APISIX - Doc
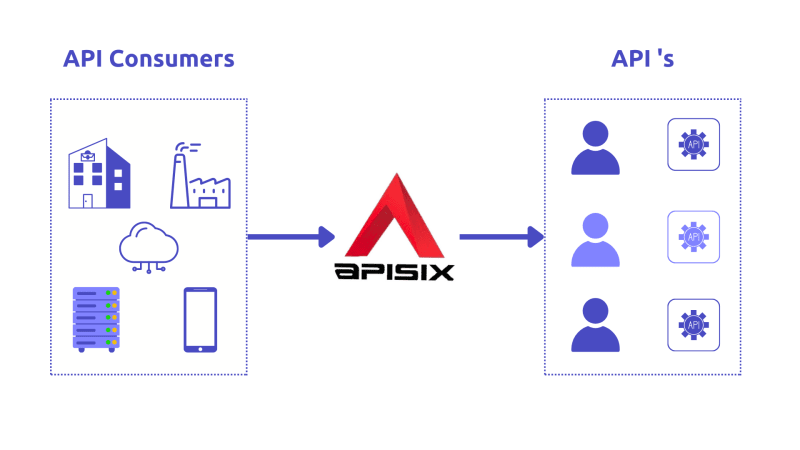
Feature Apache APISIX 基于 Radixtree Route 和 etcd 提供路由极速匹配与配置快速同步的能力 Apache APISIX 提供了自定义插件的能力 可以在 Balancer 阶段使用自定义负载均衡算法,并使用自定义路由算法对路由进行精细化控制 Apache APISIX 提供了配置热更新、插件热加载能力,在不重新启动实例的情况下可快速更新配置 Quick Start路由 Apache APISIX 使用 routes 来提供灵活的网关管理功能,在一个请求中,routes 包含了访问路径和上游目标等信息 Route Route 是访问上游目标的路径 过程 通过预定的规则来匹配客户端请求 然后加载和执行相应的插件 最后将请求转发至特定的 Upstream 一个最简单的 Route 仅由匹配路径和 Upstream 地址两个信息组成 Upstream Upstream 是一组具备相同功能的节点集合,它是对虚拟主机的抽象 Upstream 可以通过预先配置的规则对多个服务节点进行负载均衡 Examples 创建路由 = Uri + Upstr...
FaaS - Scaling
概述 Serverless 的弹性扩缩容可以将实例缩容为 0,并根据请求量级自动扩缩容,从而有效地提升资源利用率 极致动态扩缩容是 FaaS 的核心内涵,是与 PaaS 平台的核心差异 - 降本增效 调度形态 开源的 Serverless 函数计算引擎核心,一般是基于 Kubernetes HPA 云厂商一般有封装好的各种底座服务,可以基于底座服务来做封装 云厂商容器调度服务,通常有两种调度形态 基于 Node 调度 基于容器实例的调度 - Serverless 云厂商的函数计算通常是基于容器服务的底座 Node 维度 组件 Scheduler 负责将请求打到指定的函数实例(Pod)上,同时负责为集群中的 Node 标记状态,记录到 etcd Local-Controller Node 上的本地控制器,负责管理 Node 上所有函数实例的生命周期,以 DeamonSet 形式存在 AutoScaler 定期检测集群中 Node 和 Pod 的使用情况,并根据策略进行扩缩容 在扩容时,向底层的 PaaS 平台申请资源 Pod Cold 表示该 Pod 未被使用 Warm 表示...

FaaS - Cold Start
触发时机 类似于 LoadingCache 首次请求 容器实例在服务请求后被回收 启动过程 容器创建 当所有容器实例都在处理请求时,需要向集群申请创建新的容器 函数计算平台会支持多种语言的运行时 这些运行时一般来说会打包成一个镜像,然后以 DeamonSet 的方式运行在 Kubernetes 中 在冷启动时,会根据不同的参数请求,动态挂载所需的运行时到对应的运行路径 代码包 / 层依赖 是整个冷启动耗时比较长的过程 函数计算本身不具备持久化的能力,代码包和层依赖通常都是从其它存储服务端拉取 代码包通常是压缩包的形式,下载到本地后,再解压 环境变量 / 参数文件 耗时相对较短 主流的函数计算平台往往提供了环境变量注入的能力,发生在冷启动阶段 运行时以及容器本身还需要准备一些参数配置文件 VPC 打通 / 资源准备 如果用户还为函数接入了私有网络,还需要为容器进行一些 VPC 网络打通的初始化工作 如果用户使用了类似分布式文件系统等功能,还需要进行挂载 运行时初始化 通常指的是云厂商标准的 Runtime 环境的启动过程 受编程语言类型的影响比较大(JV...

FaaS - Advanced Attributes
公共能力 将函数依赖的公共库提炼到层,以减少部署、更新时的代码包体积 对于支持层功能的运行时,函数计算会将特定的目录添加到运行时语言的依赖包搜索路径中 对于自定义层,需要将所有内容打包到一个压缩包,并上传到函数计算平台 函数计算运行时会将层的内容解压并部署到特定的目录 层功能的好处 函数程序包更小 避免在制作函数 zip 包和依赖项过程中出现未知的错误 可以在多个函数中引入使用,减少不必要的存储资源浪费 上传层之后,函数计算会将层的 zip 包上传到对象存储 当调用函数执行时,会从对象存储中下载层的 zip 包并解压到特定目录 应用程序只需要访问特定目录,就能读取层的依赖和公共代码 注意:后序的层会覆盖相同目录下的文件 快速迭代 标准运行时 / 自定义镜像 函数计算系统初始化执行环境之前,会扮演该函数的服务角色,获得临时用户名和密码并拉取镜像 镜像拉取成功后,会根据指定的启动命令、参数和端口,启动自定义的 HTTP Server 该 HTTP Server 会接管函数计算系统所有请求的调用 调用方式不同:事件函数 / HTTP 函数 在创建函...
FaaS - Trigger
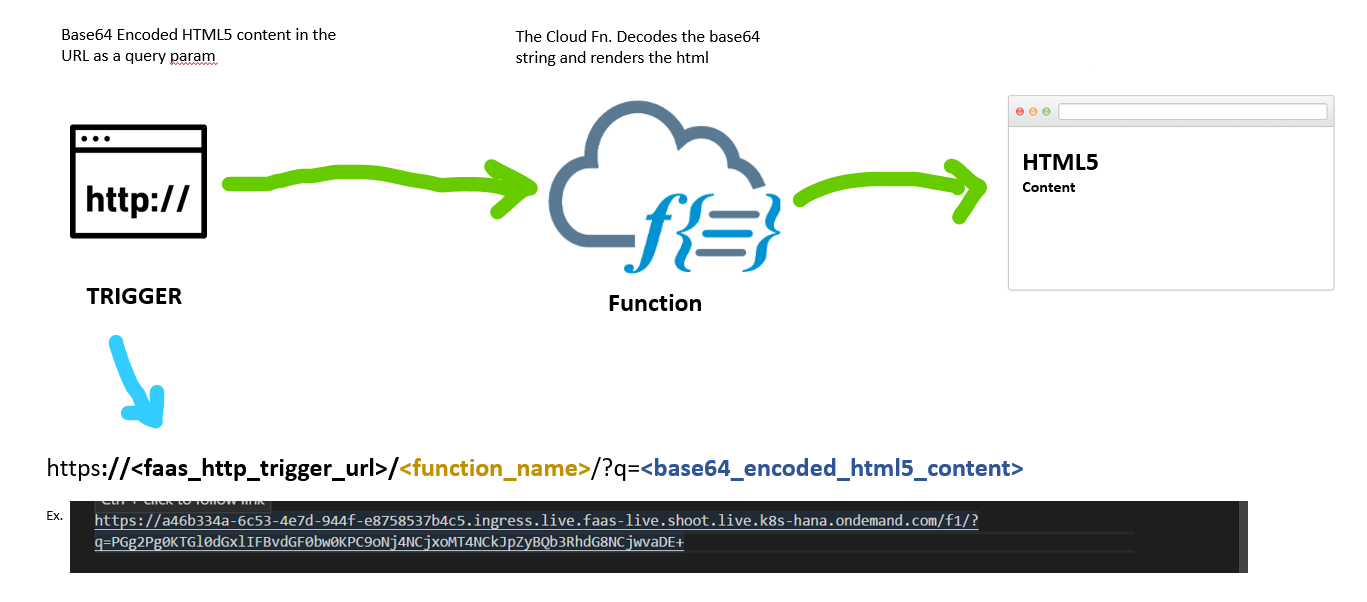
事件 事件为系统运行期间发生的动作或者发生的事情,而函数计算,提供了一种事件驱动的计算模型 CloudEvents 期望通过一种通用的格式描述事件数据的规范,以提供跨服务、平台和系统的互操作性 国内云厂商的事件规范程度:在其中一家云产品上开发了函数,一般都需要进行简单的适配才能迁移 CNCF Serverless 工作组针对函数和工作流均定义了相关的格式规范和原语 单函数的事件触发 多个简单函数通过异步调用的方式形成事件触发 复杂场景下通过 WorkFlow 来进行编排的事件交互 触发器概述 由事件驱动连接上下游服务的关系组合称为触发器 函数计算由云函数和触发器组成 触发器描述了一组关系和规则,包括核心要素:事件源、目标函数、触发条件 事件源:事件的生产者 目标函数:事件的处理者 触发条件:当触发条件满足时,就会通知函数计算引擎,调度对应的目标函数执行 触发器的元数据可以由服务方持久存储,也可以由函数托管平台和服务方共同持有 类型集成原则 区别:事件源和事件的规则存储在哪里,以及从哪里触发 单向集成触发器 双向集成触发器 代理集成触发器 设计触发器的主要考虑:事件源和函数计算的...
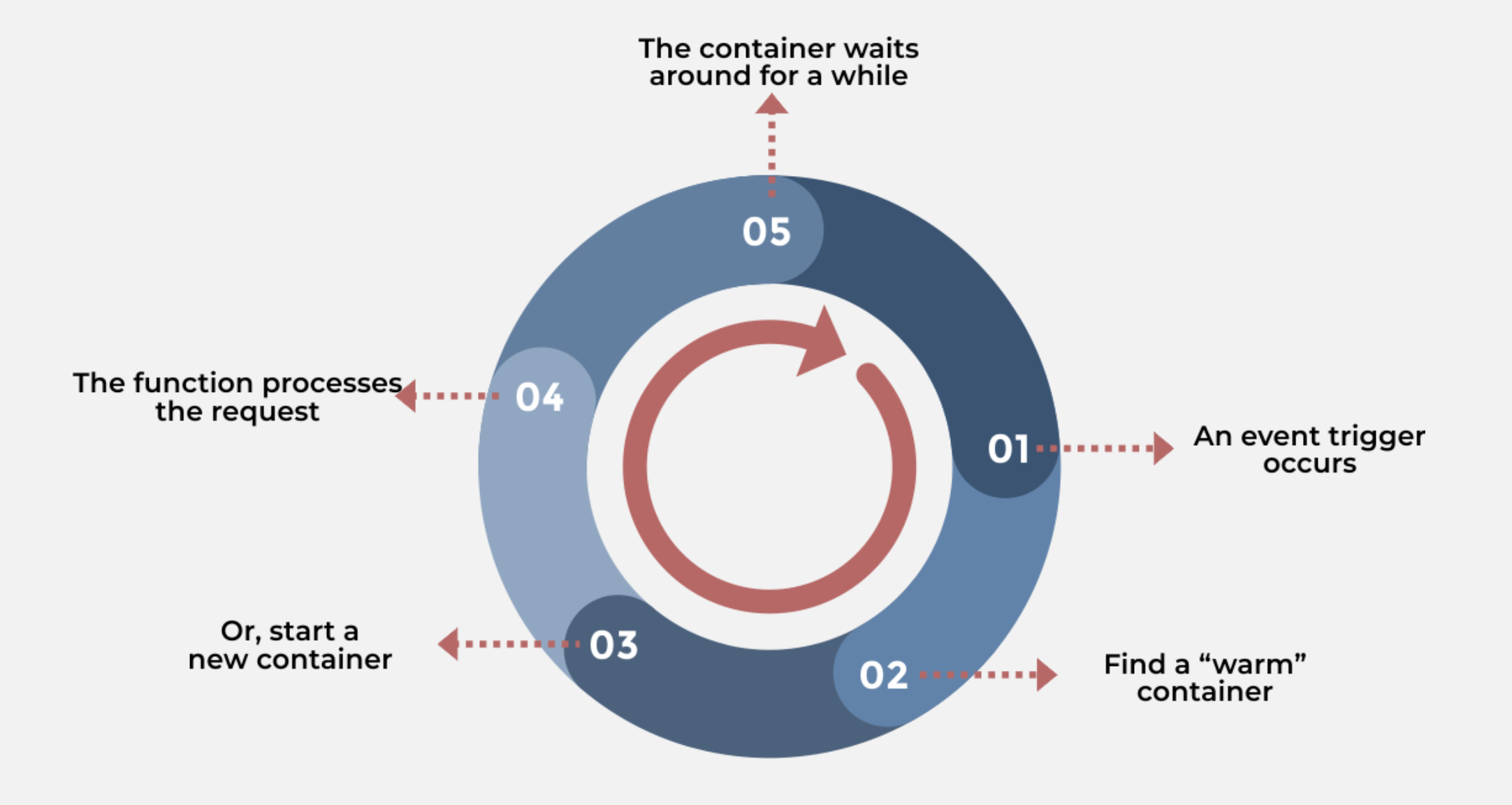
FaaS - Life Cycle
Serverless概述 Serverless 是一种架构设计理念,并非一个具体的编程框架、类库或者工具 Serverless = FaaS + BaaS 构建和运行不需要服务器管理的应用程序 描述一种更细粒度的部署模型 将应用程序打包上传到 Serverless 平台,然后根据实际需求,执行、扩展和计费 Serverless 能够实现业务和基础设施的分离 通过多种服务器无感知技术,将基础设施抽象成各种开箱即用的服务 以 API 接口的方式提供给用户按需调用,真正做到按需伸缩、按量收费 场景 形成了以函数计算、弹性应用、容器服务为核心的产品形态 函数计算 - 面向函数 用户只需关注函数层级的代码,用于解决轻量型、无状态、有时效的任务 Serverless 应用托管 - 面向应用 应用只需要关注应用本身 与微服务结合,融合应用治理、可观测 降低了新应用的构建成本,老应用的适配改造成本 Serverless 应用服务 - 面向容器 在不改变当前 kubernetes 的前提下,由于不再需要关注 Node,降低了维护成本 FaaS Life Cycle用户视角 开发...
DevOps - IaC
IaC概述 使用代码定义基础设施(声明式:云资源、配置、工具安装) 借助 Git 实现对基础设施的版本控制 有状态 - Diff + Patch 优势 幂等 版本控制 使用 Git 进行变更管理(批准、安全检查、自动化测试) 清晰的变更行为 快速配置基础设施 能力 提供以编码工作流来创建基础设施 更改或者更新现有的基础设施 安全地更改基础设施 与 CICD 工具集成,形成 DevOps 工作流 提供可复用的模块,方便协作和共享 实施安全策略和生产标准 实现基础设施的团队协作 工具 Terraform Pulumi Crossplane Terraform核心架构 全新的配置语言 HCL - HashiCorp configuration language 可执行的文档 人类和机器可读 学习成本低 测试、共享、重用、自动化 适用于几乎所有云厂商 HCL 最终转换为 JSON 对象,再与云厂商交互 JSON 123456789101112131415161718{ "io_mode": "async", "service...
DevOps - Foundation
基本原理核心原理 隔离机制 运行 Nginx 镜像 1234567891011121314151617$ docker run -d nginx:latestUnable to find image 'nginx:latest' locallylatest: Pulling from library/nginx25d3892798f8: Pull complete42de7275c085: Pull completec459a9332e03: Pull complete48882f13d668: Pull complete49180167b771: Pull completeda4abc2b066c: Pull complete20dc44ab57ab: Pull completeDigest: sha256:5f44022eab9198d75939d9eaa5341bc077eca16fa51d4ef32d33f1bd4c8cbe7dStatus: Downloaded newer image for nginx:latestd821171713e9b805c4180c122...
DevOps - Overview
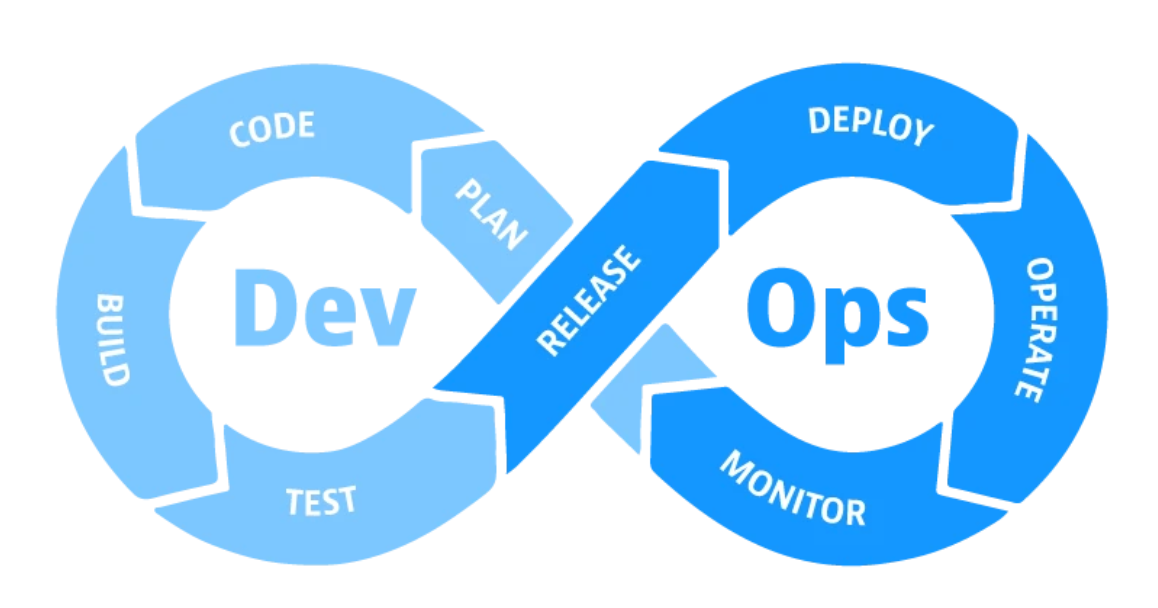
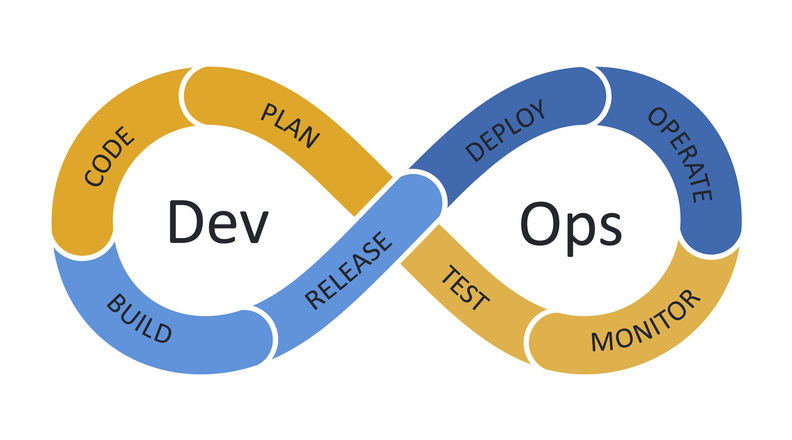
演进过程精益 诞生于工业领域:用最少的时间和资源消耗,生产出高质量的产品 瀑布模式 线性的开发流程、将软件开发划分为一系列阶段 敏捷模式 误区:敏捷 = 管理 敏捷是基于精益的思想 将开发过程拆分成 N 个敏捷开发周期,小步快跑 生命周期 基于迭代的敏捷(固定的迭代周期) 基于流程的敏捷(不固定的迭代周期) 运维不堪重负,建立部门墙,敏捷模式只关注开发,不关注运维 DevOps 核心阶段 版本控制 持续集成 - 代码提交 持续交付 - 测试环境 持续部署 - 生产环境 持续监控 源码管理 SVN / Git Git Flow git pull = git fetch + git merge Git 高级用法rebase 将一个分支的提交移动到另一个分支的末尾,使得提交历史更加线性和整洁 主要场景: 更新本地分支以匹配远程分支,避免产生多余的 merge commit 合并提交 重新排列提交 12$ git checkout feature$ git rebase master 从两个分支的共同祖先开始提取待变基分支(fe...

Kubernetes - Security
层次模型 开发 分发 部署 运行时 容器运行时Non-root 在 Dockerfile 中通过 USER 命令切换成非 root 用户 防止某些镜像窃取宿主的 root 权限并造成危害 在某些容器运行时,容器内部的 root 用户与宿主上的 root 用户是同一个用户 宿主上的重要文件被 mount 到容器内,并被容器修改配置 即使在容器内部也应该权限隔离 123FROM ubuntuRUN user add AUSER A User namespace 依赖 User namespace,任何容器内部的用户都会映射为宿主上的非 root 用户 默认关闭,因为会引入配置复杂性 系统不知道宿主用户与容器用户的映射关系,在 mount 文件时无法设置适当的权限 Rootless container 容器运行时以非 root 身份启动 即使容器被攻破,在宿主层面获得的用户权限也是非 root 用户 Docker 和其它容器运行时本身的后台 Daemon 需要以 root 身份运行,其它的用户容器才能以 rootless 身份运行 某些运行时,如 Podman,没有 Daemon 进程,...