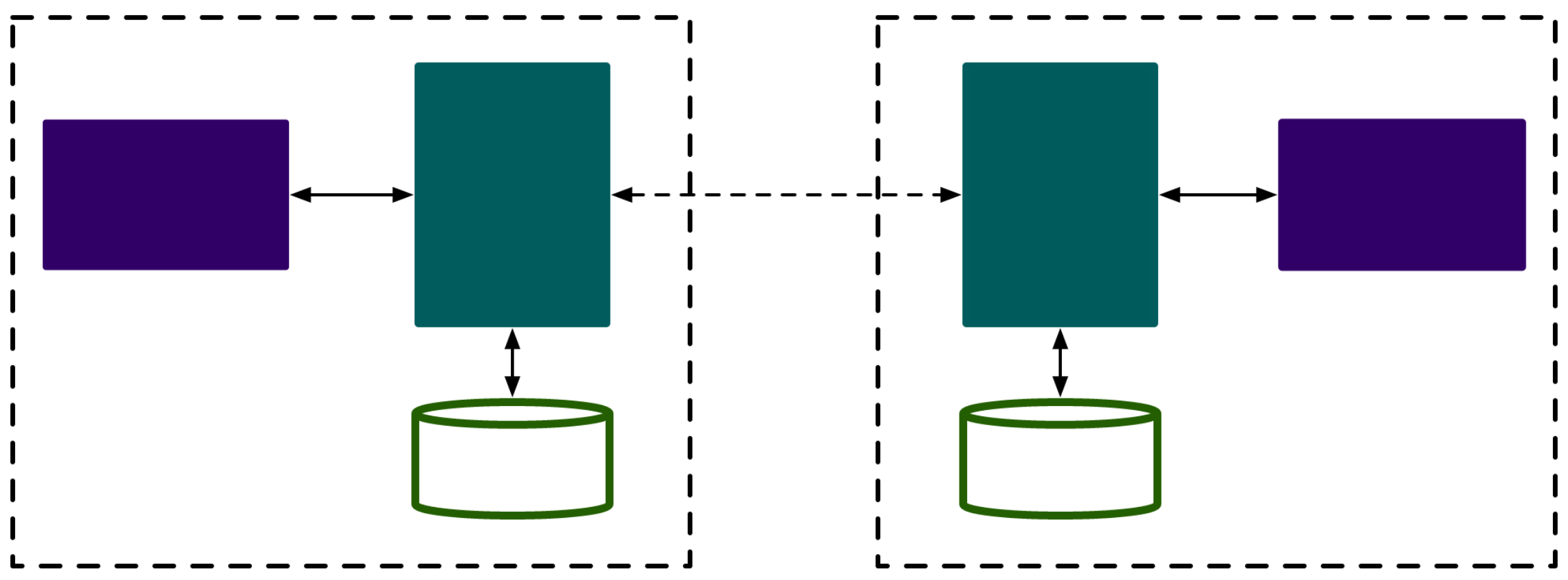
Big Data - Distributed System
SLA
Service-Level Agreement - 系统服务提供者对客户的一个服务承诺
Availabilty
- 可用性指的是系统服务能正常运行所占的时间百分比
- 对许多系统来说,99.99% 可以被认为高可用性 - 中断时间≈ 50 分钟/年
Accuracy
- 是否允许某些数据不准确或者丢失,如果允许发生,用户可以接受的概率
- 不同系统平台会用不同的指标去定义准确性,常用的是 Error Rate
$$
错误率=\frac{导致系统产生内部错误的有效请求数}{期间的有效请求总数}
$$
Case
- 以分钟为单位,每个月的 Error Rate 超过 5% 的时间少于 0.1%
- 以 5 分钟为单位,Error Rate 不会超过 0.1%
评估系统准确性
- 性能测试
- 查看系统日志
Capacity
- 系统容量通常指的是系统能够支持的预期负载量是多少,一般会以每秒的请求数为单位来表示
- QPS - Queries Per Second
- RPS - Requests Per Second
- 定义 Capacity 的方式 - Throttling / Performance Test / Log
Latency
- 延迟指的是系统在收到用户的请求到响应这个请求之间的时间间隔
- p95 / p99 - percentile
Scalability
Horizontal Scaling + Vertical Scaling
| Scaling | Desc |
|---|---|
| Horizontal | 在现有的系统中增加新的机器节点 |
| Vertical | 升级现有机器的性能 |
- 在大数据时代,数据规模越来越大,对数据存储系统的扩展性要求也越来越高
- 传统的关系型数据库
- 表与表之间的数据有关联,经常要进行 Join 操作
- 所有数据要存放在单机系统中,很难支持水平扩展
- NoSQL 型数据库
- 天生支持水平扩展 - MongoDB / Redis
Consistency
- 构成分布式系统的机器节点的可用性要低于系统的可用性
- 如何保证系统中不同的机器节点在同一时间,接收到和输出的数据是一致的
- 要保证分布式系统内的机器节点具有相同的信息,需要机器节点之间定期同步(可能失败)
一致性模型 - 强一致性很难实现,最终一致性应用最广
- 强一致性 - Google Cloud Spanner
- 系统中的某个数据被成功更新后,后续任何对该数据的读取操作都将得到更新后的值
- 在任意时刻,同一系统所有节点中的数据是一样的
- 只要某个数据的值发生更新,该数据的副本都要进行同步,保证该更新被传播到所有备份数据库中
- 在该同步过程结束后,才允许读取该数据
- 一般会牺牲一部分延迟性,并且对全局时钟的要求很高
- 弱一致性
- 系统中的某个数据被更新后,后续对该数据的读取操作可能得到更新后的值,也可能是更新前的值
- 但经过一段时间后,后续对该数据的读取都是更新后的值
- 最终一致性 - AWS DynamoDB
- 是弱一致性的特殊形式
- 存储系统保证,在没有新的更新的条件下,最终所有的访问都是更新后的值
- 无需等到数据更新被所有节点同步就可以读取
- 尽管不同的进程读同一数据可能会读到不同的结果
- 最终所有的更新会按时间顺序同步到所有节点
- 支持异步读取,延迟比较小
Durability
数据持久性
- 数据持久性意味着数据一旦被成功存储,就可以一直使用,即使系统中的节点下线、宕机或者数据损坏
- 不同的分布式数据库拥有不同级别的持久性 - 节点级别 / 集群级别
- 提高数据持久性的常规做法 - 数据复制
消息持久性
- 在分布式系统中,节点之间需要互相发送消息去同步以保证一致性
- 对于重要的系统而言,通常不允许任何消息的丢失
- 分布式系统中的消息通讯通常由分布式消息服务完成 - Kafka
- 当消息服务的节点发生了错误,已经发送的消息仍然会在错误解决之后被处理
- 如果一个消息队列声明了持久性,那么即使队列在消息发送之后掉线,仍然会在重新上线后收到该消息
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2024-10-02
Beam - WordCount
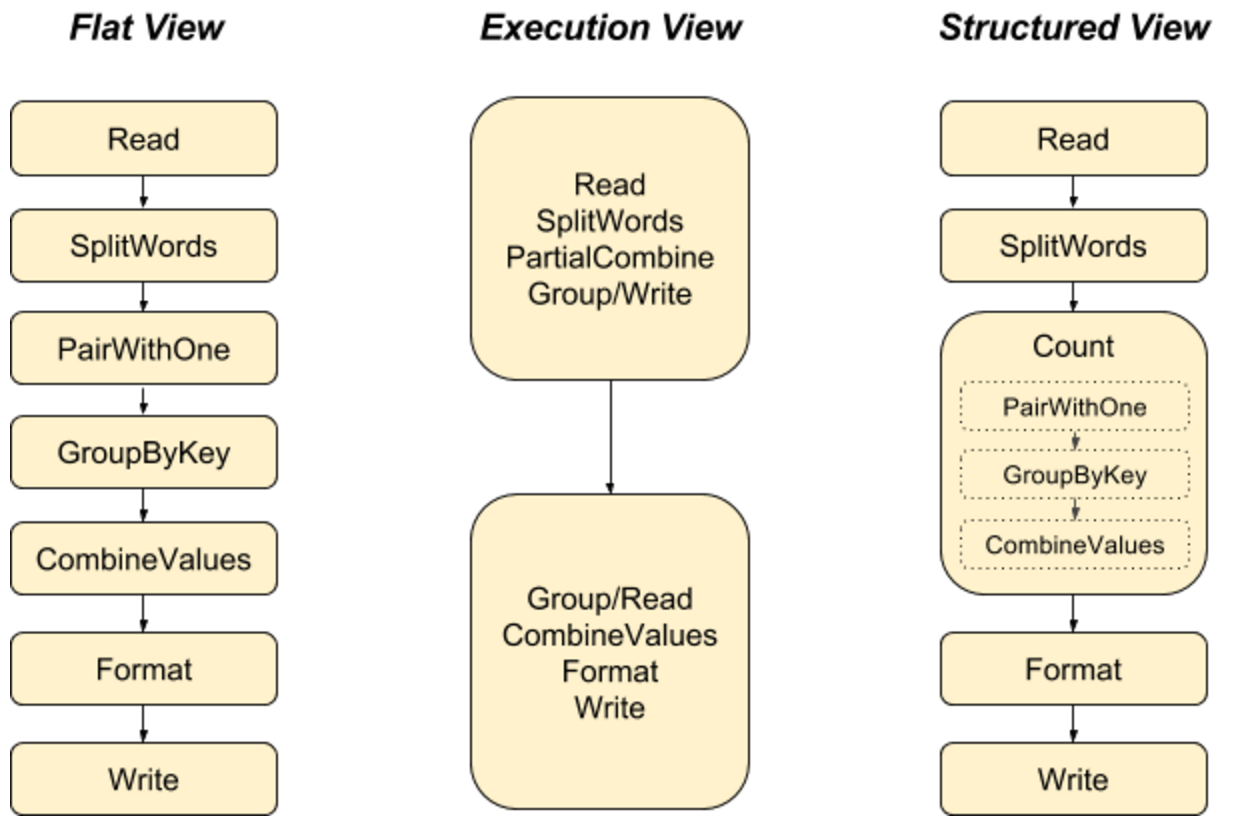
步骤 用 Pipeline IO 读取文本 用 Transform 对文本进行分词和词频统计 用 Pipeline IO 输出结果 将所有步骤打包成一个 Pipeline 创建 Pipeline 默认情况下,将采用 DirectRunner 在本地运行 1PipelineOptions options = PipelineOptionsFactory.create(); 一个 Pipeline 实例会构建数据处理的 DAG,以及这个 DAG 所需要的 Transform 1Pipeline p = Pipeline.create(options); 应用 Transform TextIO.Read - 读取外部文件,生成一个 PCollection,包含所有文本行,每个元素都是文本中的一行 123String filepattern = "file:///Users/zhongmingmao/workspace/java/hello-beam/corpus/shakespeare.txt";PCollection<String> lines = ...
2024-09-16
Big Data - Kappa
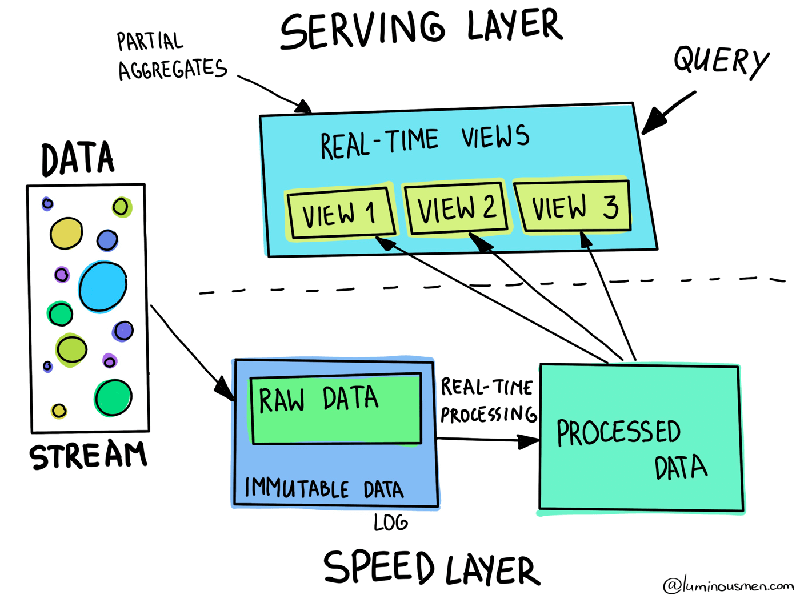
Lambda概述 Lambda 架构结合了批处理和流处理的架构思想 将进入系统的大规模数据同时送入两套架构层中,即 Batch Layer 和 Speed Layer 同时产生两套数据结果并存入 Serving Layer 中 优点 Batch Layer 有很好的容错性,同时由于保存着所有的历史记录,使得产生的数据具有很好的准确性 Speed Layer 可以及时处理流入的数据,具有低延迟性 最终 Serving Layer 将两套数据结合,并生成一个完整的数据视图提供给用户 Lambda 架构也具有很好的灵活性,可以将不同开源组件嵌入到该架构中 不足 使用 Lambda 架构,需要维护两个复杂的分布式系统,并保证它们逻辑上产生相同的结果输出到 Serving Layer 在分布式框架中进行编程是非常复杂的,尤其需要对不同的框架进行专门的优化 – 高昂的维护成本 维护 Lambda 架构的复杂性 – 同时维护两套系统架构 方向 - 改进其中一层的架构,让其具有另一层架构的特性 Kappa架构 Apache Kafka 具有永久保存数据日志的功能,基于该特性,可以让 Speed Laye...
2024-09-28
Beam - Pipeline IO
读取数据集 一个输入数据集的读取通常是通过 Read Transform 来完成 Read Transform 从外部源读取数据 - 本地文件、数据库、OSS、MQ Read Transform 返回一个 PCollection,该 PCollection 可以作为一个输入数据集,应用在各种 Transform 上 Pipeline 没有限制调用 Read Transform 的时机 可以在 Pipeline 最开始的时候调用 也可以在经过 N 个步骤的 Transforms 后再调用它来读取另外的数据集 本地文件 1PCollection<String> inputs = p.apply(TextIO.read().from(filepath)); Beam 支持从多个文件路径中读取数据集,文件名匹配规则与 Linux glob 一样 glob 操作符的匹配规则最终要和所使用的底层文件系统挂钩 从不同的外部源读取同一类型的数据来统一作为输入数据集 - 利用 flatten 操作将数据集合并 12345PCollection<String> input1 ...
2024-09-29
Beam - Pattern
Copier Pattern 每个数据处理模块的输入都是相同的,并且每个数据处理模块都可以单独并且同步地运行处理 1234567891011121314151617181920212223242526272829303132333435363738394041PCollection<Video> videoDataCollection = ...;// 生成高画质视频PCollection<Video> highResolutionVideoCollection = videoDataCollection.apply("highResolutionTransform", ParDo.of(new DoFn<Video, Video>(){ @ProcessElement public void processElement(ProcessContext c) { c.output(generateHighResolution(c.element())); }}));// 生成低画质视频...
2024-09-17
Spark - Overview
MapReduce概述 MapReduce 通过简单的 Map 和 Reduce 的抽象提供了一个编程模型 可以在一个由上百台机器组成的集群上并发处理大量的数据集,而把计算细节隐藏起来 各种各样的复杂数据处理都可以分解为 Map 和 Reduce 的基本元素 复杂的数据处理可以分解成由多个 Job(包含一个 Mapper 和一个 Reducer)组成的 DAG 然后,将每个 Mapper 和 Reducer 放到 Hadoop 集群上执行,得到最终结果 不足 高昂的维护成本 时间性能不达标 MapReduce 模型的抽象层次低 大量的底层逻辑需要开发者手工完成 - 用汇编语言开发游戏 只提供 Map 和 Reduce 操作 很多现实的数据处理场景并不适合用这个模型来描述 实现复杂的操作需要技巧,让整个工程变得庞大且难以维护 维护一个多任务协调的状态机成本很高,且扩展性很差 在 Hadoop 中,每个 Job 的计算结果都会存储在 HDFS 文件存储系统中 每一步计算都要进行硬盘的读取和写入,大大增加了系统的延迟 MapReduce 对于迭代算法的处理性能很差,而且非常耗资源 因...
2024-09-27
Beam - Pipeline
创建 在 Beam 中,所有的数据处理逻辑都会被抽象成 Pipeline 来运行 Pipeline 是对数据处理逻辑的一个封装 包括一整套流程 - 读取数据集、将数据集转换成想要的结果、输出结果数据集 创建 Pipeline 12PipelineOptions options = PipelineOptionsFactory.create();Pipeline p = Pipeline.create(options); 应用 PCollection 具有不可变性 一个 PCollection 一旦生成,就不能在增加或者删除里面的元素了 在 Beam 中,每次 PCollection 经过一个 Transform 之后,Pipeline 都会创建一个新的 PCollection 新创建的 PCollection 又成为下一个 Transform 的输入 原先的 PCollection 不会有任何改变 对同一个 PCollection 可以应用多种不同的 Transform 处理模型 Pipeline 的底层思想依然是 MapReduce 在分布式环境下,整个 Pipeline...