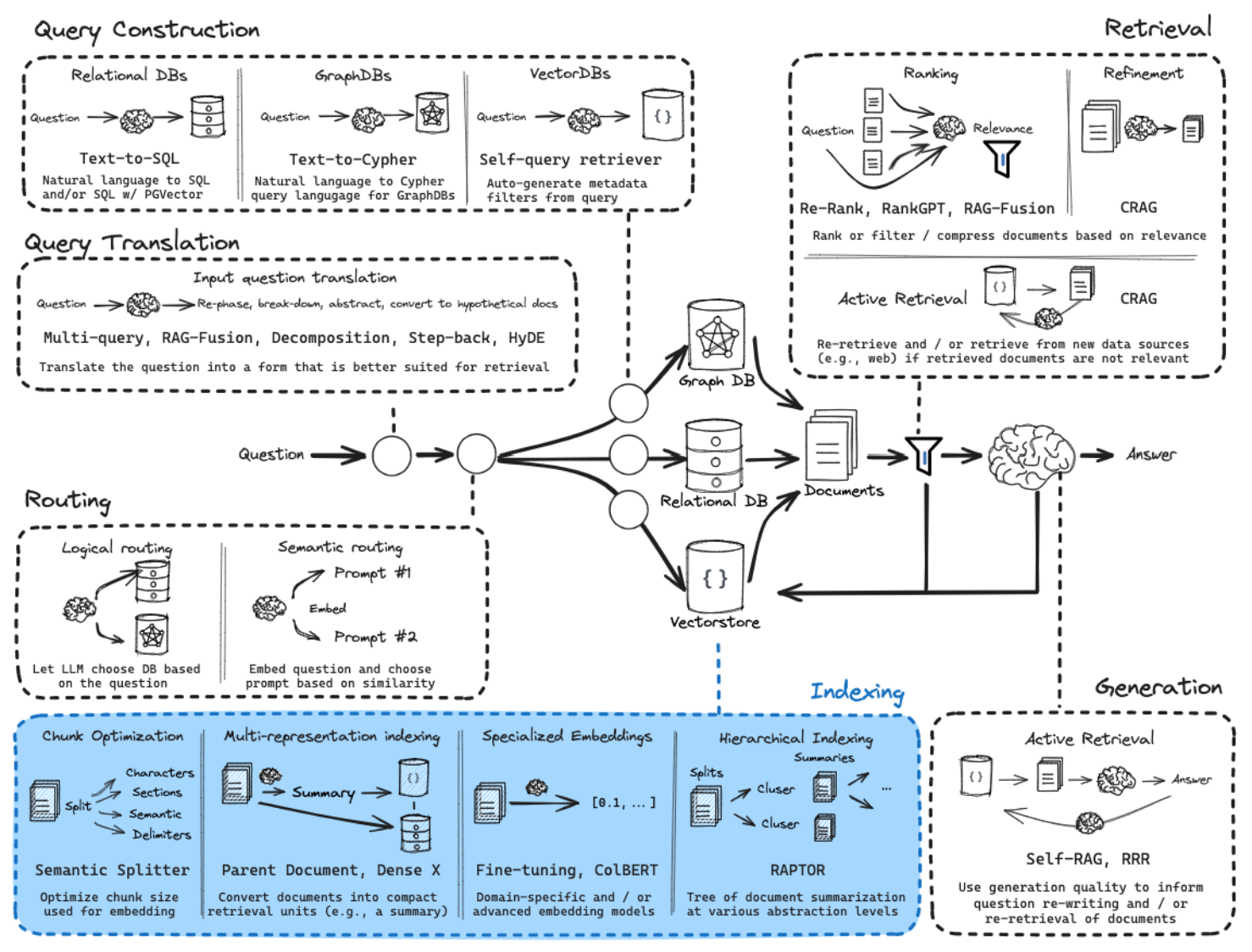
先生成摘要,再索引
- https://blog.langchain.dev/semi-structured-multi-modal-rag/
- https://python.langchain.com/v0.1/docs/modules/data_connection/retrievers/multi_vector/
- https://arxiv.org/abs/2312.06648
- https://python.langchain.com/v0.1/docs/modules/data_connection/retrievers/parent_document_retriever/
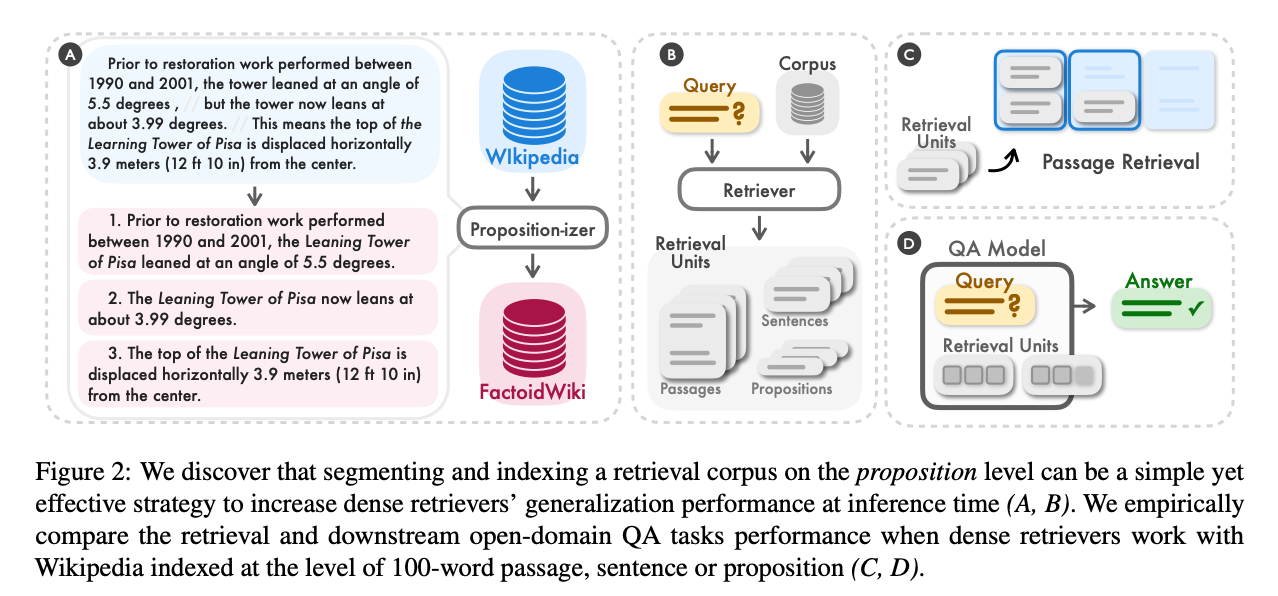
层级性索引 - https://arxiv.org/pdf/2401.18059
https://github.com/langchain-ai/langchain/blob/master/cookbook/RAPTOR.ipynb
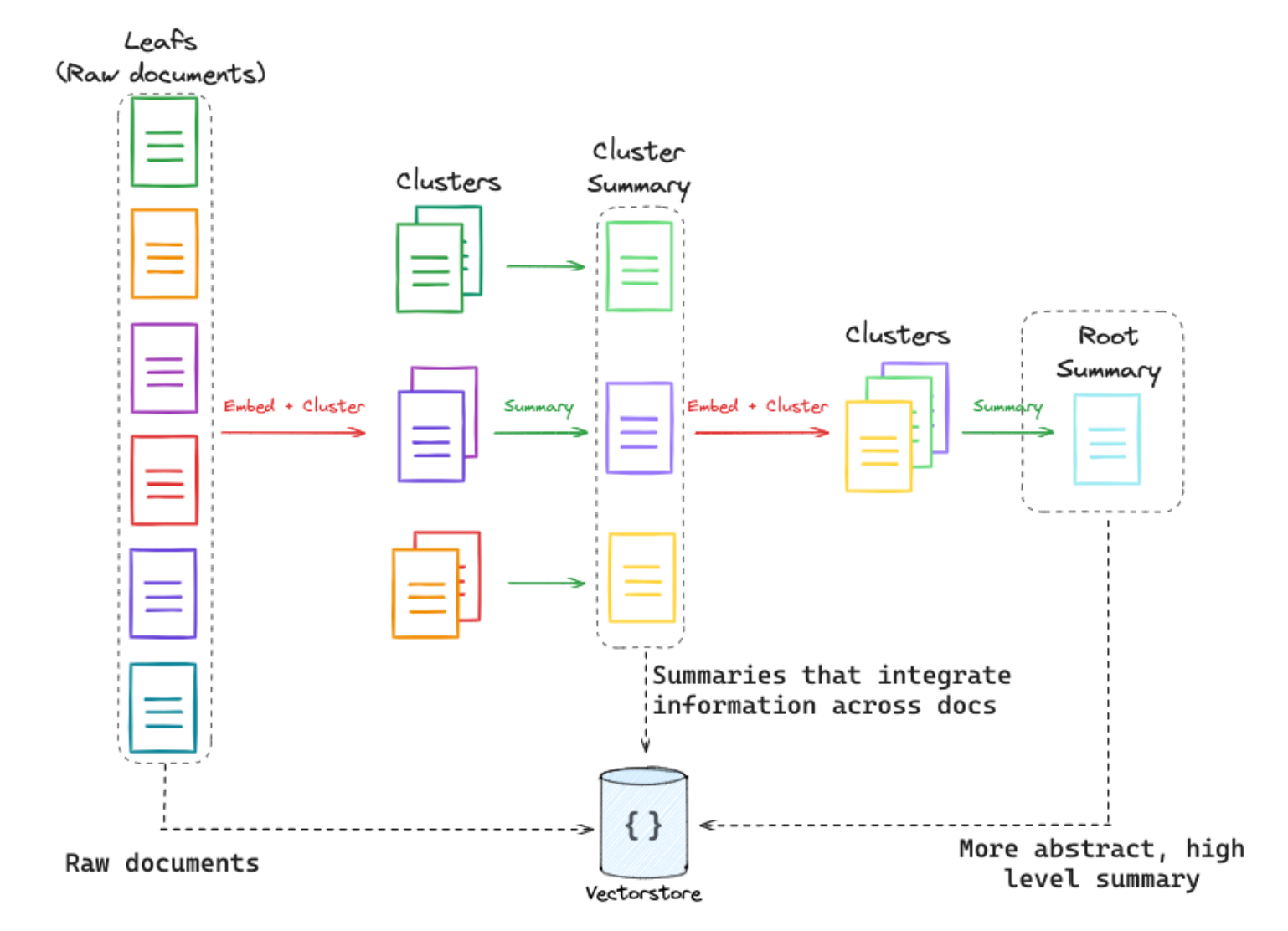
- 对文档进行生成聚类摘要,然后设计成层级性
- 具体实现,将语料库中的文档聚类,并递归地总结相似的文档
- 将它们全部编入索引,生成低级别的文档和摘要
- 可以索引这些文档和摘要来回答从详细到更高级别的问题
ColBERT - 做到 Token 级别 - 类似于关键词的召回
https://hackernoon.com/how-colbert-helps-developers-overcome-the-limits-of-rag
- 为段落中的每个 Token 生成一个受上下文影响的向量
- ColBERT 同样为 Query 中的每个 Token 生成向量
- 然后,每个文档的得分是 Query 嵌入与任意文档嵌入的最大相似度之和
Retrieval
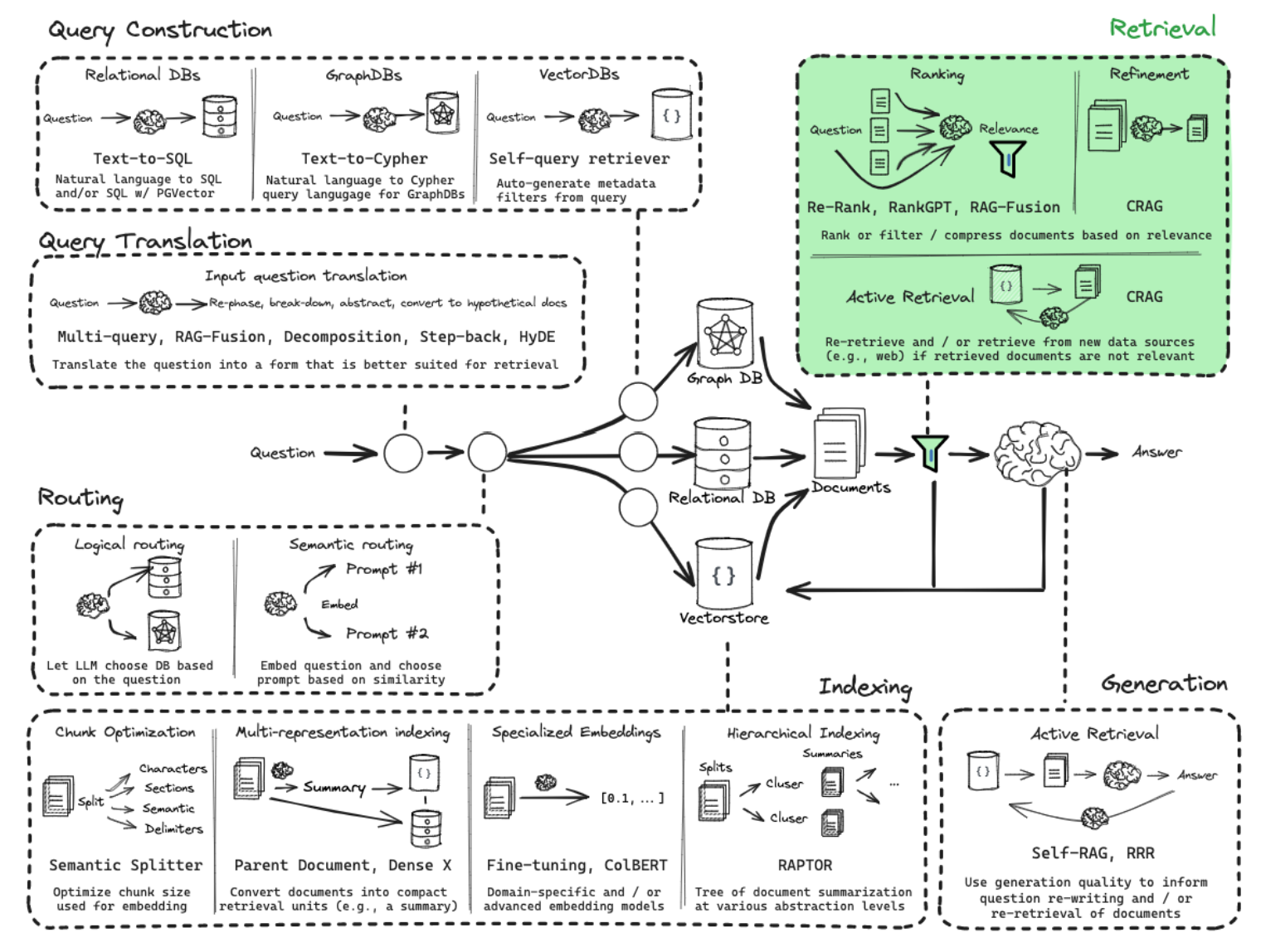
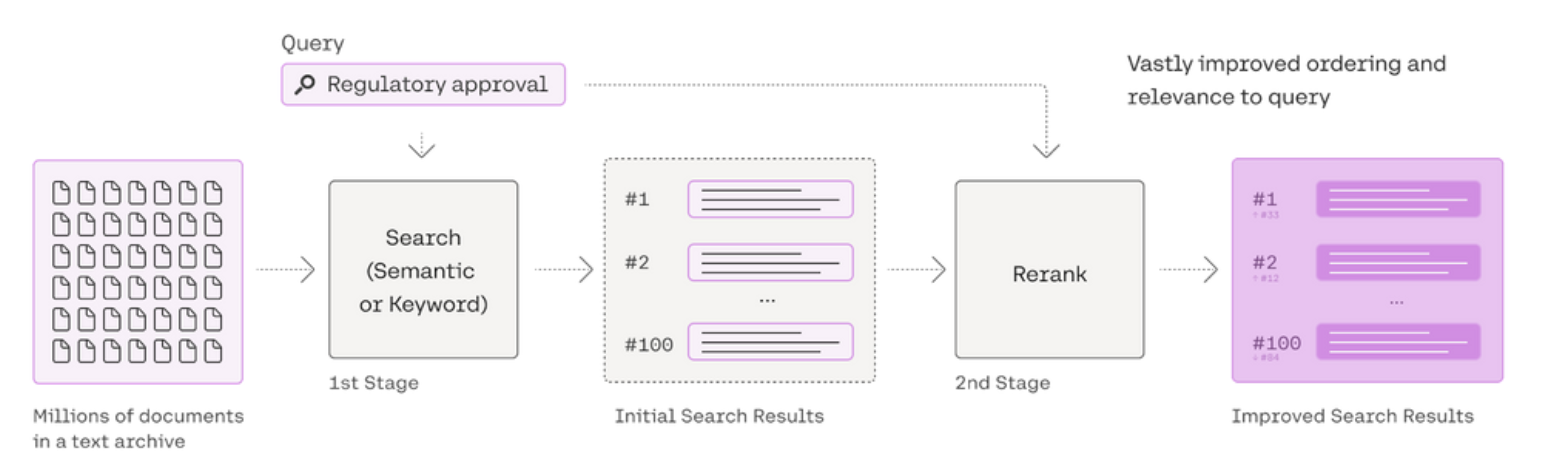
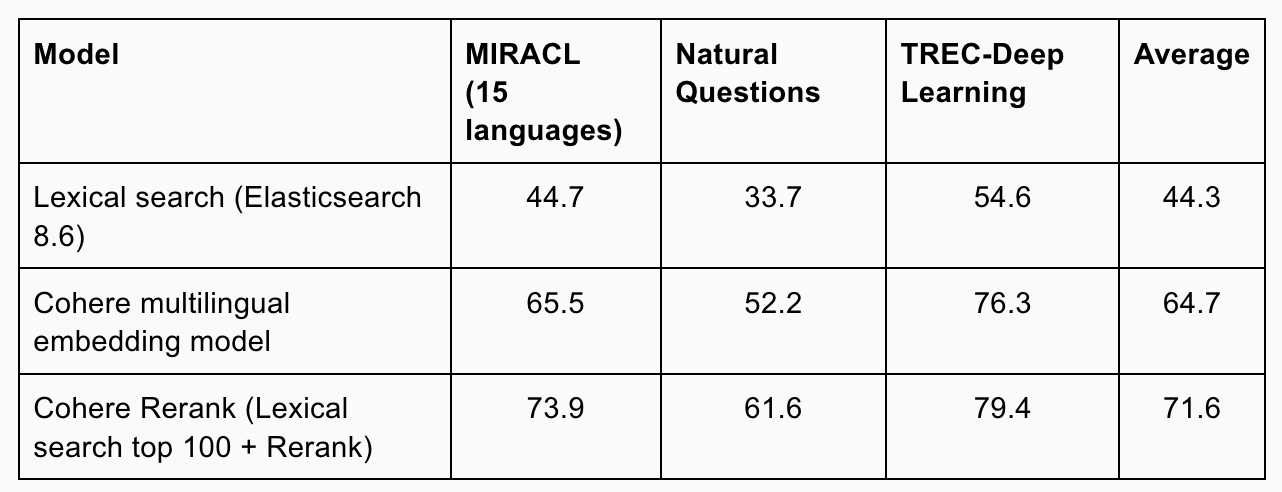
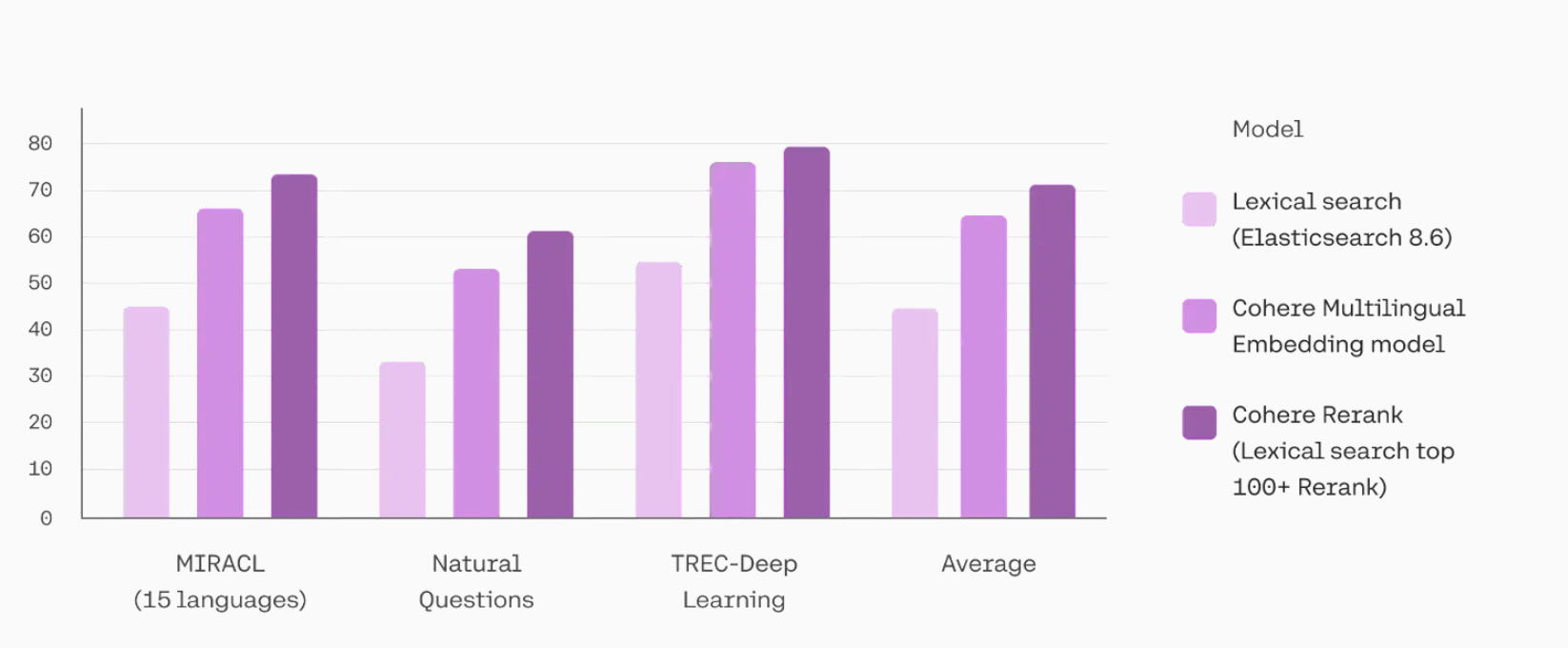
- https://python.langchain.com/v0.2/docs/integrations/retrievers/cohere-reranker/#doing-reranking-with-coherererank
- https://cohere.com/blog/rerank
- Ranking / Refinement / Active Retrieval
- 做 RAG 的时候,尽量不要去动原始的 Embedding 模型,而是动 Rerank 模型(很小,几百兆)
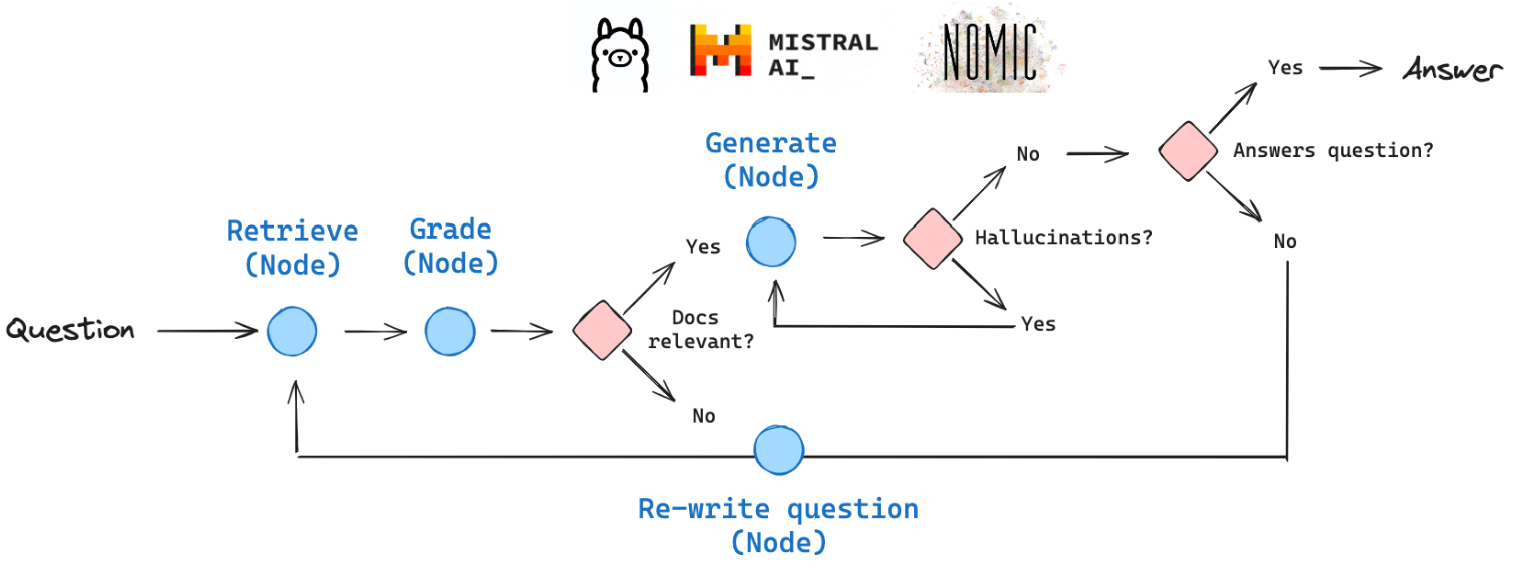
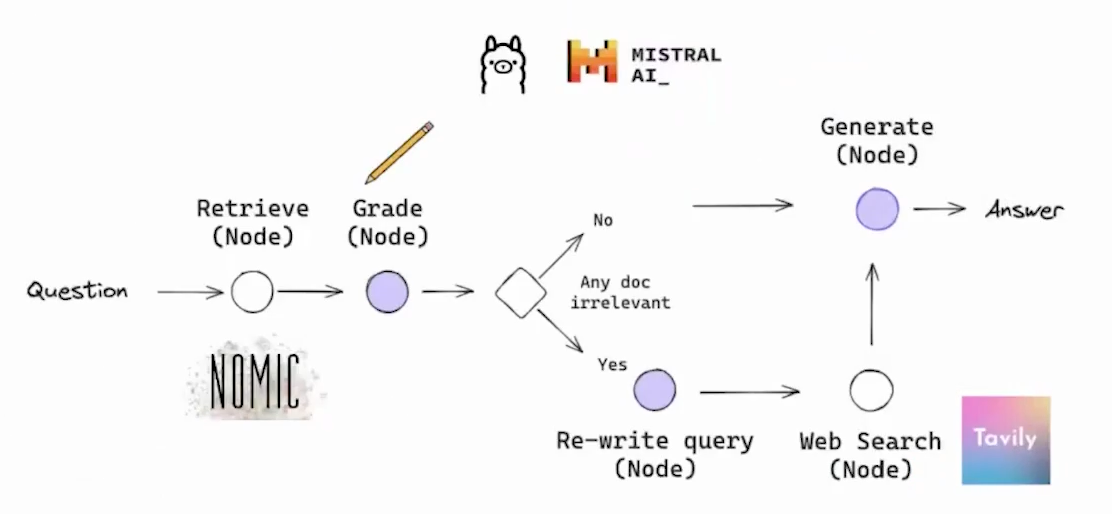
CRAG(Corrective RAG),本质也是一种 Adaptive RAG
为在循环单元测试中自我纠正检索错误,以确定文档相关性并返回到网络搜索
对检索文档的自我反思和自我评分AI 搜索
如果至少有一个文档超过了相关性阈值,则进入生成阶段
在生成之前,进行知识细化,将文档化为条带,对每个知识条进行分级,过滤不相关的知识条
如果所有文档都低于相关性阈值,或者分级者不确定,那么框架会寻找额外的数据源,使用网络补充搜索
Self-RAG
使用循环单元测试自我纠正 RAG 错误,以检查文档相关性、答案幻觉和答案质量