
Observability - Concept
概述
- 可观测性 - 从系统向外部输出的信息来推断出系统内部状态的好坏
- 可观测强调的是一种度量能力
- 在不发布新代码(如新增诊断日志)的情况下理解系统内部状态 - 系统具有可观测性
Metrics + Logs + Tracing
Metrics + Logs + Tracing 只是遥测数据类型,而 Observability 并非具体技术,而是系统属性,类似于 HA
| Key | Desc |
|---|---|
| Metrics | 在一段时间内测量的数值,默认是结构化的,便于查询和存储优化 |
| Logs | 对特定时间发生的事件的文本记录,一般是非结构化字符串,会在程序执行期间被写入磁盘 |
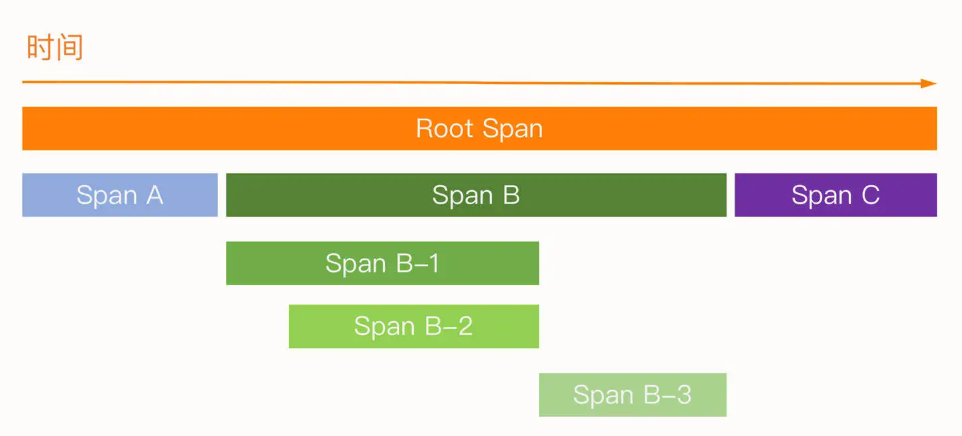
| Tracing | 表示请求通过分布式系统的端到端的路径,执行的每个操作被称为 Span |
Tracing 一般会通过可视化的瀑布图展现出来
Metrics
- 由于 Metrics 最大的特点是聚合性
- Metrics 生成的数值是反映预定义时间段内系统状态的汇总报告 - 缺乏颗粒度
- Metrics 之间可能彼此不相关
- Metrics 常用于 - 静态仪表盘的构建、随时间变化的趋势分析、监控维度是否保持在定义的阈值内
- 但都不是 Observability,因为对于故障排查来说,这些信息远远不够
Logs
- Logs 本质上是离散事件,为了便于阅读,一般是一大块非结构化文本
- 需要通过日志解析器(复杂规则)才能完成结构化、索引、搜索
- 结构化 - 创建结构化的日志数据,如 Docker 日志
Tracing
- Tracing 的主要问题 - 仅依靠开发人员进行 Instrument,是远远不够的
- 实现复杂度
- 大量的应用程序需要使用额外的开源框架或库构建的
- 在多语言架构下,会变得更具有挑战性
- 实现成本
- Instrument 的成本比较高,比较很难做到全面覆盖,适用于具体的业务场景
- 随着产品迭代,可能需要反复增加 Instrument,增加工作量且降低系统可靠性
Structured Events
Observability 定义的是一种度量能力,帮助用户更好地理解和解释系统当前所处的任何状态
- Structured Events 是 Observability 的基础
- 事件是指特定请求与服务交互时所有信息的记录,通过事件能了解到服务所受到的影响
- Structured Events 的定义
- 在请求第一次进入服务时,会有一个 Empty Map 被初始化出来
- 在该请求的生命周期内发生的任何细节或者有价值的上下文,都会附加到 Map 中
- 当请求即将退出或者出错时,刚所发生的事情都被记录下来了
- 写入该 Map 的数据被组织和格式化为 Key-Value Pair,以便于搜索 - Structured Events
- 在调试服务问题时,可以比较 Structured Events,及时发现异常 - 任意宽度 - 基数 + 维度
基数
- 在数据库中,基数是指包含在一个集合中的唯一值的数量
- 低基数(性别) - 很多重复的值;高基数(User Id) - 很大比例是完全唯一的值
- 高基数信息在调试或者理解系统的数据时非常有用 - userid + requestid - 精确定位
维度
- 基数是数据中值的唯一性,而维度是数据中 Key 的数量
- 在可观测系统中,遥测数据被生成任意宽度的结构化事件,其中可以包含成百上千的键值对(即维度)
- 事件范围越广,事件发生时获取到的上下文就越丰富,越容易定位问题
对比
传统监控
- 仪表盘 - 受到告警时,某项指标超过了阈值,但不能完全了解系统发生了什么
- 传统监控只能解决 Known-Unknowns 问题 - 完全被动
- 每次出现故障时,复盘的结果是增加一些指标或者告警,然后这些告警可能再也不会被触发
- 例如 - CPU 使用率达到了 90%,但却不知道原因
可观测性
- 可观测性通过查看和分析高纬度和高基数的数据,发现在复杂系统中的隐藏问题 - 无需预设问题发生的模式
- 通过数据的关联,允许从任何角度分析问题,而不是依靠直觉和经验
- 针对应用软件监控,不仅仅是基础设施,目标是保障应用软件的可靠性和稳定性
- 全面搜集 + 关联数据
- 数据采集 - 底层操作系统、各种语言环境的网络协议、前端用户访问数据
- 利用数据所提供的可视化、交互性来真正让可观测性落地
- 可观测性强调的是从应用和业务维度,用各种数据垂直且实时地描述应用的全貌
- 采用的不是传统的分层逻辑,不是用不同的独立的监控系统分开关注每一层的情况
- 传统运维的仪表盘在分布式架构中的用处越来越小
- 对于复杂系统来说,很多之前没有发生过的问题,单靠仪表盘是不能有效发现根本原因
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2025-01-02
Observability - OpenTelemetry Doc V2
Language APIs & SDKs OpenTelemetry code instrumentation is supported for many popular programming languages OpenTelemetry code instrumentation is supported for the languages listed in the Statuses and Releases table below. For Go, .NET, PHP, Python, Java and JavaScript you can use zero-code solutions to add instrumentation to your application without code changes. If you are using Kubernetes, you can use the OpenTelemetry Operator for Kubernetes to inject these zero-code solutions into your appli...

2025-01-03
Observability - OpenTelemetry Node.js
OverviewStatus and Releases Traces Metrics Logs Stable Stable Development Client instrumentation for the browser is experimental and mostly unspecified. Version Support OpenTelemetry JavaScript supports all active or maintenance LTS versions of Node.js. Previous versions of Node.js may work, but are not tested by OpenTelemetry. OpenTelemetry JavaScript has no official supported list of browsers. It is aimed to work on currently supported versions of major browsers. OpenTelemetry JavaScript f...
2025-01-24
Observability - Prometheus Server V1
OpenTelemetry vs Prometheus123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106关系概述:互补为主,渐趋融合OpenTelemetry 和 Prometheus 在指标领域主要是互补关系,而非冲突。两个项目都在积极合作以实现更好的互操作性。1. 定位差异Prometheus:- 完整的监控系统(采集、存储、查询、告警)- 专注于指标监控- 拉模型(Pull-based)为主- 拥有成熟的时序数据库和查询语言 PromQLOpenTelemetry:- 标准化的遥测数据收集框架- 支持三大信号:指标、追踪、日志- 推模型(Push-based)为主- 不提供存储和查询后端2. 技术模型对比| 特性 | Promet...

2025-01-23
Observability - Prometheus Concepts
Data model Prometheus fundamentally stores all data as time series streams of timestamped values belonging to the same metric and the same set of labeled dimensions. Besides stored time series, Prometheus may generate temporary derived time series as the result of queries. Metric names and labelsEvery time series is uniquely identified by its metric name and optional key-value pairs called labels. Metric names Metric names SHOULD specify the general feature of a system that is measured e.g. http_req...
2024-10-14
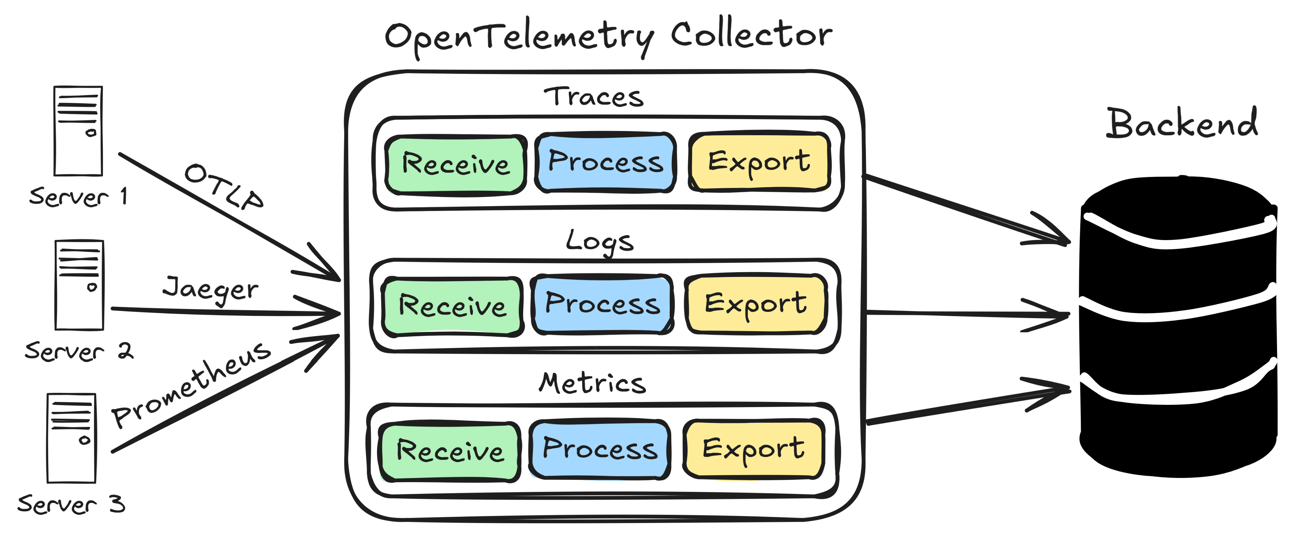
Observability - OpenTelemetry
简介 OpenTelemetry 简称 OTel,是 CNCF 的一个可观测性项目 OpenTelemetry 旨在提供可观测性领域的标准化方案 解决遥测数据的数据建模、采集、处理和导出等标准化问题,并能将数据发送到后端 - 避免厂商锁定 历史 在 OpenTelemetry 之前,已经出现过 OpenTracing 和 OpenCensus 两套标准 在 APM 领域,有 Jaeger、Pinpoint、Zipkin 等多个开源产品,都有独立的数据采集标准和 SDK OpenTracing 制订了一套与平台和厂商无关的协议标准,能够方便地添加或者更换底层 APM 实现 2016 年 11 月,CNCF 接受 OpenTracing 成为第三个项目 - Kubernetes + Prometheus OpenCensus 由谷歌发起,包括 Metrics,而微软也加入了 OpenCensus 在功能和特性上,OpenTracing 和 OpenCensus 差不多,都想统一对方,此时 OpenTelemetry 横空出世 OpenTelemetry 同时兼容 OpenTracing 和 O...
2025-01-21
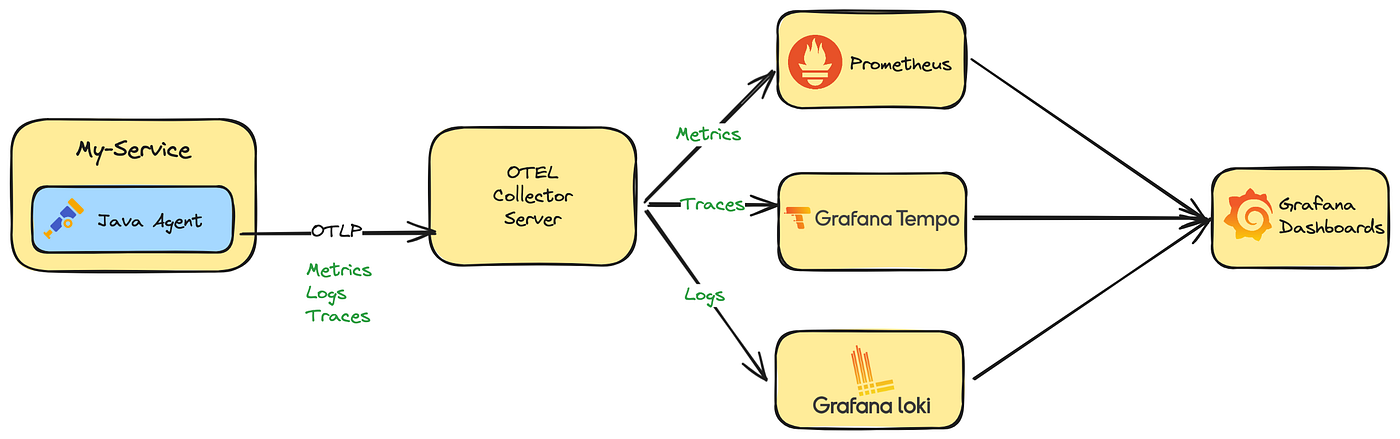
Observability - OpenTelemetry Java Zero Code
Java Agent Zero-code instrumentation with Java uses a Java agent JAR attached to any Java 8+ application. It dynamically injects bytecode to capture telemetry from many popular libraries and frameworks. It can be used to capture telemetry data at the “edges” of an app or service such as inbound requests, outbound HTTP calls, database calls, and so on. Getting startedSetup Download opentelemetry-javaagent.jar from Releases of the opentelemetry-java-instrumentation repository place the JAR in your pre...




