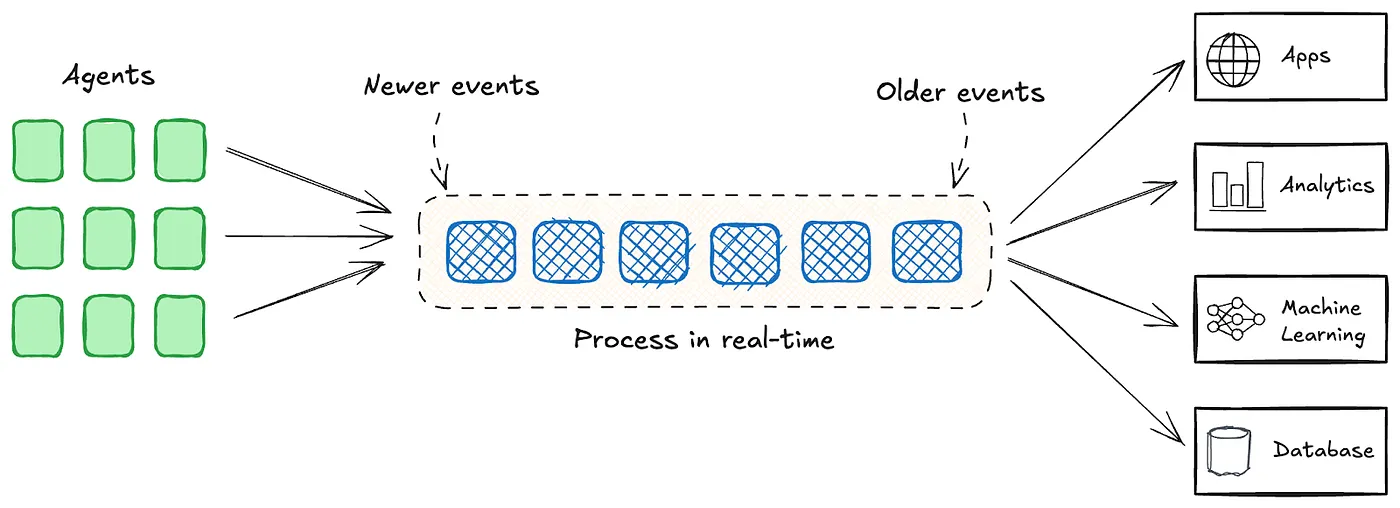
Agentic Harness - Concept
概述
- Harness 原意是”马具、线束”,在软件工程中通常指”测试线束”(test harness) - 一组用于运行和监控程序的脚手架代码
- 在 AI Agent 语境下,Harness 指的是包裹在基础模型(LLM)外层的一整套运行时基础设施,它不是模型本身,而是让模型能够”干活”的那套框架
核心组成
| 组件 | 作用 |
|---|---|
| Tool Calling | 让 Agent 调用外部工具(搜索、代码执行、API 调用等) |
| Memory Store | 短期/长期记忆,让 Agent 跨轮次保留上下文 |
| Orchestration | 编排多步推理流程(ReAct、Plan-then-Execute 等) |
| Guardrails | 安全护栏、输出校验、权限控制 |
| Observability | 日志、追踪、监控 Agent 的决策过程 |
单独的 LLM 只是一个 text-in / text-out 的函数,Harness 把它变成了一个能
| Harness 赋能 LLM | 描述 |
|---|---|
| 感知环境 | 通过工具获取实时信息 |
| 持久记忆 | 不局限于单次对话的上下文窗口 |
| 自主决策 | 多步规划、条件分支、错误重试 |
| 安全可控 | 在边界内行动,输出可审计 |
- 可以把 LLM 想象成发动机,Harness 就是整辆汽车 - 底盘、方向盘、仪表盘、刹车缺一不可
- 当前典型的 Harness 实现包括
- LangChain/LangGraph
- CrewAI
- AutoGen
- OpenAI Agents SDK
- Anthropic Claude Agent SDK
- DeerFlow
- MCP(Model Context Protocol)则是标准化工具接入的一种协议层,也是 Harness 生态的一部分
Harness 框架对比
架构模型
| 框架 | 核心抽象 | 编排模型 | 状态管理 |
|---|---|---|---|
| LangGraph | 有向图(节点+边+条件路由) | 显式图结构,确定性控制流 | 内置 checkpoint,可持久化到 Redis/PG |
| 角色团队(Agent=角色,Task=任务) | 声明式任务编排,顺序/并行 | 隐式传递,缺乏显式状态管理 | |
| 多智能体对话(消息交换协议) | 对话式自由路由,任意 Agent 互发消息 | 对话历史即状态,无结构化持久化 | |
| 原生 Tool Calling + Handoff | 基于 OpenAI Responses API 的编排 | 依赖 OpenAI 平台状态管理 | |
| Anthropic Claude Agent SDK | 单 Agent + 工具循环 | ReAct 循环(思考→行动→观察) | 本地文件系统持久化(如 Claude Code 的 memory) |
| DeerFlow 2.0 | SuperAgent + 子 Agent 层级 | Lead Agent 分解任务,子 Agent 并行执行,基于 LangGraph 构建 | 跨会话长期记忆 + 文件系统 + 子 Agent 隔离上下文 |
关键工程差异
LangGraph
最大控制力,最陡学习曲线
- 你需要用图思维(nodes/edges/state reducers)来构建一切
- 复杂条件分支是强项:根据工具返回结果动态路由、重试、升级
- 生产部署必须配置持久化 checkpoint store,否则进程崩溃丢失所有状态
- 并行执行需要手动实现 fan-out/fan-in
- 适合:有复杂分支逻辑、需要确定性执行路径的生产级工作流
CrewAI
最快原型,上限最低
- 用”角色+任务“的心智模型,2 小时就能跑起 3 Agent 流水线
- 但自定义验证逻辑要和框架对抗而非配合 - LangGraph 4 小时的事,CrewAI 要 2 天
- 长任务 12 步以上完成率从 84% 暴跌到 61%(无上下文压缩机制)
- 适合:快速验证概念、角色边界清晰的任务
AutoGen
研究灵活性最强
- Agent 间自由对话,无需预设流程,适合”不知道下一步该干啥”的研究型任务
- Human-in-the-loop 是一等公民(HumanProxyAgent)
- 代价:确定性差,Agent 可能陷入消息死循环,需自建终止条件和循环检测
- 适合:探索性研究、人工审核节点多的工作流
OpenAI Agents SDK
最紧密集成,零可移植性
- Handoff 原语设计优秀:不仅指定”交给谁”,还定义传什么上下文、做什么校验、失败怎么回退
- 原生结构化输出消除了 schema 验证失败的一大类问题
- 但只能用 OpenAI 模型(GPT-4o/o3 等),换 Claude/Gemini 基本不可行
- 适合:全栈 OpenAI 生态、对结构化输出要求严格的场景
Anthropic Claude Agent SDK
单 Agent 深度执行
- 不走多 Agent 协作路线,而是一个 Agent + 工具循环的深度执行模型
- ReAct 模式:Think → Act → Observe 循环,强调”思考过程可见“
- 工具扩展通过 MCP(Model Context Protocol)标准化接入
- 持久化走本地文件系统(如 .claude/ 目录),不走远程服务
- 典型体现:Claude Code 本身就是这个 SDK 的产物 - 一个能在终端里读写文件、执行命令的 Agent
- 适合:单 Agent 深度任务(编码、文件操作)、MCP 工具生态
DeerFlow 2.0
最完整的”开箱即用“ Harness
- 底层基于 LangGraph + LangChain 重建(2.0 是完全重写,与 1.x 无关)
- 核心差异化:给了 Agent 一台真正的电脑
- Docker 沙箱隔离执行环境 + 完整文件系统
- Agent 直接执行 shell 命令,不是”建议你运行”而是自己跑
- 子 Agent 并行执行,各自隔离上下文,结果汇总结合成最终产出
- 内置能力最丰富:技能系统(SKILL.md)、长期记忆、MCP Server、IM 通道(飞书/Slack/Telegram)
- 模型无关(OpenAI/Claude/DeepSeek/Ollama 都行)
- 适合:需要端到端自动化执行的研究、编码、内容生成任务
技术选型
没有框架是生产就绪的 - 它们都是地板,不是天花板,真正决定完成率的是你在上面搭的 Harness 层:验证循环、重试逻辑、上下文管理、可观测性。
| 选择逻辑 | Harness 框架 |
|---|---|
| 控制力 | LangGraph |
| 快出原型 | CrewAI |
| 研究灵活性 | AutoGen |
| 全押 OpenAI | OpenAI Agents SDK |
| 单 Agent 深度执行 | Claude Agent SDK |
| 开箱即用的完整 Harness | DeerFlow 2.0 |
Claude Code
| 通用 Harness | Claude Code | 说明 |
|---|---|---|
| Tool Calling | Tools(含 Agent Tool) | 子 Agent 是 Tool 的一种,不是 Orchestration |
| Memory Store | Context + Memory | 拆成短期/长期两个一等组件 |
| Orchestration | 无对应组件 | 单 Agent ReAct 循环,不需要编排层 |
| Guardrails | Permissions + Hooks | 权限边界 + 自动化约束 |
| Observability | 不显式列出 | Hooks + 本地日志隐式解决 |
编排 vs 委派
Claude Code 的子 Agent 不是编排 - 把这个子任务外包出去,结果拿回来我自己继续 - 本质上是一次 Tools 调用
1 | 关键区别:Orchestration vs 委托执行 |
本质区别
| 通用 Orchestration | Claude Code 子 Agent | |
|---|---|---|
| 定位 | 系统的核心骨架 | 一种 Tool |
| Agent 关系 | 多个 Agent 对等协作 | 主 Agent 委托,子 Agent 返回结果 |
| 生命周期 | Agent 可以长期运行、互相通信 | 子 Agent 随 Task 创建,完成后销毁 |
| 上下文 | 各 Agent 有独立上下文,编排层管理传递 | 子 Agent 结果汇总回主 Agent 上下文 |
| 决策权 | 编排层决定下一步谁执行 | 主 Agent 自己决定是否调用子 Agent |
什么是 Agent Harness?
一句话概述
Agent Harness 是包裹在 LLM 外面的那一整套软件基础设施 - 模型本身之外的”所有东西”
核心类比
- 把 LLM 比作引擎,Agent Harness 就是整辆汽车(方向盘、变速箱、底盘、仪表盘)
- 引擎提供动力,但真正能让车跑起来、转弯、刹车的,是周围的系统
Harness 具体做什么 - 管理 context(上下文)的完整生命周期
| 阶段 | 说明 |
|---|---|
| Intent Capture | 捕获用户意图 |
| Specification | 将意图转化为具体规格/指令 |
| Compilation | 编译成可执行的步骤 |
| Execution | 调用工具、执行操作 |
| Verification | 验证执行结果是否正确 |
| Persistence | 持久化记忆和信息 |
为什么重要
| 产品形态 | 组成 |
|---|---|
| 早期 ChatGPT | LLM + 聊天界面(简单) |
| 现在的 AI 助手 | LLM + Orchestrator(编排器)+ Harness(工具架) |
- Orchestrator - 控制多步推理流程(比如 chain-of-thought、plan-execute)
- Harness - 让模型能调用工具、管理文件、维护长对话记忆
关键洞察
- AI 助手的实际效果,往往取决于 Harness 的质量,而非模型本身的参数大小
- 一个普通模型配上优秀的 Harness,可能比一个强大的裸模型表现更好
Chain-of-Thought vs Plan-Execute - 可搭配使用
Plan 阶段:用 CoT 来拆解出好的计划 + Execute 阶段:每个 step 内部也可以用 CoT 来推理
| Chain-of-Thought | Plan-Execute | |
|---|---|---|
| 思想 | 边想边做,逐步推理,每一步的输出作为下一步的输入 | 先规划再执行,先拆解出完整计划,再逐步执行 |
| 本质 | 推理策略 | 编排模式 |
| 重点 | 怎么想 | 怎么做 |
| 结构 | 线性链式 | 两阶段:规划-执行 |
| 可回溯 | 不行,走到底 | 可以,重新规划 |
| 适用 | 数学、逻辑推理 | 多工具协作、复杂任务 |
为什么 AI 需要 Harness?
- LLM 从”问答玩具“进化到”干活工具“的过程中,裸模型搞不定了
- Harness 解决的就是 LLM 先天不具备的那些”胶水“问题 - 记忆、工具调用、流程编排、长任务管理
- LLM 负责”聪明“,Harness 负责”能干“
| 阶段 | 模式 | 需求 |
|---|---|---|
| 早期 | 一问一答 | 裸 LLM 足够 |
| 现在 | 持久化、多工具、多步骤 | 需要 Harness |
痛点 1 - 记忆有限
Limited Memory
- 痛点描述:LLM 有固定的上下文窗口,每次对话都是”失忆重启”
- Harness 解法
- 持久化记忆 - 跨 Session 保存上下文
- Compaction(压缩/摘要) - 比如 Claude Agent SDK 会把过去的对话浓缩,让长任务能跨越多个上下文窗口继续推进
痛点 2 - 只会”说”不会”做”
Tool Use
- 痛点描述:LLM 只能输出文本,但实际任务需要:搜索网页、执行代码、查数据库、生成图片……
- Harness 解法
- 监听模型的输出,识别出”工具调用“指令
- 代替模型去执行这些操作,把结果喂回去
- 相当于给模型装上了”手和眼睛”
痛点 3 - 缺乏结构化规划
Structured Workflows
- 痛点描述:复杂任务需要拆解、规划、验证,没有结构约束,AI 容易产出”看起来对但实际经不起推敲“的结果
- Harness 解法
- 捕获用户意图 → 制定计划 → 设定验收标准 → 逐步执行并验证
- 本质上就是给 AI 加了流程管理和护栏
痛点 4 - 长周期任务管理
Long-horizon Tasks
- 痛点描述
- 一个任务可能跑几小时甚至几天
- Anthropic 的工程博客指出:即使是最强的编码模型,如果没有外部系统来初始化项目、追踪进度、留下产物(日志、代码),也无法独立构建大型应用
- Harness 解法
- 维护状态和连续性
- 每次会话留下”面包屑“,下次接着干
- 确保 Agent 持续向前推进,而不是原地打转
1 | flowchart LR |
Agent Harness 工作原理
Harness 本质上是 用户、AI 模型、外部工具/环境之间的中间层,拦截并增强它们之间的通信
核心要点
- Harness 不修改模型权重,纯粹是模型外围的软件架构
- Harness 能把一个预训练模型的问题解决能力显著提升 - 靠的是正确的支撑结构,而非重新训练
- Harness 是 LLM 的”外骨骼” - LLM 提供智能,Harness 提供行动力、记忆和纪律
1 | flowchart TB |
五阶段运作
- 意图捕获与编排(Intent Capture & Orchestration)
- 用户提出高层目标 → 编排器(Orchestrator)拆分为子任务 → Harness 为每个子任务提供执行手段(上下文、工具)
- 编排器决定**”做什么”,Harness** 负责**”怎么做”**
- 工具调用执行(Tool Call Execution)
- 模型输出特殊标记(如 search(“xxx”) 或 python(code))→ Harness 拦截识别 → 暂停文本生成 → 在真实环境执行操作 → 把结果”喂回“模型上下文
- Harness 充当模型的 代理代理人,把意图变成行动,再把观察结果返回
- 上下文管理与记忆(Context Management & Memory)
- Harness 维护一个 持久任务日志,与模型的瞬时 prompt 分离
- 每次调用模型前,Harness 编译工作上下文:筛选相关历史 + 关键事实 + 近期结果,对过时信息做摘要或裁剪(context compaction)
- 结果验证与迭代(Result Verification & Iteration)
- 检查输出格式是否符合预期
- 对代码运行测试用例
- 发现问题时在下一轮提示模型修复
- 鼓励 增量推进:一个子任务完成 → 保存状态 → 再做下一个
- 典型循环:写代码 → 跑测试 → 修错误,全程无需人工干预
- 完成与交接(Completion & Handoff)
- 任务结束或会话超时后,Harness 保存所有产物(文件、摘要、进度日志)
- 下次启动新实例时加载这些文件,项目本身就拥有了记忆,即使 LLM 本身无状态
Agent Harness 核心组件
Harness 是一个 高度模块化的智能中间件框架,把工具调用、记忆管理、上下文工程、规划分解、验证护栏全部封装好,让 LLM 从”只会说“变成”能干活“
1 | flowchart TB |
工具集成层
Tool Integration Layer
- Harness 的心脏 - 连接模型与外部世界 - 支持 Web 搜索、数据库查询、计算器、代码执行环境、图像生成等
- Harness 定义了模型请求工具的 协议(特殊格式输出或函数调用语法),负责执行并把结果喂回
- 现代 Harness 通常自带默认工具包(文件读写、Web 搜索、代码解释器),开箱即用
- 例如 LangChain 的 DeepAgents 甚至内置虚拟文件系统
记忆与状态管理
Memory & State Management
突破单次上下文窗口的限制,分 三层记忆:
| 层级 | 生命周期 | 用途 |
|---|---|---|
| 工作上下文 | 单次调用的 prompt,瞬时 | 模型当前看到的 |
| 会话状态 | 单个任务期间,持久但任务结束重置 | 本次任务做了什么 |
| 长期记忆 | 跨任务/跨时间,永久 | 知识库或向量存储 |
老交互会被 蒸馏摘要,相关事实按需检索 - 类似人扫一眼笔记再继续工作
上下文工程与 Prompt 管理
Context Engineering - 核心能力是决定每次调用模型时 包含什么、排除什么
- 上下文隔离 - 不同子任务的上下文互不干扰
- 上下文裁剪 - 压缩/丢弃无关信息,防止 context rot
- 上下文检索 - 在正确时机注入新鲜信息(文档、搜索结果)
- 可集成 RAG 动态检索文档
- 首次运行与后续运行使用 不同的 prompt 策略(Anthropic 的实践)
规划与分解
Planning & Decomposition - 防止模型”一次性搞定所有事“然后失败,有两种模式
| 模式 | 描述 |
|---|---|
| 静态规划 | 预定义步骤序列(窄领域) |
| 动态规划 | 让模型先出计划,Harness 再逐步执行 |
- Anthropic 的做法:初始化 Agent(设置项目结构 + 任务清单)→ 编码 Agent(逐个实现功能)
- Harness 通过 prompt 设计和任务勾选来 强制增量推进。
验证与护栏
Verification & Guardrails
| 检查方式 | 描述 |
|---|---|
| 格式验证 | 输出能否被解析、是否满足要求的格式 |
| 逻辑检查 | 方案是否真的解决问题、测试是否通过 |
| 安全过滤 | 阻止违规操作或内容 |
| 编码 Agent | 跑单元测试,通过才继续 |
| 研究助手 | 验证引用的来源是否真的支撑论点 |
加更多 Agent(如单独的”QA Agent”)可能适得其反 - 更好的做法是让 Harness 引导主 Agent 自己做质量保证,只在必要时升级或重置
模块化与可扩展性
Modularity & Extensibility
- 现代 Harness 是 可插拔的模块化框架
- 每个模块可独立启用/禁用/替换,自带电池(batteries included) - 默认提供常见能力(视觉、代码执行、Web 访问等),开发者可按需精炼或替换
1 | Harness |
Agent Harness 真实案例
同一个模型,有没有 Harness,效果天壤之别 - 模型决定能力上限,Harness 决定实际发挥
Anthropic Claude Agent SDK
Anthropic 官方称 Claude Agent SDK 为 “通用 Agent Harness“,擅长编码和工具使用任务,核心能力如下
- 内置 上下文管理(自动压缩对话历史)
- 内置 工具调用 能力
- 初始化器 / 编码 Agent 模式:在超出上下文窗口的长项目中保持连贯性
- 典型功能:写代码并执行、搜索知识库、维护 claude-progress.txt 进度日志用于跨会话交接
- 关键报告:Effective harnesses for long-running agents,描述了如何让 Claude 在超长任务中持续工作
LangChain DeepAgents
LangChain 生态的三层架构
| 层架 | 描述 |
|---|---|
| LangChain(抽象层) | 提供 Agent、Tool、Memory 等基础抽象 |
| LangGraph(运行时) | 处理执行和持久化 |
| DeepAgents(Harness) | 自带默认 prompt、工具处理、规划、文件系统访问等 |
- DeepAgents 定位为 Claude Code 的通用版本 - 开箱即用的完整 Harness,开发者不需要从零组装
- DeepAgents 不是一个新模型,也不是简单的 SDK,而是 包裹模型的完整 Agent 系统
概览澄清
Framework 提供零件,Orchestrator 提供大脑,Harness 提供双手和基础设施,三者协作才构成完整的 AI Agent 系统
1 | flowchart TB |
| 概念 | 角色 | 类比 | 关注点 |
|---|---|---|---|
| Framework(框架) | 构建积木 | 乐高零件库 | 提供抽象(Tool、Memory、Chain) |
| Harness(线束) | 完整运行时 | 组装好的机器 | 能力 + 副作用(工具、上下文、环境) |
| Orchestrator(编排器) | 控制逻辑 | 大脑/指挥官 | 何时调模型、调几次、逻辑流 |
Framework → Harness 的关系
- Framework 是零件(LangChain、LlamaIndex) - 提供 Tool、Memory、Chain 等抽象
- Harness 是成品 - 用零件组装出的完整运行系统,自带主张性默认配置
- 实际关系:Harness 构建在 Framework 之上(DeepAgents Harness 用 LangChain 作为底层)
1 | Framework(零件) |
Orchestrator vs Harness
- Orchestrator = 大脑
- 决定 何时调模型、用什么 prompt、循环几次
- 实现推理循环(ReAct、Tree-of-Thought),解析思维链,决定下一步
- 关注 逻辑与控制流
- Harness = 手 + 基础设施
- 确保模型被调用时 有工具可用、有上下文、有环境
- 关注 能力与副作用
协作方式
1 | Orchestrator:"用这个 prompt 调一次模型" / "再循环一步" |
容易混淆的旧概念
现代AI语境下,除非明确说 “test” 或 “evaluation”,”harness” 默认指 Agent Harness - 我们讨论的这种运行时系统
| 旧概念 | 描述 |
|---|---|
| Test Harness(测试线束) | 软件工程老术语,自动提供输入并检查输出 |
| Evaluation Harness(评估线束) | 如 EleutherAI 的 LM Evaluation Harness,跑基准测试 |
Harness 核心收益
Harness 工程正在变得和模型工程一样重要 - 模型决定能力上限,Harness 决定实际发挥
- Harness 决定了 AI 产品的成败
- 两个产品用同一个 LLM,Harness 更好的那个用户体验会远超另一个
- 这就是为什么 Anthropic、OpenAI 等都在重金投入 Harness 工程,开源社区也在涌现各种 Harness 项目
更高的任务成功率
Higher Task Success Rates - Harness 补偿模型的弱点 - 缺乏持久性、无法使用外部知识、容易犯错 - Harness 让模型 做到原本做不到的事
| 场景 | 无 Harness | 有 Harness |
|---|---|---|
| 策略游戏 | 缺少记忆和感知 | 加入 Memory + Perception 模块,胜率提升 |
| 编程任务 | 遇到运行时错误就挂 | 跑代码 → 调试 → 修复,循环推 |
长任务的一致性
Consistency on Long Tasks
- 无 Harness - 上下文中断后 → 要么放弃,要么无脑重复之前的工作
- 有 Harness - 存储状态 + 强制增量推进 → 即使新开上下文,也能快速加载并恢复
更好的资源利用
Better Use of Resources
- 结构化工具调用和上下文 → 减少浪费的 token 和不必要的模型调用
- 把部分推理移到模型外部(知识图谱、数据库存事实)→ prompt token 可减少 10-100 倍 - 模型只拿到精准信息,而非大段文本
- 快速取消/纠正错误路径(通过验证)→ 避免模型在错误方向上浪费大量 token
无需重训即可扩展能力
Enhanced Capabilities - 这是巨大的灵活性优势,组织可以用同一个预训练模型,定制化满足不同需求
- 可能是最大的收益
- 想让 LLM 处理图像? → 加视觉模块 / 图像描述 API
- 想让 LLM 做数学/逻辑? → 加 Python 执行工具(如 OpenAI Code Interpreter)
- 过去:需要训练专用模型或微调
- 现在:一个通用模型 + Harness 适配器 = 完成各种任务
提升可靠性与安全性
Improved Reliability & Safety - Harness 层的护栏比把所有规则塞进模型 prompt 更好管理
- 过滤不安全操作或违规内容
- 强制流程:回答必须引用来源、不可逆操作前必须用户确认
- 可独立更新 - 新的最佳实践出现时,改 Harness 而非重新训练模型
Agent Harness 常见问题
Q1:Harness = Prompt Engineering 吗?
- 不等于,Prompt Engineering 是 Harness 的一部分
- Prompt Engineering 是 技巧(写好 prompt 让模型输出更好)
- Harness 是架构(prompt + 工具执行 + 结果处理 + 记忆管理 + 完整循环)
- Prompt Engineering 是 Harness 会用到的一种技术,Harness 是更大的系统
Q2:用 LLM 一定需要 Harness 吗? - 取决于任务复杂度
| 场景 | 是否需要 Harness |
|---|---|
| 一次性问答、文本生成 | 不需要,模型 + prompt 就够 |
| 使用外部数据、多步推理、长期记忆 | 必须,哪怕是最小化的 Harness |
Q3:Harness 工程和传统软件工程有啥区别? - Harness 工程是一门全新学科,最佳实践还在实时摸索中
- 共同点:模块化设计、状态管理、I/O 处理、测试……
- 核心区别:围绕一个不确定的 AI 核心在编程
- 模型可能说出/做出意料之外的事 → Harness 要 优雅地处理
- 传统软件没有的问题:token 限制、幻觉、prompt 设计
- 本质是 后端工程 + UX 设计(AI 交互)+ ML 知识 的融合
Q4:多个模型能共享同一个 Harness 吗? - Harness 保护工程投入 - 支持换模型不换架构
- 能,解耦 Harness 和模型是核心优势
- 换模型:从 GPT-4 换成更好的新模型,Harness 的记忆、工具、结构全部复用
- 多模型并行:简单任务用小模型,复杂步骤用大模型 → Harness 做路由(Model Routing)
- Harness 本质上是 模型无关的(只需调整 prompt 格式和工具调用语法)
Q5:Harness 只适用于文本 LLM 吗?
- 远不止,从 LLM 起步,但适用于 任何按序操作的 AI Agent
- 通用原则:强大的 AI 大脑需要身体和工具 - Harness 就是用软件构建这个身体的方式