Beam - WordCount
步骤
- 用 Pipeline IO 读取文本
- 用 Transform 对文本进行分词和词频统计
- 用 Pipeline IO 输出结果
- 将所有步骤打包成一个 Pipeline

创建 Pipeline
默认情况下,将采用 DirectRunner 在本地运行
1 | PipelineOptions options = PipelineOptionsFactory.create(); |
一个 Pipeline 实例会构建数据处理的 DAG,以及这个 DAG 所需要的 Transform
1 | Pipeline p = Pipeline.create(options); |
应用 Transform
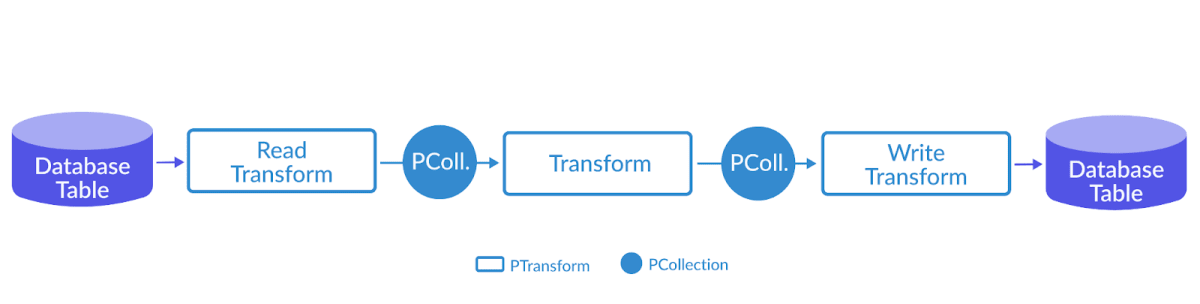
TextIO.Read - 读取外部文件,生成一个 PCollection,包含所有文本行,每个元素都是文本中的一行
1 | String filepattern = |
分词
1 | PCollection<String> words = |
Count Transform - 把任意一个 PCollection 转换成 Key-Value 组合
Key 为原来 PCollection 中非重复的元素,Value 为元素出现的次数
1 | PCollection<KV<String, Long>> counts = words.apply(Count.<String>perElement()); |
将 Key-Value 组成的 PCollection 转换成输出格式
1 | PCollection<String> formatted = |
TextIO.Write - 把最终的 PCollection 写进文本,每个元素都会被写成文本文件中独立的一行
1 | formatted.apply(TextIO.write().to("/tmp/wordcounts")); |
运行 Pipeline
Pipeline.run - 把 Pipeline 所包含的 Transform 优化并放到执行的 Runner 上执行 - 默认异步执行
1 | p.run().waitUntilFinish(); |
代码优化
独立 DoFn
提高:可读性 + 复用性 + 可测试性
ExtractWordsFn
1 | import org.apache.beam.sdk.metrics.Counter; |
FormatAsTextFn
1 | import org.apache.beam.sdk.transforms.DoFn; |
PTransform
PTransform - 整合一些相关联的 Transform
输入输出类型 - 一连串 Transform 的最初输入和最终输出
1 | import org.apache.beam.sdk.transforms.Count; |
参数化 PipelineOptions
1 | import org.apache.beam.sdk.options.Description; |
main
1 | public static void main(String[] args) { |
单元测试
将数据处理操作封装成 DoFn 和 PTransform - 可以独立测试
1 | public class ExtractWordsFnTest { |
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2024-09-26
Beam - Transform
DAG Transform 是 Beam 中数据处理的最基本单元 Beam 把数据转换抽象成有向图 反直觉 - PCollection 是有向图中的边,而 Transform 是有向图中的节点 区分节点和边的关键是看一个 Transform 是不是有一个多余的输入和输出 每个 Transform 都可能有大于一个的输入 PCollection,也可能输出大于一个的输出 PCollection Apply Beam 中的 PCollection 有一个抽象的成员函数 Apply,使用任何一个 Transform 时,都需要调用 Apply 123final_collection = input_collection.apply(Transform1).apply(Transform2).apply(Transform3) Transform概述 ParDo - Parallel Do - 表达的是很通用的并行处理数据操作 GroupByKey - 把一个 Key/Value 的数据集按照 Key 归并 可以用 ParDo 实现 GroupByKey 简单实现 - 放...
2024-09-29
Beam - Pattern
Copier Pattern 每个数据处理模块的输入都是相同的,并且每个数据处理模块都可以单独并且同步地运行处理 1234567891011121314151617181920212223242526272829303132333435363738394041PCollection<Video> videoDataCollection = ...;// 生成高画质视频PCollection<Video> highResolutionVideoCollection = videoDataCollection.apply("highResolutionTransform", ParDo.of(new DoFn<Video, Video>(){ @ProcessElement public void processElement(ProcessContext c) { c.output(generateHighResolution(c.element())); }}));// 生成低画质视频...

2024-09-23
Beam - Context
MapReduce架构思想 提供一套简洁的 API 来表达工程师数据处理的逻辑 在这套 API 底层嵌套一套扩展性很强的容错系统 计算模型 Map 计算模型从输入源中读取数据集合 这些数据经过用户所写的逻辑后生成一个临时的键值对数据集 MapReduce 计算模型会将拥有相同键的数据集集中起来发送到下一阶段,即 Shuffle 阶段 Reduce 接收从 Shuffle 阶段发送过来的数据集 在经过用户所写的逻辑后生成零个或多个结果 划时代意义 Map 和 Reduce 这两种抽象,其实可以适用于非常多的应用场景 MapReduce 的容错系统,可以让数据处理逻辑在分布式环境下有很好的扩展性(Scalability) 不足 使用 MapReduce 来解决一个工程问题,往往会涉及非常多的步骤 每次使用 MapReduce 时,都需要在分布式环境中启动机器来完成 Map 和 Reduce 步骤 并且需要启动 Master 机器来协调两个步骤的中间结果,存在不少的硬件资源开销 FlumeJava 将所有的数据都抽象成名为 PCollection 的数据结构 无论是从内存中读取的数据,...
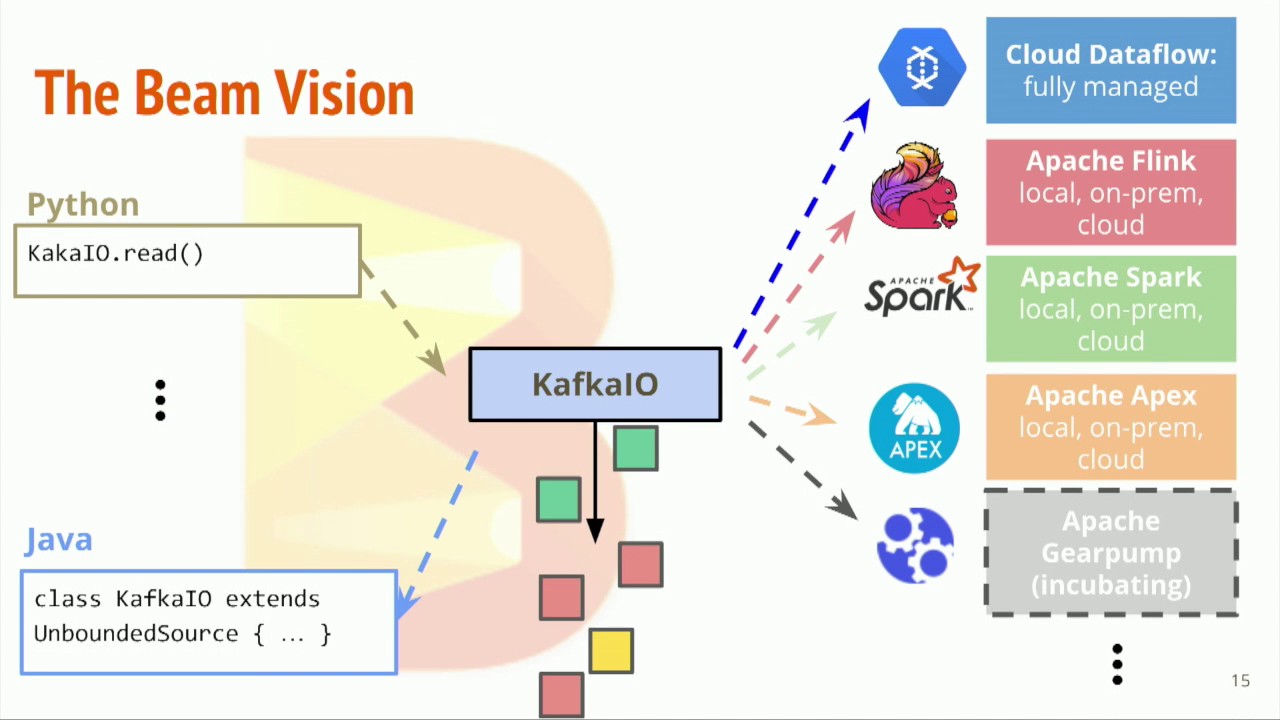
2024-10-04
Beam - Streaming
有界数据 vs 无界数据 在 Beam 中,可以用同一个 Pipeline 处理有界数据和无界数据 无论是有界数据还是无界数据,在 Beam 中,都可以用窗口把数据按时间分割成一些有限大小的集合 对于无界数据,必须使用窗口对数据进行分割,然后对每个窗口内的数据集进行处理 读取无界数据 withLogAppendTime - 使用 Kafka 的 log append time 作为 PCollection 的时间戳 12345678Pipeline pipeline = Pipeline.create();pipeline.apply( KafkaIO.<String, String>read() .withBootstrapServers("broker_1:9092,broker_2:9092") .withTopic("shakespeare") // use withTopics(List<String>) to read from multiple topics. .wi...
2024-09-27
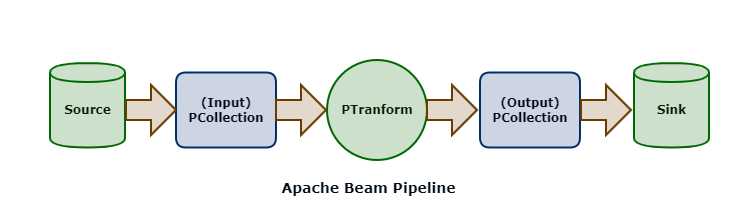
Beam - Pipeline
创建 在 Beam 中,所有的数据处理逻辑都会被抽象成 Pipeline 来运行 Pipeline 是对数据处理逻辑的一个封装 包括一整套流程 - 读取数据集、将数据集转换成想要的结果、输出结果数据集 创建 Pipeline 12PipelineOptions options = PipelineOptionsFactory.create();Pipeline p = Pipeline.create(options); 应用 PCollection 具有不可变性 一个 PCollection 一旦生成,就不能在增加或者删除里面的元素了 在 Beam 中,每次 PCollection 经过一个 Transform 之后,Pipeline 都会创建一个新的 PCollection 新创建的 PCollection 又成为下一个 Transform 的输入 原先的 PCollection 不会有任何改变 对同一个 PCollection 可以应用多种不同的 Transform 处理模型 Pipeline 的底层思想依然是 MapReduce 在分布式环境下,整个 Pipeline...
2024-09-25
Beam - PCollection
数据抽象 Spark RDD 不同的技术系统有不同的数据结构, 如在 C++ 中有 vector、unordered_map 几乎所有的 Beam 数据都能表达为 PCollection PCollection - Parallel Collection - 可并行计算的数据集,与 Spark RDD 非常类似 在一个分布式计算系统中,需要为用户隐藏实现细节,包括数据是怎样表达和存储的 数据可能来自于内存的数据,也可能来自于外部文件,或者来自于 MySQL 数据库 如果没有一个统一的数据抽象的话,开发者需要不停地修改代码,无法专注于业务逻辑 Coder 将数据类型进行序列化和反序列化,便于在网络上传输 需要为 PCollection 的元素编写 Coder Coder 的作用与 Beam 的本质紧密相关 计算流程最终会运行在一个分布式系统 所有的数据都可能在网络上的计算机之间相互传递 Coder 就是告诉 Beam 如何将数据类型进行序列化和反序列化,以便于在网络上传输 Coder 需要注册进全局的 CoderRegistry 为自定义的数据类型建立与 Coder 的对应关系,无...