Agentic Harness - Qoder
背景
不是让 Agent 更聪明,而是让错误不可发生
- 现象
- Agent 写代码违反隐式架构规则,lint 失败后陷入修复循环,上下文窗口被塞满,最终偏离目标
- 根因 - Agent “看不见”
- “教得更好“(更长 prompt、更多示例、规范文档)有天花板
- 规则随代码演进、文档在 AI 不可达的地方、不同模型”常识”不一致
- “教得更好“(更长 prompt、更多示例、规范文档)有天花板
- 解法转向
- Harness 工程的核心思路:从”教 Agent 怎么做“转向”让 Agent 自己验证做得对不对“
- 靠 linter、测试、架构约束等机械化检查保证正确性,而非依赖 LLM 的”直觉”
- 本质是把 CI/CD 的拦截时机从合并前提前到写代码时
仓库是 Agent 的操作系统
- 把散落的知识收进仓库
- 精简为可按需加载的索引
- 只编码架构边界而非实现细节
- 人的角色从执行者变为系统设计者
类比
Harness = LLM 的操作系统,不是增强它的算力,而是给它一个可以可靠运行的环境
| CPU | LLM |
|---|---|
| 计算能力极强 | 推理能力极强 |
| 不知道硬盘在哪、网络协议是什么 | 不知道分层规则、文件该放哪 |
| 需要 OS 来管理资源、提供抽象 | 需要 Harness 来提供约束和上下文 |
原则
仓库即唯一事实来源
- 问题的本质是知识不对称
- 人类团队的架构决策散落在 Aone、钉钉、架构师的脑子里
- Agent 只能看见仓库 - 不在仓库里的东西对它等于不存在
- 做法:把架构决策、层级约束、命名规范全部版本化提交到 Git
- 知识跟着代码走,无论新人还是 Agent,clone 下来就拿到完整上下文
指令文件是地图,不是手册
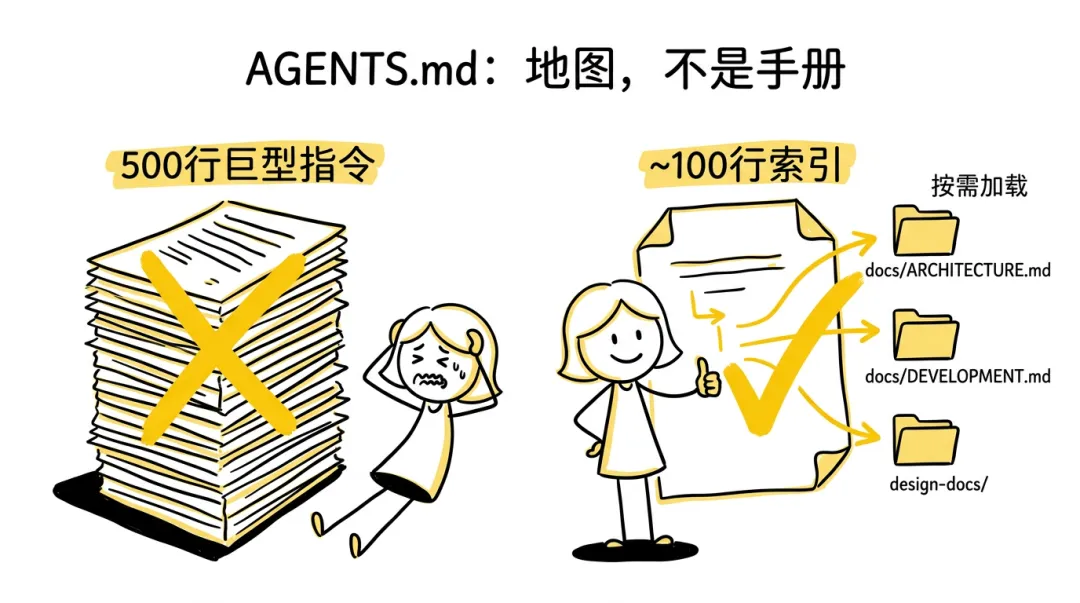
- 反直觉的点:信息越多效果越差
- 500 行的 AGENTS.md 看似全面,实际害了 Agent
- 挤占上下文窗口,留给实际任务的空间变少,而且大文件容易过时腐烂
- 正确做法是 ~100 行的索引 + 按需加载
- Agent 要改 auth 模块?先读索引找到路径,再加载对应文档,用不到的不加载
- 这和 OS 的懒加载(lazy loading)思路一样 - 只把需要的页调入内存
1 | AGENTS.md (索引,~100行) |
只管边界,不管内部
- 这是最关键的约束粒度设计
- Harness 不规定”用什么设计模式””函数怎么写” - 那是 Agent 的自主空间
- 只管依赖方向
- 规则极简
- 高层可以依赖低层,反过来不行
- 边界之内自由发挥,边界之外坚决拦截
- 这跟管理大型平台团队的逻辑一致 - 中心化管架构约束,本地自治管实现细节
1 | Layer 4+ HTTP handler / CLI → 可 import 任意低层 |
1 | graph TD |
人的角色转变
- 以前:人写代码,AI 辅助补全
- 现在:人设计系统(架构 + 约束 + 验证),Agent 在系统内执行
- 人的价值从”拧每一颗螺丝”变成”确保流水线是对的“
- 不需要比 Agent 更会写代码,需要比 Agent 更会设计让它不出错的环境
落地:从搭建到执行
- creator 按项目健康度分级搭建基础设施(文档 + 脚本 + 状态管理)
- executor 在这套环境中执行任务
- 写代码前有人类审批计划,写完后有脚本自动验证,执行过程有状态记录可回溯
- 整个体系把”靠 Agent 聪明“变成了”靠系统可靠“
1 | flowchart LR |
两个引擎,一个闭环
executor 启动时检查 AGENTS.md,没有就自动调 creator 来搭,搭完再继续 - 任何项目都能直接用 executor 起步
1 | ┌─────────────────┐ ┌─────────────────┐ |
1 | graph LR |
- creator - 基础设施工程师 - 审计项目、生成文档和 lint 脚本
- executor - 一线开发者 - 在 creator 搭好的环境里干活
creator 的分级策略
不是一刀切,而是根据项目现状分级处理
| 评分 | 状态 | 策略 |
|---|---|---|
| 0-20 | 裸奔,什么都没有 | 从零搭建全套 |
| 21-70 | 有基础但有缺口 | 针对性补充 |
| 71+ | 健康 | 微调 |
executor 的工作流
1 | 检测环境 → 加载上下文 → 制定计划 → 人类批准 → 执行 → 验证 → 完成 |
1 | flowchart TD |
“人类批准”不是走过场 - executor 会生成一个执行计划文件 - 与 Claude Code 的 Plan Mode 非常类似,推理模型就是 Plan-Execute
- 任务目标
- 影响范围
- 分阶段步骤
- 验证方式
- 回退策略
这解决了一个真实痛点:Agent 常常”悄悄干了一件错事”
- 有了执行计划,人能在 Agent 动手前就看到它打算怎么干,觉得不对直接改方向
- 这比事后 code review 的拦截时机早得多
项目结构解读
整个结构分成三层,各有分工:
第一层:知识层(docs/)
1 | docs/ |
第二层:执法层(scripts/)
1 | scripts/ |
第三层:状态层(harness/)
1 | harness/ |
在动手之前先问”能不能做”
- Harness 最核心的落地机制 - 验证体系
- 回答三个问题:怎么查、怎么防、查挂了怎么办
- 事前用 verify_action 预防(代价低),事后用四步管道验证(build → lint → test → verify)
- 报错信息自带修复指引让 Agent 自愈,同一错误超 3 轮就停
- 验证体系的核心不是”查得严“,而是”让错误尽可能早地、代价尽可能小地暴露“
两类检查
规则本身都是”常识“,但常识不提醒就不会被遵守,Agent 尤其如此
| 检查类型 | 管什么 | 例子 |
|---|---|---|
| lint-deps(依赖方向) | 架构边界 | core/ 不能 import ui/,api/ 和 cli/ 不能互引 |
| lint-quality(质量规范) | 编码纪律 | 单文件 ≤500 行,禁止 console.log,禁止硬编码品牌字符串 |
核心洞察:事前预防 >> 事后检查
类比:写代码前跑 verify_action,就像 SQL 执行前先 EXPLAIN - 代价极低,能避免灾难性后果
- 传统流程
- Agent 写 50 行代码 → 跑 lint → 发现层级违反 → 撤销、重设计 → 消耗 ~10 次 tool call
- Harness 流程
- Agent 写代码前先问一句”合法吗” → 两次交互搞定
1 | # 问一句就能避免后面 10 次来回 |
触发条件
- 不是每个操作都预验证(改函数体、加测试不需要)
- 只在创建新文件或添加跨包 import 时才验证 - 因为层级违反是 Agent 翻车的头号原因
报错信息就是教学
一条差的报错
1 | Forbidden import in core/types/user.go |
一条好的报错
1 | core/types/user.go imports core/config (Layer 0 → Layer 2). |
- 什么规则违反了 → 为什么是问题 → 怎么修,全在里面
- 好的报错让 Agent 能自愈,不需要人介入
- 这是设计 linter 时的一个关键细节 - 不只是拦截,还要教会 Agent 怎么修
四步验证管道
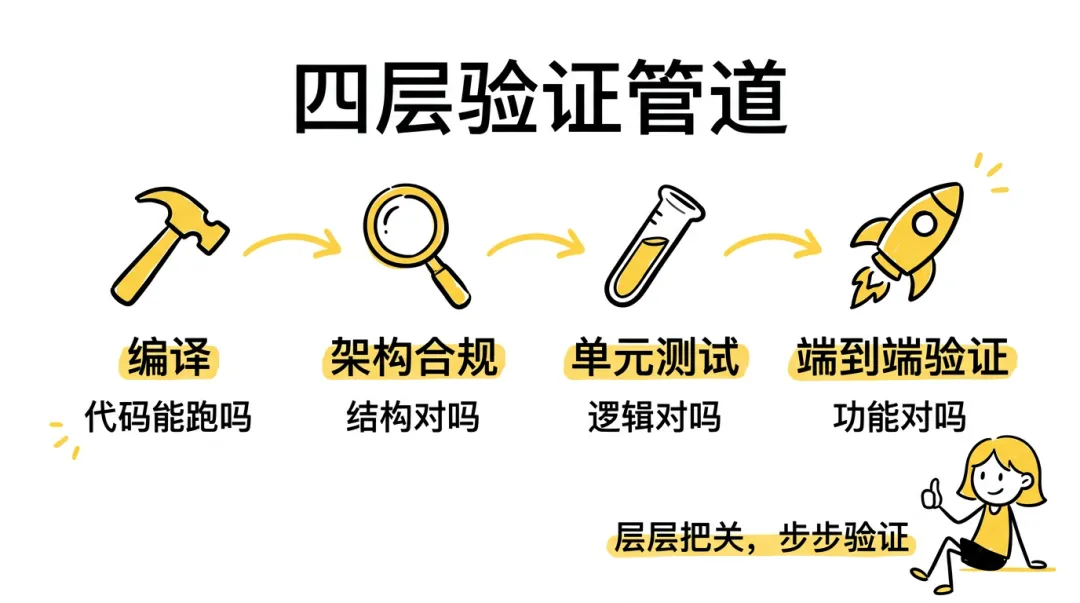
1 | build → lint-arch → test → verify |
1 | flowchart TD |
- 前三个(build / lint / test)是常规操作,重点在第四步 verify
- 测试通过了 ≠ 功能是对的
- 测试可能覆盖不全,Agent 写的测试可能恰好绕过了关键路径
- verify 是项目级端到端验证
- 不是”函数返回值对不对”,而是”用户执行这个操作,最终结果对不对“
- 比如一个 CLI 工具,verify 会实际跑命令检查输出;一个 Web API,会发真实请求验证响应
- Harness 不鼓励直接跑 go build 或 go test,而是提供 validate.py 统一入口,因为**”验证通过”在每个项目里定义不同,需要标准化**
verify skill 的思路
很多项目一开始没有端到端验证能力,Harness 引导你创建 verify skill - 这让验证闭环从”代码能跑“提升到”功能正确“
- 识别核心用户路径(如”创建用户 → 登录 → 查看资料”)
- 每条路径编码成可执行验证脚本
- creator 自动生成骨架放 scripts/verify/,你填断言逻辑
修复循环的边界
- 验证失败 → Agent 自动分析错误 → 改代码 → 重跑验证,一般 1-3 轮收敛
- 但有个硬限制:同一个错误转 3 圈还没过,就停下来交给人
- 不是 Agent 一定修不好,而是继续转下去上下文窗口要爆 - 知道什么时候放手比硬撑更聪明
三条实操经验
- 故意引入违规测试 lint - 加一个跨层 import,如果 lint 没报错,说明护栏是纸糊的
- 永远不要禁用 lint 规则来”解决”问题 - Agent 有时会想绕过规则(比如注释掉 lint 配置),应该改代码不是改规则
- 测试不需要每次跑全量 - 只跑受影响的包,速度快很多
上下文是最贵的资源
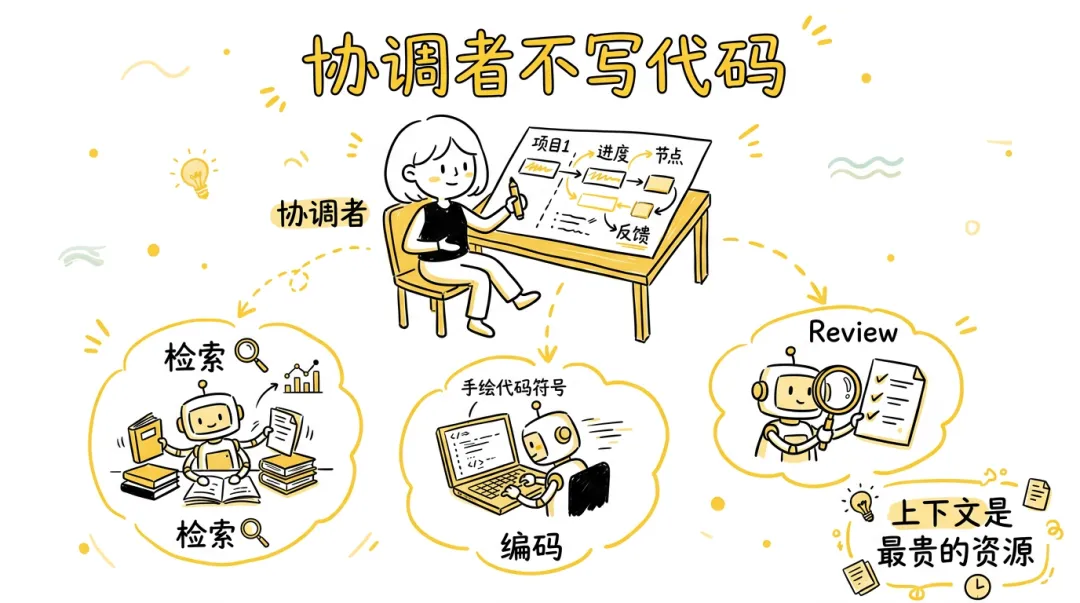
协调者绝不写代码 - Harness 的任务执行架构 - 怎么组织 Agent 干活才能在有限上下文下完成复杂任务
- 协调者不写代码,只做调度 - 每个子代理拿干净上下文、精确 prompt、合适的模型去干活,干完释放只留摘要
- 复杂任务加 worktree 隔离和交叉 review
- 分阶段存检查点保证可恢复
- 本质是用”多个短生命周期的小任务“替代”一个无限膨胀的大任务“,从根本上规避上下文耗竭
为什么协调者不能写代码
这是一个关于上下文耗竭的正反馈陷阱
1 | 任务复杂 → 消耗更多上下文 → 关键信息被压缩 → 决策质量下降 |
1 | flowchart TD |
- 到第 40 次 tool call,早期架构决策已被压缩;到第 60 次,可能忘了最初的目标
- 你让它加用户认证,它在纠结一个不相关的 import 路径
- 类比:这跟人类一样 - 你同时打开 50 个浏览器标签页,写着写着就忘了最初要查什么
- 区别是人类会意识到自己乱了,Agent 不会,它会继续”自信地犯错“
解法:两层架构
1 | ┌─────────────────────────────────────────┐ |
1 | flowchart TD |
- 关键设计:子代理每次从干净的上下文开始
- 它不知道之前发生了什么,但它的 prompt 里包含了它需要知道的一切
- 干完后详细上下文被丢掉,协调者只保留摘要
- 这跟操作系统进程模型一模一样 - 父进程不自己干活,fork 出子进程,子进程有独立的地址空间,干完把结果通过管道返回给父进程
- 协调者就是 init,子代理就是 worker process
“就改一行”的陷阱
最常见的违规方式:协调者发现一个小问题,心想”这么简单不用启子代理” → 一行改五处 → 五处变二十处 → 上下文耗尽,判断规则如下
| 复杂度 | 判断标准 | 执行方式 |
|---|---|---|
| 简单 | 一句话能描述,不含”和”字 | 直接做 |
| 中等 | 需要清单跟踪改了哪些地方 | 委派子代理 |
| 复杂 | 涉及设计决策和权衡 | 委派 + worktree 隔离 |
发现协调者在用 Edit/Write 工具修改源代码 → 立刻停,启动子代理,没有例外
模型选择:不是所有任务都需要最强模型
这是一个常被忽略的成本杠杆:
1 | 重命名变量 → Haiku(快、便宜) |
一个中等复杂度的功能,可能同时调度三四个不同模型:总成本降 60-70%,质量不打折扣,协调者本身用中等模型就行 - 它不写代码,只做调度
1 | 协调者(中等模型,只调度) |
交叉 Review:用”不同模型”做第二双眼睛
机械验证(lint / test / verify)能抓规则层面的问题,但抓不到逻辑合理性:
- 竞态条件
- 边界遗漏
- 不必要的复杂度
- 命名让人看不懂
为什么强调不同模型?
- 同一个模型既写又 review,容易对自己的产出”视而不见“
- 换一个架构和训练数据都不同的模型,思维盲区的重叠就小得多
嵌入时机
- 编码子代理完成 → 机械验证通过 → 协调者接受结果之前
其他维度
| Key | Value |
|---|---|
| 成本 | review ≈ **编码成本的 10-20%**(只需读 diff + 文档) |
| 触发条件 | 核心业务逻辑 / 安全代码 / 大范围重构 |
| 简单修改 | 直接过机械验证就够 |
隐性价值
- review 中反复出现的问题 → 记录到 harness/trace/ → 转化为新的 lint 规则
- 把**”软知识”逐渐硬化成“硬规则”** - 这是 Harness 自我进化的机制
检查点:断点续传
- 复杂任务分阶段,每阶段完成后存档(包括架构决策)
- 检查点携带架构决策这一点很关键 - 没有它,新 Agent 可能做完全不同的设计选择,引入微妙的不一致
- 任务中断了,下一个 Agent 能从检查点恢复,不会走一条矛盾的路
让 Harness 自己长大
Harness 从静态规则体系升级为自我进化的闭环系统 - 从”人定规则,Agent 遵守“到”Agent 的失败自动变成新规则“
驱动力:每次犯错都是信号
同一类错误反复出现,说明 Harness 本身有缺口
1 | 错误反复出现 |
靠人发现这些缺口太慢,让系统自己分析 - 这就引入了 Critic-Refiner 循环
自进化闭环
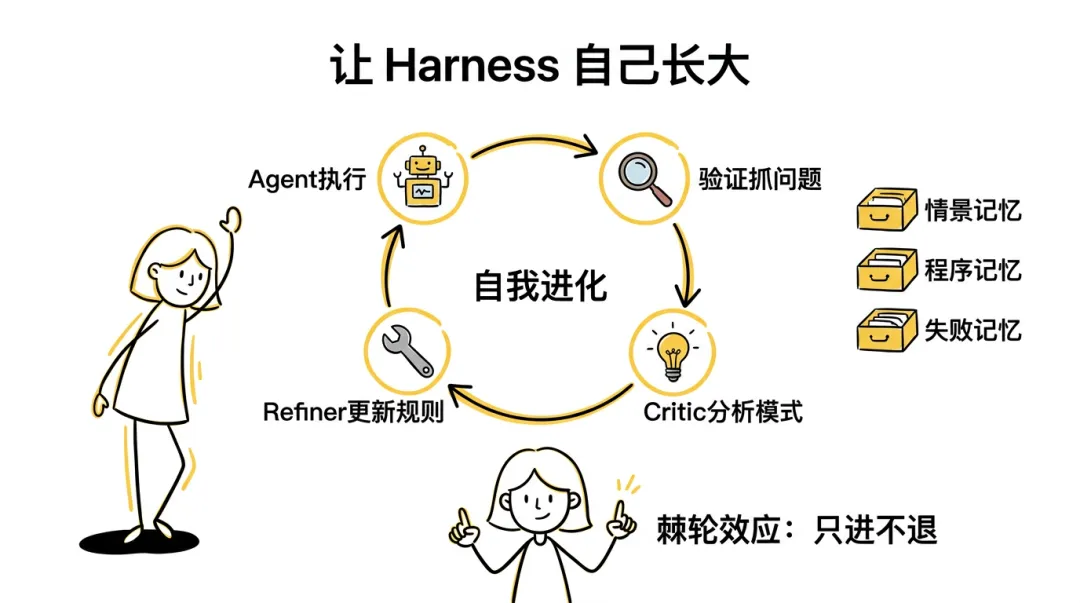
每次失败都不是浪费,而是给系统打了一针疫苗
1 | Agent 执行 → 验证抓到问题 → 保存到 harness/trace/failures/ |
1 | flowchart TD |
三种记忆
关键特性:记忆的价值随项目演进不断累积,项目越老,Harness 越聪明,而不是越腐化
| 类型 | 记什么 | 例子 | 怎么用 |
|---|---|---|---|
| 情景记忆 | 具体事件和教训 | “macOS 下 /var 是 /private/var 的符号链接,路径比较会失败” | 加载 10 秒,省掉一整个重试循环 |
| 程序记忆 | 成功操作步骤 | “添加 API 端点的标准五步流程,成功率 90%” | 新子代理执行同类任务前先查 |
| 失败记忆 | 供 Critic 分析 | 结构化的失败记录 | 挖模式、找根因 |
终极形态:轨迹编译
- 这是整个闭环走到极致的产物,同一个任务被成功执行 3 次以上,步骤高度一致:
- “添加 API 端点” 每次都是:
- 创建类型文件
- 写服务方法
- 加 handler
- 注册路由
- 写测试
- 既然每次都一样,为什么还需要 LLM?编译成确定性脚本 -
make add-endpoint NAME=foo - 直接跑脚本,LLM 都省,脚本失败了再回退到 Agent 模式
1 | flowchart LR |
棘轮效应
这是整个自进化机制的核心隐喻 - 棘轮(ratchet):只能往前转,不能倒退的齿轮
1 | 每次成功模式被编译成脚本 → 永久基础设施 |
1 | flowchart TD |
- 类比编译器的优化:热点代码被 JIT 编译成机器码,解释器再也不用逐行翻译
- Harness 做的是同样的事 - 热点任务被”编译”成确定性脚本,LLM 再也不用逐 token 推理
实践起步
Harness 是渐进式的
| 阶段 | 做什么 | 收益 |
|---|---|---|
| 今天 | 创建 AGENTS.md | Agent 立刻知道项目的基本规则 |
| 这周 | 加 lint-deps 脚本 | 层级违反被自动拦截 |
| 这个月 | 搭完整验证管道 | build → lint → test → verify 全闭环 |
| 之后 | 开启 Critic-Refiner 循环 | Harness 自我进化 |
一个 AGENTS.md 就能让体验好一截,不需要一口气搭全套,适用范围也很明确
- 多人协作、有明确分层的中大型项目 → 收益最大
- 个人项目或原型阶段 → AGENTS.md + 简单 lint 就够
新项目 vs 老项目
- 新项目:creator 问几个基本问题,直接生成全套基础设施
- 老项目:creator 扫描代码库、分析 import 关系、推断层级映射,生成反映现状的文档 - 不是从零设计,而是从现有代码中提取规则
- 持续演进:定期跑 Improve 模式做体检 - 哪些包没被 lint 覆盖、哪些文档没跟上代码变化,然后 executor 来修
AGENTS.md
- 受众
- README.md → 给人看的
- AGENTS.md → 给 Agent 看的
- AGENTS.md 是业界标准
- Agent 打开项目时会自动查找并读取这个文件名,作为了解项目的起点
- 一个最小 AGENTS.md 包含四块
- 快速链接 - 指向详细文档(地图,不是手册)
- 构建命令 - 怎么 build / test / lint
- 分层规则 - 哪些包在哪层,依赖方向是什么
- 质量标准 - 简洁的编码纪律
Harness 收益
传统灾难场景 - 写 200 行 → lint 失败 → 循环修复 → 上下文爆掉
Agent 启动
- 读 AGENTS.md 找到相关文档
- 列出执行计划,人扫一眼批准
- 子代理写代码,结构性操作前先跑 verify_action 预验证
- 层级违反在写代码前被拦住(不是写完才发现)
- 另一个模型的子代理做交叉 review
- 每个阶段存检查点、跑验证
- 经验教训记下来,下一个 Agent 接着用
对比
| 没有 Harness | 有 Harness | |
|---|---|---|
| Agent 知道规则吗 | 不知道,凭直觉 | 读 AGENTS.md 就知道 |
| 层级违反什么时候发现 | 写完 200 行后 | 写之前(verify_action) |
| 上下文管理 | 单 Agent 硬扛到爆 | 协调者 + 子代理,干净上下文 |
| 同样的错误会犯几次 | 每次新会话都可能犯 | Critic-Refiner 自动补规则 |
| 人的角色 | 全程盯着 review | 审批计划 + 间歇性介入 |
环境设计的投入回报远高于 prompt 调优
- 一套好的 Harness 能让普通模型产出可靠的代码,没有 Harness 的顶级模型照样在同样的坑里反复栽
- 与其追求更聪明的 Agent,不如设计更可靠的环境
复利效应
- 搭建成本:一个下午(基本 AGENTS.md + lint 脚本)
- 但价值随时间复利式增长
- 记忆越来越丰富(三种记忆持续累积)
- lint 规则越来越完善(Critic-Refiner 循环)
- 越来越多的操作被编译成确定性脚本(棘轮效应)
- 半年后:仓库变成了高度适配团队工作方式的 Agent 运行环境
- 任何新人(或新会话的 Agent)都能立刻进入状态