eBPF - Principle
发展历程
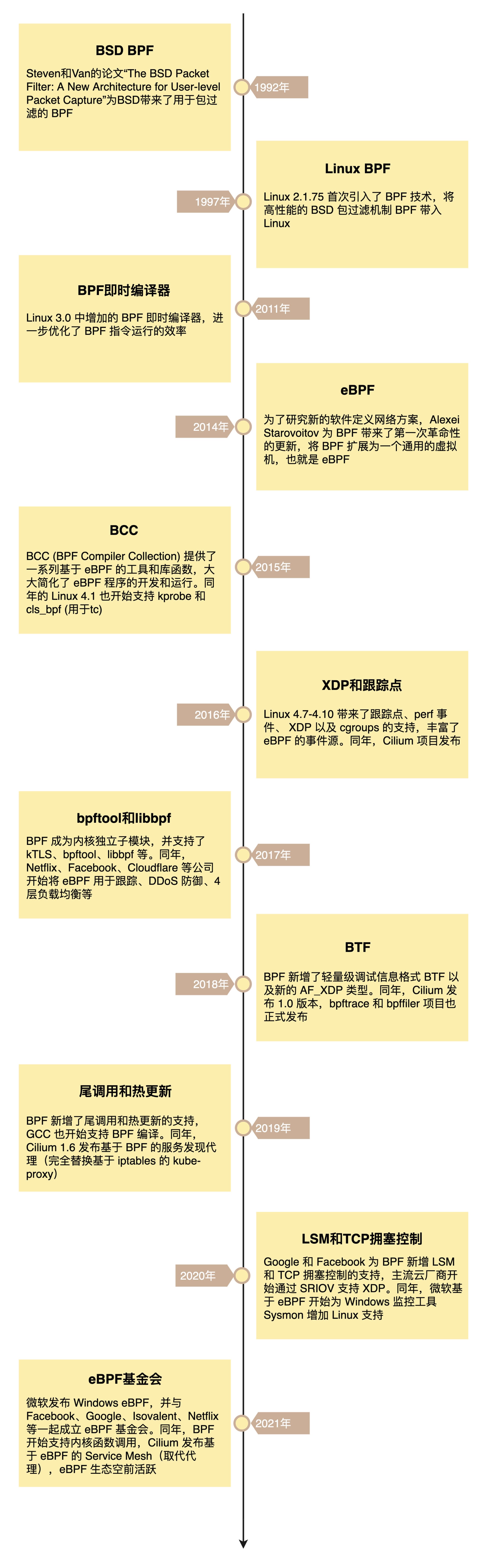
- 1992 年,在 BSD 操作系统中引入了革命性的包过滤机制 BPF,性能非常好
- BPF 的两大设计
- 内核态引入一个新的虚拟机,所有指令都在内核虚拟机中运行
- 用户态使用 BPF 字节码来定义过滤表达式,然后传递给内核,由内核虚拟机解释执行
- BPF 使得包过滤可以直接在内核中执行,避免向用户态复制每个数据包,从而极大提升了包过滤的性能,被各大操作系统广泛接受
- BPF 诞生 5 年后,在 Linux 2.1.75 首次引入了 BPF 技术,在 Linux 3.0 中增加的 BPF JIT,替换掉性能更差的解释器,进一步优化了 BPF 指令运行的效率
- 直到此时,BPF 的应用领域还仅限于网络包过滤
- 2014 年,将 BPF 扩展为一个通用的虚拟机,即 eBPF
- eBPF 不仅扩展了寄存器的数量,引入了全新的 BPF 映射存储
- 还在 4.x 内核中将原本单一的数据包过滤事件逐步扩展到了内核态函数、用户态函数、跟踪点、性能事件以及安全控制等
- eBPF 的诞生了 BPF 技术的转折点,使得 BPF 不再仅限于网络栈,而是成为内核的一个顶级子系统 - 最活跃
- eBPF 无需修改内核源码和重新编译就可以扩展内核的功能
工作原理
- eBPF 程序并不像常规的线程那样,启动后就一直运行在那里,它需要内核事件触发后才会执行
- 事件 - 系统调用、内核跟踪点、内核函数和用户态函数的调用退出、网络事件等
- 借助于强大的内核态插桩(kprobe)和用户态插桩(uprobe),eBPF 程序几乎可以在内核和应用的任意位置进行插桩
- 确保安全和稳定是 eBPF 的首要任务,不安全的 eBPF 程序不会提交到内核虚拟机中执行
执行过程
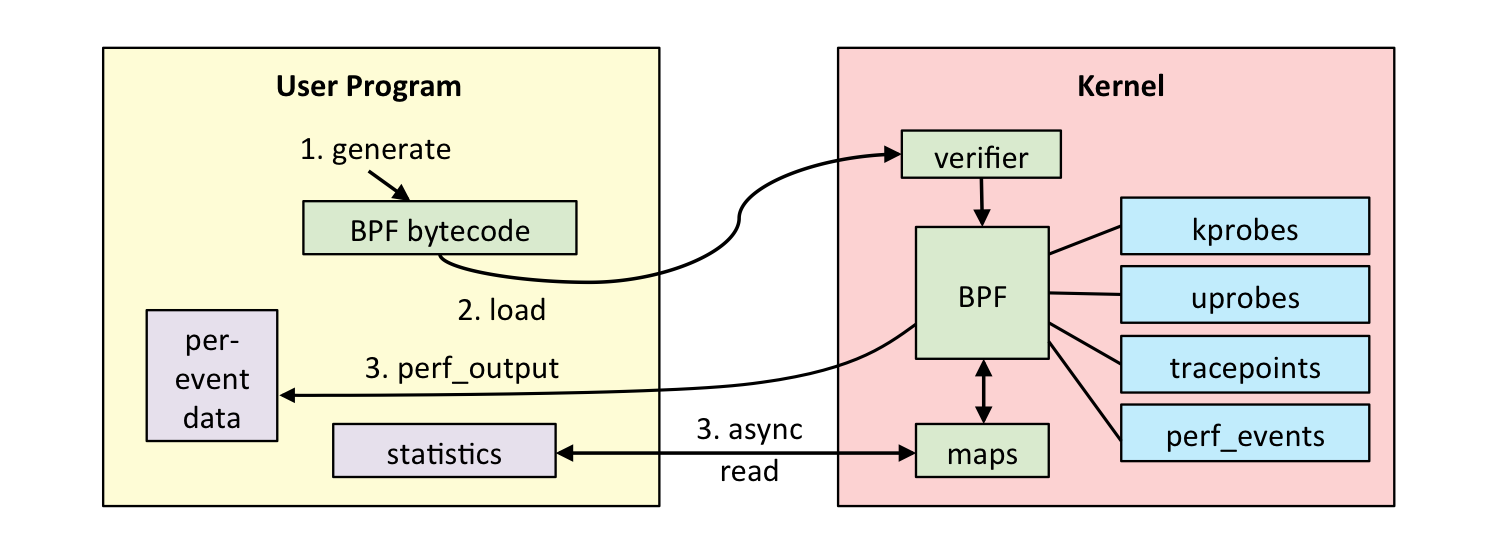
- 借助 LLVM 把编写的 eBPF 程序转换为 BPF 字节码,然后再通过 bpf 系统调用提交给内核执行
- 内核在接受 BPF 字节码之前,会首先通过验证器对字节码进行校验,只有校验通过的 BPF 字节码才会提交到 JIT 执行
- 如果 BPF 字节码中包含了不安全的操作,验证器会直接拒绝 BPF 程序的执行,典型的验证过程
- 只有特权进程才可以执行 bpf 系统调用
- BPF 程序不能包含无限循环
- BPF 程序不能导致内核崩溃
- BPF 程序必须在有限时间内完成
- BPF 程序可以利用 BPF 映射进行存储,而用户程序也需要通过 BPF 映射与运行在内核中的 BPF 程序进行交互
- eBPF 程序的运行需要经历编译、加载、验证和内核态执行等过程,而用户态程序则需要借助 BPF 映射来获取内核态 eBPF 程序的运行状态
在性能观测中,BPF 程序收集内核运行状态存储在 BPF 映射中,用户程序再从 BPF 映射中读取这些状态
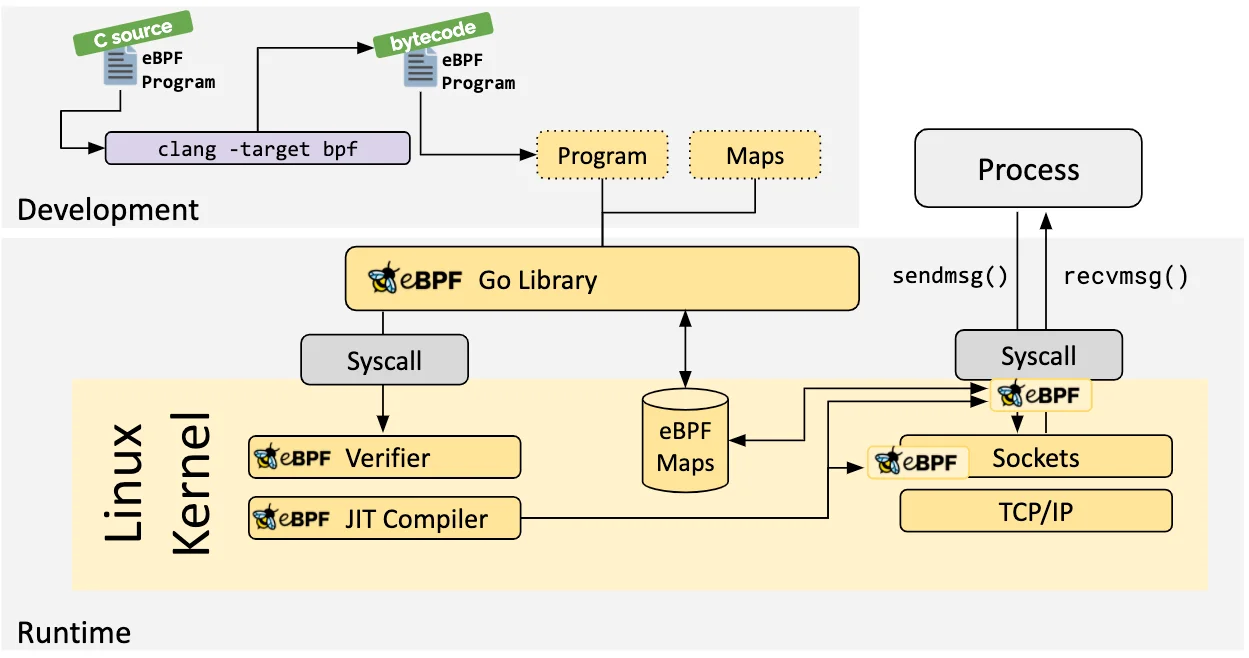
局限性
- eBPF 程序必须被验证器校验通过才能执行,且不能包含无法到达的指令
- eBPF 程序不能随意调用内核函数,只能调用在 API 中定义的辅助函数
- eBPF 程序栈空间最多只有 512 字节,要更大的存储,只能借助于 BPF 映射
- 在内核 5.2 之前,eBPF 字节码最多只支持 4096 条指令,在 5.2 内核版本将该限制提高到了 100 万条
- 内核快速发展,在不同版本内核中运行时,需要访问内核数据结构的 eBPF 程序很可能需要调整源码,并重新编译
- eBPF 很多新特性都是在 4.x 版本中才逐步增加的,要稳定运行 eBPF 程序,内核版本至少要 **4.9+**,推荐 5.x
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2024-10-17
eBPF - Overview
eBPF Extended Berkeley Packet Filter eBPF 是一种数据包过滤技术,从 BPF 技术扩展而来 BPF 提供了一种在内核事件和用户程序事件发生时安全注入代码的机制,让非内核开发人员也可以对内核进行控制 随着内核的发展,BPF 从最初的数据包过滤,扩展到网络、内核、安全、跟踪等,扩展后的 BPF 被称为 eBPF,早期的 BPF 被称为经典 BPF,即 cBPF 现代内核所运行的都是 eBPF 特性 在 eBPF 之前,内核模块是注入内核的最主要机制 由于缺乏对内核模块的安全控制,内核的基本功能很容易被一个有缺陷的内核模块破坏 eBPF 借助 JIT,在内核中运行一个虚拟机,保证只有被验证安全的 eBPF 指令才会被内核执行 同时,eBPF 指令依然运行在内核中,无需向用户态复制数据,极大地提高了事件处理的效率 eBPF 在故障诊断、网络优化、安全控制、性能监控等领域获得了大量应用 高性能网络负载均衡器 - Katran 容器网络方案 - Cilium 内核跟踪排错工具 - BCC + bpftrace 概览 技术栈 掌握 eBPF 并不需要掌握内核开发...

2025-01-23
Observability - Prometheus Concepts
Data model Prometheus fundamentally stores all data as time series streams of timestamped values belonging to the same metric and the same set of labeled dimensions. Besides stored time series, Prometheus may generate temporary derived time series as the result of queries. Metric names and labelsEvery time series is uniquely identified by its metric name and optional key-value pairs called labels. Metric names Metric names SHOULD specify the general feature of a system that is measured e.g. http_req...

2025-01-05
Observability - OpenTelemetry Python
OverviewStatus and Releases Traces Metrics Logs Stable Stable Development Version supportOpenTelemetry-Python supports Python 3.9 and higher. Installation The API and SDK packages are available on PyPI, and can be installed via pip: 12pip install opentelemetry-apipip install opentelemetry-sdk In addition, there are several extension packages which can be installed separately as: 12pip install opentelemetry-exporter-{exporter}pip install opentelemetry-instrumentation-{instrumen...

2025-01-01
Observability - OpenTelemetry Doc V1
架构 OpenTelemetry 也被称为 OTel,是一个供应商中立的、开源的可观测性框架, 可用于插桩、生成、采集和导出链路、 指标和日志等遥测数据 概述 专注于数据标准,不提供存储和可视化 OpenTelemetry 是一个可观测性框架和工具包, 旨在创建和管理遥测数据,如链路、 指标和日志 OpenTelemetry 是供应商和工具无关的,这意味着它可以与各种可观测性后端一起使用, 包括 Jaeger 和 Prometheus 这类开源工具以及商业化产品 OpenTelemetry 不是像 Jaeger、Prometheus 或其他商业供应商那样的可观测性后端 OpenTelemetry 专注于遥测数据的生成、采集、管理和导出 OpenTelemetry 的一个主要目标是, 无论应用程序或系统采用何种编程语言、基础设施或运行时环境,你都可以轻松地将其仪表化 遥测数据的存储和可视化是有意留给其他工具处理 可观测性 可观测性是通过检查系统输出来理解系统内部状态的能力 在软件的背景下,这意味着能够通过检查遥测数据(包括链路、指标和日志)来理解系统的内部状态 要使系统可观测,必须对...
2024-10-14
Observability - OpenTelemetry
简介 OpenTelemetry 简称 OTel,是 CNCF 的一个可观测性项目 OpenTelemetry 旨在提供可观测性领域的标准化方案 解决遥测数据的数据建模、采集、处理和导出等标准化问题,并能将数据发送到后端 - 避免厂商锁定 历史 在 OpenTelemetry 之前,已经出现过 OpenTracing 和 OpenCensus 两套标准 在 APM 领域,有 Jaeger、Pinpoint、Zipkin 等多个开源产品,都有独立的数据采集标准和 SDK OpenTracing 制订了一套与平台和厂商无关的协议标准,能够方便地添加或者更换底层 APM 实现 2016 年 11 月,CNCF 接受 OpenTracing 成为第三个项目 - Kubernetes + Prometheus OpenCensus 由谷歌发起,包括 Metrics,而微软也加入了 OpenCensus 在功能和特性上,OpenTracing 和 OpenCensus 差不多,都想统一对方,此时 OpenTelemetry 横空出世 OpenTelemetry 同时兼容 OpenTracing 和 O...

2025-01-02
Observability - OpenTelemetry Doc V2
Language APIs & SDKs OpenTelemetry code instrumentation is supported for many popular programming languages OpenTelemetry code instrumentation is supported for the languages listed in the Statuses and Releases table below. For Go, .NET, PHP, Python, Java and JavaScript you can use zero-code solutions to add instrumentation to your application without code changes. If you are using Kubernetes, you can use the OpenTelemetry Operator for Kubernetes to inject these zero-code solutions into your appli...