RAG - Frameworks
Overview Retrieval-Augmented Generation (RAG) is an AI framework that enhances the capabilities of large language models (LLMs) by incorporating external knowledge sources. It helps overcome limitations such as knowledge cutoff dates and reduces the risk of hallucinations in LLM outputs. RAG works by retrieving relevant information from a knowledge base and using it to augment the LLM’s input, allowing the model to generate more accurate, up-to-date, and contextually relevant responses. Haystack Hays...
RAG - Data Processing
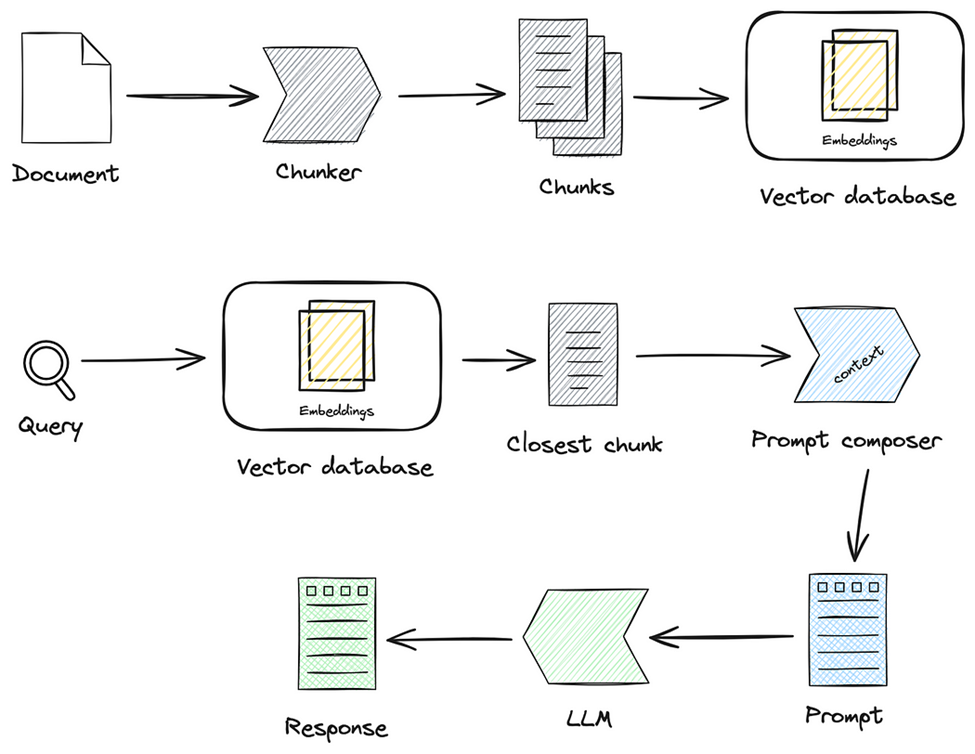
数据存储 LLM 变成生产力,有两个制约因素 - 交互过程中的长文本 + 内容的实时更新 在传统的应用开发中,数据存储在数据库中,保留了应用的全部记忆 在 AI 时代,向量数据库充当了这一角色 在 RAG 系统中,数据被转换为高维向量形式,使得语言模型能够进行高效的语义相似度计算和检索 在向量数据库中,查找变成了计算每条记录的向量近似度,然后按照分值倒序返回结果 RAG 就如何存储向量的方法论,根据不同的实现策略,衍生出了不同的 RAG 技术 利用图结构表示和检索知识的 GraphRAG 结合知识图谱增强生成能力的 KG-RAG - Knowledge Graph Augmented Generation AI 应用的数据建模强调的是数据的语义表示和关联,以支持更灵活的查询和推理 高质量的数据处理,不仅影响检索的准确性,还直接决定了 LLM 生成内容的质量和可靠性 Embedding 将所有内容转成文本 + 额外数据(用来关联数据) 选择一个 Embedding 模型,把文本转成向量,并存储到向量数据库中 厂商 LLM Embedding 国产 百度 文心一言 Embeddi...
RAG - Methodology
场景识别 分析业务流程,找出业务中依赖大量知识和信息处理的环节 复杂决策环节 在需要多维度信息综合分析与判断的业务流程中,RAG 可以为决策者提供实时的信息支持 使用 LLM 从各种来源的信息提炼出关键点,加权求和 - 压缩和整理非格式化信息 重复性内容生成 企业中有大量重复且标准化的内容生成任务 可以用程序去归纳流程,用 LLM 和 RAG 去填充每个环节 用户交互场景 增加自然语言交互 识别问题,找出流程痛点,并识别 LLM 和 RAG 能发挥的作用 信息碎片化 + 难以系统化输出 使用 LLM 和 RAG 能够通过自动化整合固定信息源,定期获取信息 统一整理(或生成)到统一的知识库,将分散的知识转化为结构化输出 人工处理效率低下 通过 LLM 自动化任务,可以更专注于更有创造力的工作 小步快跑 + 快速迭代 - LLM 技术变化极快 MVP Minimum viable product 数据驱动的迭代优化 持续收集用户行为数据和反馈,通过 A/B 测试等方法,不断优化系统表现
RAG - Document Parsing
文档解析 文档解析的本质 - 将格式各异、版本多样、元素多种的文档数据,转化为阅读顺序正确的字符串信息 Quality in, Quality out 是 LLM 的典型特征 高质量的文档解析能够从各种复杂格式的非结构化数据中提取出高精度信息 对 RAG 系统的最终效果起到决定性作用 RAG 系统的应用场景主要集中在专业领域和企业场景 除了数据库,更多的数据以 PDF、Word 等多种格式存储 PDF 文件有统一的排版和多样化的结构形式,是最为常见的文档数据格式和交换格式 Quality in, Quality out LangChainDocument Loaders LangChain 提供了一套功能强大的文档加载器(Document Loaders) LangChain 定义了 BaseLoader 类和 Document 类 BaseLoader - 定义如何从不同数据源加载文档 Document - 统一描述不同文档类型的元数据 开发者可以基于 BaseLoader 为特定数据源创建自定义加载器,将其内容加载为 Document 对象 Document Loader 模...
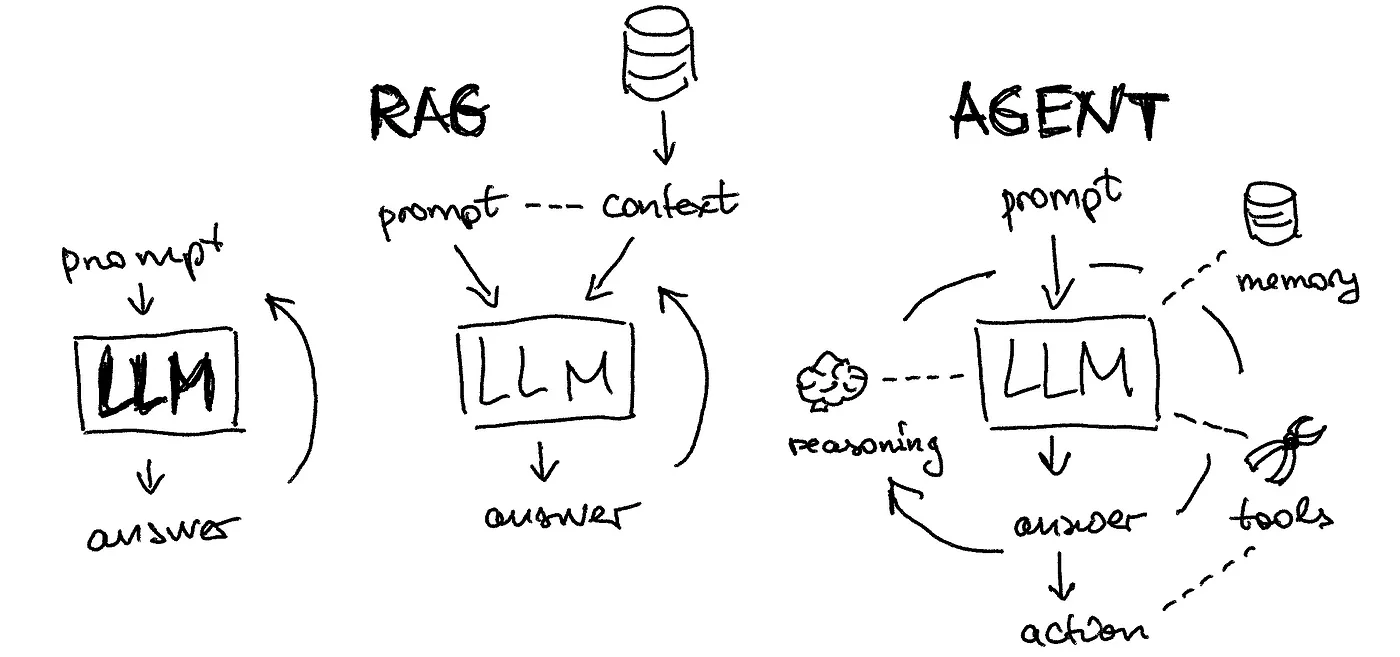
RAG - LangChain
Practice LangChain RAG https://github.com/langchain-ai/rag-from-scratch RAG 如何随着长期 LLM 而改变 Is RAG Really Dead? https://www.youtube.com/watch?v=SsHUNfhF32s 自适应 RAG 根据复杂程度动态地将查询路由到不同的 RAG 方法 - Command-R @ LangGraph Adaptive RAG https://www.youtube.com/watch?v=04ighIjMcAI Code https://github.com/langchain-ai/langgraph/blob/main/examples/rag/langgraph_adaptive_rag_cohere.ipynb Paper https://arxiv.org/abs/2403.14403 Adaptive RAG 在循环单元测试中自我纠正检索错误,以确定文档相关性并返回到网络搜索 在 LangGraph 中实现 Mistral 7B + Ol...
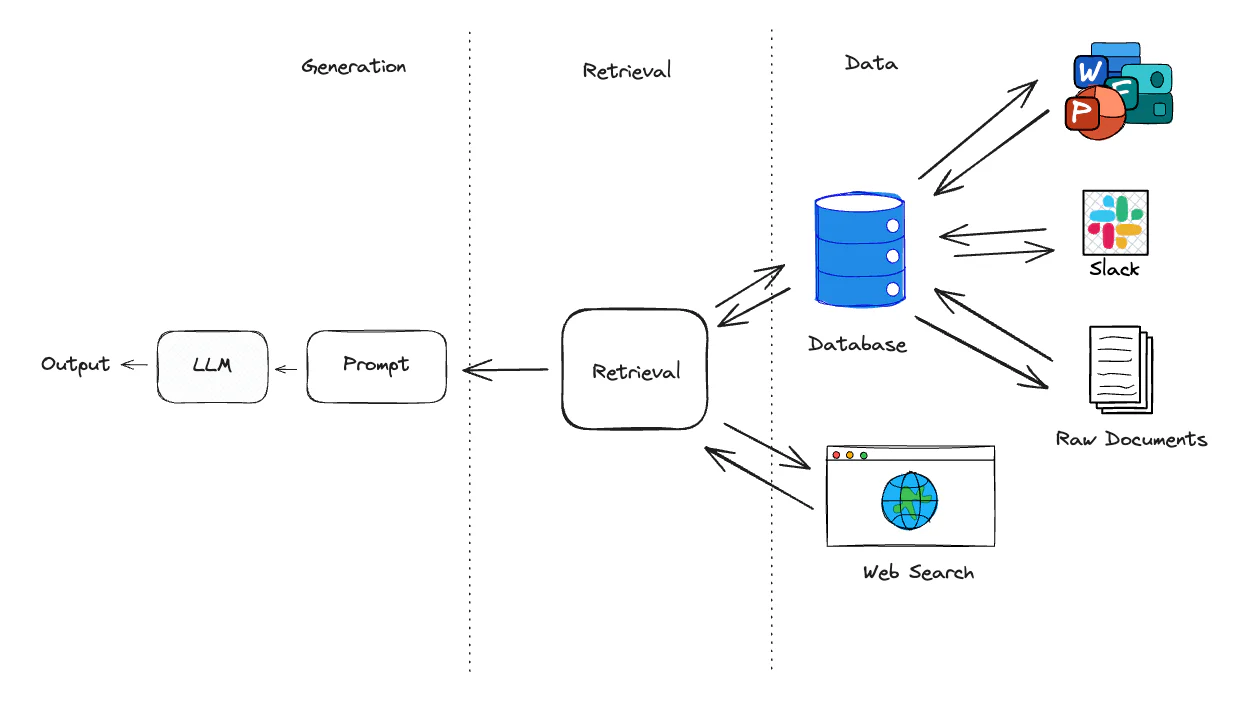
RAG - In Action
技术选型LangChain LangChain 是专门为开发基于 LLM 应用而设计的全面框架 LangChain 的核心目标是简化开发者的构建流程,使其能够高效地创建 LLM 驱动的应用 索引文档解析 pypdf 专门用于处理 PDF 文档 pypdf 支持 PDF 文档的创建、读取、编辑和转换,能够有效地提取和处理文本、图像及页面内容 文档分块 RecursiveCharacterTextSplitter 是 LangChain 默认的文本分割器 RecursiveCharacterTextSplitter 通过层次化的分隔符(从双换行符到单字符)拆分文本 旨在保持文本的结构和连贯性,优先考虑自然边界(如段落和句子) 索引 + 检索向量化模型 bge-small-zh-v1.5 是由北京智源人工智能研究院(BAAI)开发的开源向量模型 bge-small-zh-v1.5 的模型体积较小,但仍能提供高精度和高效的中文向量检索 bge-small-zh-v1.5 的向量维度为 512,最大输入长度同样为 512 向量库 Faiss - Facebook AI Similarity Sea...
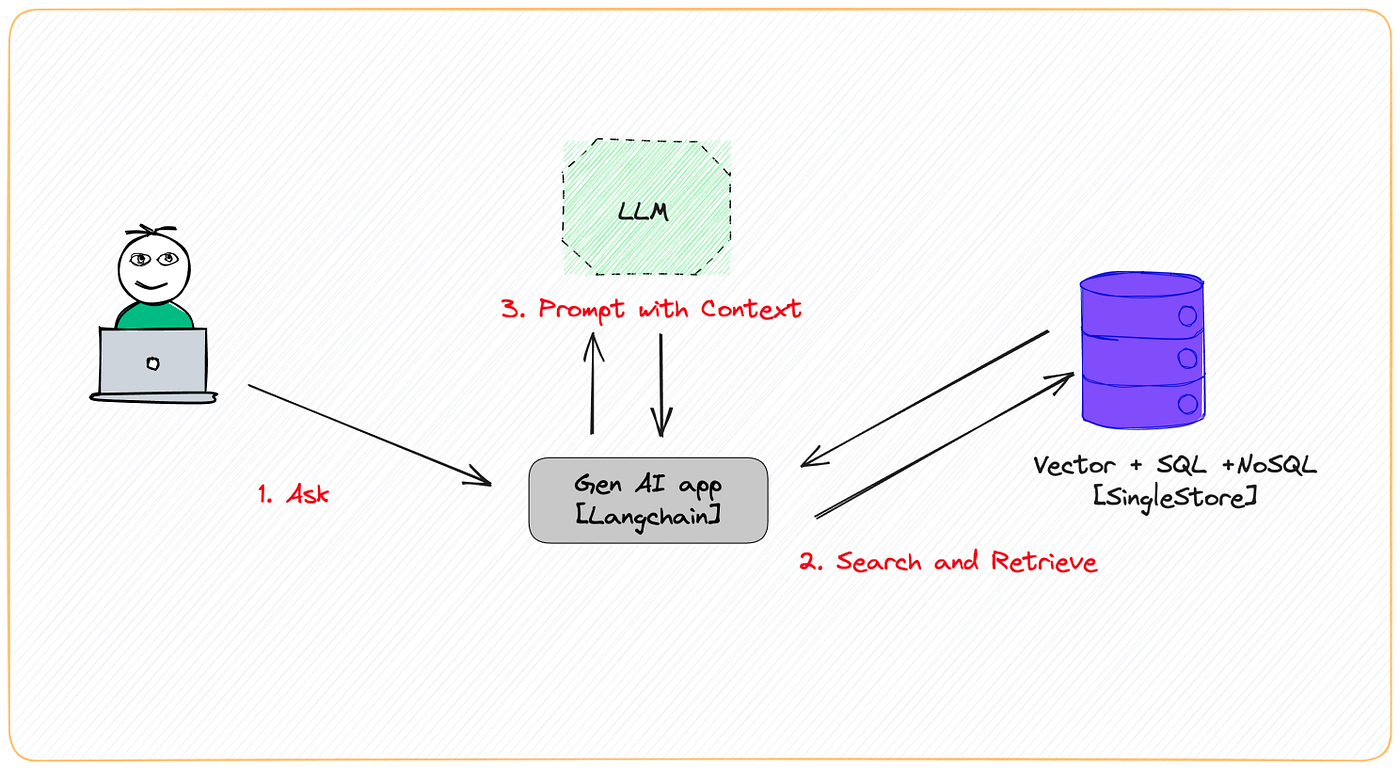
RAG -Principle
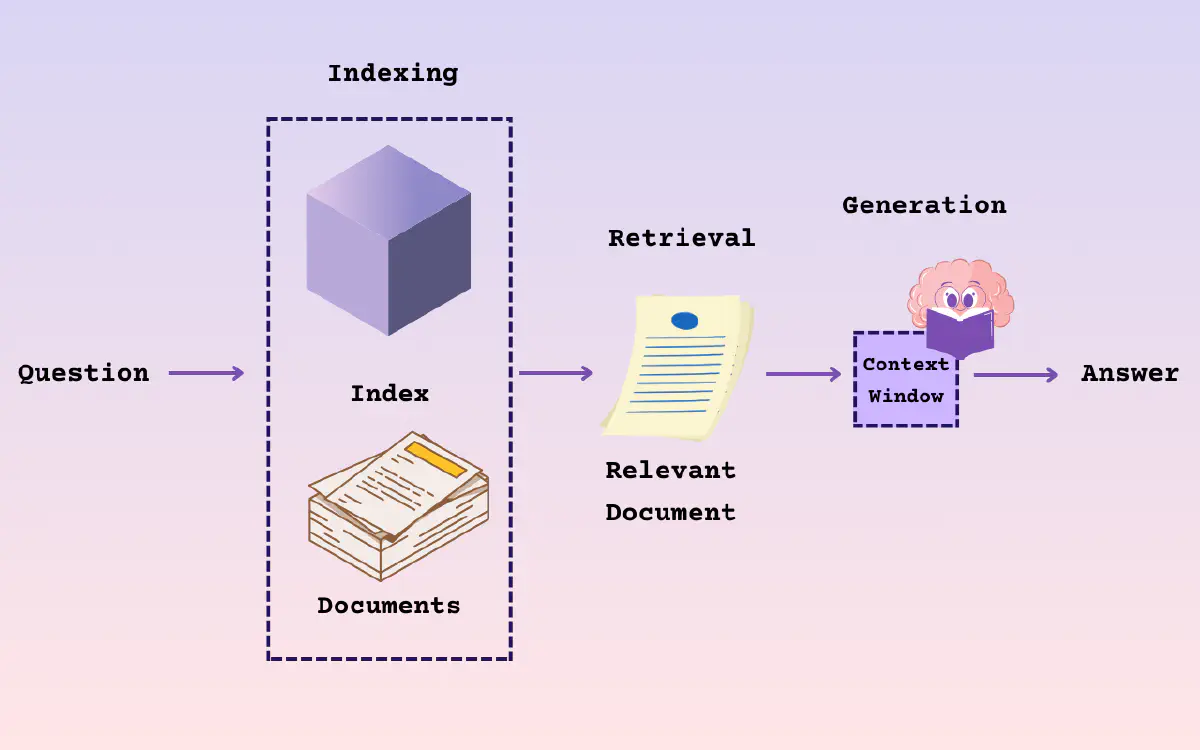
LLM 局限 当设计一个 LLM 问答应用,模型需要处理用户的领域问题时,LLM 通常表现出色 但有时提供的答案并不准确,甚至出现错误 当用户需要获取实时信息时,LLM 无法及时提供最新的答案 LLM 在知识、理解和推理方面展现了卓越的能力,在复杂交互场景中表现尤为突出 LLM 存在无法忽略的局限性 LLM 局限 Limitation Desc 领域知识缺乏 LLM 的知识来源于训练数据,主要为公开数据集,无法覆盖特定领域或高度专业化的内部知识 信息过时 LLM 难以处理实时信息,训练过程耗时且成本高昂,模型一旦训练完成,就难以处理和获取信息 幻觉 模型基于概率生成文本,有时会输出看似合理但实际错误的答案 数据安全 需要在确保数据安全的前提下,使 LLM 有效利用私有数据进行推理和生成 RAG 应运而生 将非参数化的外部知识库和文档与 LLM 结合 RAG 使 LLM 在生成内容之前,能够先检索相关信息 弥补 LLM 在知识专业性和时效性的不足 在确保数据安全的同时,充分利用领域知识和私有数据 选择 RAG 而不是直接将所有知识库数据交给 LLM ...
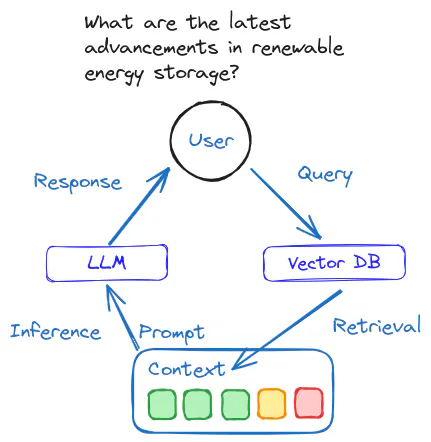
RAG - AI 2.0
AI 技术 做 AI 产品的工程研发需充分掌握 AI 技术 AI 产品从 MVP 到 PMF 的演进过程中会面临非常多的挑战 MVP - Minimum Viable Product - 最小可用产品 PMF - Product-Market Fit - 产品市场契合 要实现 AI 产品的 PMF 首先需要充分了解 AI 技术,明确技术边界,找到合适 AI 技术的应用场景 其次,需要深刻理解业务,用户需求决定产品方向,AI 技术是为业务服务的工具 在验证阶段,优先使用最佳 AI 模型以确保产品满足市场需求,确认后再逐步降低模型成本 坚持业务优先、价值至上的原则,避免纯 AI 科研化,脱离实际场景做 AI 技术选型 RAG LLM 局限 - 幻觉 + 知识实效性 + 领域知识不足 + 数据安全问题 由 OpenAI ChatGPT 引领的 AI 2.0 LLM 时代,见证了 LLM 在知识、逻辑、推理能力上的突破 Scaling Law、压缩产生智能、边际成本为零为理想中的 AGI 尽管 LLM 功能强大,但仍存在幻觉、知识实效性、领域知识不足以及数据安全问题的局限性 - RAG 文档问...

LLM Core - Model Structure
模型文件 模型文件,也叫模型权重,里面大部分空间存放的是模型参数 - 即权重(Weights)和偏置(Biases) 还有其它信息,如优化器状态和元数据等 文件格式 使用 PyTorch,后缀为 .pth 使用 TensorFlow 或者 Hugging Face Transformers,后缀为 .bin 在模型预训练后,可以保存模型,在生产环境,不建议保存模型架构 与 Python 版本和模型定义的代码紧密相关,可能存在兼容性问题 模型权重 - 推荐 1torch.save(model.state_dict(), 'model_weights.pth') 模型权重 + 模型架构 - 可能存在兼容性问题 1torch.save(model, model_path) 权重 + 偏置 权重 - 最重要的参数之一 在前向传播过程中,输入会与权重相乘,这是神经网络学习特征和模式的基本方式 权重决定了输入如何影响输出 偏置 - 调整输出 允许模型输出在没有输入或者所有输入都为 0 的时候,调整到某个基线值 $y=kx+b$ $k$ 为权重,$b$ ...
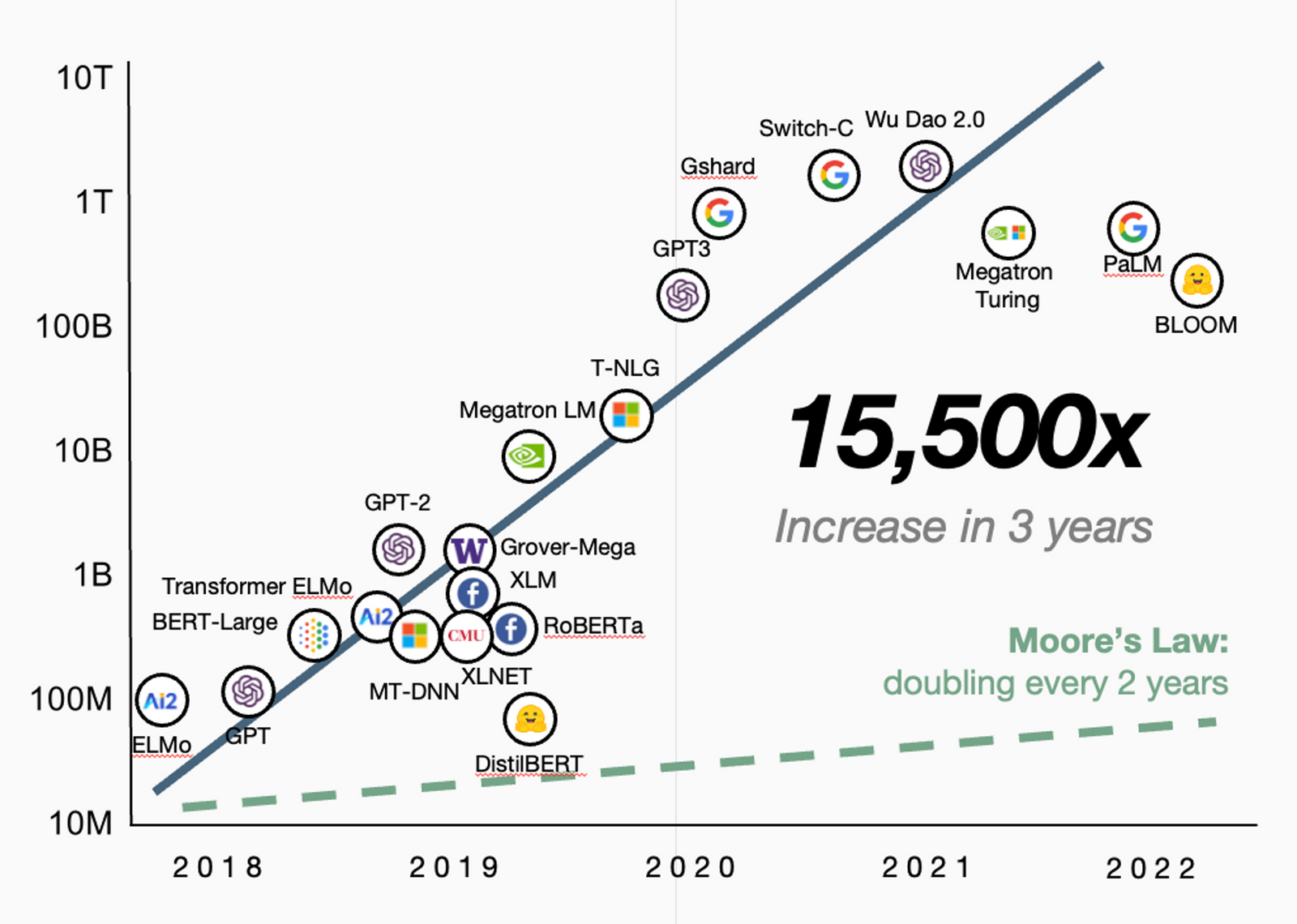
LLM Core - Decoder Only
模型架构 已经演化出很多 Transformer 变体,用来适应不同的任务和性能需求 架构名称 特点 主要应用 与原始 Transformer 的关系 原始 Transformer 编码器-解码器结构 机器翻译、文本摘要 基础模型 Decoder-only 只包含解码器 文本生成 去除了编码器部分 Encoder-only 只包含编码器 文本分类、信息提取 去除了解码器部分 Transformer-XL 加入循环机制 长文本处理 扩展了处理长序列的能力 Sparse Transformer 引入稀疏注意力机制 长序列处理 优化了注意力计算效率 Universal Transformer 递归的编码器结构 各种序列处理 引入递归机制,多次使用相同的参数 Conformer 结合 CNN 和 Transformer 优势 音频处理、语音识别 引入卷积层处理局部特征 Vision Transformer 应用于视觉领域 图像分类、视觉任务 将图像块处理为序列的 Transformer 编码器 Switch Transformer 使用稀疏性路由机制 大规模模型训练...